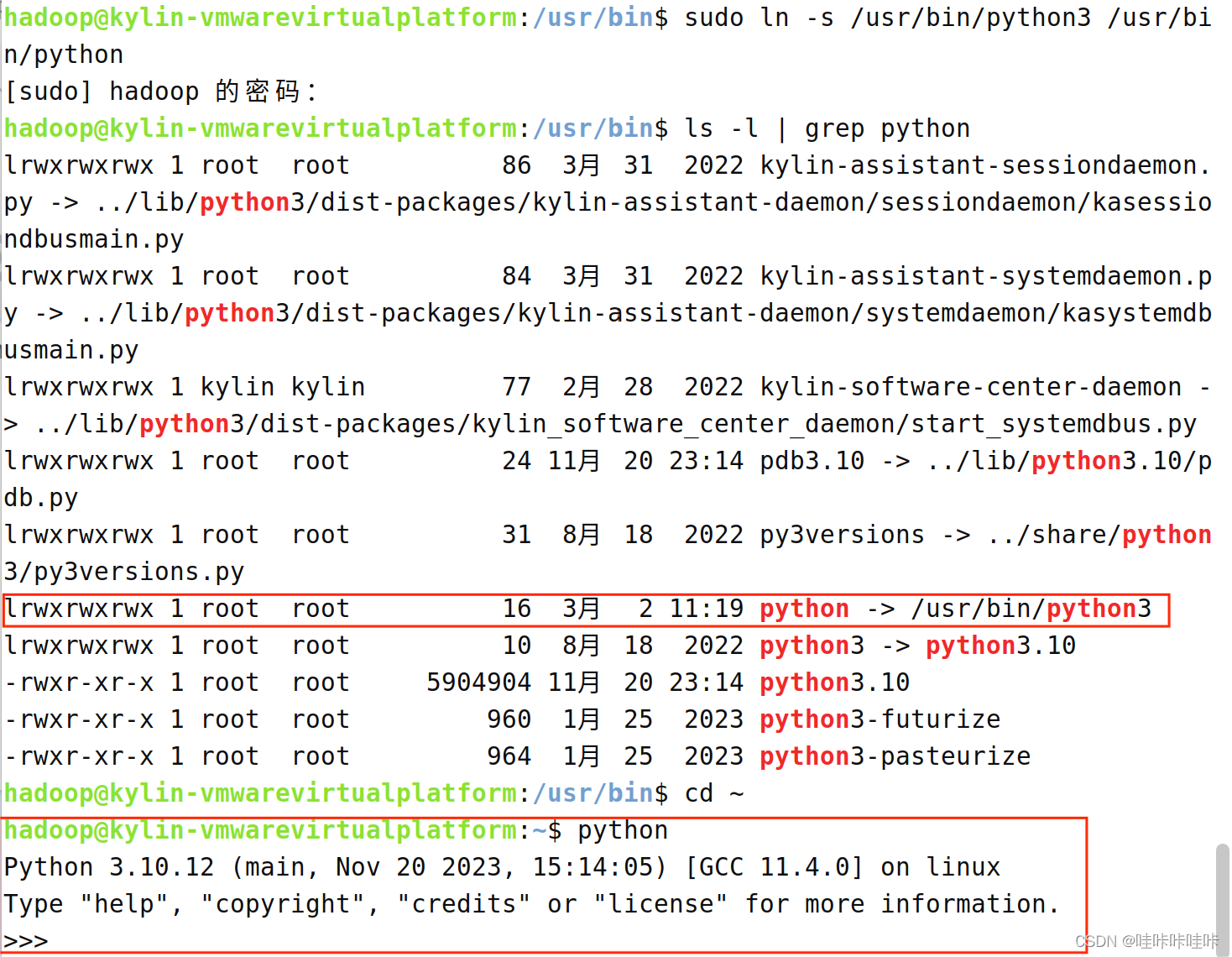
1. 概念区分
使用传统的监督学习方法做分类,往往训练样本规模越大,分类的效果越好。但是在现实生活中的
很多场景下,标记样本的获取较困难,需要领域内的专家进行人工标注,需要较大的时间成本和经
济成本。另外,当训练样本规模过于庞大时,训练的时间花费也会较多。那么有没有办法,能够使
用较少的训练样本来获得性能较好的分类器呢?主动学习(Active Learning)为我们提供了这种可
能。主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样
本训练分类模型来提高模型的精确度。
在人类的学习过程中,通常利用已有的经验来学习新的知识,又依靠获得的知识来总结和积累经
验,经验与知识不断交互。同样,机器学习模拟人类学习的过程,利用已有的知识训练出模型去获
取新的知识,并通过不断积累的信息去修正模型,以得到更加准确有用的新模型。不同于被动学习
被动的接受知识,主动学习能够选择性地获取知识。
“主动学习是机器学习(更普遍的说是人工智能)的一个子领域,在统计学领域也叫查询学习、最
优实验设计”。主动学习(有时称为“查询学习”或“优化实验设计”,在统计学文献中)是机器学习的
一个子领域,更一般地说,是人工的情报。“学习模块”和“选择策略”是主动学习算法的2个基本且重
要的模块。主动学习通过“选择策略”主动从未标注的样本集中挑选部分(1个或N个)样本让相关领
域的专家进行标注;然后将标注过的样本增加到训练数据集给“学习模块”进行训练;当“学习模块”
满足终止条件时即可结束程序,否则不断重复上述步骤获得更多的标注样本进行训练。
关键的假设是,如果允许学习算法选择它从中学习的数据——如果你愿意的话,要“好奇”——它会
在更少的训练下表现得更好。
1.1 主动学习与半监督学习的异同点
在机器学习领域中,根据是否需要样本的标签信息可分为“监督学习”和“无监督学习”。此外,同时
利用未标注样本和标注样本进行机器学习的算法可进一步归纳为3类:半监督学习、直推式学习和
主动学习 。
“半监督学习和主动学习都是从未标记样例中挑选部分价值量高的样例标注后补充到已标记样例集
中来提高分类器精度,降低领域专家的工作量但二者的学习方式不同:半监督学习一般不需要人工
参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习有别于半
监督学习的特点之一就是需要将挑选出的高价值样例进行人工准确标注。半监督学习通过用计算机
进行自动或半自动标注代替人工标注,虽然有效降低了标注代价,但其标注结果依赖于用部分已标
注样例训练出的基准分类器的分类精度,因此并不能保证标注结果完全正确。相比而言,主动学习
挑选样例后是人工标注,不会引入错误类标。
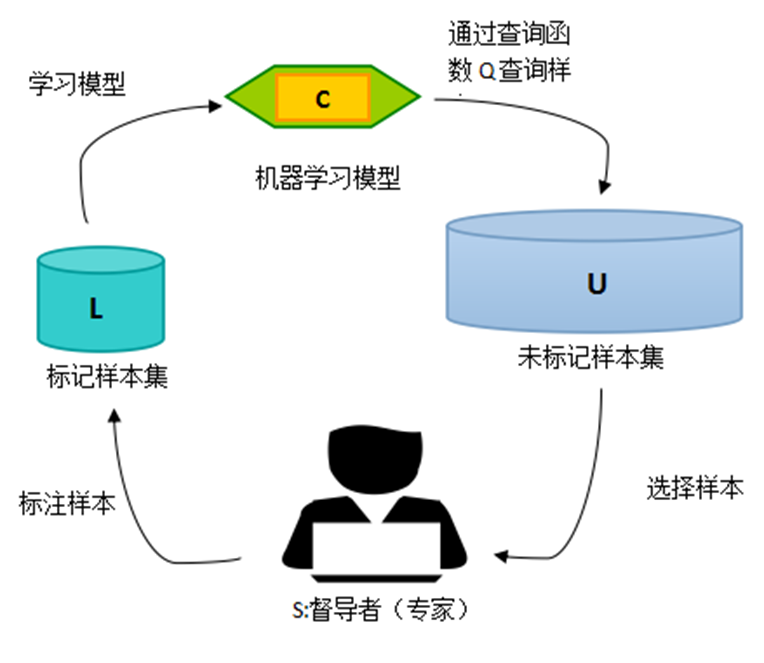
2. 主动学习模型
