明朝那些事中有一句话:我之所以写徐霞客是想告诉你,所谓千秋霸业万古流芳,与一件事相比,其实都算不了什么,这件事情就是——用你喜欢的方式度过一生。
我们以最简单的 CUDA 程序:从 GPU 中输出 Hello World! 字符串开始 CUDA 编程的学习。
经典的 Hello World 程序几乎是学习任何一门新编程语言的出发点。
学会了 HelloWorld 程序的开发过程,就对一个新的编程语言有了一个初步的认识。
本书的所有范例都是基于 Linux 操作系统开发的,但大部分也在 Windows 操作系统中使用 Command Prompt 命令行通过测试。因此,读者需要掌握基本的 Linux 或 Windows 命令行操作知识。
C++ 语言中的 Hello World 程序
学习 CUDA C++ 编程需要读者比较熟练地掌握 C++ 编程的基础。
虽然 CUDA 支持很多 C++ 的特征,但作者写的 C++ 程序有很多 C 程序的痕迹,而且本书基本上不涉及 C++ 中的类和模板等编程特征。
我们先回顾一下 C++ 中 Hello World 程序的开发过程。在 C++ 语言中开发一个程序的大致过程如下:
-
- 用文本编辑器写一个源代码(source code)。
-
- 用编译器对源代码进行预处理、编译、汇编并链接必要的目标文件得到可执行文件(executable)。这些步骤往往可由一个命令完成。
-
- 运行可执行文件得到结果。
1 #include <stdio.h>
2
3 int main(void)
4 {
5 printf("Hello World!\n");
6 return 0;
7 }
首先,让我们用编辑器写下 Listing 2.1 中的源代码。然后,将程序的文件命名为 hello.cpp,并用 g++ 编译(如上所述,此处及后面所说的编译其实包含了预处理、编译、汇编、链接等步骤):
首先,让我们用编辑器写下 Listing 2.1 中的源代码。然后,将程序的文件命名为 hello.cpp,并用 g++ 编译(如上所述,此处及后面所说的编译其实包含了预处理、编译、汇编、链接等步骤):
$ g++ hello.cpp
编译通过后,将得到一个名为 a.out 的可执行文件。用如下命令执行该文件:
$ ./a.out
接着,就可以看到屏幕上打印出如下文字:
Hello World!
也可以在编译时指定二进制文件的名字。例如,用如下命令:
$ g++ hello.cpp -o hello
将得到一个名为 hello 的可执行文件,可以用如下命令运行它:
$ ./hello
以上假定使用了 GCC 编译器套装。如果使用 Windows 下的 MSVC 编译器套装,则可用 cl 编译程序:
$ cl hello.cpp
这将产生一个名为 hello.exe 的可执行文件。
CUDA 中的 Hello World 程序
在复习了 C++ 语言中的 Hello World 程序之后,我们接着介绍 CUDA 中的 Hello World 程序。
只有主机函数的 CUDA 程序
其实,我们已经写好了一个 CUDA 中的 Hello World 程序。这是因为,CUDA 程序的编译器驱动(compiler driver)nvcc 支持编译纯粹的 C++ 代码。
一般来说,一个标准的 CUDA 程序中既有纯粹的 C++ 代码,也有不属于 C++ 的真正的 CUDA 代码。CUDA 程序的编译器
驱动 nvcc 在编译一个 CUDA 程序时,会将纯粹的 C++ 代码交给 C++ 的编译器(如前面提到的 g++ 或 cl)去处理,它自己则负责编译剩下的部分。CUDA 程序源文件的后缀名默认是 .cu,所以我们可以将上面写好的源文件更名为 hello1.cu,然后用 nvcc 编译:
$ nvcc hello1.cu
编译好之后即可运行。运行结果与 C++ 程序的运行结果一样。关于 CUDA 程序的编译过程,将在本章最后一节及后续的某些章节详细讨论,现在只要知道可以用 nvcc 编译 CUDA 程序即可。
使用核函数的 CUDA 程序
虽然上面的第一个版本是由 CUDA 的编译器编译的,但程序中根本没有使用 GPU。下面来介绍一个使用 GPU 的 Hello World 程序。
首先,我们要知道,GPU 只是一个设备,要它工作的话还需要有一个主机给它下达命令。这个主机就是 CPU。
所以,一个真正利用了 GPU 的 CUDA 程序既有主机代码(在程序 hello1.cu 中的所有代码都是主机代码),也有设备代码(可以理解为需要设备执行的代码)。
主机对设备的调用是通过核函数(kernel function)来实现的。所以,一个典型的、简单的 CUDA 程序的结构具有下面的形式:
int main(void)
{
主机代码
核函数的调用
主机代码
return 0;
}
CUDA 中的核函数与 C++ 中的函数是类似的,但一个显著的差别是:它必须被限定词(qualifier)global 修饰。
其中 global 前后是双下划线。另外,核函数的返回类型必须是空类型,即 void。
这两个要求读者先记住即可。关于核函数的更多细节,以后再逐步深入介绍。遵循这两个要求,我们先写一个打印字符串的核函数:
__global__ void hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
限定符 global 和 void 的次序可随意。也就是说,上述核函数也可以写为如下形式:
这里是引用
void __global__ hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
就像 C++ 语言中的函数要被调用才能发挥作用一样,这个核函数也要被调用才能发挥作用。
下面,我们就写一个主函数来调用这个核函数,得到如 Listing 2.2 所示的完整 CUDA 程序。我们可以用如下命令编译:
#include <stdio.h>
__global__ void hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
int main(void)
{
hello_from_gpu<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}
上述程序有 3 个地方需要进一步解释:
- • 先看看调用核函数的格式:
hello_from_gpu<<<1, 1>>>();
这个调用格式与普通的 C++ 函数的调用格式是有区别的。我们看到,在函数名 hello_from_gpu 和括号 () 之间有一对三括号 <<<1, 1>>>,里面还有用逗号隔开的两个数字。
调用核函数时为什么需要这对三括号里面的信息呢?
这是因为,一块 GPU 中有很多(例如,Tesla V100 中有 5120 个)计算核心,从而可以支持很多线程(thread)。主机在调用一个核函数时,必须指明需要在设备中指派多少个线程,不然设备不知道如何工作。
三括号中的数就是用来指明核函数中的线程数目以及排列情
况的。核函数中的线程常组织为若干线程块(thread block):
- 三括号中的第一个数字可以看作线程块的个数,
- 第二个数字可以看作每个线程块中的线程数。
一个核函数的全部线程块构成一个网格(grid),而线程块的个数就记为网格大小(grid size)。每个线程块中含有同样数目的线程,该数目称为线程块大小(block size)。
所以,核函数中总的线程数就等于网格大小乘以线程块大小,而三括号中的两个数字分别就是网格大小和线程块大小,即 <<<网格大小, 线程块大小>>>。
所以,在上述程序中,主机只指派了设备的一个线程,网格大小和线程块大小都是 1,即 1 × 1 = 1。
核函数中的 printf() 函数的使用方式和 C++ 库(或者说 C++ 从 C 中继承的库)中的 printf() 函数的使用方式基本上是一样的。
而且在核函数中使用 printf() 函数时也需要包含头文件 <stdio.h>(也可以写成 )。
需要注意的是,核函数中不支持 C++ 的 iostream(读者可亲自测试)。
我们注意到,在调用核函数之后,有如下一行语句:
cudaDeviceSynchronize();
这行语句调用了一个 CUDA 的运行时 API 函数。去掉这个函数就打印不出字符串了(请读者亲自尝试) 。
这是因为调用输出函数时,输出流是先存放在缓冲区的,而缓冲区不会自动刷新。只有程序遇到某种同步操作时缓冲区才会刷新。
函数 cudaDeviceSynchronize 的作用是同步主机与设备,所以能够促使缓冲区刷新。读者现在不需要弄明白这个函数到底是什么,因为我们这里的主要目的是介绍 CUDA 中的线程组织。
CUDA 中的线程组织
使用多个线程的核函数
核函数中允许指派很多线程,这是一个必然的特征。这是因为,一个 GPU 往往有几千个计算核心,而总的线程数必须至少等于计算核心数时才有可能充分利用 GPU 中的全部计算资源。
实际上,总的线程数大于计算核心数时才能更充分地利用 GPU 中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
所以,根据需要,在调用核函数时可以指定使用多个线程。Listing 2.3 所示程序在调用核函数 hello_from_gpu 时指定了一个含有两个线程块的网格,而且每个线程块的大小是 4。
1 #include <stdio.h>
2
3 __global__ void hello_from_gpu()
4 {
5 printf("Hello World from the GPU!\n");
6 }
7
8 int main(void)
9 {
10 hello_from_gpu<<<2, 4>>>();
11 cudaDeviceSynchronize();
12 return 0;
13 }
因为网格大小是 2,线程块大小是 4,故总的线程数是 2 × 4 = 8。也就是说,该程序中的核函数调用将指派 8 个线程。核函数中代码的执行方式是“单指令-多线程”,即每一个线程都执行同一串指令。既然核函数中的指令是打印一个字符串,那么编译、运行上述程序,将在屏幕打印如下 8 行同样的文字:
Hello World from the GPU!
