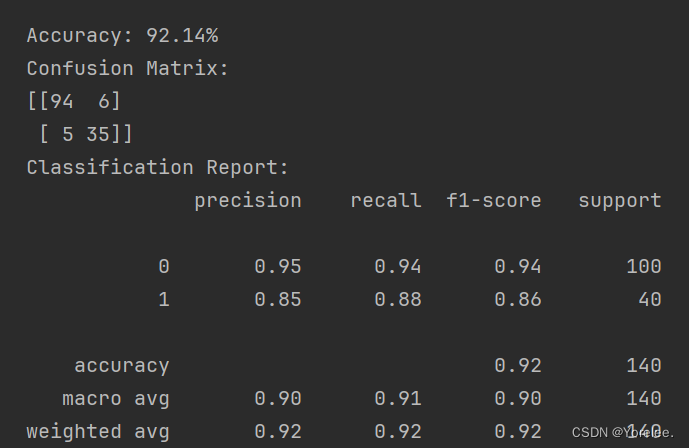
这段代码的背景是玩一个游戏。游戏的参数有NUM_TURNS,在第i回合,你可以从一个整数[-2,2,3,-3]*(NUM_TURNS+1-i)中进行选择。例如,在一个4回合的游戏中,在第1回合,你可以从[-8,8,12,-12]中选择,在第2回合,你也可以从[-6,6,9,-9]中选择。在每一个转弯处,所选择的数字都会累积为一个聚合值。游戏的目标是使累积值尽可能接近0。
定义MCTS 标量。标量越大,利用(exploitation)更大;标量越小,探索( exploration)更大。
接下来使用了logging模块,用于设置和获取日志记录器(logger)。
查看日志是开发人员日常获取信息、排查异常、发现问题的最好途径,日志记录中通常会标记有异常产生的原因、发生时间、具体错误行数等信息,这极大的节省排查时间,无形中提高了编码效率。
有关日志的更多信息。
-
logging.basicConfig(level=logging.WARNING):logging.basicConfig():用于快速设置日志系统的基本配置。level=logging.WARNING:设置日志系统的最低日志级别为WARNING。这意味着,只有WARNING、ERROR和CRITICAL级别的日志消息会被处理并显示。低于WARNING级别的消息(如DEBUG和INFO)将被忽略。- 使用
basicConfig方法后,所有后续的日志消息(除非明确指定了其他logger)都会使用这些基本设置。
-
logger = logging.getLogger('MyLogger'):logging.getLogger('MyLogger'):这是获取或创建一个名为'MyLogger'的日志记录器的方法。- 如果名为'MyLogger'的logger已经存在,该方法将返回该logger的引用。如果不存在,它将创建一个新的logger。
- 默认情况下,新创建的logger会继承root logger的配置(即
basicConfig设置的配置)。但你可以为特定logger设置特定的处理器(handlers)、格式器(formatters)和级别(levels)。
这两个语句之间的关系是:basicConfig为整个日志系统(包括所有logger)设置了基本配置,而getLogger则允许你获取或创建一个特定的logger,并可以为其设置特定的配置(如果需要的话)。
一个简单的例子:
import logging
# 设置基本配置,所有日志级别为WARNING及以上的消息都会被处理
logging.basicConfig(level=logging.WARNING)
# 获取一个名为'MyLogger'的logger
logger = logging.getLogger('MyLogger')
# 由于basicConfig已经设置了级别为WARNING,所以下面的消息将被记录
logger.warning('This is a warning message.')
