Linux磁盘性能方法以及磁盘io性能分析
- 1. fio压测
- 1.1. 安装fio
- 1.2. bs = 4k iodepth = 1:随机读/写测试,能反映硬盘的时延性能
- 1.3. bs = 128k iodepth = 32:顺序读/写测试,能反映硬盘的吞吐性能
- 2. dd压测
- 2.1. 测试纯写入性能
- 2.2. 测试纯读取性能
- 3.磁盘性能分析
- 3.1. 判断磁盘io打满
- 3.2. io打满是由于磁盘本身问题还是应用过量
- 3.3. 云盘的性能参考
- 4. 疑问和思考
- 4.1 %util能否代表磁盘io性能压力过大?
- 4.2 如何判断磁盘性能是否饱和?
- 4.3 如何判断磁盘性慢,是否与磁盘负载高还是低层设备io性能差?
磁盘性能是衡量计算机系统运行状况的关键因素之一。对于磁盘性能的测试和分析,Fio 和 dd 是两个常用的工具。在这篇文章中,将介绍如何使用 Fio 进行磁盘 I/O 测试,以及如何分析磁盘性能。同时,还会简单介绍 dd 工具的使用。
Fio 是一个灵活的 I/O 测试工具,支持多种工作模式,包括顺序读写、随机读写等。在安装 Fio 时,可以选择通过 yum 或编译源码进行安装。Fio 的测试报告中包含了丰富的信息,包括吞吐量和时延等指标。
除了 Fio 以外,dd 也是一个常用的磁盘测试工具。dd 可以用于测试磁盘的纯写入和纯读取性能。通过使用不同的参数,可以定制 dd 测试的读写块大小和读写次数等。
在分析了磁盘性能之后,可以使用 iostat 命令对磁盘的各项指标进行监控。iostat 可以显示磁盘的读写吞吐量、I/O 请求数等指标,帮助分析磁盘性能是否满足系统需求。另外,还需要参考磁盘类型的带宽参数,来判断磁盘性能的瓶颈可能来自哪里,例如磁盘本身的问题或者是应用程序的过量读写等。总之,在对磁盘性能进行测试和分析时,需要综合考虑多个方面的因素,才能更准确地判断系统的运行状况。
1. fio压测
1.1. 安装fio
使用yum安装
#yum安装
yum install fio
编译安装