其中,每一行对应一个指派的线程。读者也许要问,每一行分别是哪一个线程输出的呢?下面就来讨论这个问题。
使用线程索引
通过前面的介绍,我们知道,可以为一个核函数指派多个线程,而这些线程的组织结构是由执行配置(execution configuration)
<<<grid_size, block_size>>>
决定的。这里的 grid_size(网格大小)和 block_size(线程块大小)一般来说是一个结构体类型的变量,但也可以是一个普通的整型变量。我们先考虑简单的整型变量,稍后再介绍更一般的情形。
这两个整型变量的乘积就是被调用核函数中总的线程数。我们强调过,本书不关心古老的特斯拉架构和费米架构。从开普勒架构开始,最大允许的线程块大小是 1024,而最大允许的网格大小是 2^31 − 1(针对这里的一维网格来说;后面介绍的多维网格能够定义更多的线程块)。
所以,用上述简单的执行配置时最多可以指派大约两万亿个线程。这通常是远大于一般的编程问题中常用的线程数目的。一般来说,只要线程数比 GPU 中的计算核心数(几百至几千个)多几倍时,就有可能充分地利用 GPU 中的全部计算资源。
总之,一个核函数允许指派的线程数目是巨大的,能够满足几乎所有应用程序的要求。需要指出的是,一个核函数中虽然可以指派如此巨大数目的线程数,但在执行时能够同时活跃(不活跃的线程处于等待状态)的线程数是由硬件(主要是 CUDA 核心数)和软件(即核函数中的代码)决定的。
每个线程在核函数中都有一个唯一的身份标识。由于我们用两个参数指定了线程数目,那么自然地,每个线程的身份可由两个参数确定。在核函数内部,程序是知道执行配置参数 grid_size 和 block_size 的值的。这两个值分别保存于如下两个内建变量(built-in variable):
- • gridDim.x:该变量的数值等于执行配置中变量 grid_size 的数值。
- • blockDim.x:该变量的数值等于执行配置中变量 block_size 的数值。
类似地,在核函数中预定义了如下标识线程的内建变量:
- • blockIdx.x:该变量指定一个线程在一个网格中的线程块指标,其取值范围是从 0到 gridDim.x - 1。
- • threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从 0到 blockDim.x - 1 。
举一个具体的例子。假如某个核函数的执行配置是 <<<10000, 256>>>,那么网格大小 gridDim.x 的值为 10000,线程块大小 blockDim.x 的值为 256。
线程块指标 blockIdx.x可以取 0 到 9999 之间的值,而每一个线程块中的线程指标 threadIdx.x 可以取 0 到 255 之间的值。
当 blockIdx.x 等于 0 时,所有 256 个 threadIdx.x 的值对应第 0 个线程块;
当 blockIdx.x 等于 1 时,所有 256 个 threadIdx.x 的值对应于第 1 个线程块;依此类推。
再次回到 Hello World 程序。在程序 hello3.cu 中,我们指派了 8 个线程,每个线程输出了一行文字,但我们不知道哪一行是由哪个线程输出的。既然每一个线程都有一个唯一的身份标识,那么我们就可以利用该身份标识判断哪一行是由哪个线程输出的。为此,我们将程序改写为 Listing 2.4。
1 #include <stdio.h>
2
3 __global__ void hello_from_gpu()
4 {
5 const int bid = blockIdx.x;
6 const int tid = threadIdx.x;
7 printf("Hello World from block %d and thread %d!\n", bid, tid);
8 }
9
10 int main(void)
11 {
12 hello_from_gpu<<<2, 4>>>();
13 cudaDeviceSynchronize();
14 return 0;
15 }
编译、运行这个程序,有时输出如下文字:
Hello World from block 1 and thread 0.