# 下面的消息将不会被记录,因为级别低于WARNING
logger.info('This is an info message.')建立类State:
-
类变量:
NUM_TURNS:表示游戏或决策过程中的回合数,这里默认是10。GOAL:表示目标值,状态的值达到这个值时会获得最大的奖励,这里默认是0。MOVES:表示每次状态变化时可能的移动值,这里默认是[2,-2,3,-3]。MAX_VALUE:根据公式计算得出,用于后续的归一化奖励。num_moves:MOVES列表的长度。
-
__init__方法:- 用于初始化一个
State对象。 value:表示当前状态的值。moves:一个列表,表示到目前为止所采取的所有移动。turn:表示当前的回合数。
- 用于初始化一个
-
next_state方法:- 基于当前状态生成下一个状态。
- 随机选择一个移动值,并更新状态的值、移动列表和回合数。
- 返回新的
State对象。
-
terminal方法:- 判断当前状态是否是终止状态(即回合数是否为0)。
- 如果是终止状态,返回
True;否则返回False。
-
reward方法:- 计算并返回当前状态的奖励值,奖励值基于当前状态的值与目标值之间的差异来计算。
-
__hash__方法:- 为
State对象提供一个哈希值,以便可以在哈希表中使用。 - 使用MD5哈希算法对移动列表进行哈希。
- 为
-
__eq__方法:- 使用哈希值来判断两个
State对象是否相等。
- 使用哈希值来判断两个
-
__repr__方法:- 返回一个字符串,包括状态的值和移动列表,表示
State对象的状态。
- 返回一个字符串,包括状态的值和移动列表,表示
建立类Node,用于表示决策树或搜索树中的节点。在MCTS算法中,每个节点代表一个可能的状态,并且每个节点都存储了关于该状态的信息,如访问次数、累积奖励等。
__init__方法:state:表示该节点对应的状态。parent:表示该节点的父节点,默认为None。visits:表示该节点被访问的次数,初始化为1。reward:表示从该节点开始到终止状态所获得的累积奖励,初始化为0.0。children:一个列表,存储该节点的所有子节点。
add_child方法:- 用于向当前节点添加一个子节点。
child_state:子节点对应的状态。- 创建一个新的
Node对象,并将其作为子节点添加到children列表中。
update方法:- 用于更新节点的
reward和visits属性。 reward:从该节点开始到终止状态所获得的奖励。- 该方法将奖励累加到
self.reward,并将self.visits加1。
- 用于更新节点的
fully_expanded方法:- 检查当前节点是否已经完全扩展,即是否已经有了所有可能的子节点。
num_moves_lambda:一个可选的函数,用于计算给定节点的子节点数量。如果提供了这个函数,它将覆盖self.state.num_moves来计算子节点数量。- 如果当前节点的子节点数量等于可能的子节点数量,则返回
True,否则返回False。
__repr__方法:- 返回一个字符串,表示节点的简要信息。
- 包括子节点的数量、访问次数和累积奖励。
建立函数UCTSEARCH ,实现了UCT(Upper Confidence Bound for Trees)搜索算法的函数。UCT是一种常用于蒙特卡洛树搜索(MCTS)的策略,它结合了随机模拟与基于树结构的搜索,以找到最优的决策序列。

参数:
budget:这是一个整数,表示模拟的总次数或预算。算法将运行这么多次模拟来寻找最佳策略。root:这是搜索树的根节点,代表初始状态。num_moves_lambda:这是一个可选的lambda函数,用于自定义计算给定节点子节点数量的方式。如果未提供,将使用节点状态中的num_moves属性。
主要步骤:
-
循环模拟:算法将进行
budget次模拟。在每次模拟中,算法会从根节点开始,选择一系列的动作,直到达到终止状态。 -
日志记录:每进行10000次模拟,算法会记录当前的模拟次数,并输出根节点的信息。这有助于观察搜索过程的进展。
-
树策略(TREEPOLICY):在每次模拟中,算法使用
TREEPOLICY函数从当前节点开始,根据UCT公式选择一个子节点作为下一步。这个步骤基于已有的信息(如节点的访问次数和奖励)来做出决策。 -
默认策略(DEFAULTPOLICY):算法使用
DEFAULTPOLICY函数从选定的节点(front.state)开始,执行一系列动作直到达到终止状态,并计算累积奖励。 -
回溯(BACKUP):在模拟结束后,算法将累积的奖励回溯到搜索树中,更新每个访问过的节点的统计信息(如访问次数和累积奖励)。
-
选择最佳子节点(BESTCHILD):在所有模拟结束后,算法使用
BESTCHILD函数从根节点开始,基于节点的统计信息选择一个最佳子节点作为下一步。
最终,UCTSEARCH函数返回从根节点开始的最佳子节点序列,这些子节点代表了一系列的动作,构成了在给定预算下找到的最优策略。
建立函数TREEPOLICY ,基于当前节点的信息和UCT公式来决定是扩展一个新节点(即执行一个新的动作),还是选择一个已经存在的子节点进行进一步的搜索。函数在搜索过程中平衡了探索(扩展新节点)和利用(选择已知的最佳子节点)之间的关系,以实现更有效的搜索。
