文章目录
- 1. 什么是LRU Cache
- 2. LRU Cache的实现
- 3. LinkedHashMap
- 4. LRU Cache OJ题
- 4.1 题目要求
- 4.2 解题思路
- 4.3 代码实现
- 4.3.1 Java代码一
- 4.3.2 Java代码二
1. 什么是LRU Cache
LRUCache,全称为Least Recently Used Cache,即最近最少使用缓存,是一种常用的页面置换算法和缓存策略。这么是Cache(缓存)呢?狭义的Cache 指的是位于 CPU 和主存之间的快速 RAM,通常它不像系统主存那样使用 DRAM 技术,而使用昂贵但是相对快速的 SRAM 技术。广义上的 Cache 指的是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度的差异的结构。除了 CPU 与主存之间有 Cache,内存与硬盘之间也有 Cache,乃至硬盘与网络之间也有某种意义上的 Cache——称为 Internet 临时文件夹或者网络内容缓存等。
然而,由于缓存的容量有限,当缓存满了之后,就需要选择一种策略来替换掉部分缓存数据,以便为新数据腾出空间。LRUCache就是其中一种常用的缓存替换策略。LRUCache 的替换原则就是将最近最少使用的内容替换掉。其实 LRU 译为最久未使用更形象,因为该算法每次替换掉的就是一段时间内最久没有使用过的内容。
2. LRU Cache的实现
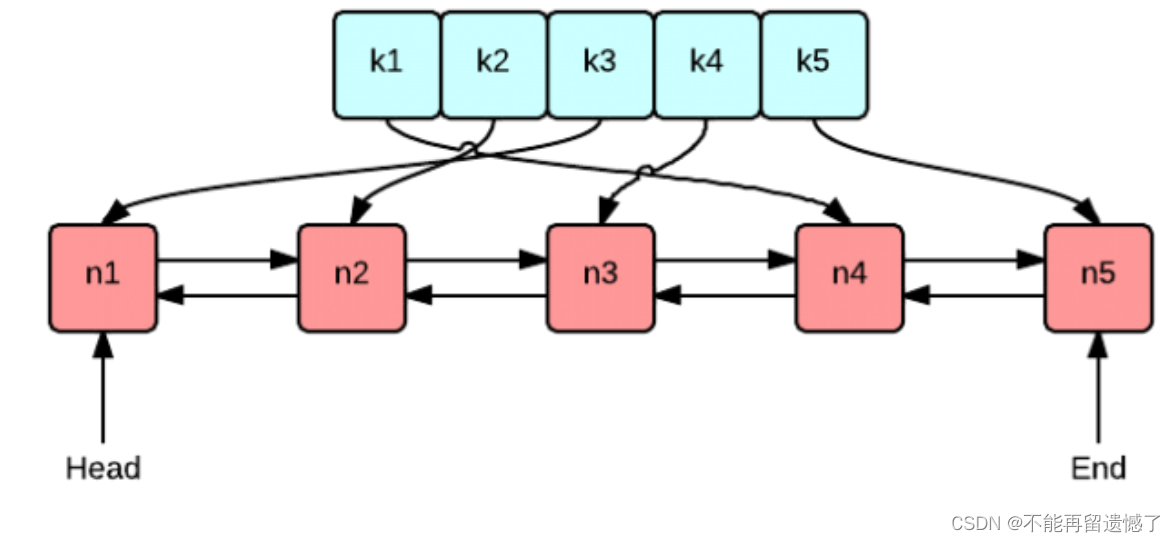
实现 LRU Cache 的方法和思路有很多,但是要保证高效实现 O(1) 的 put 和 get,那么使用双向链表和哈希表是最高效和经典的。使用双向链表可以保证在任务位置实现插入和删除的时候都能达到 O(1),使用哈希表是因为使用哈希表的增删查改的时间复杂度是 O(1)。
3. LinkedHashMap
在 JDK 中也存在类似 LRU Cache 的数据结构——LinkedHashMap。
LinkedHashMap 有下面几种构造方法:
构造方法一:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
构造方法二:
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
构造方法三:
public LinkedHashMap() {
super();
accessOrder = false;
}
构造方法四:
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
构造方法五:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
参数说明:
- initialCapacity:初始容量大小,使用无参数构造方法的时候,此值默认是16
- loadFactor:加载因子,使用无参数构造方法的时候,此值默认为0.75f
- accessOrder false:基于插入顺序 true:基于访问顺序
- map:哈希表,该构造方法常用于将哈希表转为 LinkedHashMap 操作
这里 initialCapacity、loadFactor 和 map 都好理解,接下来我们看看当 accessOrder 的值为 false 和 true 的区别:
public class Main {
public static void main(String[] args) {
Map<String,String> map = new LinkedHashMap<>(16,0.75f,false);
map.put("1","a");
map.put("2","b");
map.put("5","f");
map.put("4","e");
map.put("3","c");
System.out.println(map.get("5"));
System.out.println(map);
}
}
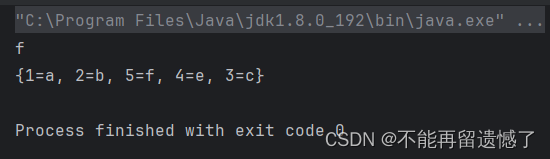
可以看到当我们的 accessOrder 为 false 的时候,不管我们如何访问 LinkedHashMap 中的数据,最后 LinkedHashMap 中数据的顺序还是按照插入时候的顺序排序的。
而我们将 accessOrder 改为 true 的时候,再访问其中的数据,就会发现 LInkedHashMap 中数据的顺序就发生了变化:
public class Main {
public static void main(String[] args) {
Map<String,String> map = new LinkedHashMap<>(16,0.75f,true);
map.put("1","a");
map.put("2","b");
map.put("5","f");
map.put("4","e");
map.put("3","c");
System.out.println(map.get("5"));
System.out.println(map);
}
}
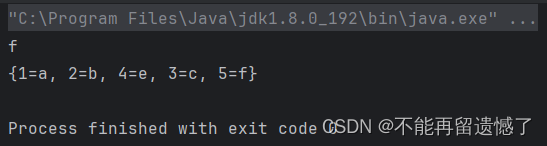
当 accessOrder 为 true 的时候,LinkedHashMap 中数据的顺序就是根据访问顺序来的,如果你访问了一个数据,那么该数据就会被放到双向链表的末尾。
4. LRU Cache OJ题
https://leetcode.cn/problems/lru-cache/description/
4.1 题目要求
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
class LRUCache {
public LRUCache(int capacity) {
}
public int get(int key) {
}