# 下载Fio源码。
wget https://github.com/axboe/fio/archive/fio-2.1.10.tar.gz
#解压Fio源码。
tar -zxvf fio-2.1.10.tar.gz
#编译并安装Fio。
cd fio-fio-2.1.10
make
make install
#检查安装的Fio版本号。
fio --version
#回显信息如下,则Fio安装成功。
fio-2.1.10
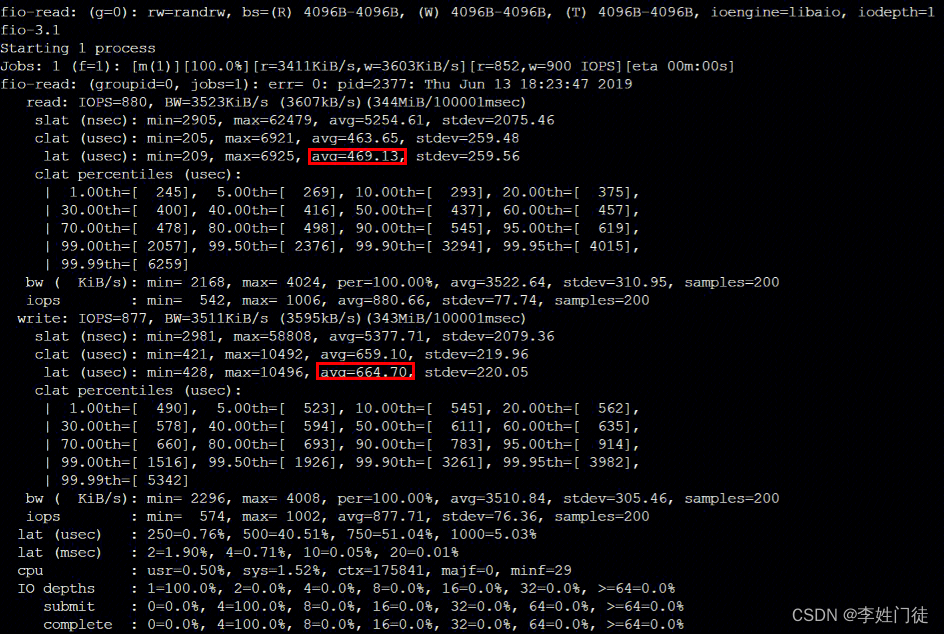
1.2. bs = 4k iodepth = 1:随机读/写测试,能反映硬盘的时延性能
# 测试硬盘的随机写时延。
fio -filename=/data/fio.txt -ioengine=libaio -direct=1 -iodepth 1 -thread -rw=randwrite -bs=4k -size=100G -numjobs=48 -runtime=300 -group_reporting -name=mytest
# 测试硬盘的随机读时延。
fio -filename=/data/fio.txt -ioengine=libaio -direct=1 -iodepth 1 -thread -rw=randread -bs=4k -size=100G -numjobs=48 -runtime=300 -group_reporting -name=mytest
查看测试报告
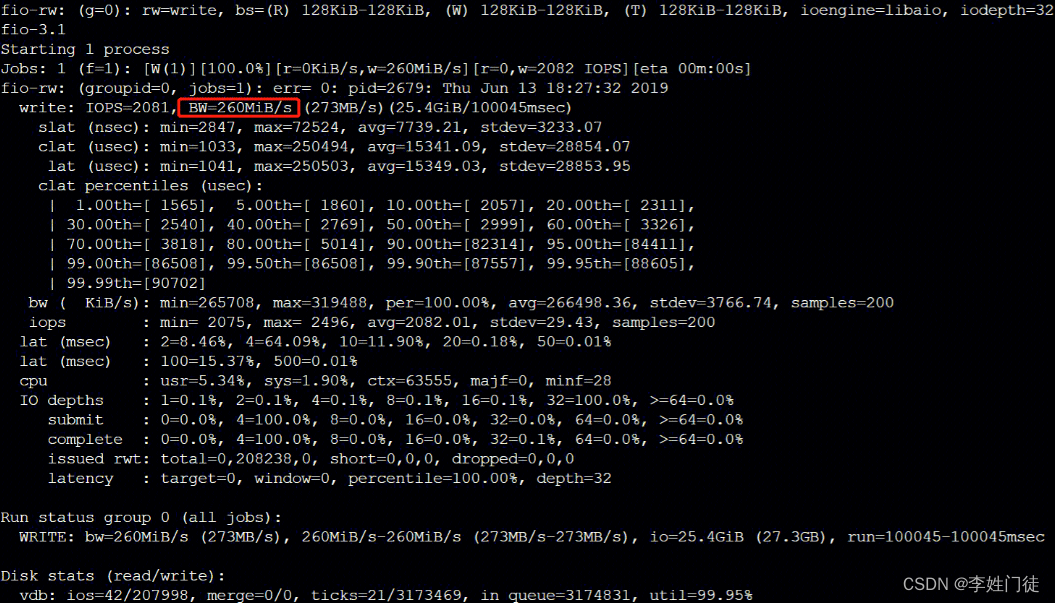
1.3. bs = 128k iodepth = 32:顺序读/写测试,能反映硬盘的吞吐性能
# 测试硬盘的随机写带宽。
fio -filename=/data/fio.txt -ioengine=libaio -direct=1 -iodepth 32 -thread -rw=randwrite -bs=128k -size=100G -numjobs=48 -runtime=300 -group_reporting -name=mytest
