🌈 博客个人主页:Chris在Coding
🎥 本文所属专栏:[高并发内存池]
❤️ 前置学习专栏:[Linux学习]
⏰ 我们仍在旅途

目录
前言
项目介绍
1.内存池
1.1 什么是内存池
池化技术
内存池
1.2 为什么需要内存池
效率原因
内存碎片问题
1.3 实现定长内存池理解池化技术
定长内存池的设计
_freelist的设计
New()和Delete()的设计
与malloc()做性能对比
前言
项目介绍
首先,本项目的原型是Google的一个开源项目TCMalloc,TCMalloc是谷歌开发的一种内存分配器(Memory Allocator),专门用于优化大规模的多线程应用程序的内存分配和管理。TCMalloc的全称是Thread-Caching Malloc,意为线程缓存内存分配器。它最初是为谷歌的服务器应用程序而开发的,旨在解决大规模多线程服务器应用程序中内存分配性能不佳的问题。

Google作为世界级大厂,学习并复现该项目, 我们能体会到其精妙的项目架构设计
1.内存池
1.1 什么是内存池
池化技术
池 是在计算机技术中经常使用的一种设计模式,其内涵在于:将程序中需要经常使用的核心资源
先申请出来,放到一个池内,由程序自己管理,这样可以提高资源的使用效率,也可以保证本程
序占有的资源数量。 经常使用的池技术包括内存池、线程池和连接池等,其中尤以内存池和线程
池使用最多。
内存池
内存池(Memory Pool)是一种动态内存分配与管理技术,旨在优化内存的分配和释放过程,减少内存碎片化,提高程序和操作系统的性能。通常情况下,程序员直接使用诸如new、delete、malloc、free等API进行内存的申请和释放,但这种方式容易导致内存碎片化问题,尤其在长时间运行的情况下性能表现更为明显。
内存池的工作原理是在程序启动时预先申请一大块内存作为池,之后在程序运行过程中,从这个内存池中动态分配内存给程序使用。当程序需要内存时,可以直接从内存池中取出一个空闲的内存块;当程序释放内存时,将释放的内存块重新放回内存池中,以备后续使用。同时,内存池会尽可能地与周边的空闲内存块合并,以减少内存碎片的产生。如果内存池的空闲内存不足以满足程序需求,内存池会自动扩大,向操作系统申请更大的内存空间。
内存池的优点包括:
- 减少内存碎片化:通过提前申请一大块内存并动态分配管理,内存池可以有效减少内存碎片的产生。
- 提高性能:内存池避免了频繁的内存申请和释放操作,从而减少了系统开销,提高了程序和操作系统的性能。
1.2 为什么需要内存池
效率原因
假设你是一个图书管理员,你管理着一个图书馆的书籍。每当有读者来借书时,你需要为他们分配一本书。如果每次有读者来借书时都去印刷新书(动态分配内存),等读者归还书籍后再销毁书籍(释放内存),那么你将花费大量的时间和精力来管理这个过程,而且频繁的印刷和销毁书籍会带来一定的成本和效率损失。
相反,如果你有一个固定数量的书库(内存池),这些书籍已经预先准备好并且处于待命状态。当读者来借书时,你只需要从书库中选择一本可用的书分配给他们,归还后书籍继续留在书库中等待下一个读者的到来。这样可以避免频繁的书籍印刷(内存分配)和销毁(内存释放),节省了时间和成本,提高了效率。
内存碎片问题

假设我们直接在堆上直接申请内存,依次申请出8ytes,24bytes,10bytes,20bytes,此时堆上还剩8bytes没被申请,而这时候我们向堆归还了原先的24bytes和20bytes的内存,这时如果我们想再去堆上申请一个30bytes的内存是申请不出来的,但是实际上我们此时空余的内存达到了52bytes,但可惜的是我们无法凑出连续的30bytes内存块.而这也就是所谓的外部内存碎片问题.
