本系列是基于OcenaBase 开发工程师在工作中的一些诊断经验,也欢迎大家分享相关经验。
1. 关于神医的故事
扁鹊,中国古代第一个被正史记载的医生,他的成才之路非常传奇。年轻时,扁鹊是一家客栈的主管。有一位名叫长桑君的客人来到客栈,只有扁鹊看出他是一个不凡之人,对他非常恭敬。长桑君也知道扁鹊不同凡人,十多年里,他在客栈来来去去。有一天,长桑君请扁鹊和他坐在一起,悄声告诉他:“我有秘传的医术,但我年事已高,想传授给你,你不要外传。”扁鹊答应了他,长桑君便将这些秘传的医术传授给了扁鹊,然后便消失了。从此,扁鹊就像是得到了神仙的点拨一般,打通了“任督二脉”,短短三十天内就成为了绝世神医。而扁鹊之所以能成为一代神医,最重要的一点就是长桑君的那本秘籍。由此可见,要想成为OceanBase数据库的“神医”并成功诊断OceanBase数据库,也需要一份秘籍。今天我将详细揭秘在大部分场景下,诊断OceanBase故障的秘籍是什么?
2. OceanBase诊断秘籍
大部分场景下OceanBase的问题都可以通过以下的三板斧:环境分析、日志分析、性能视图分析来定位和分析问题。所以我们的秘籍总结起来如下:
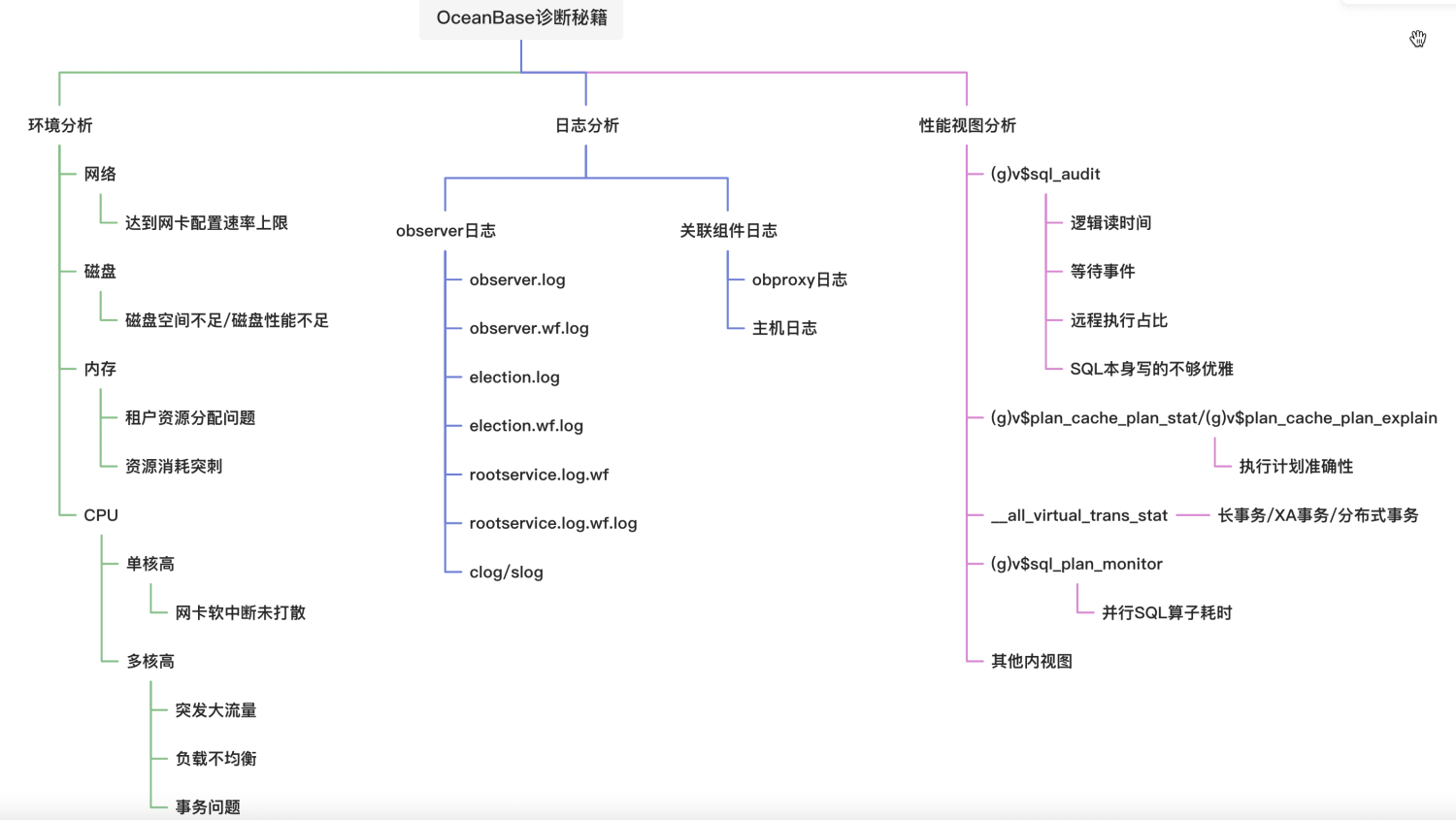
环境问题的分析和其他系统并无区别,主要是去分析一下网络、磁盘、内存、CPU等信息,本文接下来的章节不做细致展开。文章会从日志分析和性能视图分析做展开,带你一览OceanBase诊断的秘籍。
2.1. 日志分析
2.1.1. 日志概述
日志分析中最重要的就是OceanBase本身的日志。OceanBase 数据库日志模块所属的日志文件分为 observer.log 、election.log和 rootservice.log 三种类型,默认打印 INFO 级别以上的日志。每类日志文件自动生成一个带有 .wf 后缀的 WARNING 日志文件( observer.log.wf、election.log.wf 、rootservice.log.wf ),只打印了 WARN 级别以上的日志。
| 日志名称 | 日志路径 |
| 启动和运行日志( observer.log 、observer.log.wf ) | OBServer 服务器的 $work_dir/log 目录下。 |
| 选举模块日志( election.log 、election.log.wf ) | OBServer 服务器的 $work_dir/log 目录下。 |
| RootService 日志( rootservice.log 、rootservice.log.wf ) | OBServer 服务器的 $work_dir/log 目录下。 |
OceanBase 数据库日志划分了六个日志级别,含义如下表所示。表中的日志级别从高到低依次排列。
| 日志级别 | 含义 |
| ERROR | 严重错误。用于记录系统的故障信息,且必须进行故障排除,否则系统不可用。 |
| USER_ERROR | 用户输入导致的错误。 |
| WARN | 警告。用于记录可能会出现的潜在错误。 |
| INFO | 提示。用于记录系统运行的当前状态,该信息为正常信息。 |
