We implement DangZero as a shared library that overlays the de- fault memory allocator via LD_PRELOAD. Additionally, DangZero requires a backend to be available for direct page table access, which we describe in detail in the following section.
我们将DangZero实现为一个共享库,它通过LD_PRELOAD覆盖故障内存分配器。此外,DangZero需要一个后端来直接访问页表,我们将在下一节中详细描述。
1 Privilege backend
One of the critical components of DangZero is its privilege backend, which is responsible for providing direct access to privileged kernel features from the (user-space) allocator. The ability to directly modify page tables (and issue corresponding TLB flushes) is essential for the performance of our system
DangZero的关键组件之一是它的特权后端,它负责提供从(用户空间)分配器对特权内核功能的直接访问。直接修改页表(并发出相应的TLB刷新)的能力对于我们系统的性能至关重要
For this, DangZero’s primary backend builds on top of Kernel Mode Linux (KML) [ 36], a Linux kernel modification that enables running user-space applications in kernel mode (ring 0). This ef- fectively transforms Linux into an efficient unikernel [ 29 ]. It also provides the application with all privileges on the system, allowing it to call into kernel code (e.g., alloc_page for allocating physical pages) and write to any memory. However, KML still remains Linux under the hood, thus benefiting from all existing Linux drivers and supporting all existing Linux binaries
为此,DangZero的主要后端建立在内核模式Linux(KML)[36]之上,这是一种Linux的内核修改,允许在内核模式(环0)下运行用户空间应用程序。这有效地将Linux转变为高效的单内核[29]。它还为应用程序提供了系统上的所有权限,允许它调用内核代码(例如,alloc_page分配物理页面)并写入任何内存。然而,本质上看,KML仍然是Linux,从而受益于所有现有的Linux驱动程序并支持所有现有的Linux二进制文件
【kml就是能提供给程序ring 0权限的linux系统,因此可以直接访问页表,且现有的Linux驱动和二进制也能使用,相当于将linux进行了最小程度的适应dangzero需求的改造】
However, providing arbitrary user-space programs with kernel privileges is inherently unsafe: a bug or vulnerability in the program can affect or corrupt any other program and user on the system. Like other unikernel systems, we therefore run our system inside a (lightweight) virtual machine (VM), which isolates the guest from the rest of the system. By dedicating the guest system to an indi- vidual process, we consider a single security domain, and hence an attacker abusing orthogonal vulnerabilities cannot exploit page table access to compromise other security domains (e.g., other ap- plications or the host). Additionally, this setup can provide higher performance than a bare-metal baseline, since the KML kernel can be tweaked specifically for running a single application on virtual- ized hardware [ 29]. DangZero does not include such optimizations, to fairly evaluate the overhead introduced by its design
然而,提供具有内核权限的任意用户空间程序本质上是不安全的:程序中的bug或漏洞可能会影响或破坏系统上的任何其他程序和用户。因此,与其他单内核系统一样,我们在(轻量级)虚拟机(VM)中运行我们的系统,该虚拟机将客户机与系统的其余部分隔离开来。 通过将客户机系统专用于独立的个体进程,我们考虑了一个单一的安全域,因此滥用正交漏洞的攻击者无法利用页表访问来破坏其他安全域(例如,其他应用程序或主机)。此外,这种设置可以提供比裸机基线更高的性能,因为KML内核可以专门针对在虚拟化硬件上运行单个应用程序进行调整[29]。DangZero不包括此类优化,以公平评估其设计引入的开销
For DangZero, we used the latest Linux kernel with an available KML patch, i.e., v4.0. We applied two patches to the KML kernel such that it can properly operate with the latest LTS version of Ubuntu at the time (20.04). The KML project introduced a patch to glibc 2.11 to change system calls into direct calls, which we port to glibc 2.31 (the default for the used OS). The modern version of glibc allows us to use the default gcc version on our OS (9.4.0). For some features, we require access to kernel data structures (e.g., iterating through VMA structs). This is conveniently implemented in a kernel module, which, thanks to KML, we can call directly from our allocator via a regular function call.
对于DangZero,我们使用了最新的Linux内核和可用的KML补丁,即v4.0。我们对KML内核应用了两个补丁,以便它可以在当时(20.04)与最新的LTS版本的Ubuntu一起正常运行。KML项目为glibc 2.11引入了一个补丁,将系统调用更改为直接调用,我们将其移植到glibc 2.31(已使用操作系统的默认值)。glibc的现代版本允许我们在我们的操作系统(9.4.0)上使用默认的gcc版本。对于某些功能,我们需要访问内核数据结构(例如,遍历VMA结构)。这在内核模块中方便地实现,多亏了KML,我们可以通过常规函数调用直接从我们的分配器调用。
1.1 Alternative backend: Dune
Next to KML, we have also imple- mented an alternative backend for DangZero to demonstrate the wide applicability of its design. For this purpose, we chose Dune [ 6 ], a hypervisor and libOS that is aimed at granting user applications access to privileged hardware features. Our Dune-based DangZero prototype showed almost identical performance as KML for the SPEC benchmarks. However, on system call intensive applications (e.g., Nginx), the Dune baseline itself reports a significant perfor- mance overhead (up to 60%), because Dune has to translate system calls into far more expensive VM exits, resulting in higher overall overhead for DangZero/Dune. As such, the remainder of this paper is solely evaluated using DangZero’s KML backend.
