目录
启动nacos
项目步骤
Nacos服务分级存储模型编辑
服务跨域集群调用问题
NacosRule负载均衡
服务实例的权重设置
环境隔离-namespace
Nacos环境隔离
Nacos和Eureak对比
临时实例和非临时实例
Ncaos与Eureka的共同点
Nacos与Eureka的区别
Nacos配置管理
统一配置管理
实现
总结(将配置交给Nacso管理的步骤)
热更新
多环境配置共享
步骤
多环境配置优先级
Nacos集群搭建
1.集群结构图
2.搭建集群
2.1.初始化数据库
2.2.下载nacos
2.3.配置Nacos
2.4.启动
2.5.nginx反向代理
2.6. 优化
总结
HTTP客户端Feign
1.RestTemplate方法调用存在的问题
Feign的介绍
定义和使用Feign客户端
Feign的使用步骤
自定义Feign的配置
自定义Feign的配置
方式一:配置文件方式
方式二:Java代码配置
总结
Feign的性能优化
Feign地城的客户端实现
因为优化Feign的性能主要包括:
Feign的性能优化-连接池配置
Feign添加HttpClient的支持:
总结
Feign的最佳实践
方式一(继承)
方式二(抽取):
实现
当定义的FeignClient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用。有两种方式解决:
总结
总结
统一网关Gateway
为什么需要网关
网关功能
网关的技术实现
总结
gateway快速入门
搭建网关
总结
断言工厂
网关路由可以配置的内容包括
断言工厂
spring提供了11种基本的Predicate工厂编辑
实例
测试1
测试2
过滤器工厂
总结
全局过滤器
总结
过滤器执行顺序
总结
跨域问题
总结
启动nacos
D:\Student\SpringCloudAlibabadown\nacos\bin\startup.cmd
个人配置9001端口
项目步骤
-
在父项目确定alibaba.cloud版本。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>-
在子项目(或者需要使用的项目中)添加nacos包
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <version>2.2.5.RELEASE</version> </dependency> -
在配置文件中配置添加nacos
cloud: nacos: server-addr: localhost:9001成功实现

Nacos服务分级存储模型
服务跨域集群调用问题
服务调用尽可能选择本地集群的服务,跨集群调用延迟较高 本地集群不可访问,再去访问其他集群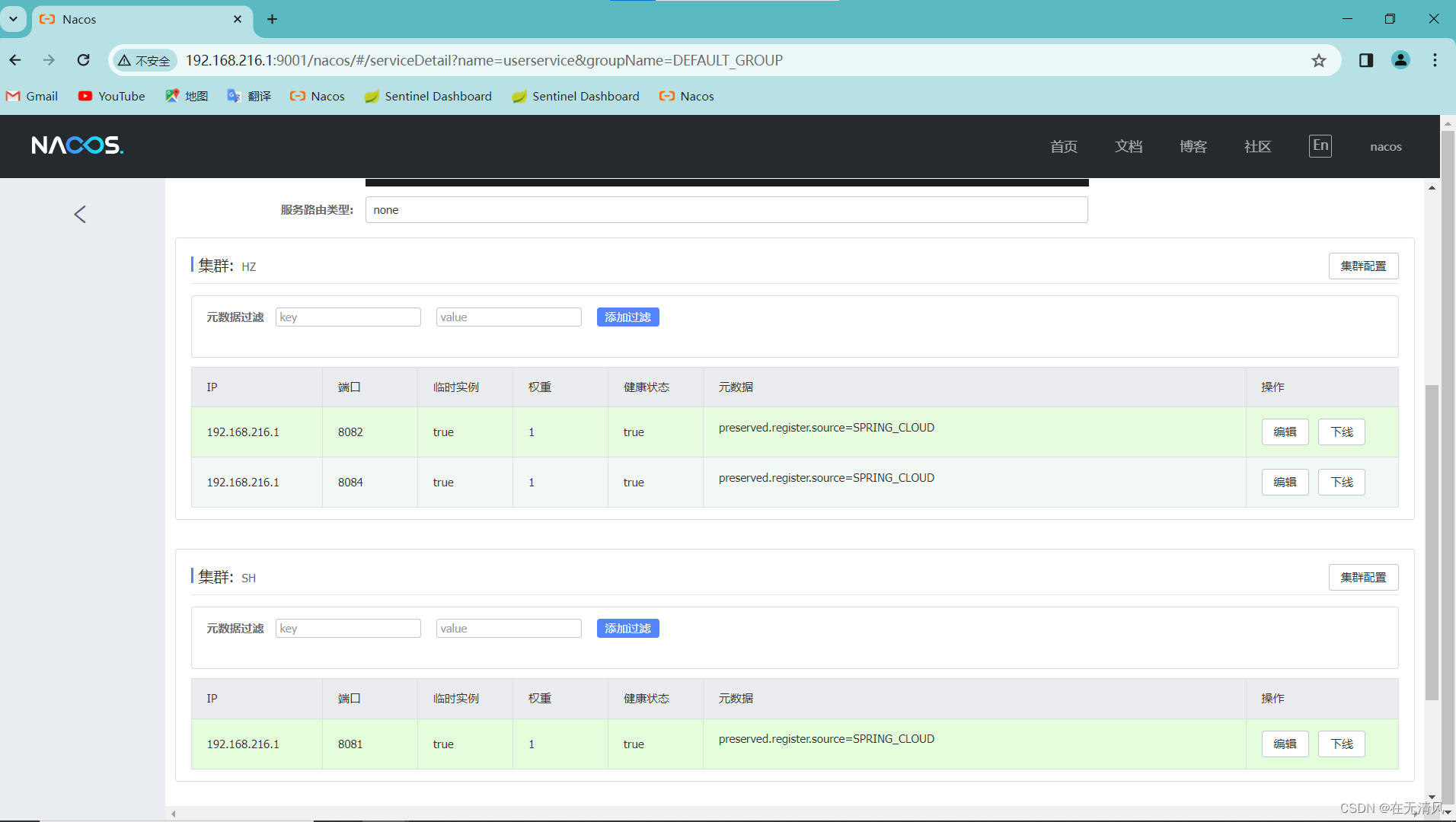
-
Nacos服务分级存储模型
-
一级是服务,列入userservice
-
二级是集群,例如杭州和上海
-
三级是实例,例如杭州机房的某台部署了userserviec的服务器
-
-
如何设置实例的集群属性
-
修改application.yml文件,添加spring.cloud.nacos.discovry.cluster -name属性即可如下:
