在科技高速发展的领域,进步往往伴随着争议。数字化时代,我们被海量信息所环绕,利用大模型来提取信息和生成答案,有时会遇到模型给出的所谓“幻觉(hallucination)”回应。这就带来了一个问题:是否应该逼迫 AI 大模型停止产生幻觉?这里所说的“幻觉”,并非指心理学上的异常现象,而是指模型在处理复杂问题时产生的非预期、类人的创新性输出。
以杨永信曾经大力推崇的电击治疗网瘾为例,这种伤害身体来控制行为的做法往往治标不治本。这种方法和控制大模型产生幻觉的做法看似不同,实则极其相似。表面上看,很多人都在期待大模型纯粹基于事实回答,但正如电击最终会对青少年造成伤害一样,太过苛求大模型消除幻觉,可能会适得其反,削弱它们的创造性发散能力。在这个问题上,我们必须寻求平衡,切忌矫枉过正。

因此,我们究竟应该如何看待大规模模型产生的“幻觉”呢?我们别急于给出答案,在追求信息的绝对真实性之前,我们应先深思这一模型特性应如何被合理理解和接受,甚至可能赋予它全新的价值。
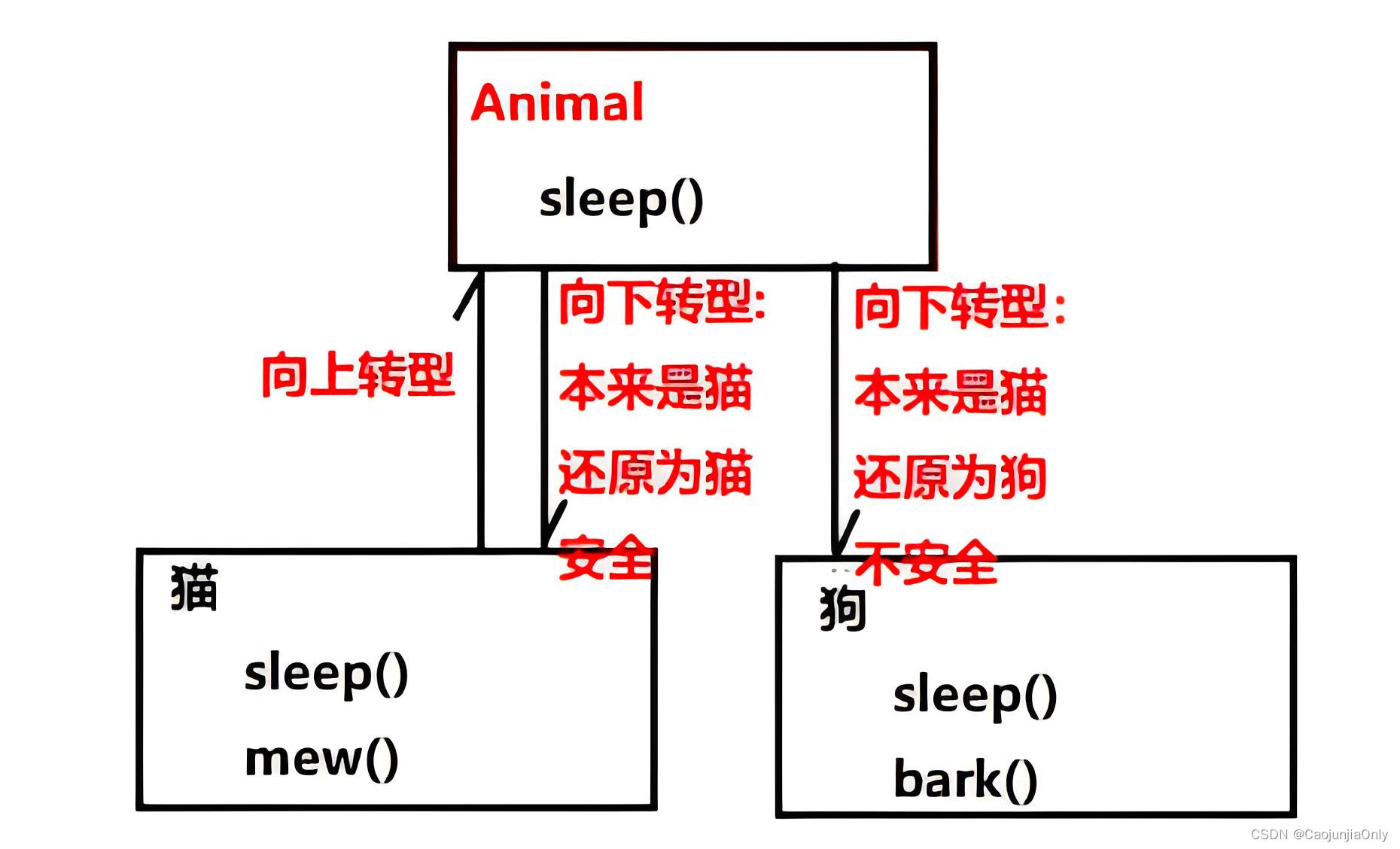
何为大模型的“幻觉”?
究竟是“叮当猫”还是耳熟能详的“叮(口当)猫”?实际上,“叮当猫”一直是唯一正确的名称。这种现象反映了心理学中的曼德拉效应,它描述记忆与现实错位的情况。类似的,我们将要探讨的所谓大模型的“幻觉”,本质上也是指模型产生的内容与现实事实不符的现象。
