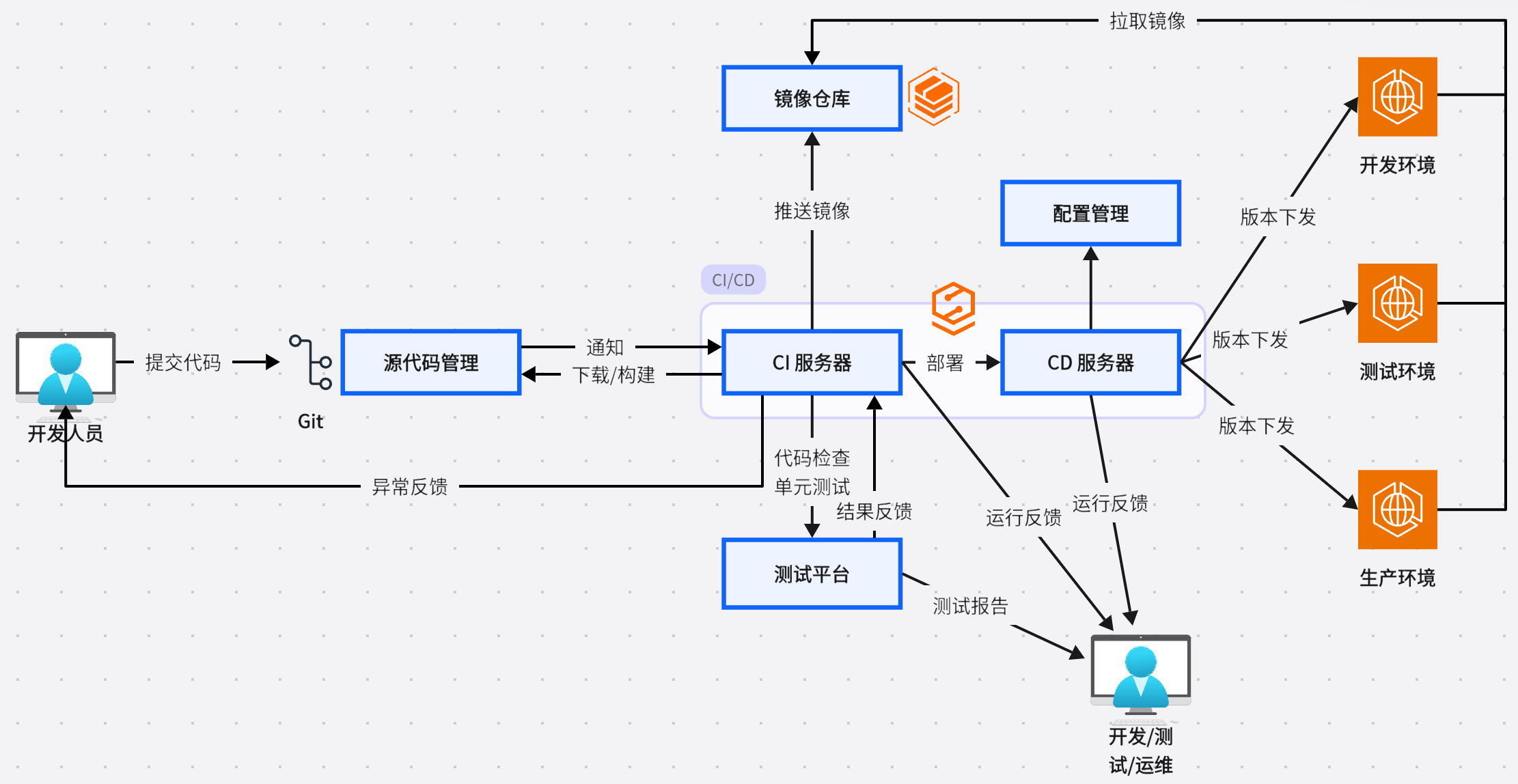
4.堆
堆
- 一个Java程序(main方法)对应一个jvm实例,一个jvm实例只有一个堆空间
- 堆是jvm启动的时候就被创建,大小也确定了。大小可以用参数设置。堆是jvm管理的一块最大的内存空间 核心区域,是垃圾回收的重点区域
- 堆可以位于物理上不连续的内存空间中,但在逻辑上是连续的
- 所有的线程共享堆,堆里还有TLAB(线程私有的缓冲区 Thread Local Allocation Buffer)
- 所有的对象及数组分配在堆里(如果对象在方法里面没有逃逸,理论上可以栈上分配,取决于jvm设计者的选择)
- 在方法结束后,堆中的对象不会被马上移除,垃圾回收时才会移除
- 内存细分:现代垃圾收集器大部分都基于分代收集理论设计
- 新生区=新生代=年轻代 养老区=老年区=老年代 永久区=永久代
- Java7及之前,堆内存逻辑上分为三部分:
- 新生代 Young/New Generation Space 又被分为 Eden区和 Survivor 0区 Survivor 1区(不空的为from区 空的为to区,to区是下一次要放的区域)
- 老年代 Old/Tenure Generation Space
- 永久代 Permanent Space
- Java8及之后,堆内存逻辑上分为三部分:新生代 老年代 元空间(Meta Space)
- 事实上,永久代 / 元空间 具体是方法区实现
- 当面试题问 jdk8内存结构有什么改变,要提出 永久代变成元空间
- 设置堆空间大小
- -Xms 用于设置堆空间(年轻代+老年代,不含元空间)初始大小(等价于 -XX:InitialHeapSize) 例子:-Xms10m
- -Xmx 用于设置堆空间最大大小(等价于 -XX:MaxHeapSize)例子:-Xmx10m
- 一旦堆空间超过 -Xmx 的值,就会报OOM
- 通常会设置 -Xms -Xmx为一样的值,目的是为了能够在Java垃圾回收完之后,不用再重新分隔计算堆区的大小,从而提高性能
- 默认情况下,初始内存 = 本机内存 / 64,最大内存 = 本机内存 / 4
- 查看堆空间大小
- java代码中 用Runtime.getRuntime().totalMemory() / 1024 / 1024 可以看到堆空间大小 多少兆
- 【输出的值和设置的值不一样】因为survivor区只能用其中一个,所以所有加起来能用的区域就少一些
- 或者cmd ,jps查看当前Java程序的进程id ,然后jstat -gc 进程id (代码加个 Thread.sleep() 执行长一些)