public void put(int key, int value) {
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
4.2 解题思路
这道题目我们可以直接继承 LinkedHashMap 类,然后重写父类中的方法就可以了。当然我们也可以自己实现一个 LinkedHashMap 类。
4.3 代码实现
4.3.1 Java代码一
class LRUCache extends LinkedHashMap<Integer,Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity,0.75f,true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key,-1);
}
public void put(int key, int value) {
super.put(key,value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
4.3.2 Java代码二
class LRUCache {
static class DLinkNode {
public int key;
public int val;
public DLinkNode prev;
public DLinkNode next;
public DLinkNode() {
}
public DLinkNode(int key, int val) {
this.key = key;
this.val = val;
}
@Override
public String toString() {
return "{ key=" + key +", val=" + val+"} ";
}
}
public DLinkNode head;//双向链表的头节点
public DLinkNode tail;//双向链表的尾巴节点
public int usedSize;//代表当前双向链表当中 有效的数据个数
public Map<Integer,DLinkNode> cache;//定义一个map
public int capacity;//容量
public LRUCache(int capacity) {
this.head = new DLinkNode();
this.tail = new DLinkNode();
head.next = tail;
tail.prev = head;
cache = new HashMap<>();
this.capacity = capacity;
}
/**
* 存储元素
* 1. 查找当前的这个key 是不是存储过
* @param key
* @param val
*/
public void put(int key,int val) {
//1. 查找当前的这个key 是不是存储过
DLinkNode node = cache.get(key);
//2. 如果没有存储过
if(node == null) {
//2.1 需要实例化一个节点
DLinkNode dLinkNode = new DLinkNode(key,val);
//2.2 存储到map当中一份
cache.put(key,dLinkNode);
//2.3 把该节点存储到链表的尾巴
addToTail(dLinkNode);
usedSize++;
//2.4 检查当前双向链表的有效数据个数 是不是超过了capacity
if(usedSize > capacity) {
//2.5 超过了,就需要移除头部的节点
DLinkNode remNode = removeHead();
//2.6 清楚cache当中的元素
cache.remove(remNode.key);
//2.7 usedSize--;
usedSize--;
}
}else {
//3. 如果存储过
//3.1 更新这个key对应的value
node.val = val;
//3.2 然后将该节点,移动至尾巴处【因为这个是新插入的数据】
moveToTail(node);
}
}
/**
* 移除当前节点到尾巴节点
* 逻辑:先删除 后添加到尾巴
* @param node
*/
private void moveToTail(DLinkNode node) {
//1. 先删除这个节点
removeNode(node);
//2. 添加到尾巴节点
addToTail(node);
}
/**
* 删除指定节点
* @param node
*/
private void removeNode(DLinkNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
/**
* 添加节点到链表的尾部
* @param node
*/
private void addToTail(DLinkNode node) {
tail.prev.next = node;
node.prev = tail.prev;
node.next = tail;
tail.prev = node;
}
private DLinkNode removeHead() {
DLinkNode del = head.next;
head.next = del.next;
del.next.prev = head;
return del;
}
/**
* 访问当前的key
* 逻辑:把你访问的节点 放到尾巴
* @param key
* @return
*/
public int get(int key) {
DLinkNode node = cache.get(key);
if(node == null) {
return -1;
}
//把最近 最多使用的 放到了链表的尾巴
moveToTail(node);
return node.val;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/