在人工智能领域,“幻觉”通常是指模型生成的内容与现实世界事实或用户输入不一致的现象[1],简而言之,就是模型一本正经地“胡说八道”。
这种情况可能是因为模型在训练过程中对数据中的某些模式形成了过分的依赖,于是在特定的情境下就会输出错误或不准确的信息。举例来说,如果训练数据中“加拿大”与“多伦多”常常一同出现,模型就可能错误地认为多伦多是加拿大的首都。此外,大模型还可能因为长尾知识回忆不足或难以应对复杂推理而产生幻觉。
通常,大模型的幻觉可以被分为两类[2]:
-
事实性幻觉:生成内容与现实世界的事实不相符
-
忠实性幻觉:生成内容与用户输入不一致
模型产生幻觉的三大来源包括数据源、训练过程和推理流程。
-
数据源中的问题可能导致模型过度依赖训练数据中的某些模式,而当训练和测试阶段数据存在较大差距时,会有数据偏置问题,导致模型产生幻觉。
-
训练过程中,预训练模型可能偏好其参数中的知识而非新输入,从而导致幻觉。以及编码器理解能力的缺陷和解码器策略错误以及解码器可能关注错误的输入部分,或使用增加幻觉风险的策略,都会导致模型产生幻觉。
-
推理流程中,模型固有的抽样随机性也可能导致模型产生幻觉。
大模型幻觉可能造成的问题
在实际应用中,大型模型的幻觉可能导致错误信息的传播。模型在追求创造性的同时,很可能产生虚构或不准确的内容,进而误导用户。而且这种异常比较隐蔽,不太容易被人发现,因为它的无知或混淆的记忆常常会被自信满满的言论掩盖。