| TRACE | 与 INFO 相比更细致化地记录事件消息。 |
| DEBUG | 调试信息。用于调试时更详细地了解系统运行状态,包括当前调用的函数名、参数、变量、函数调用返回值等。 |
2.1.2. 日志格式
日志数据格式如下,具体格式以实际情况为准。
- [time] log_level [module_name] (file_name:fine_no) [thread_id][Y_trace_id0-trace_id1] [lt=last_log_print_time] [dc=dropped_log_count] log_data_
- [time] log_level [module_name] function_name (file_name:fine_no) [thread_id][Y_trace_id0-trace_id1] [lt=last_log_print_time] [``dc=``dropped_log_count] log_data_
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 observer.log
[2016-07-17 14:18:04.845802] INFO [RPC.OBMYSQL] obsm_handler.cpp:191 [9543][Y0-0] [lt=47] [dc=0] connection close(easy_connection_str(c)="192.168.0.2:56854_-1_0x7fb8a9171b68", version=0, sessid=2147562562, tenant_id=1, server_id=1, is_need_clear_sessid_=true, ret=0)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 observer.log.wf
[2016-07-17 14:18:28.431351] WARN [SQL.SESSION] set_conn (ob_basic_session_info.cpp:2568) [8541][YB420AF4005E-52A8CF4E] [lt=16] [dc=0] debug for set_conn(conn=0x7fb8a9171b68, lbt()="0x4efe71 0x818afd 0xe9ea5b 0x721fc8 0x13747bc 0x2636db0 0x2637d68 0x5054e9 0x7fb98705aaa1 0x7fb9852cc93d ", magic_num_=324478056, sessid_=2147562617, version_=0)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 rootservice.log
[2016-07-17 14:18:53.701463] INFO [RS] ob_server_table_operator.cpp:345 [8564][Y0-0] [lt=11] [dc=0] svr_status(svr_status="active", display_status=1)
