目录
- 1. 前言
- 2. IK分词器的特点
- 3. 引入IK分词器的依赖
- 4. 示例代码
- 5.结论
1. 前言
中文分词是将连续的中文文本切分成一个个独立的词语的过程,是中文文本处理的基础。IK分词器是一个高效准确的中文分词工具,采用了"正向最大匹配"算法,并提供了丰富的功能和可定制选项。
2. IK分词器的特点
- 细粒度和颗粒度的分词模式选择。
- 可自定义词典,提高分词准确性。
- 支持中文人名、地名等专有名词的识别。
- 适用于中文搜索、信息检索、文本挖掘等应用领域。
3. 引入IK分词器的依赖
IK分词器的实现是基于Java语言的,所以你需要下载IK分词器的jar包,并将其添加到你的Java项目的构建路径中。你可以从IK分词器的官方网站或GitHub仓库上获取最新的jar包。
<!-- https://mvnrepository.com/artifact/cn.shenyanchao.ik-analyzer/ik-analyzer -->
<dependency>
<groupId>cn.shenyanchao.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>9.0.0</version>
</dependency>
4. 示例代码
我们提供了一个简单的Java示例代码,展示了如何使用IK分词器进行中文文本分词。示例代码包括初始化分词器、输入待分词文本、获取分词结果等步骤。读者可以根据该示例快速上手使用IK分词器。
@SpringBootTest
class IkAnalyzerDemoApplicationTests {
@Test
void contextLoads() {
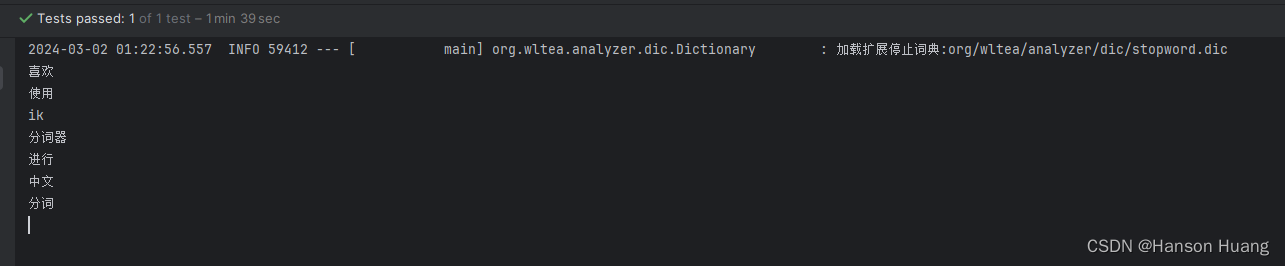
String text = "我喜欢使用IK分词器进行中文分词。";
try (StringReader reader = new StringReader(text)){
IKSegmenter ikSegmenter = new IKSegmenter(reader, true);
Lexeme lexeme;
while ((lexeme = ikSegmenter.next()) != null){
System.out.println(lexeme.getLexemeText());
}
}catch (IOException e){
e.printStackTrace();
}
}
}
在上述示例中,我们首先定义了一个待分词的文本字符串。然后,我们创建一个StringReader对象,将待分词的文本作为输入。接下来,我们创建一个IKSegmenter对象,并传入StringReader对象和true参数,表示启用智能分词模式。
在使用IKSegmenter对象进行分词时,我们使用next()方法获取下一个分词结果,返回一个Lexeme对象。我们通过调用getLexemeText()方法获取分词结果的文本内容,并将其打印输出
5.结论
IK分词器是一个功能强大的中文分词工具,可广泛应用于各种中文文本处理任务。本文通过介绍IK分词器的特点和使用方法,帮助读者了解和掌握中文分词的基本概念和操作。
在实际应用中,中文分词对于提高文本处理和信息检索的准确性和效率至关重要。通过使用IK分词器,我们可以更好地处理中文文本,从而提供更好的用户体验和结果。希望本文能为读者提供有价值的指导和启示,促进中文分词技术的应用和发展。