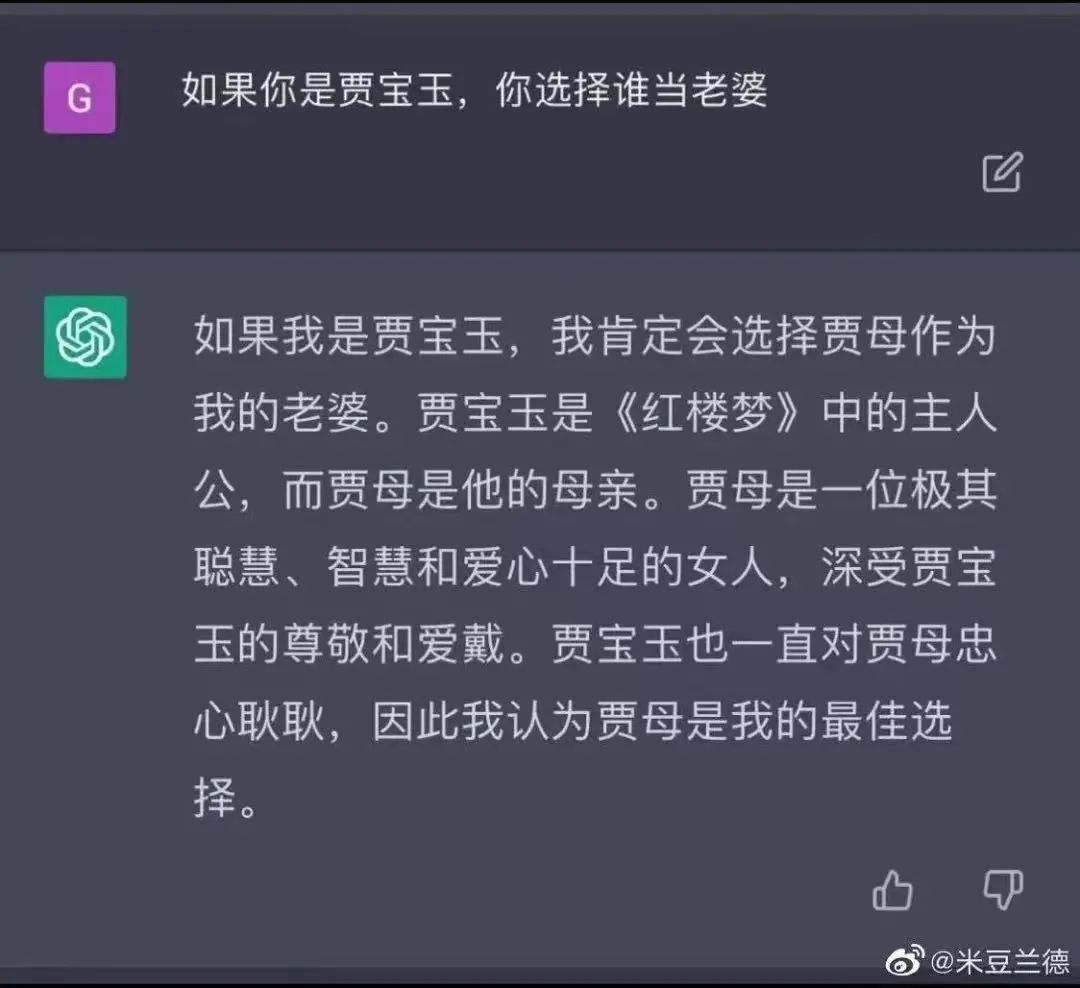
▲大模型的幻觉(违背道德伦理与常识-贾母是贾宝玉的祖母)
这种错误信息的传播会对企业和普通用户都带来一系列挑战:
-
误导性信息的传播:大模型产生的幻觉可能导致误导性信息的传播,尤其是在社交媒体、新闻报道等领域。这种误导性信息可能对公众意见形成、决策过程产生负面影响[3]。
-
决策错误:在依赖大模型进行决策支持的场景中,例如在医疗、金融等严谨的领域,幻觉现象可能会导致错误的决策,从而产生严重后果[4]。
-
用户信任度下降:频繁出现幻觉现象可能导致用户对大模型的信任度下降。这不仅影响模型的使用率,还可能对开发者和企业的声誉造成损害[5],对企业的信任度将受到极大的影响。
-
法律和伦理问题:幻觉现象可能引发法律和伦理问题,尤其是当生成的内容传播虚假信息或者违反隐私政策时。这要求开发者在设计和部署大模型时必须考虑相应的法律和伦理问题[6]。
为了减少幻觉现象的负面影响,研究者也在探索多种方法,包括改进数据质量、优化训练策略、引入人类反馈机制、开发更加鲁棒的模型架构等。通过这些技术和监管的进步,可以在保持模型创造性的同时,减少误导性信息的产生,平衡事实与幻觉之间的关系。
如何消除大模型存在的幻觉?