- 或者在vm参数加 -XX:+PrintGCDetails
- java代码中 用Runtime.getRuntime().totalMemory() / 1024 / 1024 可以看到堆空间大小 多少兆
- 年轻代和老年代
- 堆中可以分成两类对象
- 一种是生命周期较短的对象,创建和消亡十分迅速
- 另一种是生命周期比较长的对象,有些甚至和jvm生命周期一样
- 配置年轻代和老年代的比例(一般用默认值)
- 默认:-XX:NewRatio=2,表示 年轻代/老年代 = 1/2,年轻代占堆 1/3
- 配置 Eden区和Survivor区比例(一般用默认值)
- 默认:-XX:SurvivorRatio=8 ,表示 Eden区:Survivor 0:Survivor 1=8:1:1
- 不过直接看不是这个比例,因为jvm有自适应的内存分配策略,可能可以用 -XX:-UseAdaptiveSizePolicy(不太管用)
- 可以显式设置 -XX:SurvivorRatio=8
- 默认:-XX:SurvivorRatio=8 ,表示 Eden区:Survivor 0:Survivor 1=8:1:1
- 配置 Eden区最大大小(一般不用)【同时设置了比例和这个,以这个为准】
- -Xmn60m
- 几乎所有的对象都是从Eden区new出来的(很大的除外,很大的对象在Eden区YGC之后还放不下就放Old区)
- 堆中可以分成两类对象
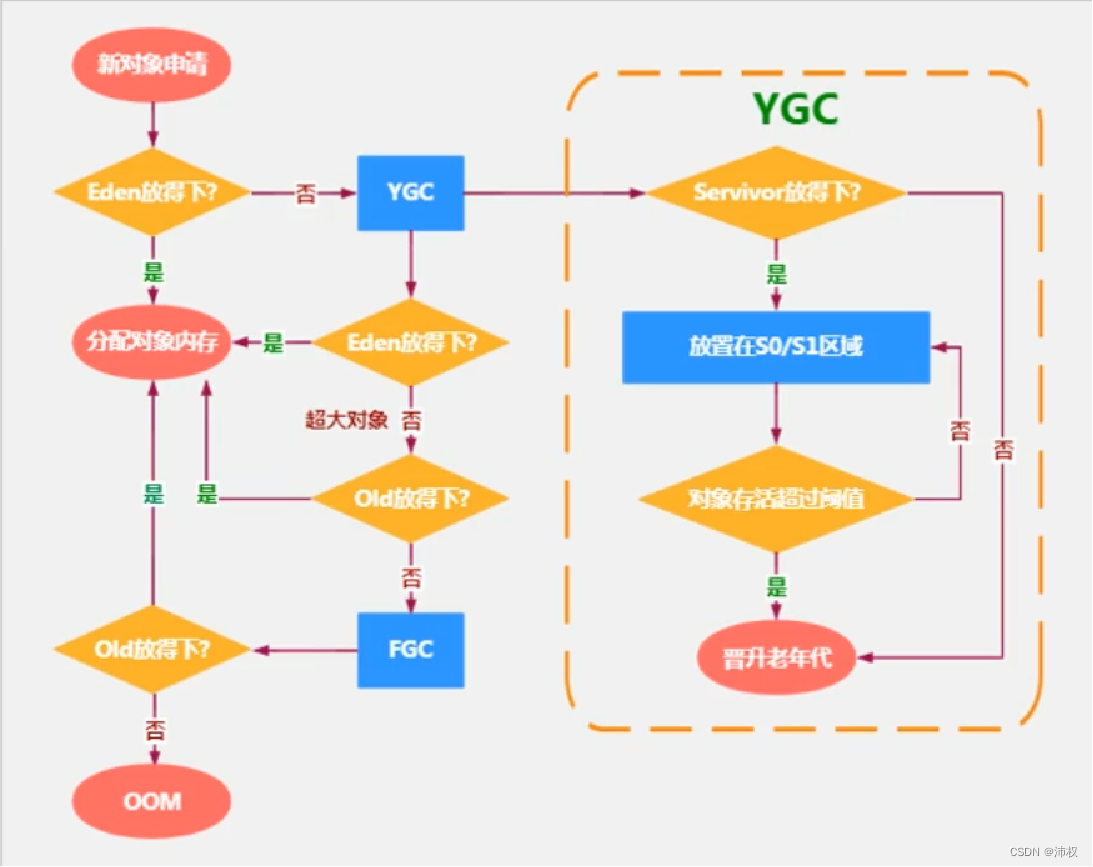
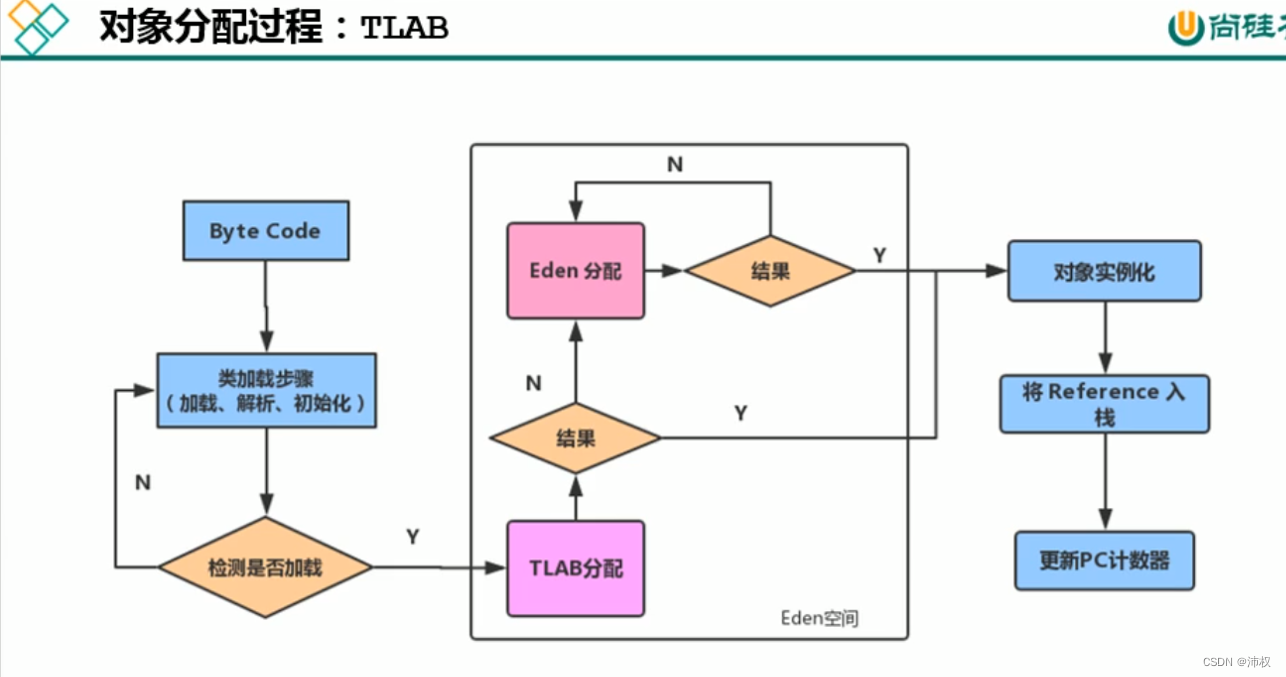
- 对象分配过程
- 1.new的对象先分配到Eden区
- 2.如果Eden区满了,会触发young/minor gc,垃圾回收Eden区和Survivor区。Eden区 和 Survivor区中没被回收的对象放到空的Survivor区,对象的age+1。然后再把新对象放到Eden区
- 3.如果这个对象过大,在Eden区YGC之后还放不下就放Old区
- 4.young gc后,当对象的age=15时,就是15次垃圾回收都没有被回收,就会放到 Old区
- 这个次数可以设置。-XX:MaxTenuringThreshould=15
- 5.young gc后,当Survivor区满了,会把Survivor区的对象放到Old区,即使不够15次
- 6.young gc后,当Old区满了,就会 Full gc
- (Survivor区满了,不会触发GC)
- 7.若Old区发生了Full gc 后,还是满的,就会OOM