内存碎片问题通常被分为内部碎片问题和外部碎片问题。这两种碎片问题都是指在内存管理过程中未被有效利用的内存空间,但它们的来源和解决方法略有不同。
-
内部碎片问题(Internal Fragmentation): 内部碎片是指已经被分配给进程或对象的内存空间中,由于未被完全利用而产生的空闲部分。这种情况通常出现在动态内存分配中,比如在分配内存时,由于分配的内存块大于所需大小,导致分配的内存中存在一些未被使用的空间。内部碎片问题通常由内存分配算法引起,例如,如果使用固定大小的内存块进行分配(如固定大小的内存池),而分配的内存大小与需求不匹配,就会产生内部碎片。
-
外部碎片问题(External Fragmentation): 外部碎片是指未分配给任何进程或对象的内存空间中的零散碎片。这些碎片可能由已释放的内存块留下,但由于它们的大小和位置不符合当前内存分配需求,因此无法被有效利用。外部碎片问题通常由内存释放操作引起,释放的内存块使得内存空间出现了不连续的空闲区域,这些零散的空闲区域无法满足大块内存分配的需求,从而产生了外部碎片。
1.3 实现定长内存池理解池化技术
malloc
在C/C++编程中,当我们需要动态分配内存时,确实不是直接与操作系统打交道,而是通过诸如malloc这样的函数来完成。malloc是一个C标准库提供的函数,它帮助我们从计算机系统的堆内存区域请求一定数量的连续内存空间。
在C++中,new关键字则是用来进行动态内存分配的另一种方式,它本质上是对malloc功能的扩展和封装,不仅分配内存,还能自动调用构造函数初始化对象(对于类类型数据)。当你使用new分配数组或对象时,它会确保每个元素或对象都被正确初始化。而delete关键字在释放内存的同时,也会调用析构函数来清理对象。

不同编译器和操作系统环境下,malloc的具体实现可能会有所不同。例如,在Windows下的Visual Studio编译器中,malloc由微软进行了特定的优化实现;而在Linux系统下,采用glibc库的编译器(如GCC)则使用ptmalloc作为默认的malloc实现。这些实现通常包含高级算法,旨在提高内存分配的效率、减少碎片并满足各种内存需求。
定长内存池的设计
malloc函数作为一个通用的内存分配器,它可以接受任意大小的内存请求,并试图在堆上找到合适的连续空间进行分配。然而,由于它的通用性,它必须处理各种尺寸的请求,这可能导致内部碎片(即分配出的内存块之间存在无法使用的空隙),并且每次分配或释放都需要一定的查找和维护成本,所以对于特定场景而言,其性能可能不如针对性设计的内存管理方案。
定长内存池(Fixed-size Memory Pool)正是这样一种针对性的设计,它适用于那些内存块大小固定的场景,例如在大量创建和销毁相同大小对象的应用中。在定长内存池中,内存预先按照固定大小进行划分,申请和释放内存的操作可以简化为从池中取出或归还一个预设大小的内存块,无需像malloc那样复杂的寻找合适大小的空间。这种做法能够显著减少内存分配和释放的开销,消除内部碎片。
通过从零实现一个定长内存池,我们可以更直接的理解池化技术,同时也是在为高并发内存池项目的实现做铺垫。
template<class T, long long Nums>
class ObjMemoryPool
{
public:
ObjMemoryPool()
:_freelist(nullptr), _pool(nullptr), _remainder(0)
{}
T* New()
{
}
void Delete(T* obj)
{
}
private:
void* _freelist;
char* _pool;
size_t _remainder;
};我们首先写出定长内存池类ObjMemoryPool的大致框架,同时使用可变模板参数class T表示定长内存池存储的对象的类型和long long Nums来表示每次内存池预先申请多少个T大小的空间。
同时我们后面会通过一个_freelist来实现对回收对象的管理,_remainder则表示内存池剩余的字节数,同时我们会留出接口New(),Delete(),来调用以申请和销毁对象。
_freelist的设计
这里我们将_freelist(自由链表)设计成一个不带头的单向链表,把每个回收的对象当作链表的节点链接存储维护。

我们会从每一个对象的内存块中取出一块来存放下一个内存块的地址来实现指针链接
但是这个时候我们会遇到一个问题:指针的大小在32位和64位下的大小不一致,如何在32位平台取出4个字节,而在64位平台下取出8个字节呢?