# 测试硬盘的随机读带宽。
fio -filename=/data/fio.txt -ioengine=libaio -direct=1 -iodepth 32 -thread -rw=randread -bs=128k -size=100G -numjobs=48 -runtime=300 -group_reporting -name=mytest
查看测试报告
2. dd压测
dd 也是我们经常使用到的磁盘测试工具,Linux服务器装好系统之后,想要知道硬盘的读写是否能满足服务的需要,如果不满足硬盘的IO就是服务的一个瓶颈。我们可以使用dd命令简单进行测试,更为专业的测试可以使用上面描述的fio 工具:
time有计时作用,dd用于复制,从if读出,写到of。if=/dev/zero不产生IO,因此可以用来测试纯写速度。同理of=/dev/null不产生IO,可以用来测试纯读速度。bs是每次读或写的大小,即一个块的大小,count是读写块的数量。
2.1. 测试纯写入性能
dd if=/dev/zero of=/data/testw bs=8k count=10000 oflag=direct
10000+0 records in
10000+0 records out
81920000 bytes (82 MB) copied, 3.07226 s, 26.7 MB/s
2.2. 测试纯读取性能
# 创造一个2G的可读文件
dd if=/dev/zero of=/data/testr bs=10M count=200
200+0 records in
200+0 records out
2097152000 bytes (2.1 GB) copied, 2.88613 s, 727 MB/s
# 测试纯读速度
dd if=/data/testr of=/dev/null bs=8k count=10000 iflag=direct
10000+0 records in
10000+0 records out