Hello World from block 1 and thread 1.
Hello World from block 1 and thread 2.
Hello World from block 1 and thread 3.
Hello World from block 0 and thread 0.
Hello World from block 0 and thread 1.
Hello World from block 0 and thread 2.
Hello World from block 0 and thread 3.
有时输出如下文字:
Hello World from block 0 and thread 0.
Hello World from block 0 and thread 1.
Hello World from block 0 and thread 2.
Hello World from block 0 and thread 3.
Hello World from block 1 and thread 0.
Hello World from block 1 and thread 1.
Hello World from block 1 and thread 2.
Hello World from block 1 and thread 3.
也就是说,有时是第 0 个线程块先完成计算,有时是第 1 个线程块先完成计算。这反映了CUDA 程序执行时的一个很重要的特征,即每个线程块的计算是相互独立的。
不管完成计算的次序如何,每个线程块中的每个线程都进行一次计算。
推广至多维网格
细心的读者可能注意到,前面介绍的 4 个内建变量都用了 C++ 中的结构体(struct)或者类(class)的成员变量的语法。其中:
• blockIdx 和 threadIdx 是类型为 uint3 的变量。该类型是一个结构体,具有 x、y、z 这 3 个成员。所以,blockIdx.x 只是 3 个成员中的一个,另外两个成员分别是 blockIdx.y 和 blockIdx.z。
类似地,threadIdx.x 只是 3 个成员中的一个,另外两个成员分别是 threadIdx.y 和 threadIdx.z。结构体 uint3 在头文 件 vector_types.h 中定义:
struct __device_builtin__ uint3
{
unsigned int x, y, z;
};
typedef device_builtin struct uint3 uint3;
也就是说,该结构体由 3 个无符号整数类型的成员构成。
• gridDim 和 blockDim 是类型为 dim3 的变量。该类型是一个结构体,具有 x、y、z 这 3 个成员。所以, gridDim.x 只是 3 个成员中的一个,另外两个成员分别是 gridDim.y 和 gridDim.z。
类似地,blockDim.x 只是 3 个成员中的一个,另外两个成员分别是 blockDim.y 和 blockDim.z。结构体 dim3 也在头文件 vector_types.h 定义,除了和结构体 uint3 有同样的 3 个成员之外,还在使用 C++ 程序的情况下定义了一些成员函数,如下面使用的构造函数。
这些内建变量都只在核函数中有效(可见),而且满足如下关系:
• blockIdx.x 的取值范围是从 0 到 gridDim.x - 1。
• blockIdx.y 的取值范围是从 0 到 gridDim.y - 1。
• blockIdx.z 的取值范围是从 0 到 gridDim.z - 1。
• threadIdx.x 的取值范围是从 0 到 blockDim.x - 1 。
• threadIdx.y 的取值范围是从 0 到 blockDim.y - 1 。
• threadIdx.z 的取值范围是从 0 到 blockDim.z - 1 。
我们前面介绍过,网格大小和线程块大小是在调用核函数时通过执行配置指定的。在之前的例子中,我们用的执行配置仅仅用了两个整数:
<<<grid_size, block_size>>>
我们知道,这两个整数的值将分别赋给内建变量 gridDim.x 和 blockDim.x。此时,gridDim和 blockDim 中没有被指定的成员取默认值 1。在这种情况下,网格和线程块实际上都是“一维”的。