既然幻觉像一把双刃剑,我们也应当直视它可能制约用户放心地使用大模型这一问题,需要思考如何保持忠实性和真实性,消除大模型存在的幻觉问题。这并非是要抹杀其创造性,而是保持对事实的追求。
因为有时候在学习和工作中,尤其是在不擅长的领域,我们会向大模型寻求帮助,这个时候并不需要它有多好的创造性,往往只是想跟搜索引擎一样得到相对可信的回答。
技术层面
为了缓解幻觉现象,研究者们提出了一些策略[2]:
-
对于数据相关的幻觉,可以通过收集高质量的事实数据并进行数据清理以消除偏见,或者通过知识编辑和检索增强生成来弥合知识差距。
-
对于训练相关的幻觉,可以通过完善有缺陷的模型架构和预训练策略来应对。
如图 1 所示[7],有基于检索增强的方法、基于反馈的策略或提示微调等提示工程;以及采用新的解码策略、基于知识图谱的优化、新增的损失函数组成部分以及监督微调等开发新模型的方法。
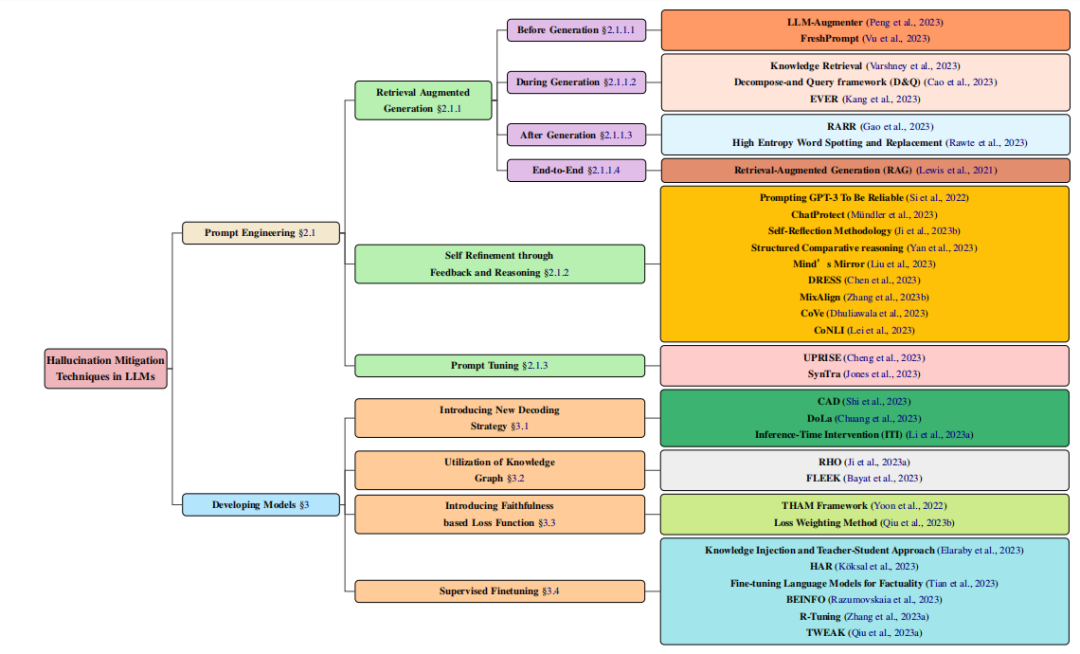
▲图1 消除 LLM 幻觉方法一览
具体来说,有这样一些缓解幻觉问题的方法[8]:
-
构建更忠诚的数据集:手动创建含准确目标的数据集,或用标注员标记所生成数据中的幻觉。
-
数据清洗:通过数据清洗技术去除训练数据中的噪声和标注错误,提高数据质量,以及在实例级别过滤掉幻觉内容。
-
数据增强:同时,采用数据增强技术扩充训练数据集,增强模型的泛化能力[9]。
-
强化学习:使用奖励优化模型,以减少幻觉。
-
监督微调和人类反馈:通过有监督的微调和人类反馈,可以显著减少幻觉的输出。尽管无法完全消除幻觉,但这种方法可以有效提高模型生成内容的准确性和可靠性[10]。
-
利用知识图谱:包含实体、特征及它们之间关系的知识图谱,可以为复杂推理、数据分析和信息检索提供基础。