参数:
node:当前搜索树中的节点,代表当前的状态。num_moves_lambda:一个可选的函数,用于计算给定节点的子节点数量。如果未提供,将使用节点状态中的num_moves属性。
函数流程:
-
检查终止状态:首先,函数检查当前节点是否处于终止状态(即游戏是否结束)。如果是终止状态,则不再继续搜索,直接返回当前节点。
-
处理空子节点:如果当前节点没有子节点(即还没有进行过任何扩展),则调用
EXPAND函数来扩展一个新的子节点,并返回这个新节点。 -
随机选择:如果当前节点有子节点,函数会随机决定是否选择一个最佳子节点还是扩展一个新的子节点。这是通过生成一个0到1之间的随机数来实现的。
- 如果随机数小于0.5,则调用
BESTCHILD函数选择当前节点中根据UCT公式计算出的最佳子节点,并将该节点设置为新的当前节点。 - 如果随机数大于或等于0.5,则进入下一步。
- 如果随机数小于0.5,则调用
-
检查是否完全扩展:使用
fully_expanded方法检查当前节点是否已经完全扩展(即是否已经有了所有可能的子节点)。- 如果当前节点没有完全扩展,则调用
EXPAND函数来扩展一个新的子节点,并返回这个新节点。 - 如果当前节点已经完全扩展,则调用
BESTCHILD函数选择当前节点中根据UCT公式计算出的最佳子节点,并将该节点设置为新的当前节点。
- 如果当前节点没有完全扩展,则调用
-
返回节点:函数最终返回选择的节点,这个节点可能是新扩展的节点,也可能是根据UCT公式选择的最佳子节点。
建立函数EXPAND,用于扩展当前节点的一个新的子节点,即在当前状态下尝试一个新的动作或决策。
参数:
node:当前搜索树中的节点,代表当前的状态。
函数流程:
-
获取已尝试的子节点状态:首先,函数创建一个列表
tried_children,其中包含当前节点所有已存在子节点的状态。这是为了确保不会重复扩展已经尝试过的相同状态。 -
生成新的状态:调用当前节点状态对象的
next_state()方法来生成一个新的状态new_state。这个方法通常代表在当前状态下可以采取的下一个动作或决策。 -
检查状态是否已尝试:函数使用一个
while循环来检查新生成的状态new_state是否已经作为子节点尝试过。这是通过检查new_state是否存在于tried_children列表中,并且该状态不是终止状态来实现的。如果new_state已经尝试过或是一个终止状态,则继续生成新的状态。 -
添加新子节点:一旦找到一个新的、未尝试过的状态
new_state,函数使用add_child方法将其作为新的子节点添加到当前节点中。 -
返回新子节点:最后,函数返回新添加的子节点,这样调用者可以进一步处理或从这个新状态开始进行模拟。
建立函数BESTCHILD,用于从当前节点的子节点中选择一个最佳子节点来继续搜索。这个函数同样基于UCT公式来平衡探索和利用的权衡。
参数:
node:当前搜索树中的节点,代表当前的状态。scalar:用于调整探索和利用之间的权衡。较大的scalar值将增加探索的倾向,而较小的值将更注重利用已知信息。
函数流程:
-
初始化最佳分数和最佳子节点列表:函数首先初始化
bestscore为0.0,用于存储当前找到的最佳分数。同时,bestchildren列表用于存储具有相同最佳分数的子节点。 -
遍历子节点:对于当前节点的每一个子节点
c,函数计算其UCT分数。 -
计算利用部分:
exploit = c.reward / c.visits是利用部分,它表示子节点c的平均奖励与其被访问次数之间的比率。这反映了子节点c的已知价值。 -
计算探索部分:
explore = math.sqrt(2.0 * math.log(node.visits) / float(c.visits))是探索部分,它基于子节点c的访问次数和父节点node的总访问次数来计算。这反映了选择较少访问的子节点以进行进一步探索的倾向。 -
计算UCT分数:
score = exploit + scalar * explore是子节点c的UCT分数。它结合了利用部分和探索部分,其中scalar用于调整两者之间的平衡。 -
更新最佳分数和最佳子节点:如果子节点
c的UCT分数大于当前的bestscore,则更新bestscore为该分数,并重置bestchildren列表只包含当前子节点c。如果分数等于bestscore,则将子节点c添加到bestchildren列表中。 -
处理无最佳子节点的情况:如果遍历完所有子节点后
bestchildren列表为空(这通常是一个错误情况,表明没有子节点被访问过),则记录一个警告日志。 -
返回最佳子节点:最后,函数从
bestchildren列表中随机选择一个子节点作为最佳子节点返回。这允许在多个具有相同最佳分数的子节点之间进行随机选择。
建立函数DEFAULTPOLICY,用于在没有其他特定策略可用时选择一个默认的动作。
参数:
state:当前的状态对象,代表游戏或决策过程的当前状态。
函数流程:
-
检查终止状态:函数首先检查当前状态
state是否是终止状态(即游戏是否结束)。如果是终止状态,则不再继续执行,因为终止状态没有后续的动作或决策。 -
选择下一个状态:如果当前状态不是终止状态,函数使用
next_state()方法来选择或生成下一个状态。这通常意味着在当前状态下执行一个默认的动作或决策。 -