cloud: nacos: server-addr: localhost:9001 # nacos地址 discovery: cluster-name: SH # 集群名称,代指杭州
-
NacosRule负载均衡
修改客户端的application.yml
cloud:
nacos:
server-addr: localhost:9001 # nacos地址
discovery:
cluster-name: SH # 集群名称,代指杭州在客户端中设置负载均衡的IRule未NacosRule,这个规则优先会寻找与自己同集群的服务:
userservice:
ribbon:
NFLoadbalancerClassName: com.alibaba.cloud.nacos.ribbon.NacosRule注意将项目的权重都设置为1
-
NacosRule负载均衡策略
-
优先选着同集群服务实例列表
-
本地集群找不到提供者,才回去其他集群寻找,并且会报警告
-
确定了可用实力列表后,在采用随机负载均衡挑选实例
-
服务实例的权重设置
-
实例的权重控制
-
Nacos控制台可以设置实例的权重值,0~1之间
-
同集群内的多个实例,权重越高北访问的频率越高
-
权重设置为0则完全不会被访问
-
环境隔离-namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离
-
在Nacos控制台可以创建namespace,用来隔离不同环境

-
然后填写一个新的命名空间信息(不填写id,则UUID自动生成id)
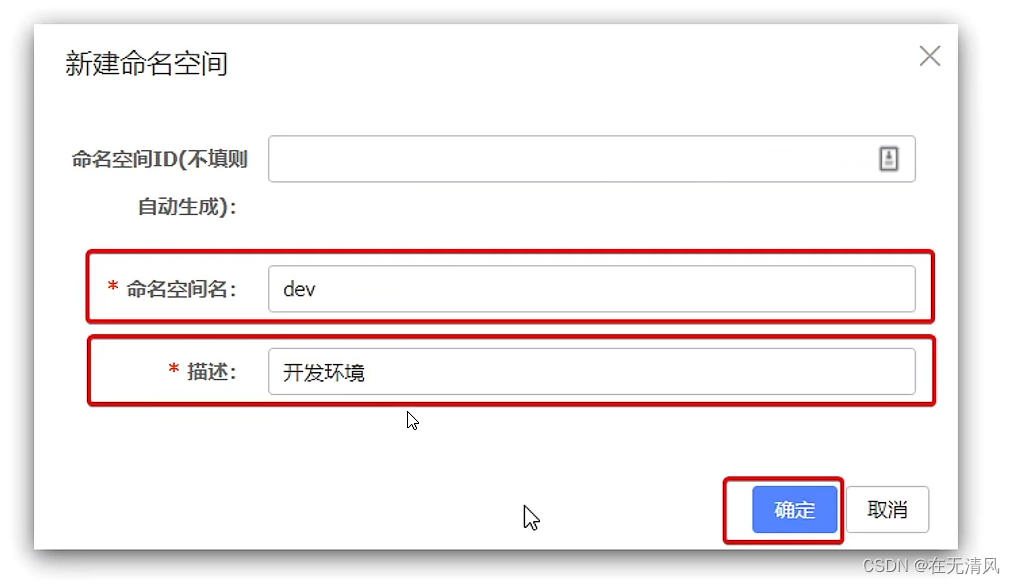
-
保存后会在控制台看到这个命名空间的id:
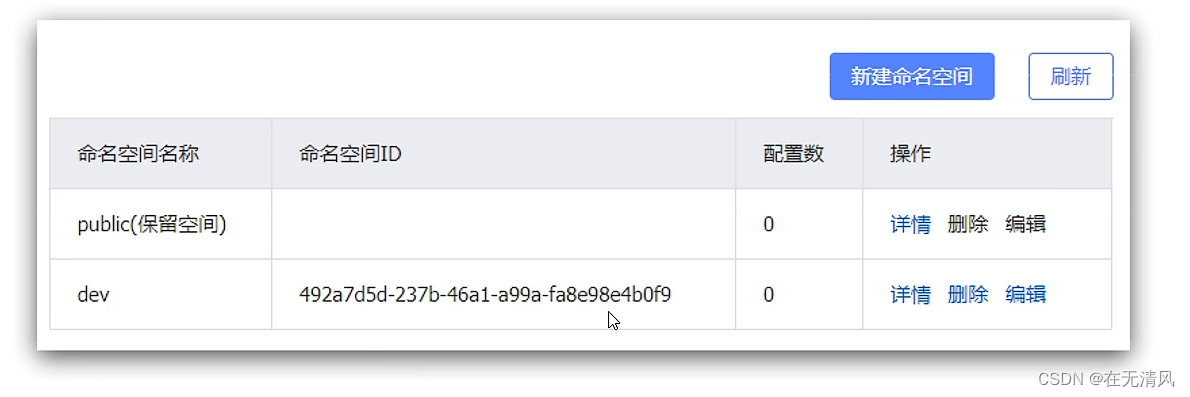
-
修改需要配置的项目的application.yml,添加namespace:
spring:
datasource:
url: jdbc:mysql://localhost:3306/cloud_order?useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
application:
name: orderservice #服务名称
cloud:
nacos:
server-addr: localhost:9001
discovery:
cluster-name: SC # 集群名称,代指杭州
namespace: e371f002-c878-4ceb-8339-5e605150395e #命名空间-
Nacos环境隔离
-
namespace用来做环境隔离
-
每个namespace都是唯一id
-
不同的namespace下的服务不可见
-
Nacos和Eureak对比
临时实例
临时实例如果健康状态为false时会被剔除,但非临时实例不会被剔除,而是等待实例恢复健康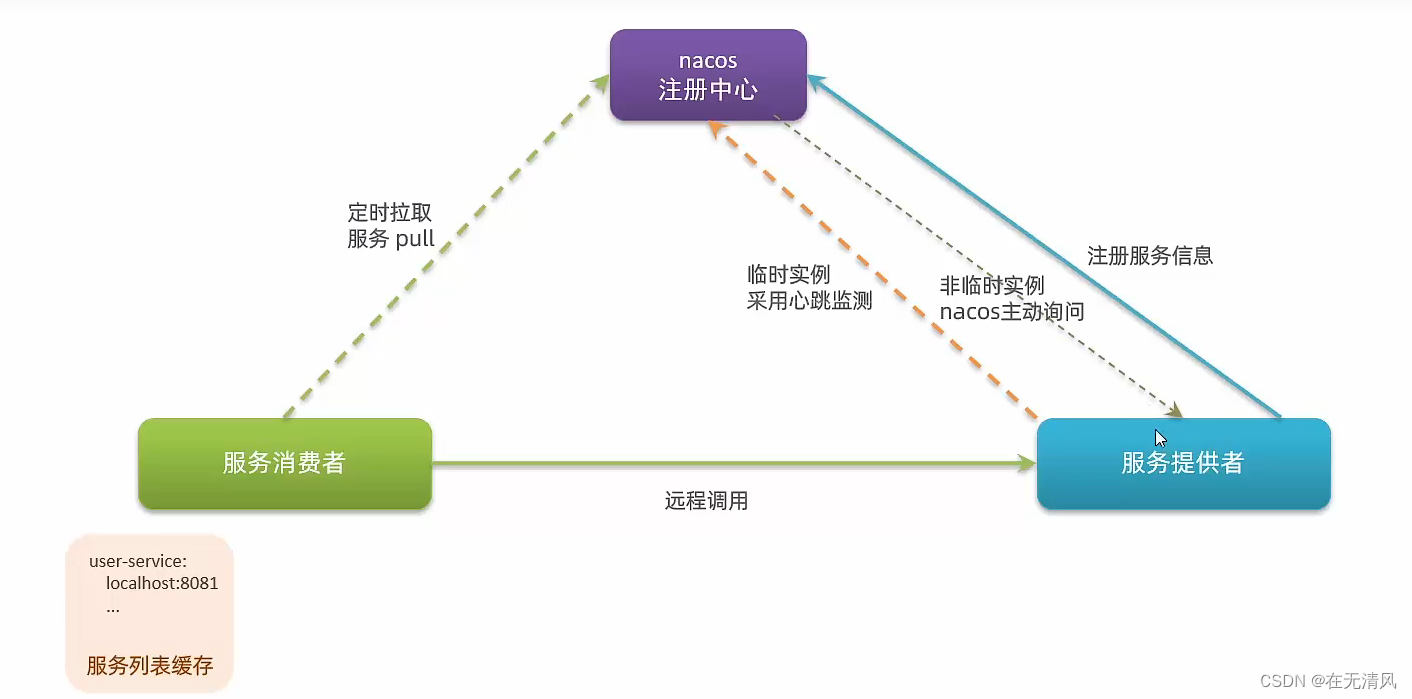
临时实例和非临时实例
服务注册到Nacos时,可以选择注册为临时实例或非临时实例,通过下面的配置来设置(ephemeral为ture时临时实例,为false时非临时实例):
cloud:
nacos:
server-addr: localhost:9001
discovery:
cluster-name: SC # 集群名称,代指杭州