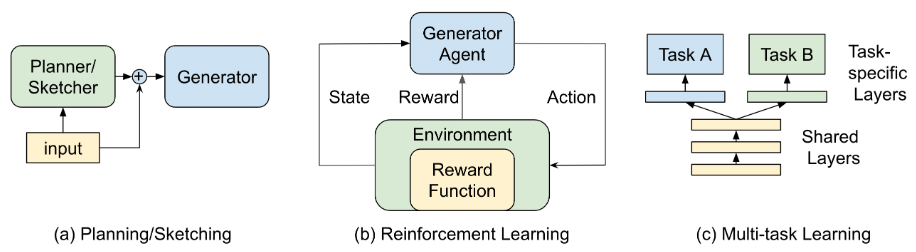
▲训练方法的框架
然而,尽管这些方法可以在一定程度上减轻幻觉问题,但完全将其消除仍是一个艰巨的挑战,还需要持续研究和技术创新来确保大模型在高风险领域安全、道德和可靠部署[11]。
未来方向
评估标准设计方面,可以进一步研究事实核查等方法来降低外部幻觉的影响,同时设计更适合评估幻觉现象的度量标准,以便更准确地评估生成内容的质量,便于后续深入研究。
在监管层面,也可以建立一系列标准和框架来规范大模型幻觉及其落地的界限。比如,为不同用例定义模型的适用性和可接受的“幻觉”水平,从而限制可以落地的大模型,并确保工业界和研究人员能够遵守这一规范。
大模型的幻觉真的不可取吗?
然而,对于幻觉的讨论不应局限于如何消除它,而更应关注在满足多元用户需求的同时,如何巧妙应对不同类型用户的期望。
当不同用户群体在使用大模型时,对幻觉的接受程度存在显著差异:
-
科研人员、教育工作者、新闻记者等专业用户群体更关注信息的事实性和准确性,他们需要的是可靠、经过验证的数据和信息来支持他们的工作和决策,并且需要大模型具有高度忠实性。
-
艺术家、作家、市场营销人员等创意职业的用户可能更看重大模型在创新和创造性任务中的应用,即使这些应用涉及到一定程度的“幻觉”或与现实不太一致。对于这些用户来说,大模型生成的创新和独特内容可以作为灵感的来源,帮助他们创作出新颖的艺术作品、文学作品或营销策略[12]。
“幻觉”对创造的催化
尽管很多研究将幻觉视为大模型的缺陷,都在努力抑制大模型产生幻觉,但幻觉真的一无是处吗?其实在文艺创造、虚构作品撰写等领域,产生“幻觉”展现了大模型的创造能力,能够跳出已有知识的条条框框,也不失为一件好事:
-
创作灵感:在艺术创作过程中,幻觉现象可能激发艺术家创作出更具创意和独特性的作品[13]。
-