迭代过程:函数将当前状态更新为下一个状态,并重复上述过程,直到达到一个终止状态。
-
返回奖励:当达到终止状态时,函数调用
reward()方法来获取该状态的奖励值,并将其作为结果返回。
建立函数BACKUP,用于在模拟结束后更新从根节点到叶节点的路径上所有节点的统计信息。具体来说,它会遍历这条路径,增加每个节点的访问次数(visits)和累计奖励(reward)。
参数:
node:需要进行回溯的起始节点,通常是一个叶节点。reward:模拟结束时获得的奖励值。
函数流程:
-
检查起始节点:函数首先检查起始节点
node是否为None。如果是None,则不执行任何操作并直接返回。 -
遍历路径并更新统计信息:
- 如果起始节点不是
None,函数进入一个while循环,该循环将继续执行,直到遍历到根节点或遇到None节点为止。 - 在循环内部,函数首先增加当前节点
node的访问次数(visits)和累计奖励(reward)。这通过node.visits += 1和node.reward += reward实现。 - 然后,函数将当前节点更新为其父节点
node.parent,以便在下一次循环迭代中处理父节点。
- 如果起始节点不是
-
返回:函数完成后返回
None。
主程序入口:
if __name__=="__main__"::这是一个常见的Python模式,用于检查脚本是否作为主程序运行,而不是被导入为模块。argparse.ArgumentParser():创建一个命令行参数解析器。parser.add_argument('--num_sims', ...):添加一个命令行参数--num_sims,它是一个必需的整数参数,用于指定模拟的次数。parser.add_argument('--levels', ...):添加一个命令行参数--levels,它也是一个必需的整数参数,用于指定搜索的层数。它的值必须在0到State.NUM_TURNS之间(包括两端)。args = parser.parse_args():解析命令行参数,并将结果存储在args对象中。
current_node = Node(State()):创建一个根节点,其状态由State()确定。for l in range(args.levels)::对于每个指定的搜索层数l,执行以下操作:current_node = UCTSEARCH(args.num_sims/(l+1), current_node):对当前节点执行UCT搜索,模拟次数随着层数的增加而减少(这是一个常见的策略,因为随着树深度的增加,每个节点的模拟次数通常会减少)。- 打印当前层数、当前节点的子节点数量以及每个子节点的信息。
print("Best Child: %s" % current_node.state):打印当前节点下具有最佳UCT分数的子节点的状态。print("--------------------------------"):打印一个分隔符,以便于阅读输出。
#!/usr/bin/env python
import random
import math
import hashlib
import logging
import argparse
"""
A quick Monte Carlo Tree Search implementation. For more details on MCTS see See http://pubs.doc.ic.ac.uk/survey-mcts-methods/survey-mcts-methods.pdf
The State is a game where you have NUM_TURNS and at turn i you can make
a choice from an integeter [-2,2,3,-3]*(NUM_TURNS+1-i). So for example in a game of 4 turns, on turn for turn 1 you can can choose from [-8,8,12,-12], and on turn 2 you can choose from [-6,6,9,-9]. At each turn the choosen number is accumulated into a aggregation value. The goal of the game is for the accumulated value to be as close to 0 as possible.
The game is not very interesting but it allows one to study MCTS which is. Some features
of the example by design are that moves do not commute and early mistakes are more costly.
In particular there are two models of best child that one can use
"""
#MCTS scalar. Larger scalar will increase exploitation, smaller will increase exploration.