namespace: e371f002-c878-4ceb-8339-5e605150395e #命名空间
ephemeral: false #是否临时节点即使健康为false时也不会停止实例

-
Ncaos与Eureka的共同点
-
都支持服务注册和服务拉取
-
都支持服务提供者心跳方式做健康检测
-
-
Nacos与Eureka的区别
-
Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
-
临时实例的心跳不正常会被剔除,非临时实例则不会被剔除
-
Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
-
Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用cp模式;Eureka采用AP方式
-
Nacos配置管理
统一配置管理
配置更改热更新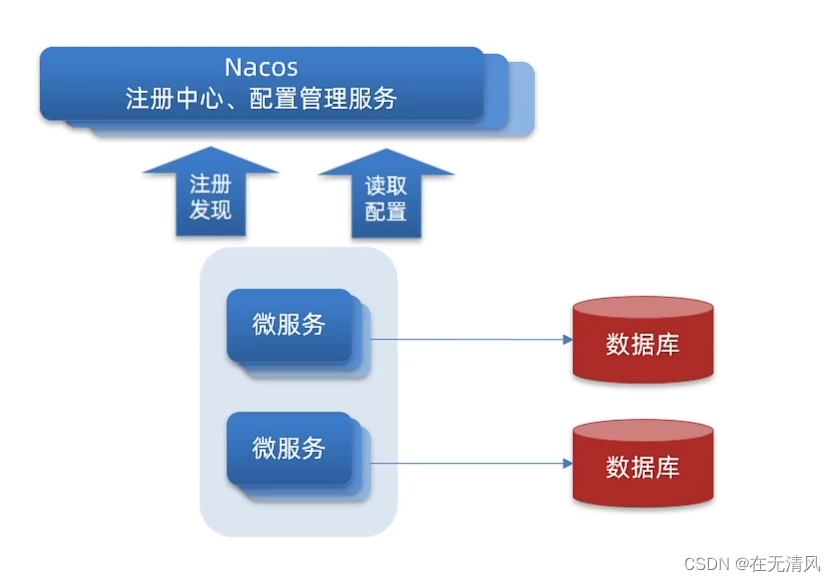
-
在Nacos中添加配置信息:
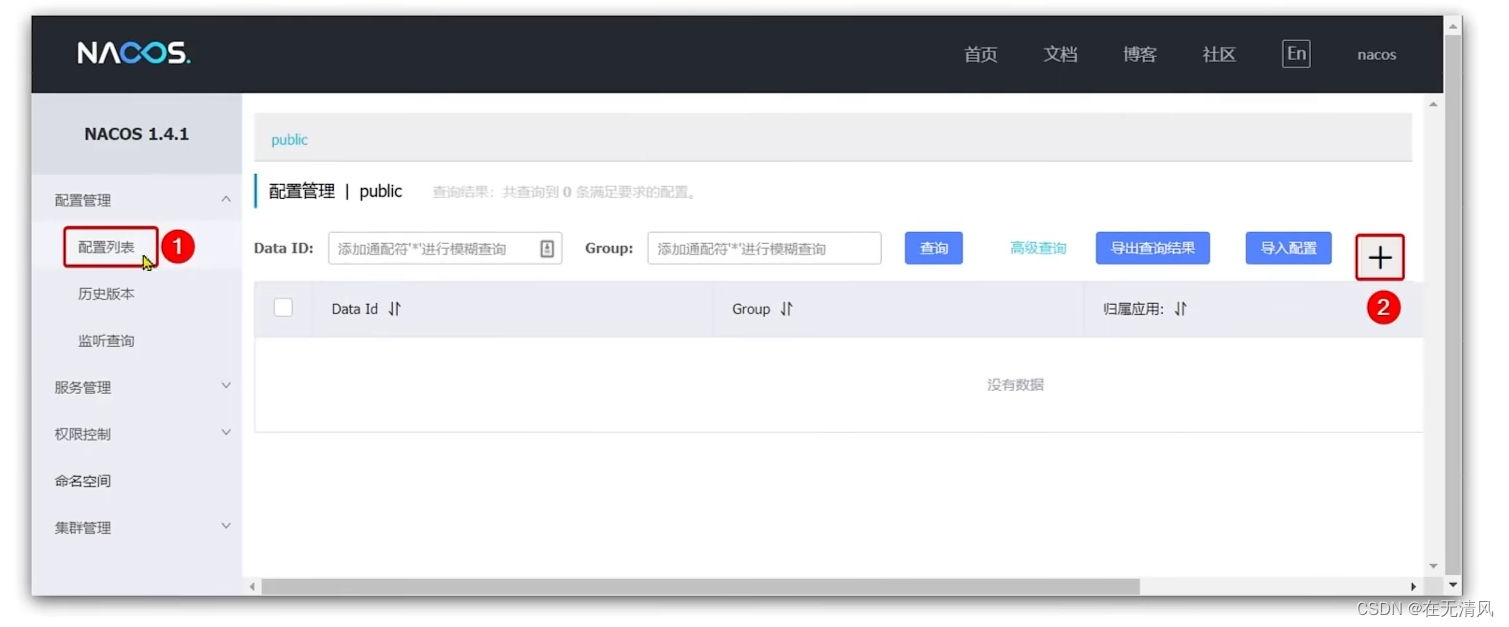
-
在弹出的表单中填写配置信息:
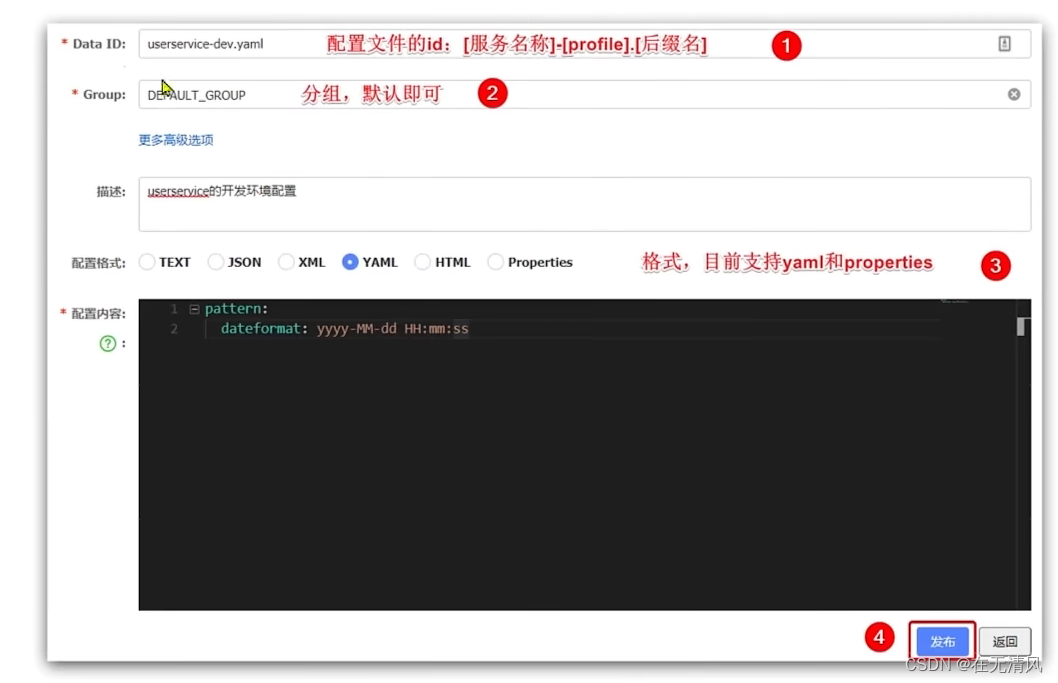
原配置获取的步骤如下:
nacos加入流程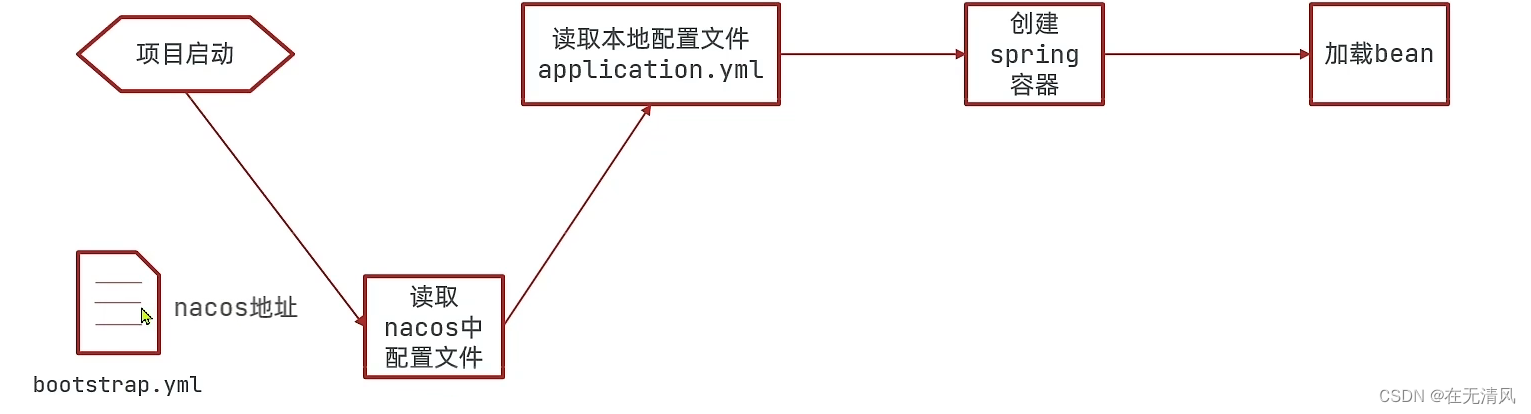
实现
-
引入Nacos的配置管理客户端依赖:
<!--nacos配置管理依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> <version>2.2.5.RELEASE</version> </dependency> -
在项目的resource目录添加一个bootstrap.yml文件,这个文件是引导文件,优先级高于application.yaml:
spring: application: name: userservice profiles: active: dev #激活环境 cloud: nacos: server-addr: localhost:9001 #nacso地址 config: file-extension: yaml #配置文件后缀 -
我们在项目的controller中做测试看看有没有配置成功:
@Value("${pattern.dateformat}") private String dateFormat; @GetMapping("now") public String now() { return "当前时间:" + LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateFormat));}
总结(将配置交给Nacso管理的步骤)
-
在Nacos中添加配置文件
-
在微服务中引入nacos的config依赖
-
在微服务中添加bootstrap.yml,配置nacos地址,当前环境,服务名称,文件后缀民。这些决定了程序启动时去nacos读取哪个文件
热更新
Nacos中配置文件变更后,微服务无需重启就可以感知。不过需要通过下面两种配置实现:
-
方式一:在@Value注入的变量所在类上添加注解@RefreshScope