- 【s0,s1区,复制之后有交换,谁空谁是to】
- 【关于垃圾回收,频繁Eden区,很少Old区,几乎不在永久区/元空间】
- GC
- 针对hotspot jvm,按回收区域分为两大类型:一种的部分收集(Partial GC),一种是整堆GC(full gc)
- 部分收集:在一部分堆空间进行垃圾回收
- 新生代收集 (Minor GC / Young GC):只收集Eden区 Survivor区
- 老年代收集(Major GC / Old GC):只收集 Old区
- 目前,只有CMS GC会有单独收集老年代的行为
- 很多时候,Major GC 和 Full GC混用,需要具体分辨是老年代回收还是整堆回收【很多帖子混淆】
- 混合收集(Mixed GC)收集整个新生代及一部分老年代
- 目前,只有G1 GC有这种行为
- 整堆收集(Full GC):收集整个堆和方法区
- 年轻代GC(Minor GC)触发机制:
- 当Eden区空间不足时触发,Survivor区满不触发,清理的是Eden区和Survivor区
- 因为Java对象大都是朝生夕灭的,所以Minor GC非常频繁,速度也比较快
- Minor GC会引发STW,暂停其他用户线程,等垃圾回收结束,用户线程才恢复执行
- 老年代GC(Major GC / Full GC 这样说不正确其实)触发机制:
- 发生在Old 区
- 出现Major GC 一般伴随着一次Minor GC (但非绝对,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC 的策略选择过程)
- 也就是在老年代空间不足时,会先尝试触发Minor GC。但之后空间如果还不足,则触发Major GC
- Major GC 的速度比Minor GC慢10倍以上,STW的时间更长
- 如果Major GC后,内存还不足,就OOM了
- Full GC触发机制:(后面细讲)
- 1.调用System.gc()时,系统建议使用Full GC,但是不必然执行
- 2.老年代空间不足
- 3.方法区空间不足
- 4.通过Minor GC 后进入老年代的平均大小大于老年代的可用内存
- 5.由Eden区,Survivor space0(From Space)区向Survivor space1(To Space)区进行复制时,对象大于To Space可用内存,则把对象转存到老年区,且老年区的可用内存小于该对象大小
- Full GC 是开发或调优中要尽量避免的,这样暂停时间短一点
- 为什么要把Java堆分代?不分代就不能工作嘛?