81920000 bytes (82 MB) copied, 3.07104 s, 26.7 MB/s
3.磁盘性能分析
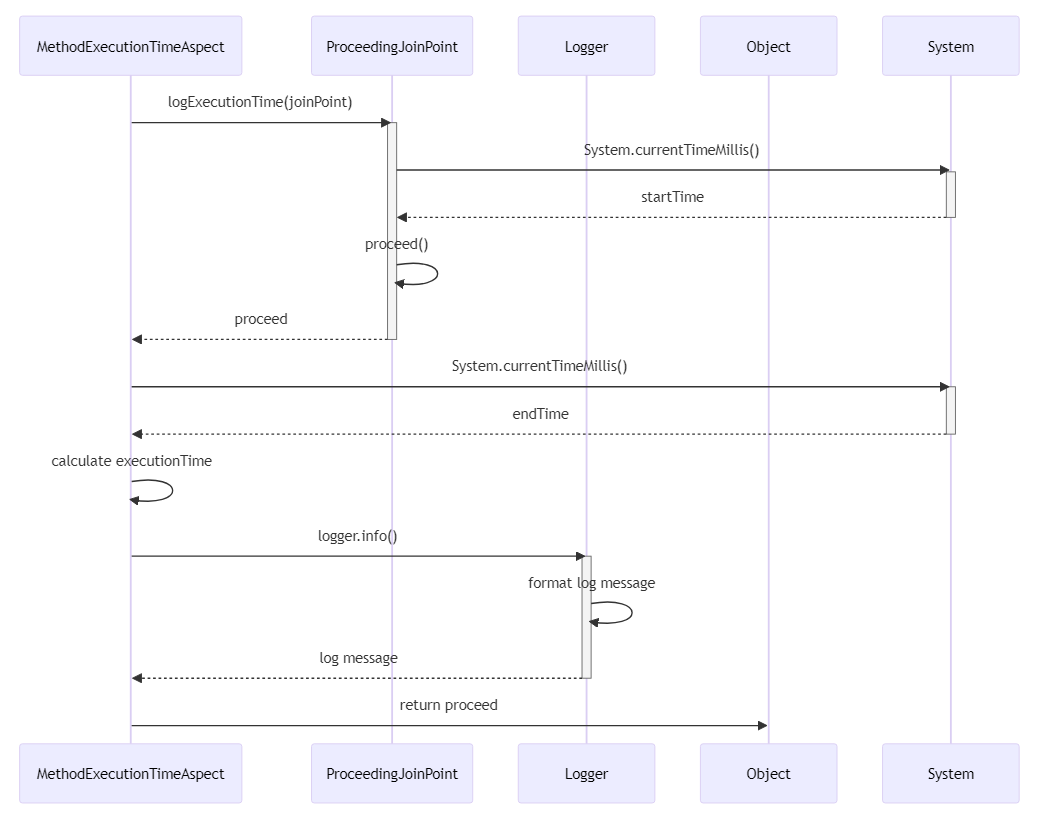
使用iostat命令可以获取当前硬盘的指标情况,以判断当前的硬盘性能是否足够。但是经常会遇到一些磁盘的ioutil已经打满,只能判断io性能不足,不能判断是否与应用对磁盘读写过高导致io打满,还是磁盘本身的性能不足导致小量的io读写就导致磁盘性能打满,常见的分析手段
iostat -mx 1
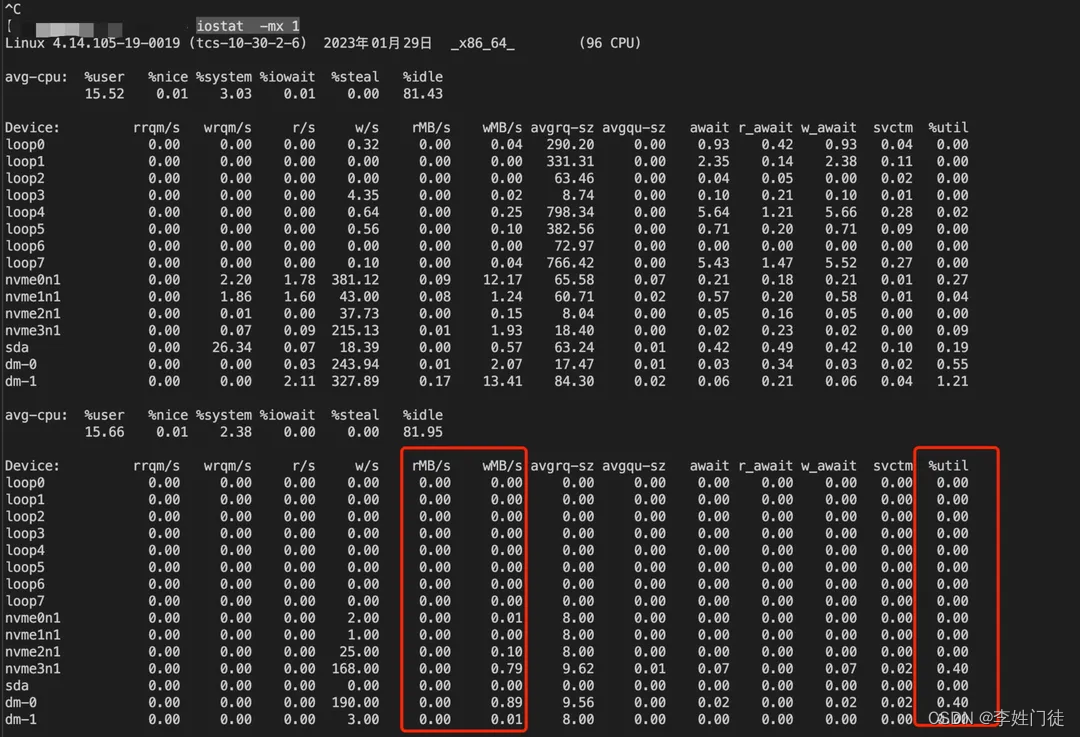
3.1. 判断磁盘io打满
如上图所示,ioutil标志当前磁盘的io打满情况,一般大于60%以上就认为磁盘的io有比较大的压力,如果持续90%以上,并且间歇性出现100%,则认为磁盘的io性能已经打满
3.2. io打满是由于磁盘本身问题还是应用过量
ioutil需要配合当前读写量配合看(标红部分),来判断是否当前的磁盘性能问题是来于底层本身的问题还是应用的磁盘读写过量导致。以ioutil使用率为90%为准绳,判断当前的磁盘读、写的带宽情况,常见的磁盘类型的带宽参考如下。
| 磁盘类型 | iops | 磁盘最大吞吐 | 备注 |
|---|---|---|---|
| 机械磁盘SATA | 150 | 150MB/s | 7200 rpm的磁盘IOPS = 1000 / (9 + 4.17) = 76 IOPS 10000 rpm的磁盘IOPS = 1000 / (6+ 3) = 111 IOPS 15000 rpm的磁盘IOPS = 1000 / (4 + 2) = 166 IOPS |
| SSD SATA | 3000~10000 | 250MB/s - 400MB/s | |
| nvme | 20w+ | 2GB/s + | |
| 内存 | 100w+ | 30~60 GB/s。 |
3.3. 云盘的性能参考
- 云硬盘类型
4. 疑问和思考
4.1 %util能否代表磁盘io性能压力过大?