替代后端:沙丘。除了KML,我们还为DangZero实现了一个替代后端,以展示其设计的广泛适用性。为此,我们选择了Dune[6],这是一个管理程序和libOS,旨在授予用户应用程序访问特权硬件功能的权限。我们基于Dune的DangZero原型在SPEC基准测试中显示出与KML几乎相同的性能。然而,在系统调用密集型应用程序(例如Nginx)上,Dune基线本身报告了显着的性能开销(高达60%),因为Dune必须将系统调用转换为更昂贵的VM出口,从而导致DangZero/Dune的总体开销更高。因此,本文的其余部分仅使用DangZero的KML后端进行评估。
2 Alias page tables
While KML grants our allocator direct access to kernel memory such as the page table data structures, it cannot easily take full control of them. In particular, Linux itself is unaware of DangZero, and will overwrite any changes our allocator would make in user- space mappings. Instead, DangZero operates in a normally reserved area of the Linux kernel address space (untouched by the kernel by design). This strategy has two advantages: it does not require kernel modifications to allow for page table access sharing and it does not reduce the amount of virtual memory available to userland.
虽然KML允许我们的分配器直接访问内核内存,如页表数据结构,但它不能轻易完全控制它们。特别是,Linux本身不知道DangZero,并且会覆盖我们的分配器在用户空间映射中所做的任何更改。相反,DangZero在Linux内核地址空间的一个通常保留区域中运行(设计上不受内核影响)。这种策略有两个优点:它不需要内核修改来允许页表访问共享,也不会减少用户空间的虚拟可用存储器数量。
【找1个既不影响内核又不影响用户空间的地方来运行dangzero,就对哪一部分都不会有影响】
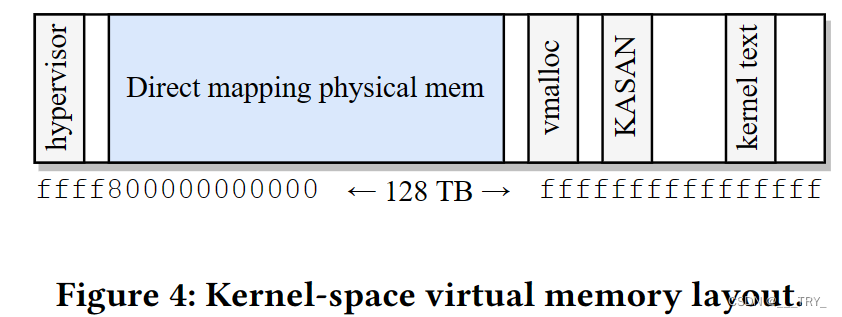
Figure 4 shows a (simplified) kernel-space virtual memory layout. The kernel reserves a virtual memory area of 64 TB for the direct mapping of all physical memory. Since most machines have at most a few hundred gigabytes of RAM, most of this area is not in use. Therefore, we can reserve a large part of this unused area to host our alias page tables. The 64 TB of direct mapping corresponds to the highest level (L4) page table entries 273 to 400. Assuming that the system uses up to 27 x 512 GB physical memory at most (a generous overapproximation for the foreseeable future), this leaves entries 300 to 400 available for our virtual alias pages. This area can host up to 50 TB of virtual alias space, which corresponds to a maximum of 12.5 billion concurrent 4K alias pages.
图4显示了一个(简化的)内核空间虚拟内存布局。内核为所有物理内存的直接映射保留了64 TB的虚拟内存区域。由于大多数机器最多只有几百GB的RAM,因此这个区域的大部分都没有被使用。因此,我们可以保留这个未使用区域的很大一部分来托管我们的别名页表。 64 TB的直接映射对应于最高级别(L4)页表条目273到400。假设系统最多使用27 x 512 GB的物理内存(在可预见的未来是一个慷慨的超近似值),这为我们的虚拟别名页面保留了300到400个条目可用。这个区域最多可以托管50 TB的虚拟别名空间,这对应于最多125亿并发的4K别名页面。
3 Supporting fork
The downside of bypassing the kernel when creating alias mappings directly in the page tables of a process is that the kernel is not aware of these pages when executing operations such as fork. The fork system call creates a child process where the pages of the parent and the child are shared. Upon modification of a shared page, the copy-on-write (CoW) technique ensures a copy of the page is used. Unfortunately, the alias pages are not copied over to the page tables of the child process, and even if they were (e.g., by being present in the normal kernel data structures such as VMAs), they would wrongfully remain aliased to the physical pages of the parent.