- 其实不分代可以,分代是为了优化GC性能。不分代的话,就要扫描整个堆。扫描范围大,比较耗时。而进行分代,把新创建的对象放到一个区域,因为大部分的对象生命周期很短,那么就可以对这个区域进行频繁GC。不用扫描整个堆,提高效率、
- 内存分配策略(或晋升(Promotion)规则)
- 优先分配到Eden区
- 大对象直接分配到老年代
- 尽量避免程序中出现过多的大对象(不仅仅是因为占很多空间,容易导致频繁Major GC或Full GC。而且因为这些大对象大部分生命周期也很短,往往是Major GC或Full GC之后就被清楚掉,不值得放到老年代)
- 长期存活的对象分配到老年代
- 动态对象年龄判断
- 如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄
- 空间分配担保
- -XX:HandlePromotionFailure 【Java7及以后,相当于默认开启此参数,改变设置也不起作用】
- TLAB——堆全部都是共享的嘛?不是
- 为什么有TLAB:因为堆是线程共享区域,而对象实例的创建在jvm中非常频繁,因此在并发环境下从对中划分空间是线程不安全的。为了避免多个线程操作同一地址,需要加锁的话,就会影响分配速度。有了TLAB,对象在TLAB里创建就不会有线程安全问题
- 尽管不是所有的对象都能在TLAB内创建,但是TLAB确实是jvm内存分配的首选
- 所有OpenJDK衍生出的jvm都有TLAB
- -XX:UseTLAB 设置是否开启TLAB空间,默认开启
- TLAB很小,默认占Eden区 1%
- -XX:TLABWasteTargetPercent 设置TLAB占Eden百分比大小
- 一旦对象在TLAB分配失败,就会在Eden中分配,使用时要加锁
- 栈上分配—逃逸分析—堆是对象分配的唯一选择嘛?是(逃逸分析->栈上分配),也可以不是(取决于jvm设计者要不要在栈上分配)
- 如果一个对象经过逃逸分析,发现没有逃逸,那么就会在栈上分配(不分配到堆上,减少GC压力)
- 而淘宝的TaoBaoVM,其中的GCIH(GC invisible heap)技术实现off-heap,将生命周期较长的Java对象从heap中移至heap外,并且GC不能管理GCIH内的Java对象,从而降低GC回收频率,提升GC回收效率
- **逃逸分析:**如果在方法内使用的对象,它会在除本方法外的其他地方用到,那就是逃逸
- 比如:作为参数传入,通过return返回,给对象属性赋值,使用对象属性
- 逃逸分析其实并不成熟。根本原因是无法保证做了逃逸分析的性能一定比不做好,因为逃逸分析也是一个相对耗时的过程。极端点就是经过逃逸分析发现没有一个对象是逃逸的,那么分析的过程就白白浪费了一些性能。
- 虽然不成熟,但是也是即时编译器优化技术中一个十分重要的手段。
- 重点:【通过逃逸分析,jvm会在栈上分配那些不会逃逸的对象,这种理论上是可行的,但是这取决于jvm设计者的选择。Oracle Hotspot JVM中并没有这样做,这一点在逃逸分析相关的文档里已经说明,所以,可以明确所以的对象实例都是创建在堆上。在实际代码测试中,运行速度加快,是因为虽然没有在栈上分配,但是jvm做了标量替换,加快了速度】