@Slf4j @RestController @RequestMapping("/user") @RefreshScope public class UserController { @Value("${pattern.dateformat}") private String dateFormat; -
方式二:使用@ConfigurationProperties注解
-
新建一个类
@Data @Component @ConfigurationProperties(prefix = "pattern") public class PatternProperties { private String dateformat; } -
属性注入实现
@Autowired private PatternProperties properties; // @Value("${pattern.dateformat}") // private String dateFormat; @GetMapping("now") public String now() { return "当前时间:" + LocalDateTime.now().format(DateTimeFormatter.ofPattern(properties.getDateformat())); }
-
多环境配置共享
微服务启动时会从nacos读取多个配置文件:
-
[spring.application.name]-[spring.profiles.active].yaml,例如:uservice-dev.yaml
-
[spring.application.name].yaml,例如:userservice.yaml
无论profile如何变化,[spring.application.name].yaml这个文件一定会加载,因此多环境共享配置可以写入这个文件
步骤
这里有两个环境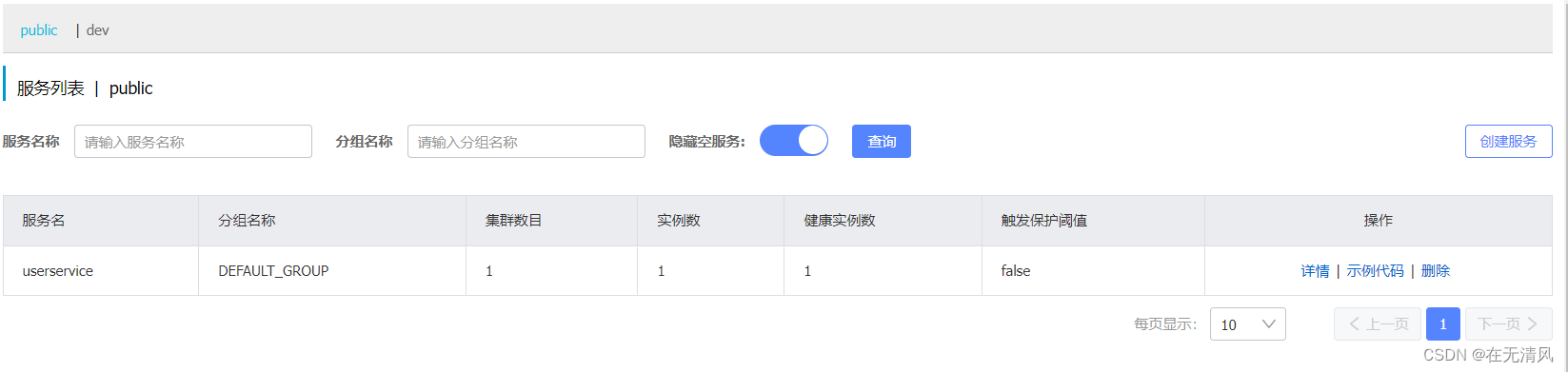

添加配置
端口8001在public中,8002,8004在dev中分别是两个环境,分别东鞥获取到envSharedValue的值。实现了不同环境共享了配置文件

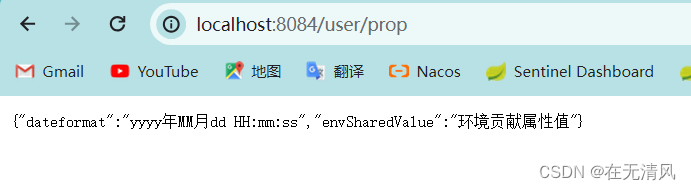
多环境配置优先级
服务名-profile.yaml > 服务名.yaml > 本地配置
Nacos集群搭建
1.集群结构图
官方给出的Nacos集群图:

其中包含3个nacos节点,然后一个负载均衡器代理3个Nacos。这里负载均衡器可以使用nginx。
我们计划的集群结构:
三个nacos节点的地址:
| 节点 | ip | port |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
2.搭建集群
搭建集群的基本步骤:
-
搭建数据库,初始化数据库表结构
-
下载nacos安装包
-
配置nacos
-
启动nacos集群
-
nginx反向代理
2.1.初始化数据库
Nacos默认数据存储在内嵌数据库Derby中,不属于生产可用的数据库。
官方推荐的最佳实践是使用带有主从的高可用数据库集群,主从模式的高可用数据库可以参考传智教育的后续高手课程。
这里我们以单点的数据库为例来讲解。
首先新建一个数据库,命名为nacos,而后导入下面的SQL:
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`src_user` text,
`src_ip` varchar(50) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE `users` (
`username` varchar(50) NOT NULL PRIMARY KEY,
`password` varchar(500) NOT NULL,
`enabled` boolean NOT NULL
);
CREATE TABLE `roles` (
`username` varchar(50) NOT NULL,
`role` varchar(50) NOT NULL,
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
);
CREATE TABLE `permissions` (
`role` varchar(50) NOT NULL,
`resource` varchar(255) NOT NULL,
`action` varchar(8) NOT NULL,
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');2.2.下载nacos
nacos在GitHub上有下载地址:Tags · alibaba/nacos · GitHub,可以选择任意版本下载。
本例中才用1.4.1版本:
2.3.配置Nacos
将这个包解压到任意非中文目录下,如图:
目录说明:
-
bin:启动脚本
-
conf:配置文件
进入nacos的conf目录,修改配置文件cluster.conf.example,重命名为cluster.conf:
然后添加内容:
127.0.0.1:8845 127.0.0.1.8846 127.0.0.1.8847
然后修改application.properties文件,添加数据库配置
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=1232.4.启动
将nacos文件夹复制三份,分别命名为:nacos1、nacos2、nacos3
然后分别修改三个文件夹中的application.properties,
nacos1:
server.port=8845
nacos2:
server.port=8846
nacos3:
server.port=8847
然后分别启动三个nacos节点:
startup.cmd
2.5.nginx反向代理
找到课前资料提供的nginx安装包:
解压到任意非中文目录下:
修改conf/nginx.conf文件,配置如下:
upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}而后在浏览器访问:http://localhost/nacos即可。
代码中application.yml文件配置如下:
spring:
cloud:
nacos:
server-addr: localhost:80 # Nacos地址2.6. 优化
-
实际部署时,需要给做反向代理的nginx服务器设置一个域名,这样后续如果有服务器迁移nacos的客户端也无需更改配置.