void* nextobj = *(void**)obj;这里通过将当前obj对象的指针强转为void**类型,即认为obj指向一个指针类型,这时候直接解引用该指针就一定是取出一个指针大小的内存块,我们就可以在其中读取或者写入下一个内存块的地址。
New()和Delete()的设计
由于是_freelist是单向链表,这里我们将节点的插入与取出都设计成O(1)时间复杂度的头插和头删。
Delete()
void Delete(T* obj)
{
obj->~T();
*(void**)obj = _freelist;
_freelist = obj;
}Delete()接口的实现最简单,我们只需要去调用内存块中对应类型的析构函数,再直接将其头插进_freelist里面即可。
直接向堆申请空间
这里我们的项目将摆脱与malloc的联系,直接向堆申请空间使用和管理。
要想直接向堆申请内存空间,在Windows下,可以调用VirtualAlloc函数;在Linux下,可以调用brk或mmap函数。这里我在Windows下便选择使用VirtualAlloc函数。
#ifdef _WIN32
#include <windows.h>
#endif
inline static void* SystemAlloc(size_t kpage) {
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32
VirtualFree(ptr, 0, MEM_RELEASE);
#endif
- 0:此参数指定要分配的区域的起始地址。当设置为0时,系统会确定在哪里分配该区域。
- kpage << 13:此参数指定要分配的内存大小,VirtualAlloc 函数返回的内存区域地址会在页边界上对齐,页大小通常是4KB(即2的12次方字节),这里就是指我们一次申请的内存块大小为kpage页
- MEM_COMMIT表示根据需要分配已提交页面的物理存储或后备空间。
- MEM_RESERVE表示保留进程虚拟地址空间的一段范围,而不分配任何实际的物理存储。
- PAGE_READWRITE:此参数指定区域的内存保护。在这种情况下,它允许对分配的内存进行读取和写入。
_RoundUp()对齐
inline size_t _RoundUp(size_t size, size_t alignsize)
{
if (size % alignsize == 0)
{
return size / alignsize;
}
return size / alignsize + 1;
}既然我们是选择以页为单位申请内存块, 这里我们在申请内存前就要将申请的内存大小向上取整对齐页的大小,这里的alignsize使用时就传入一页的字节大小。
New()
T* New()
{
T* allocate = nullptr;
if (_freelist)
{
allocate = (T*)_freelist;
_freelist = *(void**)_freelist;
}
else
{
if (_remainder < sizeof T)
{
size_t kpage = (_RoundUp(sizeof T * Nums, 1 << 13) >> 13);
_remainder = sizeof T * Nums;
_pool = (char*)malloc(_remainder);
if (_pool == nullptr)
{
throw std::bad_alloc();
}
}
allocate = (T*)_pool;
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_pool += objSize;
_remainder -= objSize;
}
new(allocate) T(); //定位new,显示调用T的构造函数初始化
if (allocate == nullptr)
{
int n = 0;
}
return allocate;
}- 用于从内存池中分配一个新的对象。如果有空闲对象可用,则从 _freelist 中获取一个,并将 _freelist 指向下一个空闲对象。
- 如果没有空闲对象,则从内存池 _pool 中分配新的内存,如果剩余空间不足以容纳一个对象,则重新分配内存池。
- 在分配的内存位置使用定位 new 构造一个类型为 T 的对象,并返回指向该对象的指针。
与malloc()做性能对比
完整代码:
#pragma once
#include <iostream>
#include <vector>
#include <time.h>
using std::cout;
using std::endl;
inline size_t _RoundUp(size_t size, size_t alignsize)
{
if (size % alignsize == 0)
{
return size / alignsize;
}
return size / alignsize + 1;
