以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏
文章目录
- 偏差与方差
- 高偏差
- 高方差
- 合适的模型
- 理解偏差与方差
- 总结
当你构建神经网络的时候,几乎没有人能够在一开始就将神经系统构建得十分完美。因此构建神经网络最重要的是直到你下一步需要做什么来提高你模型的表现。其中,通过查看**偏差(bias)与方差(variance)**就是一种很好的手段。让我们看看该怎么做。
偏差与方差
在这个专栏开始的章节中,我们曾经在房价预测的例子中使用线性拟合,但效果不好,我们称这个算法有很高的偏差(High Bias),即欠拟合(underfit)。之后我们也用过四阶多项式来进行拟合,但是效果也不好,我们称这种算法有很高的方差(High variance),即过拟合(overfit)。最后我们发现,二阶多项式的拟合效果最佳,我们称之为Just Right。因为这是个单特征问题,我们可以通过画图来理解:

但是如果我们面对的是多特征模型,我们就不能通过画图来判断拟合程度是否良好了。因此,我们需要一种更加系统的,通用的方法来定义模型的拟合程度;我们可以在训练集和交叉验证集的性能来判断偏差与方差的大小。
高偏差
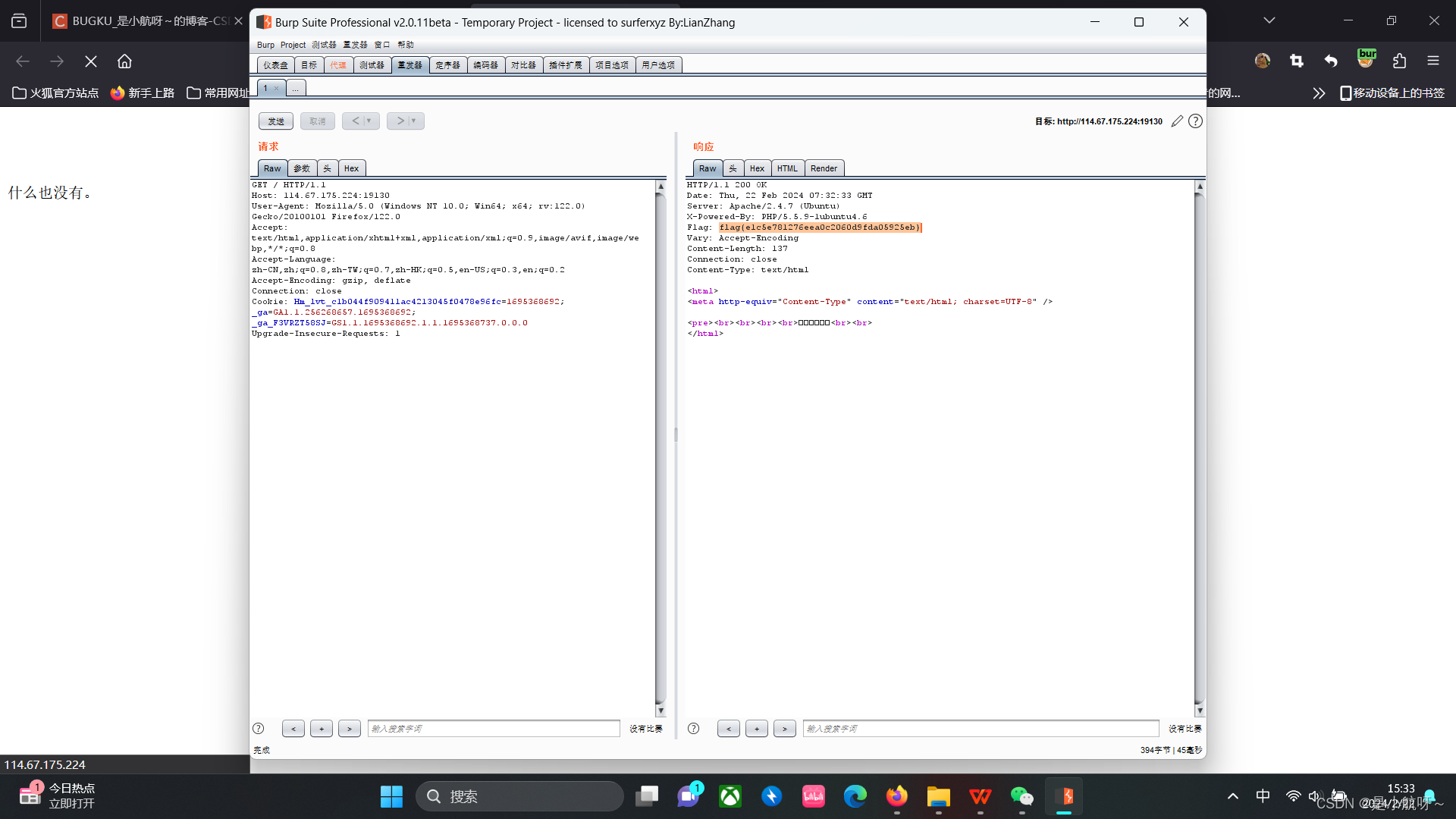
例如我们就看最左边这个图,如果我们想要计算
J
t
r
a
i
n
J_{train}
Jtrain,该算法在训练集上的表现如何,那么我估计你算出的
J
t
r
a
i
n
J_{train}
Jtrain会很高,这很显然。
那么
J
c
v
J_{cv}
Jcv呢,
J
c
v
J_{cv}
Jcv和
J
t
r
a
i
n
J_{train}
Jtrain的公式一样,只是数据换成了一些新的数据点:

那么很显然,连训练集的代价函数都很高,那么交叉验证集也一样很高。
高偏差的函数的一个典型特征就是模型在训练集的效果都不是很好,即
J
t
r
a
i
n
J_{train}
Jtrain就很大,那么就可以说明这个模型为高偏差。
高方差
再看看右边的图,它的代价函数的特点是,
J
t
r
a
i
n
J_{train}
Jtrain很小(毕竟拟合程度很高),但是
J
c
v
J_{cv}
Jcv很大,这是由于过拟合的特点就是泛化能力较弱。

那么就可以总结出来了,高方差的特点是
J
c
v
J_{cv}
Jcv远大于
J
t
r
a
i
n
J_{train}
Jtrain
合适的模型
最后,再看看中间的图,这算是拟合效果很好的了。由于其拟合程度比较合适,很容易看出它的
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv都比较小,那么这个模型就算是比较合适的了。

理解偏差与方差
我们再从另一个角度考虑下这个问题。在上文的例子之中,我们可以看出,随着特征维度d的升高,拟合程度逐渐上升,
J
t
r
a
i
n
J_{train}
Jtrain逐渐降低,而
J
c
v
J_{cv}
Jcv先下降后上升,我们可以画出d和j的关系图:

所以我们一般选择的点就是图中箭头的这种,从而能够使得J_train和J_cv都保持在一个较低的水准,从而提高了模型的效果。
另外补充一种更加糟糕的情况,那就是一看你发现训练集的代价函数很大,但然后你发现交叉验证集的代价函数甚至比训练集还要大。出现这种情况一种比较常见的原因是你的模型过于复杂,使得模型在前几个数据就已经过拟合了,无法拟合训练集后面的数据,因此导致了训练集的大偏差。而在交叉验证集由于数据全是全新的,对于前几个数据也无法很好地拟合,因此导致了比偏差还要大的方差。

总结
虽然上面讲了很多种不同的效果不佳,但是最重要的是要记住高偏差是在训练集的效果不好,高方差是在验证集的效果不好。观察偏差和方差是改善模型的一个重要手段。下节博客我们将详细讲讲正则化是如何影响方差与偏差的,这将帮助你更好地使用正则化的方法来改善模型。
为了给读者你造成不必要的麻烦,博主的所有视频都没开仅粉丝可见,如果想要阅读我的其他博客,可以点个小小的关注哦。