不能。
%util是最容易让人产生误解的一个参数,很多初学者看到%util 等于100%就说硬盘能力到顶了,这种说法是错误的。
%util数据源自diskstats中的io_ticks,这个值并不关心等待在队里里面IO的个数,它只关心队列中有没有IO。
和超时排队结账这个类比最本质的区别在于,现代硬盘都有并行处理多个IO的能力,但是收银员没有。收银员无法做到同时处理10个顾客的结账任务而消耗的总时间与处理一个顾客结账任务相差无几。但是磁盘可以。所以,即使%util到了100%,也并不意味着设备饱和了。
最简单的例子是,某硬盘处理单个IO请求需要0.1秒,有能力同时处理10个。但是当10个请求依次提交的时候,需要1秒钟才能完成这10%的请求,,在1秒的采样周期里,%util达到了100%。但是如果10个请一次性提交的话, 硬盘可以在0.1秒内全部完成,这时候,%util只有10%。
因此,在上面的例子中,一秒中10个IO,即IOPS=10的时候,%util就达到了100%,这并不能表明,该盘的IOPS就只能到10,事实上,纵使%util到了100%,硬盘可能仍然有很大的余力处理更多的请求,即并未达到饱和的状态。
如下4张图,可以看到当IOPS为1000的时候%util为100%,但是并不意味着该盘的IOPS就在1000,实际上2000,3000,5000的IOPS都可以达到。根据%util 100%时的 r/s 或w/s 来推算磁盘的IOPS是不对的。

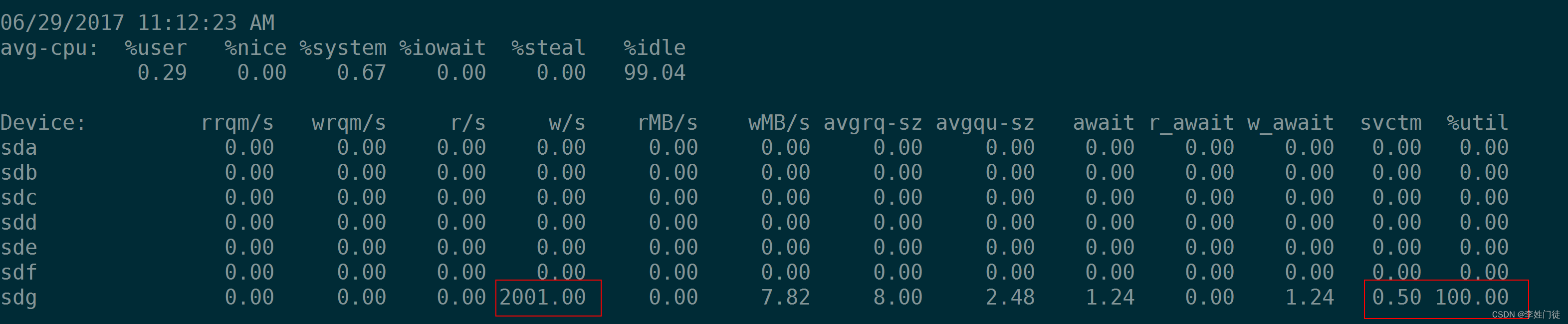
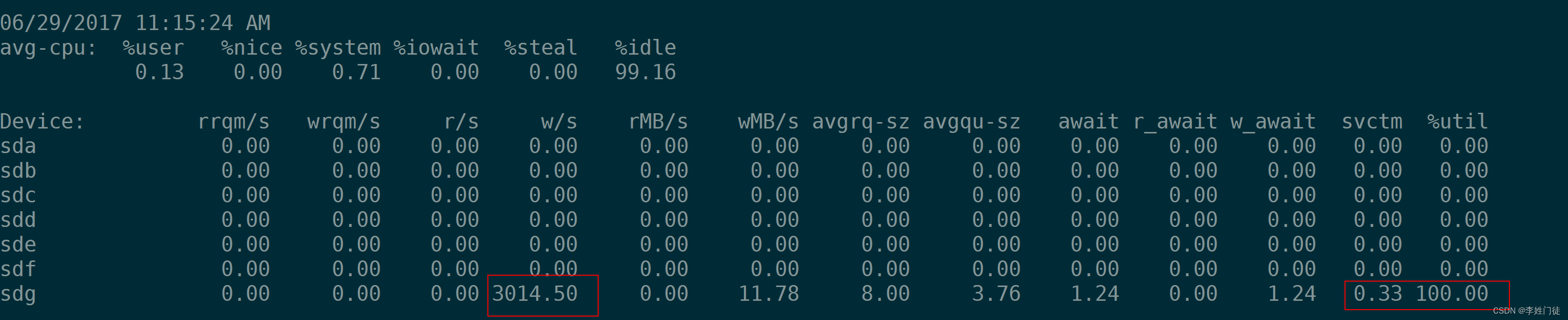
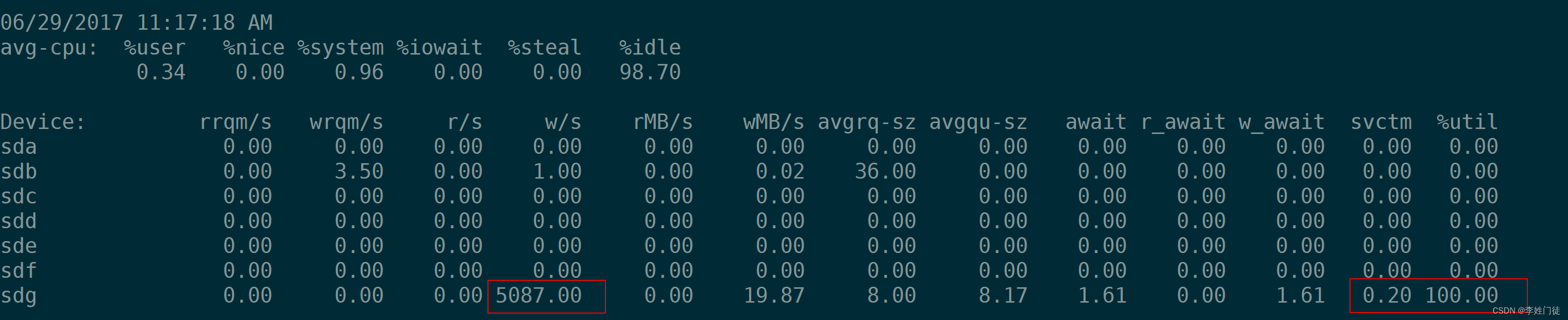
那么有没有一个指标用来衡量硬盘设备的饱和程度呢。很遗憾,iostat没有一个指标可以衡量磁盘设备的饱和度。
4.2 如何判断磁盘性能是否饱和?
通过使用iostat -xm 1获取磁盘的io使用情况,相关参数如下
$iostat -d -k 1 10
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 39.29 21.14 1.44 441339807 29990031