也可以用结构体 dim3 定义“多维”的网格和线程块(这里用了 C++ 中构造函数的语法):
dim3 grid_size(Gx, Gy, Gz);
dim3 block_size(Bx, By, Bz);
如果第三个维度的大小是 1,可以写
dim3 grid_size(Gx, Gy);
dim3 block_size(Bx, By);
例如,如果要定义一个 2 × 2 × 1 的网格及 3 × 2 × 1 的线程块,可将执行配置中的 grid_size 和 block_size 分别定义为如下结构体变量:
dim3 grid_size(2, 2); // 等价于 dim3 grid_size(2, 2, 1);
dim3 block_size(3, 2); // 等价于 dim3 block_size(3, 2, 1);
由此产生的核函数中的线程组织见图 2.1。
多维的网格和线程块本质上还是一维的,就像多维数组本质上也是一维数组一样。与一个多维线程指标 threadIdx.x、 threadIdx.y、 threadIdx.z 对应的一维指标为
int tid = threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
也就是说,x 维度是最内层的(变化最快),而 z 维度是最外层的(变化最慢)。
与一个多维线程块指标 blockIdx.x、blockIdx.y、blockIdx.z 对应的一维指标没有唯一的定义(主要是因为各个线程块的执行是相互独立的),但也可以类似地定义:
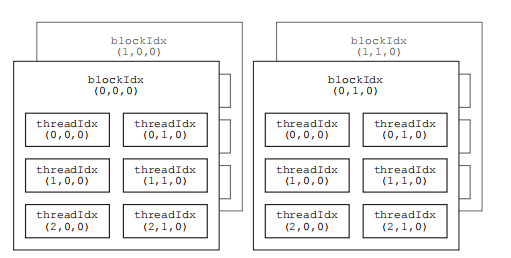
图 2.1: CUDA 核函数中的线程组织示意图。在执行一个核函数时,会产生一个网格,由多个相同大小的线程块构成。该图中展示的是有 2 × 2 × 1 个线程块的网格,其中每个线程块包含 3 × 2 × 1 个线程。
int bid = blockIdx.z * gridDim.x * gridDim.y +blockIdx.y * gridDim.x + blockIdx.x;
对于有些问题,如第 7 章引入的矩阵转置问题,有时使用如下复合线程索引更合适:
int nx = blockDim.x * blockIdx.x + threadIdx.x;
int ny = blockDim.y * blockIdx.y + threadIdx.y;
int nz = blockDim.z * blockIdx.z + threadIdx.z;
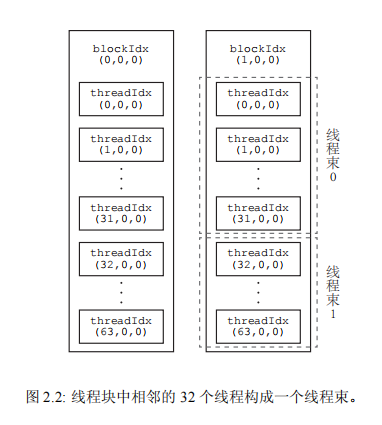
一个线程块中的线程还可以细分为不同的线程束(thread warp)。一个线程束(即一束线程)是同一个线程块中相邻的 warpSize 个线程。warpSize 也是一个内建变量,表示线程束大小,其值对于目前所有的 GPU 架构都是 32。所以,一个线程束就是连续的 32 个线程。
具体地说,一个线程块中第 0 到第 31 个线程属于第 0 个线程束,第 32 到第 63 个线程属于第 1 个线程束,依此类推。图 2.2 中展示的每个线程块拥有两个线程束。
我们可以通过继续修改 Hello World 程序来展示使用多维线程块的核函数中的线程组织情况。Listing 2.5 是修改后的代码,在调用核函数时指定了一个 2 × 4 的两维线程块。程序的输出是:
Hello World from block-0 and thread-(0, 0)!
Hello World from block-0 and thread-(1, 0)!
Hello World from block-0 and thread-(0, 1)!
Hello World from block-0 and thread-(1, 1)!
Hello World from block-0 and thread-(0, 2)!
Hello World from block-0 and thread-(1, 2)!
Hello World from block-0 and thread-(0, 3)!
Hello World from block-0 and thread-(1, 3)!