当直接在进程的页表中创建别名映射时,绕过内核的缺点是内核在执行诸如fork之类的操作时不知道这些页面。fork系统调用创建一个子进程,其中父进程和子进程的页面是共享的。修改共享页面时,写时复制(CoW)技术确保使用页面的副本。不幸的是,别名页面没有复制到子进程的页表中, 即使它们被复制了(例如,存在于VMA等正常内核数据结构中),它们也会错误地保持父进程物理页面的别名。
The intuition to solve this problem is that we forcefully trigger CoW on all of the canonical pages in the child process, causing the pages to receive new physical backing. After this, we can create the appropriate alias pages and make them point to these new physical pages in the child. However, recreating the alias mappings in the child to point to the new physical pages is difficult, since we lack both a canonical-to-shadow map, or a parent-physical to child-physical map. Maintaining such a data structure would be prohibitively expensive for an uncommon operation such as fork.
解决这个问题的直觉是,我们在子进程中的所有规范页面上强制触发CoW,导致页面获得新的物理支持。在此之后,我们可以创建适当的别名页面,并使它们指向子进程中的这些新物理页面。然而,在子进程中重新创建别名映射以指向新的物理页面是困难的,因为我们既缺乏规范到阴影的映射,也缺乏父物理到子物理的映射。 对于像fork这样的不常见操作,维护这样的数据结构的成本高得令人望而却步。
To overcome this problem, we apply the following algorithm as an epilogue to the fork library call (also shown in Listing 2). We create a temporary map of parent-physical to canonical addresses, which we generate by walking the page tables for each canonical address in the parent and reading the physical page in the resulting PTE. Using this map of physical-canonical address pairs, we reconstruct the alias page tables in the child process. For each alias page in the parent, we obtain its physical address by doing a page walk and look up the corresponding canonical address in our map, using the physical address as key. Then, we touch the virtual address in order to trigger CoW, resulting in new physical backing in the child. Next, we look up the new child-physical address with a page walk of the canonical address in the child. Finally, we create the corre- sponding page table entries in the alias space of the child, such that the new alias page points to the new physical backing. Throughout this algorithm, we sync the parent to wait for the child to finish these operations, such that the memory state remains consistent.
为了克服这个问题,我们将以下算法作为fork库调用的结束语(也如清单2所示)。我们创建了一个父物理到规范地址的临时映射,我们通过遍历父中每个规范地址的页表并读取生成的PTE中的物理页面来生成这个映射。使用这个物理-规范地址对映射,我们重建子进程中的别名页表。对于父进程中的每个别名页面,我们通过页面遍历获得其物理地址,并使用物理地址作为键在映射中查找相应的规范地址。 然后,我们触摸虚拟地址以触发CoW,从而在子进程中产生新的物理支持。接下来,我们使用子进程中规范地址的页面遍历来查找新的子物理地址。最后,我们在孩子的别名空间中创建相应的页表条目,这样新的别名页面就指向新的物理支持。在整个算法中,我们同步父级以等待孩子完成这些操作,这样内存状态就保持一致。
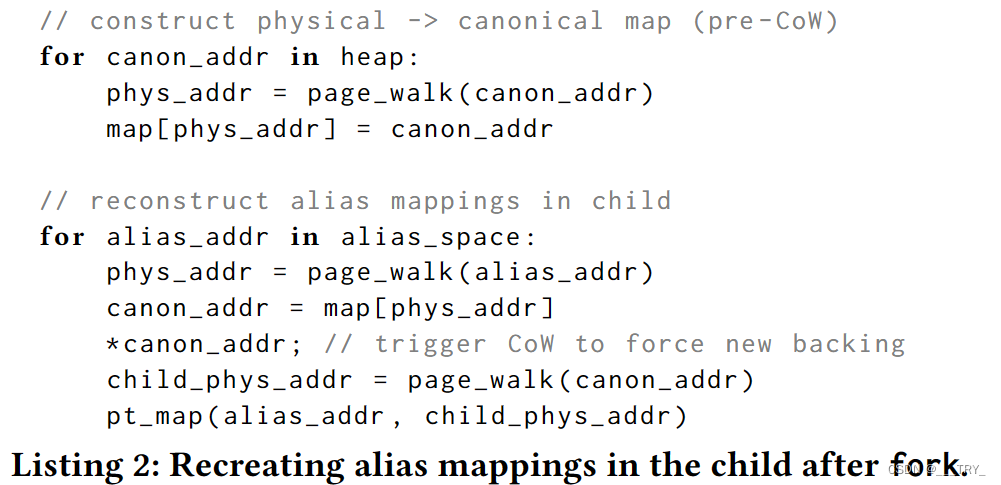
【目的:在子进程中建立alias页表,以重新映射alias页面到新的phys页面
步骤
- 保留父进程的canon->phys映射
- 获得子进程中alias->canon映射(alias->parent_phys parent_phys->canon)
- 触发cow以获得canon->child_phys,以获得目的alias->child_phys