SCALAR=1/(2*math.sqrt(2.0))
logging.basicConfig(level=logging.WARNING)
logger = logging.getLogger('MyLogger')
class State():
NUM_TURNS = 10
GOAL = 0
MOVES=[2,-2,3,-3]
MAX_VALUE= (5.0*(NUM_TURNS-1)*NUM_TURNS)/2
num_moves=len(MOVES)
def __init__(self, value=0, moves=[], turn=NUM_TURNS):
self.value=value
self.turn=turn
self.moves=moves
def next_state(self):
nextmove=random.choice([x*self.turn for x in self.MOVES])
next=State(self.value+nextmove, self.moves+[nextmove],self.turn-1)
return next
def terminal(self):
if self.turn == 0:
return True
return False
def reward(self):
r = 1.0-(abs(self.value-self.GOAL)/self.MAX_VALUE)
return r
def __hash__(self):
return int(hashlib.md5(str(self.moves).encode('utf-8')).hexdigest(),16)
def __eq__(self,other):
if hash(self)==hash(other):
return True
return False
def __repr__(self):
s="Value: %d; Moves: %s"%(self.value,self.moves)
return s
class Node():
def __init__(self, state, parent=None):
self.visits=1
self.reward=0.0
self.state=state
self.children=[]
self.parent=parent
def add_child(self,child_state):
child=Node(child_state,self)
self.children.append(child)
def update(self,reward):
self.reward+=reward
self.visits+=1
def fully_expanded(self, num_moves_lambda):
num_moves = self.state.num_moves
if num_moves_lambda != None:
num_moves = num_moves_lambda(self)
if len(self.children)==num_moves:
return True
return False
def __repr__(self):
s="Node; children: %d; visits: %d; reward: %f"%(len(self.children),self.visits,self.reward)
return s
def UCTSEARCH(budget,root,num_moves_lambda = None):
for iter in range(int(budget)):
if iter%10000==9999:
logger.info("simulation: %d"%iter)
logger.info(root)
front=TREEPOLICY(root, num_moves_lambda)
reward=DEFAULTPOLICY(front.state)
BACKUP(front,reward)
return BESTCHILD(root,0)
def TREEPOLICY(node, num_moves_lambda):
#a hack to force 'exploitation' in a game where there are many options, and you may never/not want to fully expand first
while node.state.terminal()==False:
if len(node.children)==0:
return EXPAND(node)
elif random.uniform(0,1)<.5:
node=BESTCHILD(node,SCALAR)
else:
if node.fully_expanded(num_moves_lambda)==False:
return EXPAND(node)
else:
node=BESTCHILD(node,SCALAR)
return node
def EXPAND(node):
tried_children=[c.state for c in node.children]
new_state=node.state.next_state()
while new_state in tried_children and new_state.terminal()==False:
new_state=node.state.next_state()
node.add_child(new_state)
return node.children[-1]
#current this uses the most vanilla MCTS formula it is worth experimenting with THRESHOLD ASCENT (TAGS)
def BESTCHILD(node,scalar):
bestscore=0.0
bestchildren=[]
for c in node.children:
exploit=c.reward/c.visits
explore=math.sqrt(2.0*math.log(node.visits)/float(c.visits))
score=exploit+scalar*explore
if score==bestscore:
bestchildren.append(c)
if score>bestscore:
bestchildren=[c]
bestscore=score
if len(bestchildren)==0:
logger.warn("OOPS: no best child found, probably fatal")
return random.choice(bestchildren)
def DEFAULTPOLICY(state):
while state.terminal()==False:
state=state.next_state()
return state.reward()
def BACKUP(node,reward):
while node!=None:
node.visits+=1
node.reward+=reward
node=node.parent
return
if __name__=="__main__":
parser = argparse.ArgumentParser(description='MCTS research code')
parser.add_argument('--num_sims', action="store", required=True, type=int)
parser.add_argument('--levels', action="store", required=True, type=int, choices=range(State.NUM_TURNS+1))
args=parser.parse_args()
current_node=Node(State())
for l in range(args.levels):
current_node=UCTSEARCH(args.num_sims/(l+1),current_node)
print("level %d"%l)
print("Num Children: %d"%len(current_node.children))
for i,c in enumerate(current_node.children):
print(i,c)
print("Best Child: %s"%current_node.state)
print("--------------------------------")