- 参数设置:
- 在Java7及以后,Hotspot默认开启逃逸分析
- 如果使用的是较早的版本
- -XX:+DoEscapeAnalysis 显式开启逃逸分析
- -XX:+PrintEscapeAnalysis 查看逃逸分析的筛选结果
- 所以,能使用局部变量,就不要在方法外定义
- 使用逃逸分析,jvm能做的优化
- 1.栈上分配
- 2.同步省略 / 锁消除:在动态编译同步块时,就是运行时,JIT编译器通过逃逸分析判断个对象是否只能从一个线程被访问到。如果是,那么JIT编译器在编译这个同步块时会取消对这部分代码的同步。大大提高性能和并发(不过字节码文件还是显示有锁的)
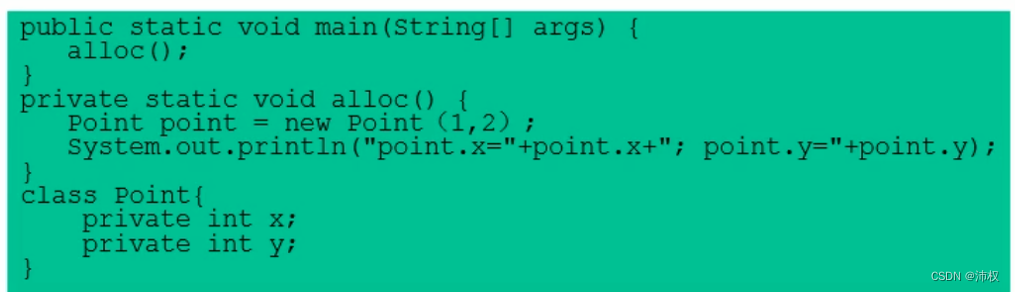
- 3.分离对象或标量替换:【简单的说就是不用对象,而是创建几个和对象属性对应的变量】有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在堆,而是存储在栈中
- 标量就是一个无法再分解成更小数据的数据。聚合量就可以再分解。对象就是聚合量
- JIT阶段,如果经过逃逸分析,发现对象不会逃逸,就会把那个对象分解成若干个标量。这个过程就是标量替换【比如下面两张图】
- 标量替换可以减少对象的创建,减少堆内存的分配,大大减少堆内存的占用。为栈上分配提供了很好的基础
- 参数:-XX:+EliminateAllocations 开启了标量替换,默认开启,允许将对象打散分配在栈上

- 常用命令
- -XX:+PrintFlagsInitial:查看所有的参数的默认初始值
- -XX:+PrintFlagsFinal:查看所有的参数的最终值(可能会存在修改,不再是初始值)
- -Xms:初始堆空间内存(默认为物理内存的1/64)【常用】
- -Xmx:最大堆空间内存(默认为物理内存的1/4)【常用】
- -Xmn:设置新生代的大小。(初始值及最大值)
- -XX:NewRatio:配置新生代与老年代在堆结构的占比
- -XX:SurvivorRatio:设置新生代中Eden和s0/S1空间的比例
- -Xx:MaxTenuringThreshold:设置新生代垃圾的最大年龄 【常用】
- -XX:+PrintGCDetails:输出详细的GC处理日志 【常用】
- 打印gc简要信息:1.-XX:+PrintGC 2.-verbose:go
- -XX:UseTLAB 设置是否开启TLAB空间,默认开启
- -XX:TLABWasteTargetPercent 设置TLAB占Eden百分比大小
- -XX:+DoEscapeAnalysis 显式开启逃逸分析,默认开启
- -XX:+PrintEscapeAnalysis 查看逃逸分析的筛选结果 【常用】
- -XX:+EliminateAllocations 开启了标量替换,默认开启,允许将对象打散分配在栈上
- -XX:HandlePromotionFailure:是否设置空间分配担保 【Java7及以后,相当于默认开启此参数,改变设置也不起作用】

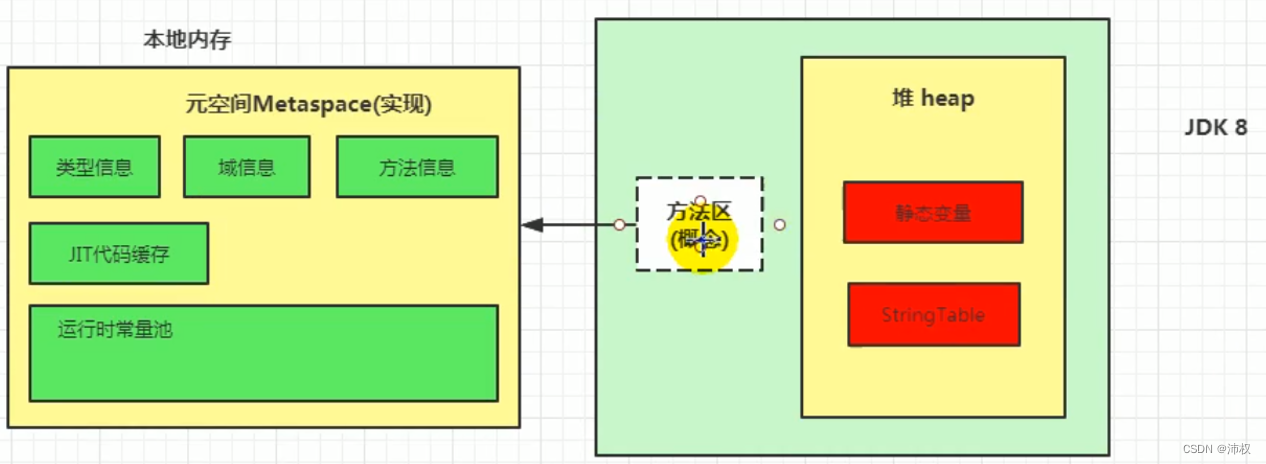