1 #include <stdio.h>
2
3 __global__ void hello_from_gpu()
4 {
5 const int b = blockIdx.x;
6 const int tx = threadIdx.x;
7 const int ty = threadIdx.y;
8 printf("Hello World from block-%d and thread-(%d, %d)!\n", b, tx,
ty);
9 }
10
11 int main(void)
12 {
13 const dim3 block_size(2, 4);
14 hello_from_gpu<<<1, block_size>>>();
15 cudaDeviceSynchronize();
16 return 0;
17 }
因为线程块的大小是 2 × 4,所以我们知道在核函数中,blockDim.x 的值为 2,blockDim.y 的值为 4。可以看到,threadIdx.x 的取值范围是从 0 到 1,而 threadIdx.y的取值范围是从 0 到 3。
另外,因为网格大小 gridDim.x 是 1,故核函数中 blockIdx.x 的值只能为 0。
最后,从输出结果可以确认,x 维度的线程指标 threadIdx.x 是最内层的(变化最快)。
网格与线程块大小的限制
CUDA 中对能够定义的网格大小和线程块大小做了限制。对任何从开普勒到图灵架构的 GPU 来说,网格大小在 x、y 和 z 这 3 个方向的最大允许值分别为 2^31−1、65535 和 65535;
线程块大小在 x、y 和 z 这 3 个方向的最大允许值分别为 1024、1024 和 64。
另外还要求线程块总的大小,即blockDim.x、blockDim.y 和 blockDim.z 的乘积不能大于 1024。
也就是说,不管如何定义,一个线程块最多只能有 1024 个线程。这些限制是必须牢记的。
CUDA 中的头文件
我们知道,在编写 C++ 程序时,往往需要在源文件中包含一些标准的头文件。读者也许注意到了,本章程序包含了 C++ 的头文件 <stdio.h>,但并没有包含任何 CUDA 相关的头文件。
CUDA 中也有一些头文件,但是在使用 nvcc 编译器驱动编译 .cu 文件时,将自动包含必要的 CUDA 头文件,如 <cuda.h> 和 <cuda_runtime.h>。
因为 <cuda.h> 包含了 <stdlib.h>,故用 nvcc 编译 CUDA 程序时甚至不需要在 .cu 文件中包含 <stdlib.h>。
当然,用户依然可以在 .cu 文件中包含 <stdlib.h>,因为(正确编写的)头文件不会在一个编译单元内被包含多次。本书会从第 4 章开始使用一个用户自定义头文件。
在本书第 14 章我们将看到,在使用一些利用 CUDA 进行加速的应用程序库时,需要包含一些必要的头文件,并有可能还需要指定链接选项。
用 nvcc 编译 CUDA 程序
CUDA 的编译器驱动(compiler driver)nvcc 先将全部源代码分离为主机代码和设备代码。主机代码完整地支持 C++ 语法,但设备代码只部分地支持 C++。nvcc 先将设备代码编译为 PTX(Parallel Thread eXecution)伪汇编代码,再将 PTX 代码编译为二进制的 cubin 目标代码。在将源代码编译为 PTX 代码时,需要用选项 -arch=compute_XY 指定一个虚拟架构的计算能力,用以确定代码中能够使用的 CUDA 功能。
在将 PTX 代码编译为 cubin 代码时,需要用选项 -code=sm_ZW 指定一个真实架构的计算能力,用以确定可执行文件能够使用的 GPU。真实架构的计算能力必须等于或者大于虚拟架构的计算能力。例如,可以用选项
-arch=compute_35 -code=sm_60
编译,但不能用选项
-arch=compute_60 -code=sm_35
编译(编译器会报错)。如果仅仅针对一个 GPU 编译程序,一般情况下建议将以上两个计算能力都选为所用 GPU 的计算能力。
用以上的方式编译出来的可执行文件只能在少数几个 GPU 中才能运行。选项 -code=sm_ZW 指定了 GPU 的真实架构为 Z.W。对应的可执行文件只能在主版本号为 Z、次版本号大于或等于 W 的 GPU 中运行。举例来说,由编译选项
-arch=compute_35 -code=sm_35
编译出来的可执行文件只能在计算能力为 3.5 和 3.7 的 GPU 中执行,而由编译选项