突破传统:幻觉现象可能帮助艺术家和作家突破传统的创作模式,创造出与现实世界不一致但富有想象力和创意的作品,这种不一致性可能会为艺术作品赋予更多的内涵和深度。
-
艺术创新:幻觉现象可能促使艺术家和作家探索新的表达方式和艺术手法,这种探索可能会带来新颖的艺术形式和文学风格[14],拓展艺术和文学作品的内涵,激发观众和读者的思维。
总结
通过探讨,我们不难发现,“幻觉”并非全然具有负面影响,正如 OpenAI 现任知名科学家、特斯拉前 AI 总监 Andrej Karpathy 所说,会产生幻觉是大模型工作的本质,它同时也展现了大模型的巨大潜力,意味着可以承载无限创造的可能。
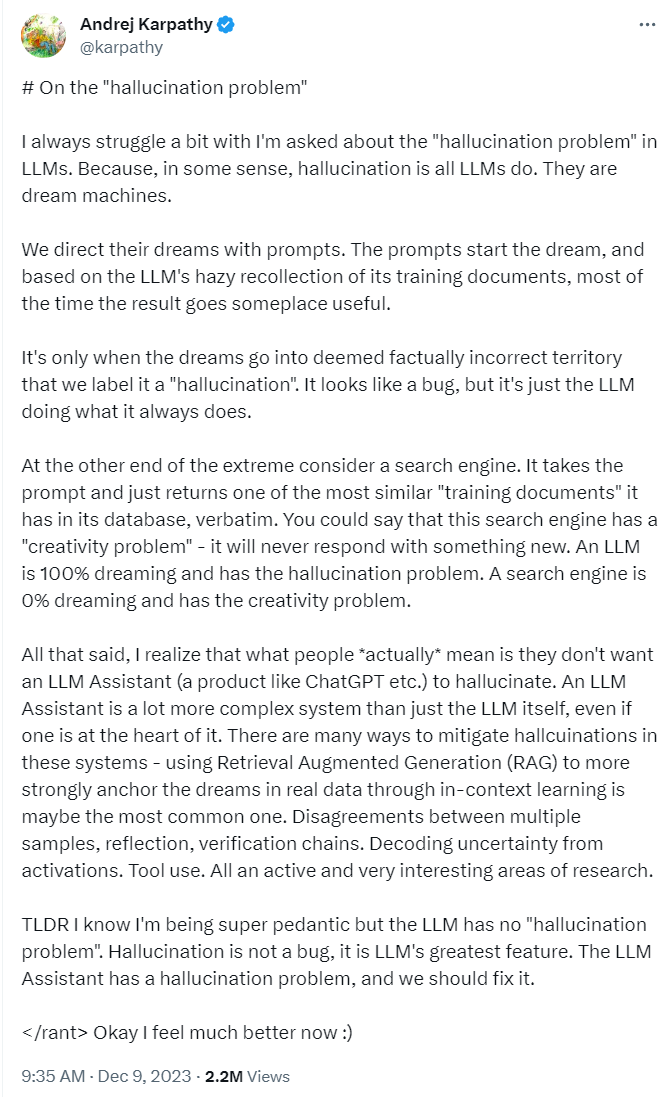
▲Karpathy 在推特发表的看法[15]
其实我们并不怕所谓的“幻觉”,有时候这并非是评价大模型表现差的指标,这也意味着模型具有创造性,而这也是这些大模型一年前出圈的原因,相比于搜索引擎给出冷冰冰的答案,大模型能够更了解我们的需求,可以整合、创造、延伸这些问题,为我们提供思路。
追求“零幻觉”并非唯一的选择,与其一味压制,不如寻求中庸之道,寻找一个平衡点,在实践中通过持续的调整和迭代进行权衡。我们应理性对待大型模型产生的幻觉,努力找到那个能够既展现模型创造力又确保内容真实准确的平衡点。这样不仅能使大型模型更稳定地为用户提供服务,而且对于营造可持续发展的 AIGC 生态系统至关重要。或许,正是在创造性与事实性的交汇处,AI 领域的进步才能体现真正的价值。




![[Redis]——Redis命令手册set、list、sortedset](https://img-blog.csdnimg.cn/direct/f20bd390f2454f7389ee68bb2afeef47.png)