5.方法区 / 元空间
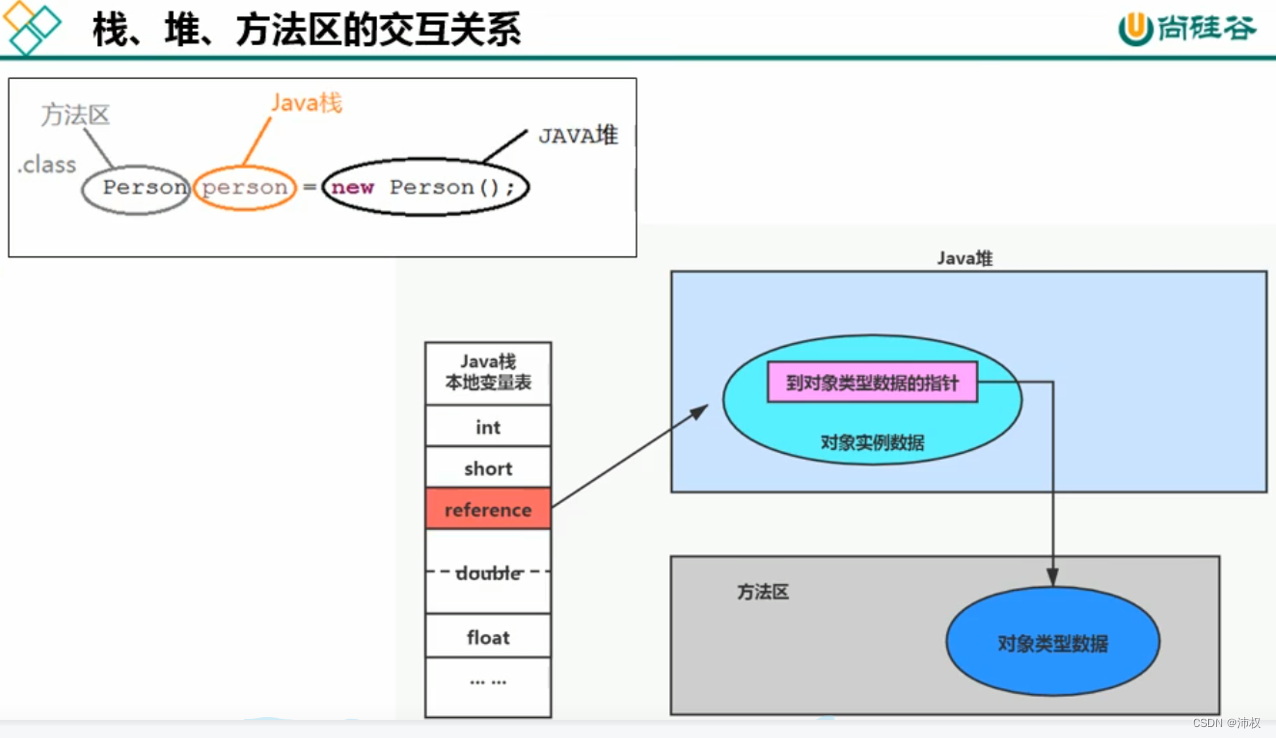
(对象类型数据 就是 类的数据)
方法区 / 元空间
- 方法区(Method Area)与Java堆一样,是各个线程共享的内存区域。
- 方法区在JVM启动的时候被创建,并且它的实际的物理内存空间中和Java堆区一样都可以是不连续的。
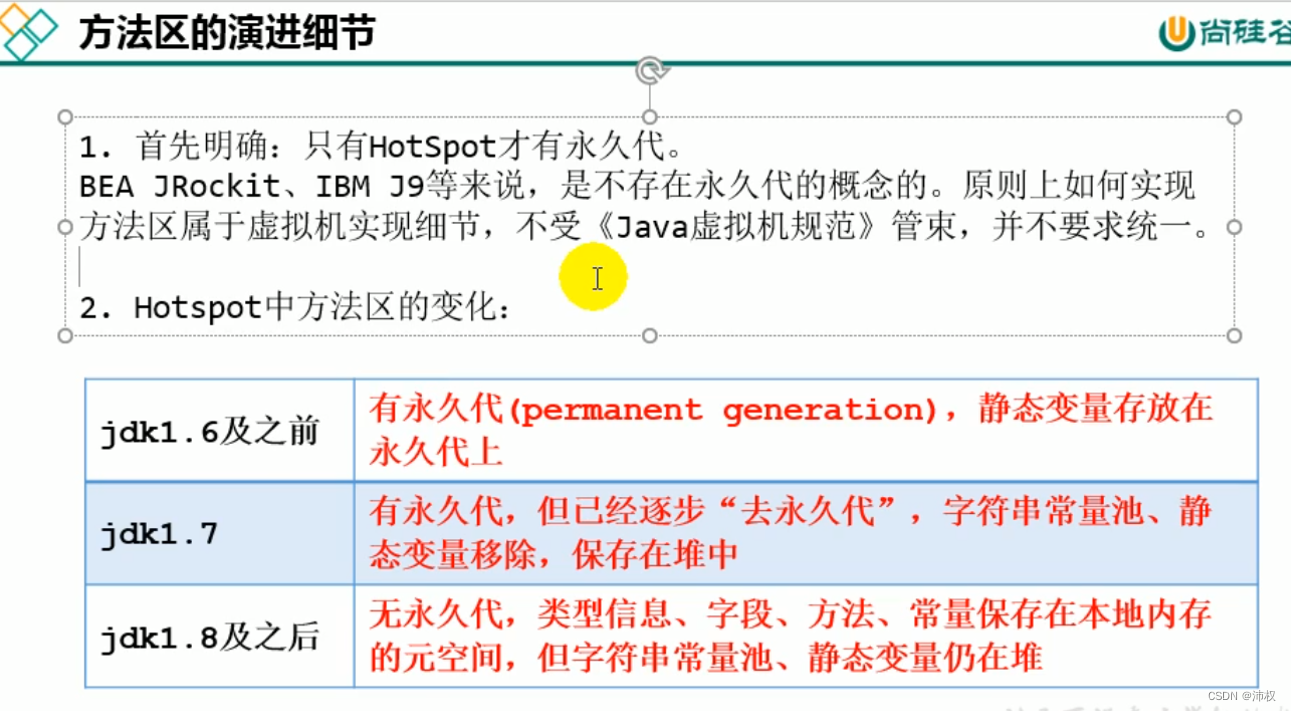
- 在Jdk7及以前,习惯把方法区称为永久代。Jdk8及以后,永久代变成了元空间
- 本质上,方法区和永久代不等价。仅是对Hotspot而言是等价的。《Java虚拟机规范》对如何实现方法区,不做统一要求。例如:BEA 的 JRockit / IBM 的 J9不存在永久代的概念
- 现在看来,当年用永久代,不是一个好想法。因为它导致Java程序更容易OOM(超过 -XX:MaxPermSize上限)
- 元空间与永久代类似,都是对jvm规范中方法区的实现。他们最大的区别在于:元空间不是使用Java虚拟机的内存,而是使用本地内存
- 元空间不仅仅是名称变了,内部结构也变了
- 方法区的大小,跟堆空间一样,可以选择固定大小或者可扩展。
- jdk7及以前
- -XX:PermSize=60m 来设置永久代初始分配空间。默认值是20.75m
- -XX:MaxPermSize=60m 来设置永久代最大可分配空间。32位机器默认64m,64位机器默认82m
- 当jvm加载的类超过最大大小,会报 java.lang.OutofMemoryError:PermGen space
- jdk8及以后
- 元数据区大小可以使用参数-XX:MetaspaceSize=100m和-XX:MaxMetaspaceSize指定
- 默认值依赖于平台。window下,-XX:MetaspaceSize是21m,-XX:MaxMetaspaceSize是-1,即没有限制,会一直用系统内存
- jdk7及以前
- 高水位线(在jdk8及以后)
- 初始的高水位线 和 -XX:MetaspaceSize的值一样。一旦元空间大小触及到这条线,Full GC就会被触发并卸载没用的类(即这些类对应的类加载器不再存活),然后这个高水位线就会被重置。新的高水位线的值取决于GC后释放了多少元空间。如果释放的空间不足,那么在不超过MaxMetaspaceSize时,适当提高改值。如果释放的空间过多,适当降低该值。
- 如果初始的 高水位线设置过低,上述 高水位线调整情况会发生很多次,也会频繁Full GC。建议将-XX:MetaspaceSize设置为一个相对较高的值
- 方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误:java.lang.OutofMemoryError:PermGen space (java7及之前) 或者 java.lang.OutofMemoryError:Metaspace(java8及以后)
- 加载大量的第三方的jar包会OOM:Tomcat部署的工程过多(30-50个) , 大量动态的生成反射类