[admin@OceanBase000000000.sqa.ztt /home/admin/oceanbase/log]
$tail -f -n 1 rootservice.log.wf
[2016-07-16 02:02:12.847602] WARN [RS] choose_leader (ob_leader_coordinator.cpp:2067) [8570][YB420AF4005E-4626EDFC] [lt=8] [dc=0] choose leader info with not same candidate num(tenant_id=1005, server="192.168.0.1:2882", info={original_leader_count:0, primary_zone_count:0, cur_leader_count:1, candidate_count:1, in_normal_unit_count:1})
2.1.3. 日志诊断秘籍
关注日志信息,尤其是错误日志信息,根据OceanBase的日志模型建立日志收集告警机制。
2.1.4. 日志诊断例子



2.2. 性能视图分析
2.2.1. gv$sql_audit
OceanBase在SQL性能诊断方面有个很有用的功能叫SQL审计视图(OceanBase 4.0 版本以前是gv$sql_audit,OceanBase 4.0以后是gv$ob_sql_audit,下文均以为OB 4.0版本以前为例,不再做特别说明)。该视图可以方便开发运维排查在OceanBase运行过的任意一条SQL,不管这些SQL是成功还是失败,都有详细的运行信息记录。GV$SQL_AUDIT 的含义是查出每一台机器上的 SQL_AUDIT 记录,而 V$SQL_AUDIT 是查出连接的这台server的SQL_AUDIT 记录。如果是查询 V$SQL_AUDIT ,无法确定请求会被路由到哪一台机器上。所以如果想查询某一台机器上的SQL_AUDIT记录,一定要直连到要这台机器,或者查询 GV$SQL_AUDIT 然后通过指定机器的 IP 与端口号来访问具体机器的记录。详细的字段解释可以参阅官网文档。
几点注意事项:
- SQL_AUDIT 是维护在内存中的,因此它的数据不可能无限地存放。所以当内存到达一定限制的时候,会触发一些淘汰机制,以保证新的记录能够写进去。SQL_AUDIT 采用先进先出的自动淘汰机制,内存到达高水位线(90%)的时候会自动触发淘汰,直至内存达到低水位线(50%)。
- 除了基于内存水位线的淘汰,SQL_AUDIT 还有一个淘汰策略,当 SQL_AUDIT 的记录达到 900 万条的时候会触发淘汰,一直淘汰到记录剩 500 万条为止。
- 此外,SQL_AUDIT 提供了一个集群级的配置项 enable_sql_audit 和一个租户级的配置项 ob_enable_sql_audit,只有这两个配置项都为 true 的时候,SQL_AUDIT 才会生效,否则为关闭状态。
2.2.2. 性能视图诊断案例
Case 1: 如何查看集群 SQL 的请求量是否均匀?
