文章目录
- 1 整体概念梳理
- 1.1 数据集与数据术语——原材料
- 1.2 任务术语——目标
- 1.3 训练和测试术语——怎么做
- 1.4 结果——预期期望
整体框架
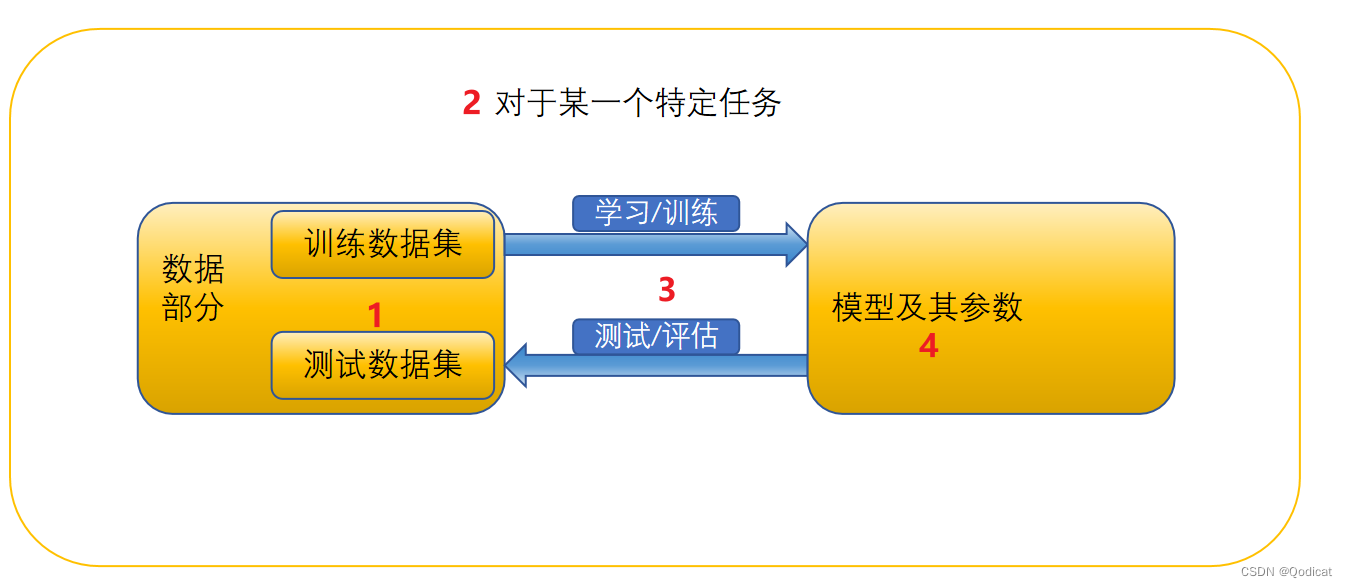
机器学习的基本概念全梳理
我们通过一个生动形象的例子来介绍这些概念
我们假设有一个任务是根据地理天气等特征位置预测经纬度
1 整体概念梳理
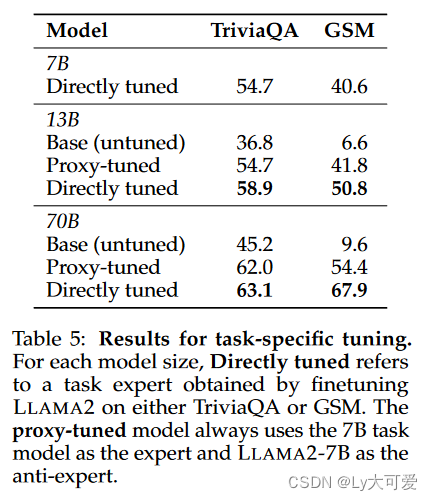
1.1 数据集与数据术语——原材料
进行机器学习,首先要有一个一个的数据,理论上数据越多越好
数据本身会有一些特征信息,比如(湿度,温度,降水量,风速),我们把这些称作属性,属性最后会表示为向量,,我们叫他特征向量,这些特征向量最后会张成一个向量空间, 属性的向量空间叫属性空间或样本空间或输入空间
数据除了本身的一些特征信息,还要有对应的标记 示例结果信息,比如最后的经纬度信息,标记张成的空间叫做标记空间 或者输出空间
而数据的集合就是数据集 ,数据集往往会分为训练数据集和测试数据集
- 前者用来训练,优化模型参数
- 后者用来测试评估模型
1.2 任务术语——目标
有了数据,我们还要有目标,即让模型干什么,机器学习中很多都是预测类
如果我们要预测的是离散值,比如判断一个猕猴桃是优质的还是不优质的,叫做分类问题
- 只涉及两个类别的称做
二分类通常称其中一个为正类,另外一个为反类 - 多个类别的分类,叫做
多分类
如果我们要判断的是连续值,比经纬度,那么叫做回归问题
怎么训练呢
1.3 训练和测试术语——怎么做
有监督学习和无监督学习
有监督学习:有监督学习是指在训练过程中,模型从带有标签的数据中学习。这些标签是预先定义的输出,它们告诉模型每个输入数据点的正确结果。有监督学习的目标是让模型能够学习到输入数据与输出标签之间的映射关系,以便在给定新的、未见过的数据时能够做出准确的预测。
- 典型的任务有分类(Classification)和回归(Regression)
- 例子:图像识别、语音识别、信用评分、股票价格预测等。
无监督学习: 无监督学习是指在训练过程中,模型处理没有标签的数据。模型需要自行发现数据中的结构和模式。无监督学习的目标是探索数据的内在特性,而不是从标签中学习。
- 典型任务类型:聚类(Clustering)、降维(Dimensionality Reduction)和关联规则学习(Association Rule Learning)
- 例子:社交网络分析、推荐系统(通过用户行为而非明确标签)、异常检测等
1.4 结果——预期期望
我们最终希望得到一个泛化能力强的模型
泛化能力(Generalization)是机器学习模型的一个重要特性,它描述了模型在处理新的、未见过的数据时的表现能力。一个具有良好泛化能力的模型能够将从训练数据中学到的知识有效地应用到新的情境中,做出准确的预测或决策。
但是模型会根据我们选取的算法不同而产生归纳偏好
就好比我们要评价一个产品的质量好坏,有些人是从产品的外观评价得出是个好产品,而有些人是从产品的内核评价得出是个坏产品。机器学习也类似,他可能偏向于从某些特征做出自己的判断。
而假设所有问题都同等重要的情况下,所有算法的总误差的期望都是一样的,这叫做天下没有免费的午餐定理。因而我们要意识到 一点,就是算法的好坏是就具体问题而论的,有些算法可能在某一个问题表现很好,但在另外的问题上表现却很差。
我们要具体问题具体分析
参考
周志华老师《机器学习》