- 关闭JVM就会释放这个区域的内存。
- OOM的例子:


- 方法区存的内容
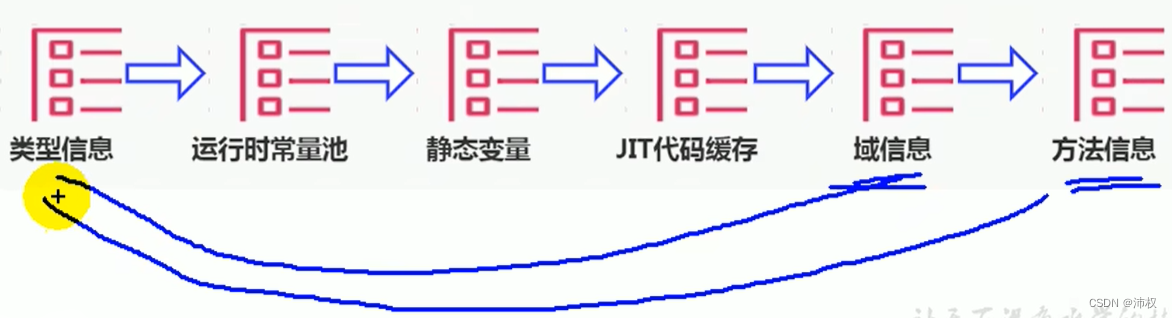
- 存放已被虚拟机加载的类型信息,常量,静态变量,JIT即时编译器编译后的代码缓存等。(随jdk版本不同,会有些变化)
- 类型信息(类,接口,枚举,注解)
- 这个类型的完整有效名称(全名=包名.类名)
- 这个类型直接父类的完整有效名(对于接口和Object类都没有父类)
- 这个类型的修饰符(public,abstract,final的某个子集)
- 这个类型实现的接口的一个有序列表
- 域(Field)信息(就是类的属性信息)
- jvm必须在方法区中保存类型的所有域的相关信息以及域的声明顺序
- 域的相关信息包括:域名称、域类型、域修饰符(public,private,protected,static,final,volatile,transient的某个子集)
- 方法(Method)信息
- jvm必须在方法区中保存所有方法的以下信息以及域的声明顺序
- 方法名称
- 方法的返回类型(或 void)
- 方法参数的数量和类型(按顺序)
- 方法的修饰符(public,private,protected,static,final,synchronized,native,abstract的一个子集)
- 方法的字节码(bytecodes)、操作数栈、局部变量表及大小(abstracth和native方法除外)
- 异常表(abstracth和native方法除外)
- 每个异常处理的开始位置、结束位置、代码处理在程序计数器中的偏移地址、被捕获的异常类的常量池索引
- 类变量(static)
- 没加final的:静态变量和类关联在一起,随着类的加载而加载,它们成为类数据在逻辑上的一部分,但是放到堆中
- 加了final的:在编译期就确定下来了,放到元空间
- 运行时常量
- 方法区中的运行时常量池和字节码文件中的常量池的对应起来的
- Java中的字节码需要数据支持,通常这种数据很大不能直接放到字节码文件中,换另一种方式,可以存到常量池,在动态链接时再引用进来
- 字节码的常量池包括各种字面量,和对类型、域、方法的符号引用
- jvm为每个已加载的类型(类或接口)都维护一个常量池,通过索引访问
- 运行时常量池 把 字节码文件的常量池中的符号引用 转成了直接引用
- 运行时常量池 相当于Class文件常量池的另一重要特征是:具备动态性(有些没有的东西会自动加进去)
- 运行时常量池类似于传统编程语言中的符号表(symbol table),但是它所包含的数据却比符号表要更加丰富一些
- 如果创建运行时常量池超过方法区的最大值,会OOM
- 方法区中的运行时常量池和字节码文件中的常量池的对应起来的
- 还包含了加载这个字节码文件的 类加载器
- 方法区的演进细节
-
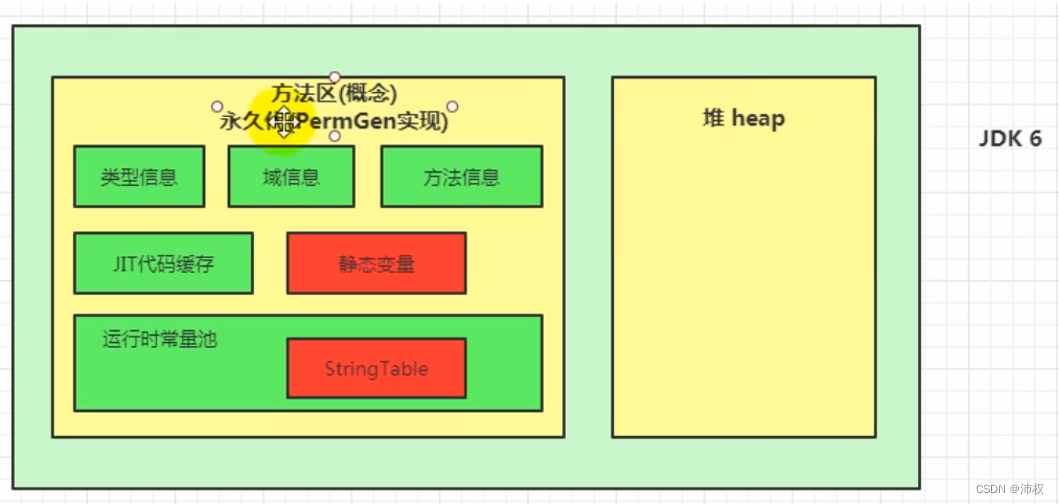
jdk1.6及之前,有永久代,静态变量存放在永久代上
-
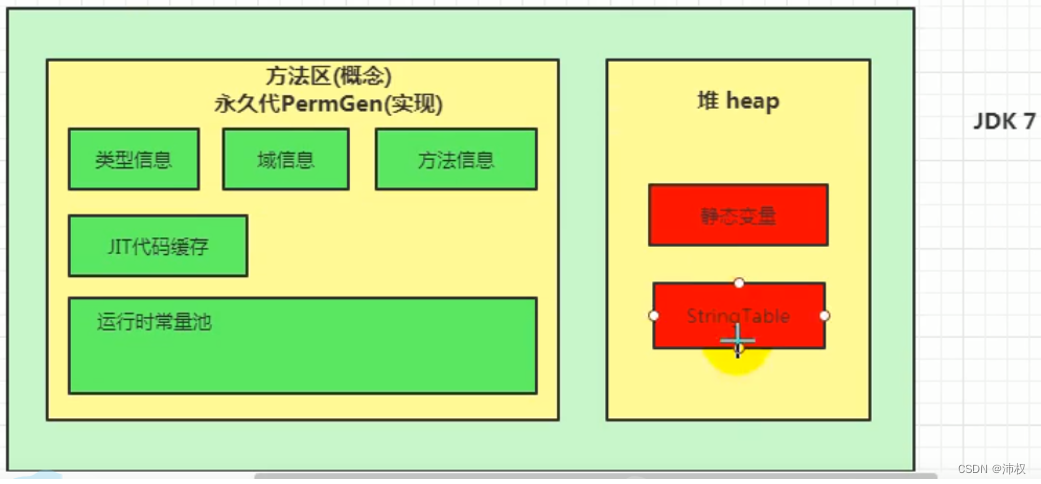
jdk1.7,有永久代,但已经逐步“去永久代”,字符串常量池、静态变量保存到堆中