Action: 可以去查 SQL_AUDIT,找出某个时间段内所有执行的用户 SQL, 然后在 server IP 的维度上做聚合,最后求出每一个 server IP 的分组里面,此时间段内有多少 SQL ,就可以大概得出每一个 server 上的流量。
select/*+ parallel(15)*/t2.zone, t1.svr_ip, count(*) as QPS, avg(t1.elapsed_time), avg(t1.queue_time)
from oceanbase.gv$sql_audit t1, __all_server t2
where t1.svr_ip = t2.svr_ip and IS_EXECUTOR_RPC = 0
and request_time > (time_to_usec(now()) - 1000000)
and request_time < time_to_usec(now())
group by t1.svr_ip
order by t2.zone;Case 2: 如何找到消耗 CPU 最多的 SQL 。
Action: 首先查出某一个时间段内所有执行的用户 SQL, 然后在 SQL_ID 维度上做聚合,求出每一个 SQL_ID 总的执行时间。这里的执行时间 = ELAPSED_TIME - QUEUE_TIME ,因为在队列里等待的时间并没有消耗 CPU ,实际消耗 CPU 的就是获取和执行计划的时间。最终可以基于这些消耗 CPU 最多的 SQL 做一些性能分析、性能调优之类的工作。
Case 3:如何分析 RT 突然抖动的 SQL
Action:在此场景下,可以在抖动出现后立即将 SQL_AUDIT 关闭,保证产生抖动的 SQL 能够在 SQL_AUDIT 中使用 (g)v$sql_audit 进行问题排查方式如下:
- 在线上如果出现 RT 抖动,但 RT 并不是持续很高的情况,可以考虑在抖动出现后,立刻将 sql_audit 关闭 (alter system set ob_enable_sql_audit = 0),从而确保该抖动的 SQL 请求在 sql_audit 中存在。
- 通过 SQL Audit 查询抖动附近那段时间 RT 的 TOP N 请求,分析有异常的 SQL。
- 找到对应的 RT 异常请求,则可以分析该请求在 sql_audit 中的记录进行问题排查:
- 查看 retry 次数是否很多(RETRY_CNT 字段),如果次数很多,则可能有锁冲突或切主等情况。
- 查看 queue time 的值是否过大(QUEUE_TIME 字段)。
- 查看获取执行计划时间(GET_PLAN_TIME 字段),如果时间很长,一般会出现 IS_HIT_PLAN = 0,表示没有命中 plan cache。
- 查看 EXECUTE_TIME 的值,如果值过大,则可以通过以下步骤进行排查:
a. 查看是否有很长等待事件耗时。
b. 分析逻辑读次数是否异常多(突然有大账户时可能会出现)。
逻辑读次数 = 2 * ROW_CACHE_HIT
+ 2 * BLOOM_FILTER_CACHE_HIT
+ BLOCK_INDEX_CACHE_HIT
+ BLOCK_CACHE_HIT + DISK_READS如果在 SQL Audit 中 RT 抖动的请求数据已被淘汰,则需要查看 OBServer 中抖动时间点是否有慢查询的 trace 日志,并分析对应的 trace 日志。
3. 一个愿景
OceanBase是原生分布式数据库系统,故障根因分析通常是比较繁琐的,因为涉及的因素可能有很多,如机器环境、配置参数、运行负载等等。所以我们的愿景是:让诊断OceanBase变得更快更容易。
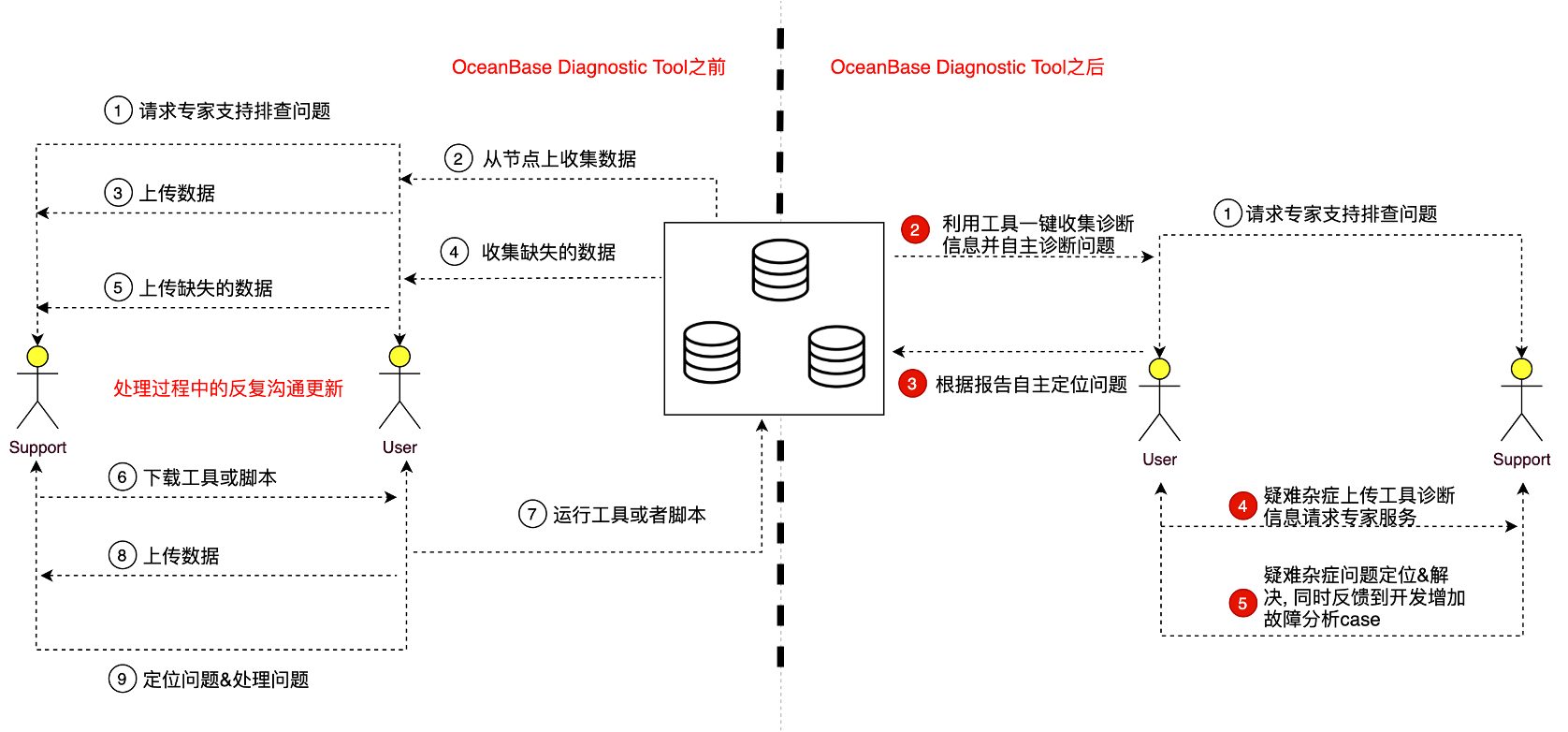