主动学习的模型如下:A=(C,Q,S,L,U),其中 C 为一组或者一个分类器,L是用于训练已标注的样
本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本
标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或
一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查
询。主动学习是一个循环的过程,直至达到某一停止准则为止。
查询函数Q用于查询一个或一批最有用的样本。那么,什么样的样本是有用的呢?即查询函数查询
的是什么样的样本呢?在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则
(uncertainty)和差异性准则(diversity)。
对于不确定性,可借助信息熵的概念进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不
确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于
不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-
bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含
的丰富信息量,对我们训练模型来说就是有用的。
差异性如何理解?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的
样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在
每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以新
获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样
本,那么就应该想办法来保证样本的差异性,避免数据冗余。
2.1 主动学习流程(以分类任务为例)
(1)选取合适的分类器(网络模型)记为 current_model 、主动选择策略、数据划分为
train_sample(带标注的样本,用于训练模型)、validation_sample(带标注的样本,用于验证当
前模型的性能)、active_sample(未标注的数据集,对应于ublabeled pool);
(2)初始化:随机初始化或者通过迁移学习(source domain)初始化;如果有target domain的
标注样本,就通过这些标注样本对模型进行训练;
(3)使用当前模型 current_model 对 active_sample 中的样本进行逐一预测(预测不需要标
签),得到每个样本的预测结果。此时可以选择 Uncertainty Strategy 衡量样本的标注价值,预测