-
Nacos的各个节点应该部署到多个不同服务器,做好容灾和隔离
总结
集群搭建步骤:
-
搭建mysql集群搭建并初始化数据库表
-
下载解压nacos
-
修改集群配置(节点信息),数据库配置
-
分别启动多个nacos结点
-
nginx反向代理
HTTP客户端Feign
1.RestTemplate方法调用存在的问题
先来看我们以前利用RestTemplate发起远程调用的代码:
String url = "http://userservice/user/"+order.getUserId(); User user = restTemplate.getForObject(url, User.class);
存在下面的问题:
-
代码可读性差,编程体验不统一
-
参数复杂URL难以维护
Feign的介绍
Feign是一个声明式的http客户端,官方地址:GitHub - OpenFeign/feign: Feign makes writing java http clients easier其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。
定义和使用Feign客户端
使用Feign的步骤如下:
-
引入依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> -
在order-service的启动类添加注解开启Feign的功能:
@EnableFeignClients
-
编写Feign客户端(包主启动类里):
@FeignClient("userservice") public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id);主要基于SpringMVC的注解来声明远程调用的信息,比如:
-
服务名称:userservice
-
请求方式:GET
-
请求路径:/user/{id}
-
请求参数:Long id
-
返回值类型:User
-
-
使用Feign客户端代替RestTemplate
@Autowired private UserClient userClient; public Order queryOrderById(Long orderId) { // 1. 查询订单 Order order = orderMapper.findById(orderId); // 2.Feign远程调用 User user = userClient.findById(order.getUserId()); // 3.封装user到order order.setUser(user); // 根据id查询订单并返回 return order;
Feign的使用步骤
-
引入依赖
-
添加@EnableFeignClients注解
-
编写FeignClient接口
-
编写FeignClient中定义的方法代替RestTemplate
自定义Feign的配置
Feign运行自定义配置来覆盖默认配置,可以修改的配置如下:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的基别:None,Basic,Headers,Full |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign.Contract | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign.Retryer | 失败重机制 | 请求失败的重试机制,默认式没有,不过会使用Ribbon的重试 |
一般我们需要配置的就是日志级别。
自定义Feign的配置
方式一:配置文件方式
-
全局生效:
#feign: feign: client: config: default: #默认配置 loggerLevel: FULL #日志级别 # - TRACE:追踪级别的日志,输出最详细的日志信息。 - DEBUG:调试级别的日志,输出详细的日志信息。 - INFO:信息级别的日志,输出一般性的日志信息。 - WARN:警告级别的日志,输出可能表示潜在问题的日志信息。 - ERROR:错误级别的日志,输出发生的错误信息。 - OFF:完全关闭该 logger 输出日志。 -
局部生效
feign: client: config: # default: #默认配置 # loggerLevel: FULL #日志级别 # - TRACE:追踪级别的日志,输出最详细的日志信息。 - DEBUG:调试级别的日志,输出详细的日志信息。 - INFO:信息级别的日志,输出一般性的日志信息。 - WARN:警告级别的日志,输出可能表示潜在问题的日志信息。 - ERROR:错误级别的日志,输出发生的错误信息。 - OFF:完全关闭该 logger 输出日志。 userservice: #指定服务名称 loggerLevel: FULL
方式二:Java代码配置
需要线声明一个bean
package cn.itcast.order.config;
import feign.Logger;
import org.springframework.context.annotation.Bean;
/**
* @ClassName DefaultFeignConfiguration
* @Author AndyWu
* @Date 2024-01-03 19:59
* @Motto 学不死就往死里学
* @Version 1.0
*/
public class DefaultFeignConfiguration {
@Bean
public Logger.Level logger(){
return Logger.Level.BASIC;
}
}
-
而后如果是全局配置,则把它放到@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)
-
如果是局部配置,则把它放到@FeignClient这个注解中
@FeignClient(value = "uservice",configuration = FeignClientProperties.FeignClientConfiguration.class)
总结
Feign的日志配置:
-
方式一是配置文件,feign.client.config.xxx.loggerLevel
-
如果xxx是default则代表全局
-
如果xxx是服务名称,列入userservice则代表服务
-
-
方式二是Java代码配置Logger.Level这个Bean
-
如果在@EnableFeignClients注解声明则代表全局
-
如果在@FeignClient注解中声明则代表某服务
-
Feign的性能优化
Feign地城的客户端实现
-
URLConnection:默认实现,不支持连接池
-
Apache HttpClient:支持连接池
-
OKHttp:支持连接池
因为优化Feign的性能主要包括:
-
使用连接池代替默认的URLConnection
-
日志级别,最好用basic或none
Feign的性能优化-连接池配置
Feign添加HttpClient的支持:
-
引入依赖:
<!--引入HttpClient依赖--> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency> -
配置连接池:
feign: httpclient: enabled: true #开启feign的httpclient max-connections: 200 #最大连接数 max-connections-per-route: 50 #每个路由最大连接数
总结
Feign的优化
-
日志基别尽量用basic
-
使用HttpClient或OKHttp代替URLConnection
-
引入fegn-httpClient依赖
-
配置文件开启httpClient功能,设置连接池参数
-
Feign的最佳实践
方式一(继承)
给消费者的FeignClient和提供者的controller定义统一的父接口作为标准。(spring官方不推荐,因为紧耦合)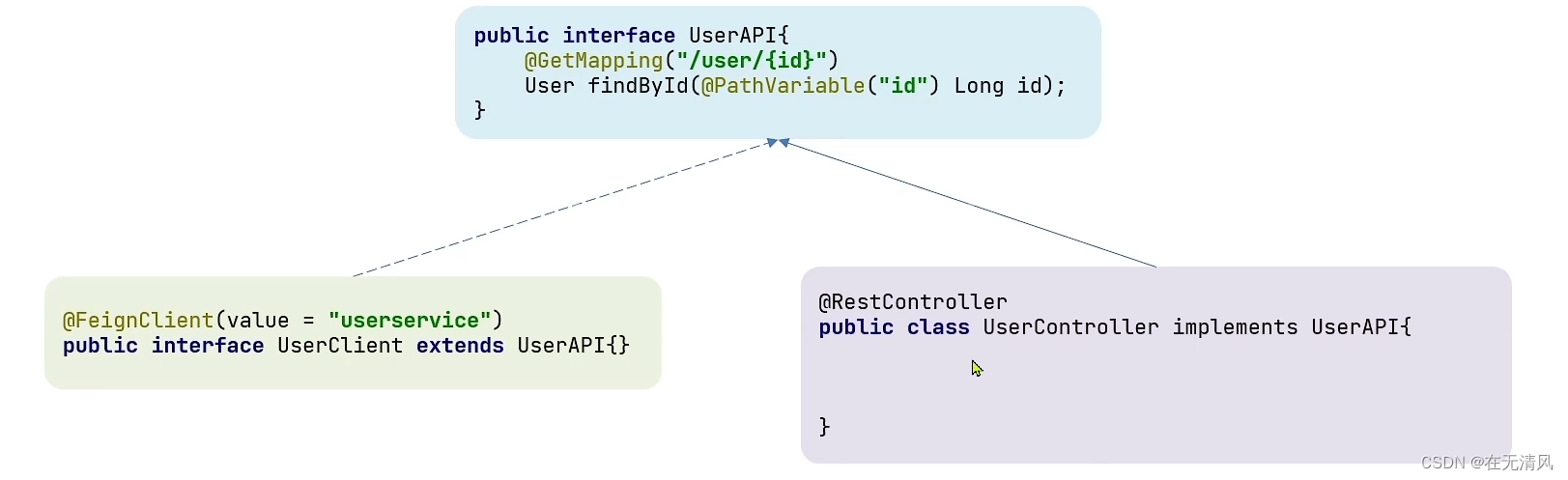
方式二(抽取):
将FeignClient抽取为独立模块,并且把接口有关的pojo,默认的Feign配置都放到这个模块中,提供给所有消费者使用(问题:可能只需要几个接口但引入依赖,把所有接口全部引入进来了)
实现
实现最佳实现方式二的步骤如下:
-
首先创建一个module,命名为feign-api,然后引入feign的starter依赖
-
将order-service中编写UserClient,User,DefaultFeignConfiguration都复制到feign-api项目中
-
在order-service中引入feign-api的依赖
-
在order-service中的说有与上述三个组件有关的import部分,改成导入feign-api中的包
-
重启测试
当定义的FeignClient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用。有两种方式解决:
方式一:指定FeignClient所在包(全部扫描)
@EnableFeignClients(basePackages = "cn.itcast.feign.clients")
方式二:指定FeignClient字节码(部分扫描,精准定位)
@EnableFeignClients(clients = {UserClient.class})
完整的代码
@EnableFeignClients(clients = {UserClient.class},defaultConfiguration = DefaultFeignConfiguration.class)
总结
不同包的FeignClient的导入有两种方式:
-
在@EnableFeignClients注解中添加basePackages,指定FeignClient所在的包
-
在@EnableFeignClients注解中添加clients,指定具体FeignClient的字节码
总结
-
让controller和FeignClient继承同一接口
-
将FeignClient,POJO,Feign的默认配置都定义到一个项目中,供所有消费者使用
统一网关Gateway
为什么需要网关
网关功能
-
身份认证和权限校验
-
服务路由,负载均衡
-
请求限流

网关的技术实现
在spring cloud中网关的实现包括两种:
-
gateway
-
zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而spring cloud Gateway则是基于spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
总结
网关的作用:
-
对用户请求的身份认证,权限校验
-
将用户请求路由到微服务,并实现负载均衡
-
对用户请求做限流
gateway快速入门
搭建网关
-
创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖:
<!--网关依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--服务发现依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <version>2.2.5.RELEASE</version> </dependency> -
编写路由配置及nacos地址
必须在同一个环境下,不能一个是测试环境一个是运行环境
server: port: 10010 #服务端口 spring: application: name: gateway #服务名称 cloud: nacos: server-addr: localhost:9001 #nacos地址 discovery: cluster-name: SC # 集群名称,代指杭州 namespace: e371f002-c878-4ceb-8339-5e605150395e #命名空间 gateway: routes: - id: user-service #路由id uri: lb://userservice #服务地址 predicates: - Path=/user/** #路由规则,判断路径是否以/user开通,如果符合就会代理到userservice里去 - id: order-service uri: lb://orderservice predicates: - Path=/order/** # filters: # - StripPrefix=1 #去除前缀
总结
网关搭建步骤:
-
创建项目,引入nacos服务发现和gateway依赖
-
配置application.yaml,包括服务基本信息,nacos地址,路由
路由配置包括
-
路由id:路由的唯一标识
-
路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
-
路由断言(predicates):判断路由的规则,
-
路由过滤器(filters):对请求或响应做处理
断言工厂
路由断言工厂Route Predicate Factory
网关路由可以配置的内容包括
-
路由id:路由唯一标示
-
uri:路由目的地,支持lb和http两种
-
predicates:路由断言,判断请求是否符合要求,符合则转发到路由目的地
-
filters:路由过滤器,处理请求或响应
断言工厂
-
我们在配置文件中写断言规则只是字符串,这些字符串会被PredicateFactory读取并处理,转变为路由判断的条件
-
例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的
-
像这样的断言工厂在spring cloudGateway还有十几个
spring提供了11种基本的Predicate工厂
实例
测试1
yaml中添加断言
gateway:
routes:
- id: user-service #路由id
uri: lb://userservice #服务地址
predicates:
- Path=/user/** #路由规则,判断路径是否以/user开通,如果符合就会代理到userservice里去
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
- After=2031-01-01T12:00:00.000+08:00[Asia/Shanghai] #时间过滤不符合
测试2
在yaml中添加
gateway:
routes:
- id: user-service #路由id
uri: lb://userservice #服务地址
predicates:
- Path=/user/** #路由规则,判断路径是否以/user开通,如果符合就会代理到userservice里去