-
jdk1.8及以后,无永久代,类型信息、字段、方法、常量保存在本地内存的元空间。但字符串常量池,静态变量仍然在堆中
-
【要注意:如果静态变量是对象的引用。比如:public static a = new int[10] 无论是哪个jdk,数组都是在堆中。因为它是被new 出来的对象。而变量a在不同jdk的位置就不一样】
-
- 为什么元空间要替代永久代?
- 1.为永久代设置大小是很难的。设置小了在某些场景下容易OOM,特别是要动态加载很多类的时候。设置大了浪费空间。元空间使用本地内存,不用设置,仅仅受内存大小的限制
- 2.对永久代进行调优是很困难的。Full GC的时候会对方法区的垃圾回收。判断类型信息是否要清理比较满分。所以Full GC比较麻烦,调优也比较困难。用本地内存,空间大一些,Full GC也会少一些
- 为什么StringTable要放到堆里
- jdk7中将StringTable放入堆中。因为永久代很少进行垃圾回收,只有触发Full GC的时候才会进行清理。Full GC只有在老年代空间不足,或者永久代空间不足才会触发,这就导致StringTable的回收效率不高。在运行过程中,大量的字符串常量被创建,很多都是不用的,放到堆中可以及时清理
- 方法区的垃圾回收
- 有的虚拟机支持方法区GC,有的没有GC。Java的虚拟机规范对方法区的约束很宽松,方法区实不实现垃圾回收都可以。(JDK 11的ZGC收集器就不支持类卸载)
- 方法区的回收效果比较难以让人满意,尤其是类型的卸载,条件很苛刻。但是这部分区域的回收有时又确实是必要的。以前Sun公司的Bug列表中,曾出现的几个严重的BUG就是因为低版本的hotspot对方法区未完全回收导致内存泄露
- 主要回收两部分内容:常量池中废弃的常量 以及 不再使用的类型
- 常量包括字面量 和 符号引用
- 符号引用包括,类和接口的全限定名,字段的名称和描述符,方法的名称和描述符
- 常量只要没有地方使用 就可以回收
- 但是类型是否回收的判断条件很苛刻,下面是被回收的前提(但是满足了也不一定会回收)
- 1.该类没有实例。也没有任何派送子类的实例
- 2.加载该类的类加载器已经被回收。除非是精心设计的可替换类加载器的场景,比如OSGI,JSP的重加载等,否则很难达成
- 3.该类对应的java.lang.class对象没有被任何地方引用,无法在任何地方通过反射访问该类的方法
- Java虚拟机被允许对满足上述三个条件的无用类进行回收,这里说的仅仅是“被允许”,而并不是和对象一样,没有引用了就必然会回收。关于是否要对类型进行回收,HotSpot虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class以及-XX:+Traceclass-Loading、-XX:+TraceClassUnLoading查看类加载和卸载信息
- 常量包括字面量 和 符号引用
- 在大量使用反射、动态代理、CGLib等字节码框架,动态生成JSP,以及OSGi这类频繁自定义类加载器的场景中,通常需要Java虚拟机具备类型卸载的能力,以保证不会对方法区造成过大的内存压力。