结果越接近0.5的样本表示当前模型对于该样本具有较高的不确定性,即样本需要进行标注的价值
越高。
(4)专家对选择的样本进行标注,并将标注后的样本放至train_sapmle目录下。
(5)使用当前所有标注样本 train_sample对当前模型current_model 进行fine-tuning,更新
current_model;
(6)使用 current_model 对validation_sample进行验证,如果当前模型的性能得到目标或者已不
能再继续标注新的样本(没有专家或者没有钱),则结束迭代过程。否则,循环执行步骤(3)-
(6)。
3. 主动学习意义
在一些复杂的监督学习任务中,获取标注样本是非常困难:既耗时,而且代价昂贵。如,语音识别
(Speech recoginition)、信息提取(Information extraction)、分类和聚类(Classification and
filtering)等。主动学习系统尝试解决样本的标注瓶颈,通过主动选择一些最有价值的未标注样本
给相关领域的专家进行标注(主动学习系统试图通过要求以未标记的实例的形式进行查询来克服标
记瓶颈)。
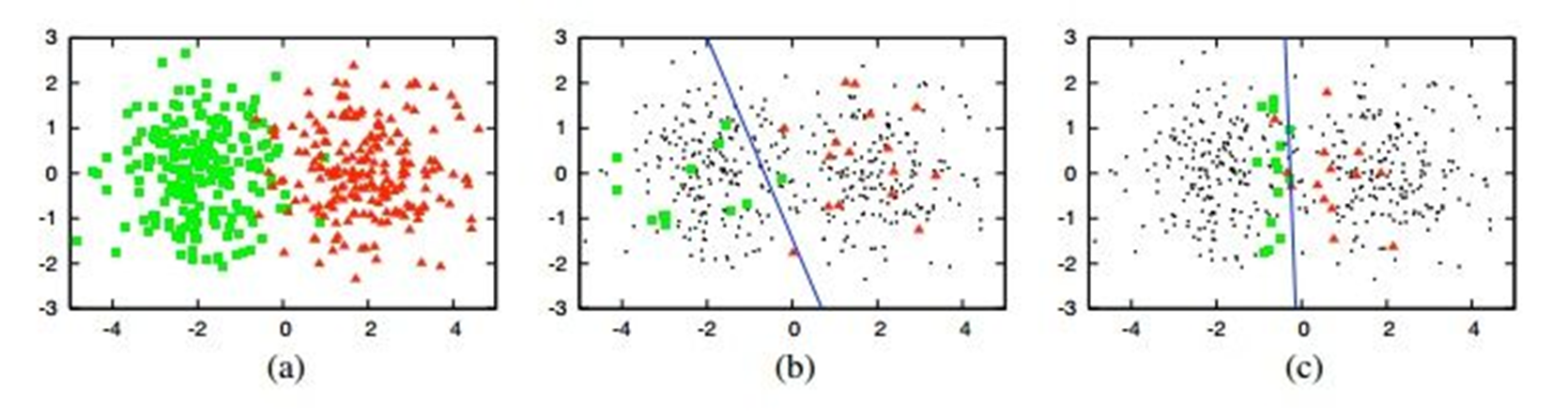
如下图所示,数据集(toy data)是从高斯分布产生的400个样本,任务是2分类问题(每个类有
200个样本),如(a)图所示将这些数据映射在2D特征空间上;图(b)使用了逻辑回归模型,通过训
练随机选择的30个标注样本,得到70%的验证精度,蓝色线表示决策边界(decision
boundary);图(c)同样使用逻辑回归模型,但训练的30个标注样本是通过主动学习(US策略)选
择而来,达到90%的验证精度。这个简单的案例体现了引入主动学习算法所带来的效果,同样使用
30个标注样本能够提升20%的精度。
 标注数据是一个很棘手的问题,特别是在生物医疗领域:1)需要具有相关专业知识的医生;2)成
标注数据是一个很棘手的问题,特别是在生物医疗领域:1)需要具有相关专业知识的医生;2)成
本很高;3)周期较长。

标注1000张X-Ray图片,大约需要3-4天,花费20000-30000元;标注同样数量CT图片,大约需要
10-20天,花费50000-70000元;然而,构建深度学习模型,需要不止1000张图片。
主动学习作为一种新的机器学习方法,其主要目标是有效地发现训练数据集中高信息量的样本,并
高效地训练模型。与传统的监督方法相比,主动学习具有如下优点:能够很好地处理较大的训练数
据集,从中选择有辨别能力的样本点,减少训练数据的数量,减少人工标注成本。
4. 主动学习问题场景
学习器能够在输入空间中为未标注数据集申请标签,包括“queries that the learner generates de
novo ”,而不是这些来自于同一个潜在分布的样本。