4. 一个工具箱
4.1. 特性介绍
OceanBase是原生分布式数据库系统,故障根因分析通常是比较繁琐的,因为涉及的因素可能有很多,如机器环境、配置参数、运行负载等等。专家在排查问题的时候需要获取大量的信息来分析故障,如何高效的获取故障场景下分散在各个节点的信息,挖掘出其中的关联性便是OceanBase敏捷诊断工具(OceanBase Diagnostic Tool) ,简称obdiag。需要解决的问题。
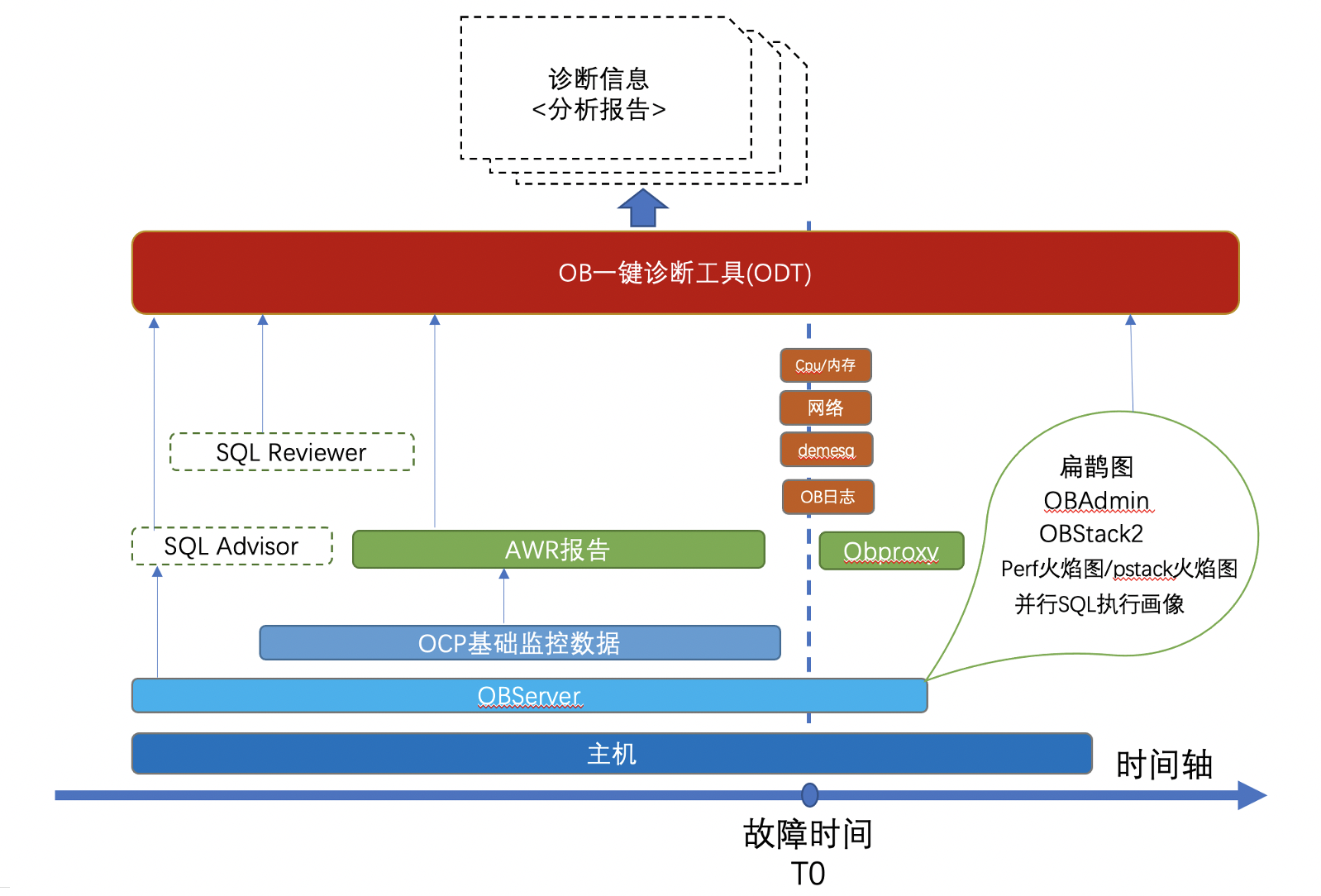
obdiag定位为OceanBase敏捷诊断工具。整体使用上备以下的特点:
- 部署简单:提供rpm包和OBD上部署的模式,均可一键部署安装,可以选择部署到任意一台能连接到集群各个节点的上,并不局限于OBServer节点。
- 开箱即用:使用中所依赖的python包,全部都是自包含的,只需要部署机器存在python2或者python3环境即可;
- 集中式收集:单点部署,无需每台服务器部署。使用的时候只需要在部署机器上执行收集或分析命令即可;
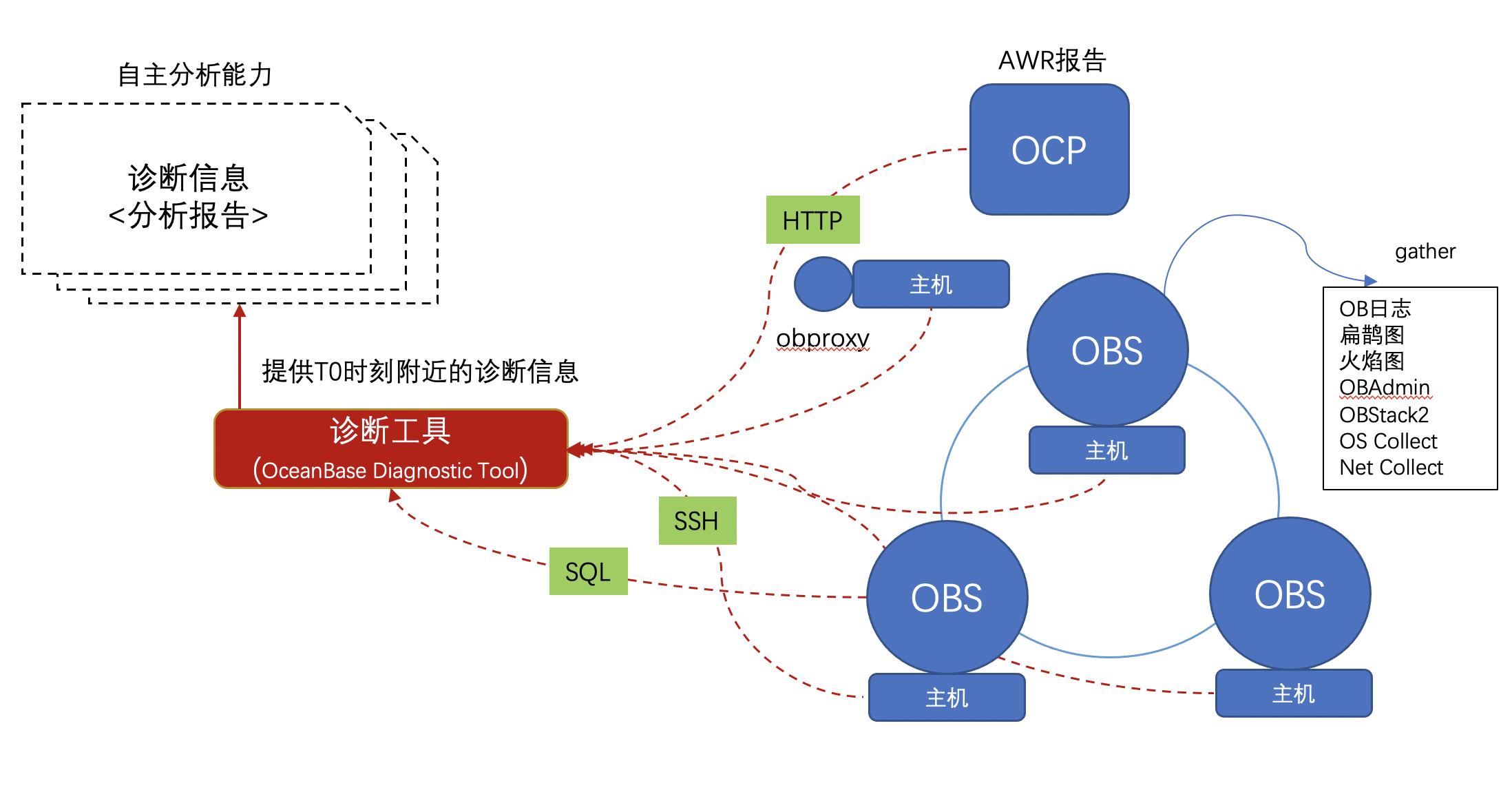
obdiag现有功能包含了对于OceanBase日志、SQL Audit以及OceanBase进程堆栈等信息进行的扫描、收集,可以在OceanBase集群不同的部署模式下(OCP,OBD或用户根据文档手工部署)实现一键执行。未来会加入诊断分析能力。一方面在现有采集能力的基础上增加有效信息提取分析的能力形成诊断分析报告;另一方面将已有的SQL Reviewer(OceanBase的SQL审核工具)和SQL Diagnoser(OceanBase的敏捷SQL诊断工具)进行整合,扩展工具在SQL层面的诊断能力。
obdiag-1.2.0版本支持以下功能:
- 一键收集OB日志