}
template<class T, long long Nums>
class ObjMemoryPool
{
public:
ObjMemoryPool()
:_freelist(nullptr), _pool(nullptr), _remainder(0)
{}
T* New()
{
T* allocate = nullptr;
if (_freelist)
{
allocate = (T*)_freelist;
_freelist = *(void**)_freelist;
}
else
{
if (_remainder < sizeof T)
{
size_t kpage = (_RoundUp(sizeof T * Nums, 1 << 13) >> 13);
_remainder = sizeof T * Nums;
_pool = (char*)malloc(_remainder);
if (_pool == nullptr)
{
throw std::bad_alloc();
}
}
allocate = (T*)_pool;
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_pool += objSize;
_remainder -= objSize;
}
new(allocate) T(); //定位new,显示调用T的构造函数初始化
if (allocate == nullptr)
{
int n = 0;
}
return allocate;
}
void Delete(T* obj)
{
obj->~T();
*(void**)obj = _freelist;
_freelist = obj;
}
private:
void* _freelist;
char* _pool;
size_t _remainder;
};
struct TreeNode
{
int _val;
TreeNode* _left;
TreeNode* _right;
TreeNode()
:_val(0)
, _left(nullptr)
, _right(nullptr)
{}
};
int main()
{
// 申请释放的轮次
const size_t Rounds = 5;
// 每轮申请释放多少次
const size_t N = 100000;
std::vector<TreeNode*> v1;
v1.reserve(N);
size_t begin1 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode);
}
for (int i = 0; i < N; ++i)
{
delete v1[i];
}
v1.clear();
}
size_t end1 = clock();
std::vector<TreeNode*> v2;
v2.reserve(N);
ObjMemoryPool<TreeNode,10000> TNPool;
size_t begin2 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New());
}
for (int i = 0; i < N; ++i)
{
TNPool.Delete(v2[i]);
}
int x=1;
v2.clear();
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl;
cout << "object pool cost time:" << end2 - begin2 << endl;
return 0;
}1)定义了一个简单的二叉树节点结构 TreeNode,做为被测试申请释放的obj类型
2)在 main() 函数中:
- 设置了两组实验参数:每轮申请释放的次数 N 和申请释放的轮次 Rounds。
- 创建了两个空的 vector 容器 v1 和 v2,用于存放申请的节点指针。
- 对第一组实验使用了直接使用 new 的方式进行内存分配和释放。通过循环在每轮中申请 N 个节点,然后释放它们,并清空容器。
- 对第二组实验使用了自定义的对象内存池 ObjMemoryPool 进行内存分配和释放。同样地,通过循环在每轮中申请 N 个节点,然后释放它们,并清空容器。 记
3)录了每组实验的开始和结束时间,并输出两组实验的时间差,以比较它们的性能。 最后输出了两组实验的耗时情况。
测试结果:
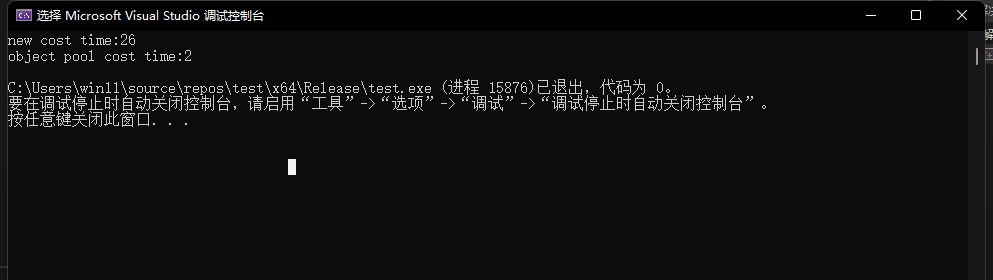
这里我们可以明显看到,此时定长内存池的申请释放效率明显快过malloc和free
![]()
![P9905 [COCI 2023/2024 #1] AN2DL 【矩阵区间最大值】](https://img-blog.csdnimg.cn/direct/4f73e4d86e754d29833b227c5da0e9fa.png#pic_center)