-arch=compute_35 -code=sm_60
编译出来的可执行文件只能在所有帕斯卡架构的 GPU 中执行。
如果希望编译出来的可执行文件能够在更多的 GPU 中执行,可以同时指定多组计算能力,每一组用如下形式的编译选项:
-gencode arch=compute_XY,code=sm_ZW
例如,用选项
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=sm_60
-gencode arch=compute_70,code=sm_70
编译出来的可执行文件将包含 4 个二进制版本,分别对应开普勒架构(不包含比较老的 3.0 和 3.2 的计算能力)、麦克斯韦架构、帕斯卡架构和伏特架构。
这样的可执行文件称为胖二进制文件(fatbinary)。在不同架构的 GPU 中运行时会自动选择对应的二进制版本。需要注意的是,上述编译选项假定所使用的 CUDA 版本支持 7.0 的计算能力,也就是说至少是 CUDA 9.0。如果在编译选项中指定了不被支持的计算能力,编译器会报错。
另外需要注意的是,过多地指定计算能力,会增加编译时间和可执行文件的大小。
nvcc 有一种称为即时编译(just-in-time compilation)的机制,可以在运行可执行文件时从其中保留的 PTX 代码临时编译出一个 cubin 目标代码。
要在可执行文件中保留(或者说嵌入)一个这样的 PTX 代码,就必须用如下方式指定所保留 PTX 代码的虚拟架构:
-gencode arch=compute_XY,code=compute_XY
这里的两个计算能力都是虚拟架构的计算能力,必须完全一致。例如,假如我们处于只有 CUDA 8.0 的年代(不支持伏特架构),但希望编译出的二进制版本适用于尽可能多的 GPU,则可以用如下的编译选项:
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=sm_60
-gencode arch=compute_60,code=compute_60
其中,前三行的选项分别对应 3 个真实架构的 cubin 目标代码,第四行的选项对应保留的 PTX 代码。
这样编译出来的可执行文件可以直接在伏特架构的 GPU 中运行,只不过不一定能充分利用伏特架构的硬件功能。在伏特架构的 GPU 中运行时,会根据虚拟架构为 6.0 的 PTX 代码即时地编译出一个适用于当前 GPU 的目标代码。
在学习 CUDA 编程时,有一个简化的编译选项可以使用:
-arch=sm_XY
它等价于
-gencode arch=compute_XY,code=sm_XY
-gencode arch=compute_XY,code=compute_XY
例如,在作者的装有 GeForce RTX 2070 的计算机中,可以用选项 -arch=sm_75 编译一个 CUDA 程序。
读者也许注意到了,本章的程序在编译时并没有通过编译选项指定计算能力。这是因为编译器有一个默认的计算能力。以下是各个 CUDA 版本中的编译器在编译 CUDA 代码时默认的计算能力:
• CUDA 6.0 及更早的:默认的计算能力是 1.0。
• CUDA 6.5 到 CUDA 8.0:默认的计算能力是 2.0。
• CUDA 9.0 到 CUDA 10.2:默认的计算能力是 3.0。
作者所用的 CUDA 版本是 10.1,故本章的程序在编译时实际上使用了 3.0 的计算能力。
如果用 CUDA 6.0 进行编译,而且不指定一个计算能力,则会使用默认的 1.0 的计算能力。此时本章的程序将无法正确地编译,因为从 GPU 中直接向屏幕打印信息是从计算能力 2.0 才开始支持的功能。正如在第 1 章强调过的,本书中的所有示例程序都可以在 CUDA 9.0-10.2 中进行测试。
关于 nvcc 编译器驱动更多的介绍,请参考如下官方文档:https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc
内容来自:CUDA 编程:基础与实践_樊哲勇 著






![latex中\documentclass[preprint,review,12pt]{elsarticle}的详细解释](https://img-blog.csdnimg.cn/direct/4869b2982ac541b7a6cf924d26a3baae.png)



![[数据结构]栈](https://img-blog.csdnimg.cn/direct/e633ad0f8bda4bcf9a7ba0081babe7f6.png)