- 一键收集AWR报告
- 一键收集主机信息
- 一键收集OB堆栈信息
- 一键收集(clog、slog解析后的日志)
- 一键收集perf信息(扁鹊图、perf火焰图、pstack火焰图)
- 一键收集并行SQL的执行详情信息
- 一键收集OBPROXY的日志
待解锁功能(敬请期待): - 集成SQL Reviewer/SQL Diagnoser能力,支持一键分析SQL问题。
- 在诊断信息采集的基础上加入自主分析能力,支持生成诊断信息分析报告
- 抽取OceanBase常见问题,形成快速诊断套餐
4.2. OBD模式下安装使用obdiag
如果你的OceanBase集群是通过OBD安装部署的,并且OBD的版本大于2.1.0那么,你可以直接通过下面的方式使用。
4.2.1. 安装
- 安装OBD 2.1.0 及以上版本
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/oceanbase/OceanBase.repo
sudo yum install -y ob-deploy
source /etc/profile.d/obd.sh
- 安装obdiag工具
使用该命令可部署obdiag工具可在本机安装部署obdiag, (如果用户不安装直接使用也会走自动安装流程)
obd obdiag deploy4.2.2. 使用
4.2.2.1. obd obdiag gather
使用该命令可调用obdiag工具进行OceanBase相关的诊断信息收集
obd obdiag gather <gather type> <deploy name> [options]gather type包含:
- log:一键收集所属OceanBase集群的日志
- sysstat:一键收集所属OceanBase集群主机信息
- clog:一键收集所属OceanBase集群(clog日志)