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
- Before=2031-01-01T12:00:00.000+08:00[Asia/Shanghai] #时间过滤符合
过滤器工厂
路由过滤器gatewayFilter
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和服务返回的响应做处理:
给gateway中修改application.yaml文件,给userservice的路由添加过滤器:
gateway:
routes:
- id: user-service #路由id
uri: lb://userservice #服务地址
predicates:
- Path=/user/** #路由规则,判断路径是否以/user开通,如果符合就会代理到userservice里去
filters:
- AddRequestHeader=Truth,Itcast is freaking aowsome! #添加请求头
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
gateway:
routes:
- id: user-service #路由id
uri: lb://userservice #服务地址
predicates:
- Path=/user/** #路由规则,判断路径是否以/user开通,如果符合就会代理到userservice里去
# filters:
# - AddRequestHeader=Truth,Itcast is freaking aowsome! #添加请求头
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
- Before=2031-01-01T12:00:00.000+08:00[Asia/Shanghai] #时间过滤
default-filters:
- AddRequestHeader=Truth,Itcast is freaking aowsome! #添加请求头总结
-
过滤器的作用是什么?
-
对路由的请求或响应做加工处理,比如添加请求头
-
配置在路由下的过滤器只对当前路由的请求生效
-
-
defaultFiters的作用是什么?
-
对所有路由都生效的过滤器
-
全局过滤器
全局过滤器GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。
区别在于GatewayFilter通过配置定义,处理逻辑固定。而GlobalFiter的逻辑需要自己写代码实现。
定义方式是实现GlobalFiter接口
1.自定义类,实现GlobalFilter接口,添加@Order注解:
@Component
public class AuthorizeFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1.获取请求头中的token
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, String> params = request.getQueryParams();
//2.获取参数中的authorization 参数
String auth = params.getFirst("authorization");
//3.判断参数是否有等于admin
if ("admin".equals(auth)){
//4.是,放行
return chain.filter(exchange);
}
//5.否,拦截
//5.1.设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
//5.2.拦截请求
return exchange.getResponse().setComplete();
}
//@Order(-1)
@Override
public int getOrder() {
return -1;
}
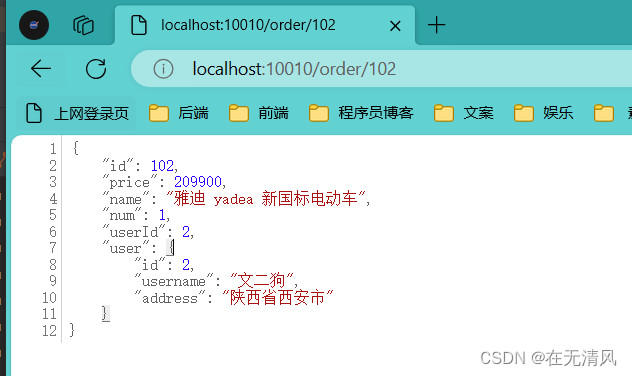
}失败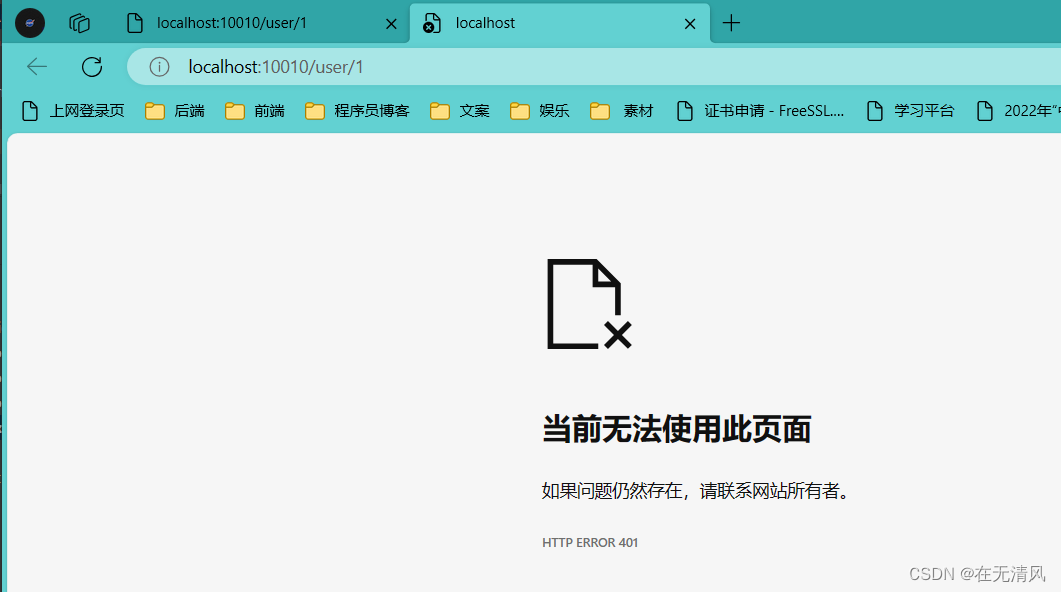
成功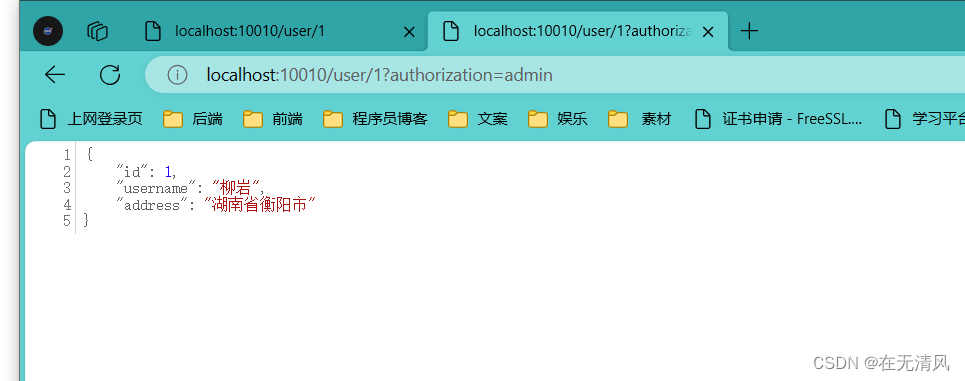
总结
-
全局过滤器的作用是什么?
-
对所有路由都生效的过滤器,并且可以自定义处理逻辑
-
-
实现全局过滤器的步骤?
-
实现GlobalFilter接口
-
添加@Order注解或实现Ordered接口
-
编写处理逻辑
-
过滤器执行顺序
请求进入网关碰到三类过滤器:当前路由的过滤器,DefaultFilter,GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter,GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器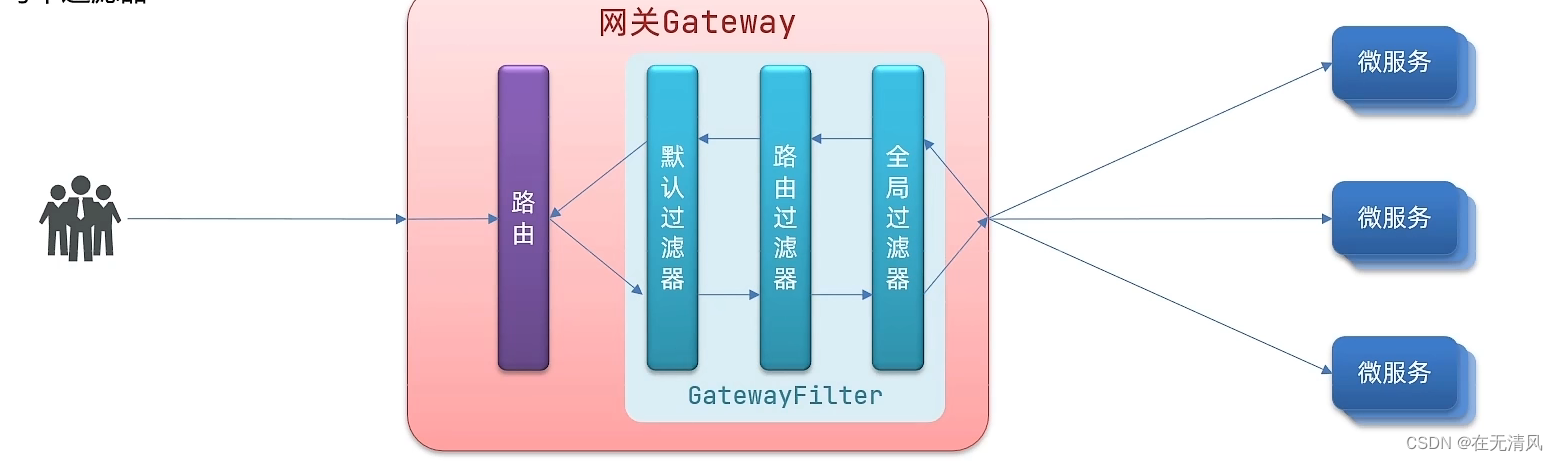
-
每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
-
GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
-
路由过滤器和defaultFilter的order由spring指定,默认是按照声明顺序从1递增。
-
当过滤器的order值一样时,会按照defaultFilter > 路由过滤器 > GlobalFiter的顺序执行

总结
路由过滤器,defaultFilter,全局过滤器的执行顺序?
-
order值越小,优先级越高
-
当order值一样是,顺序时defaultFilter最先,然后是局部的路由过滤器,最后是全局过滤器
跨域问题
跨域:域名不一致就是跨域,主要包括:
-
域名不同:www.taobao.com和www.taobao.org和www.jd.com和miaosha.js.com
-
域名相同,端口不同:localhost:8080和localhost:8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS (CORS是Cross-Origin Resource Sharing的缩写,跨域资源分享。在Web开发中,由于浏览器的同源策略限制,JavaScript不能从一个域名下的网页向其他域名下的网页请求资源,但是CORS提供了实现跨域请求的标准解决方案。通过在服务器端设置响应头部信息,允许指定的源访问资源,从而实现跨域请求。这样可以实现不同域名之间的数据交互,为Web开发提供了更多的灵活性和扩展性。)
跨域问题解决:
spring:
cloud:
gateway:
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://www.leyou.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期总结
CORS跨域要配置的参数包括哪几个?
-
允许哪些域名跨域?
-
允许哪些请求方式?
-
允许哪些哪些请求方式?
-
是否允许使用cookie?
-
有效期是多久?
感谢!各位道友阅读
![[HackMyVM]靶场 Adria](https://img-blog.csdnimg.cn/direct/dd48ef57d1b5451780e4cb62f49f411f.png)