sda1 0.00 0.00 0.00 1623 523
sda2 1.32 1.43 4.54 29834273 94827104
sda3 6.30 0.85 24.95 17816289 520725244
sda5 0.85 0.46 3.40 9543503 70970116
sda6 0.00 0.00 0.00 550 236
sda7 0.00 0.00 0.00 406 0
sda8 0.00 0.00 0.00 406 0
sda9 0.00 0.00 0.00 406 0
sda10 60.68 18.35 71.43 383002263 1490928140
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 327.55 5159.18 102.04 5056 100
sda1 0.00 0.00 0.00 0 0
disk属性值说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
关键指标 svctm、await、avgque-sz
- 如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
- 如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
- 如果avgqu-sz比较大,也表示有当量io在等待。
await能够反映磁盘读写的正常时间,通常情况下,不应该超过5ms,因此可以通过该指标判断磁盘io性能是否已经达到瓶颈
4.3 如何判断磁盘性慢,是否与磁盘负载高还是低层设备io性能差?
磁盘io性能关键指标: svctm、await、avgque-sz
磁盘负载指标: w/s和r/s
两者相结合,判断磁盘的io慢是由于磁盘io负载高导致还是磁盘设备本身性能差导致
- svctm、await、avgque-sz 大,但是w/s和r/s 小,表示磁盘没有磁盘io高负载,但是磁盘io响应慢,大概率是磁盘低层设备性能差导致
- svctm、await、avgque-sz 大,w/s和r/s 大,表示表示磁盘磁盘io高负载,导致依然很慢,大概率是磁盘读写压力过大,导致磁盘io响应慢
参考云厂商磁盘io的磁盘读写吞吐情况