有效的“query synthesis”在解决特定领域的问题通常比较易于处理和高效,但如果主动学习的专家
环节是人工的话,标注任意样本这项工作往往很不合适(awkward)。
如:模式训练一个神经网络模型对手写体字母进行分类,遇到一个意外的问题,通过学习器生成的
许多 query images 都不包含可识别的符号(recognizable symbols),伪造的混合字符没有语义
(semantic meaning)。
同样地,当“membership queries”应用到 NLP 任务时可能会产生一些相当于乱语的文本或者语音
的数据流(streams of text or speech)。
因此提出基于数据流和基于池方法(stream-based and pool-based scenarios)来解决上述问题。
4.1 Stream-Based Selective Sampling
Stream-Based Selective Sampling 有一个重要的前提假设:可以免费或者便宜的获取相关领域的
未标注样本,因此就能够从真实的分布采集未标注的数据,然后学习器能够决定是否选择这些未标
注样本让专家标注。如果输入样本属于 uniform distribution,选择性采样(selective sampling)可
能跟 membership query learning 的效果一样好。
基于流的策略依次从未标注样例池中取出一个样例输入到选择模块,若满足预设的选中条件则对其
进行准确的人工标注,反之直接舍弃。该学习过程需要处理所有未标记样例,查询成本高昂。另
外,由于基于流的样例选择策略需要预设一个样例标注条件,但该条件往往需要根据不同的任务进
行适当调整,因此很难将其作为一种通用方法普遍使用。
4.2 Pool-Based Sampling
基于池的方法每次从系统维护的未标注样例池中按预设的选择规则选取一个样例交给基准分类器进
行识别,当基准分类器对其识别出现错误时进行人工标注。相较基于流的方法,基于池的方法每次
都可选出当前样例池中对分类贡献度最高的样例,这既降低了查询样例成本,也降低了标注代价,
这使得基于池的样例选择策略广泛使用。基于池的样例选择标准主要包括:不确定性标准、版本空
间缩减标准、泛化误差缩减标准等。
5. 分类问题的启发式方法(也属于选择/查询策略)
5.1 基于委员会的主动学习算法(QBC):熵值装袋查询(EBQ)、自适应不一致最大化(AMD)
在 QBC 算法中,使用标记样本训练多个参数不同的假设模型,并用于预测未标记的样本。因此,
QBC算法需要训练一定数量的分类器,在实际应用中,其计算复杂度相当大。为了约束计算量,
使用EQB方法简化计算。针对高维数据的情形,AMD算法能够将特征空间划分为子空间,它是
EQB算法的变形,不同的分类方法将相同的样本分类在不同的区域中,在计算过程中避免了维数灾
难的问题。该算法优点:分类器可以使用多种分类模型以及组合模式,如:神经网络,贝叶斯法则