- slog:一键收集所属OceanBase集群(slog日志)
- plan_monitor:一键收集所属OceanBase集群指定trace_id的并行SQL的执行详情信息
- stack:一键收集所属OceanBase集群的堆栈信息
- perf:一键收集所属OceanBase集群的perf信息(扁鹊图、perf火焰图、pstack火焰图)
- obproxy_log:一键收集所属OceanBase集群所依赖的obproxy组件的日志
- all:一键统一收集所属OceanBase集群的诊断信息,包括收集OceanBase日志/主机信息/OceanBase堆栈信息/OceanBase clog、slog日志/OceanBase perf信息(扁鹊图、perf火焰图、pstack火焰图)
4.3. 独立安装使用obdiag
4.3.1. obdiag下载
obdiag工具可从OceanBase官网下载免费下载,下载链接
4.3.1. obdiag使用文档
- 安装文档: OceanBase分布式数据库-海量数据 笔笔算数
- 配置文档: OceanBase分布式数据库-海量数据 笔笔算数
- 使用文档: OceanBase分布式数据库-海量数据 笔笔算数
5. 总结
当遇到OceanBase的问题时候,很多工程师可能会感到无从下手,本文介绍了一般情况下OceanBase的故障诊断路径,大家可通过环境分析、日志分析、性能视图分析来定位和分析问题。同时给大家推荐了一个很好用的OceanBase敏捷诊断工具(OceanBase Diagnostic Tool) ,简称obdiag,帮助大家方便的获取这些故障信息。
| 第一篇 | “神医”的修炼秘籍——《OceanBase诊断系列》之一 |
| 第二篇 | 《OceanBase诊断系列》——带你认识sql_audit性能视图 |