等等。
5.2 基于边缘的主动学习算法(MS):边缘抽样、基于多层不确定性抽样、基于空间重构的抽样
对于边缘的启发式方法而言,主要针对支持向量机的情形。根据分类模型计算出样本到分类界面的
距离选择样本。在 MS算法中,仅仅选择距离分类界面最近的样本加入训练集,它是最简单的边缘
抽样的方法。而在 MCLU 算法中,与 MS 不同之处在于:选择离分类界面最远的两个最可能的样
本的距离差值作为评判标准。在混合类别区域中,MCLU能够选择最不确信度的样本,而MS的效
果不佳。在某些情形下,MS和 MCLU都会选出冗余的样本,引入多样性准则,剔除相似的样本,
减少迭代的次数。常用的多样性准则采用样本间相似度,即样本间的相似度越高,说明样本所反映
的数据特点越一致,则需要剔除该样本,反之,相似度越低。可以使用相似系数值来刻画样本点性
质的相似性。
5.3 基于后验概率的主动学习算法(PP):Kullback-Leibler最大化、Breaking Ties算法
基于概率的启发式方法依赖于样本的后验概率分布形式,所以该方法的计算速度最快。KL方法的
不足之处在于:在迭代优化过程中,它每次只能选择一个样本,增加了迭代的次数。此外,如果分
类模型不能提供准确的概率评估值,它依赖于之后的优化评估值。而在 BT 算法中,其思想类似于
EQB,在多分类器中,选择样本两个最大概率的差值作为准则。当两个最大的概率很接近时,分类
器的分类确性度最低。
6. 查询策略(Query Strategy)
选择当前模型认为最不确定的样本(如,分类问题,概率为0.5表示对该样本模棱两可,不确定性
很高),标注这类样本对提升当前模型最有帮助,US也是主动学习领域最常用的策略之一。但是
很少有人仅仅只用这种策略选择样本,其原因在于:US 策略仅仅考虑单个样本的信息,没有考虑
样本空间整体的分布情况,因此会找到 outlier 样本,或者一些冗余的样本。
随着大数据时代的到来以及计算能力的突飞猛进,深度学习在学术界和工业界取得了巨大的成就。
深度学习的各种成绩也同时给很多领域带来可能,近几年主动学习又开始在学术界蠢蠢欲动,结合
深度学习使得主动学习在一定程度上突破了瓶颈,在一些领域取得了不错的成绩(主要用来减少标
注代价)。
主动学习的关键在于“select strategy”,目前主要是一些手工设计的策略,一种选择策略仅仅能够应
用于某些特定的领域,类似于机器学习的手工设计特征。某种相似的套路:针对手工设计特征的局
限性,(分类任务)深度学习将特征选择和分类器结合,不再需要为分类器输入手工设计的特征,
取得了质的飞跃;同样的,文献“Learning Active Learning from Data”通过学习得到的“select
strategy”能够同时应用到多个不同的领域,克服了手工设计的选择策略跨领域泛化能力的不足。主
动学习领域还是有很多方面可以尝试的,毕竟如果做好了,确实能够给实际业务带来价值。