NOIP 2007 普及组初赛试题及解析
- 一. 单项选择题 (共20题,每题1.5分,共计30分。每题有且仅有一个正确答案.)。
- 二. 问题求解(共2题,每题5分,共计10分)
- 三. 阅读程序写结果(共4题,每题8分,共计32分)
- 四. 完善程序 (前4空,每空2.5分,后6空,每空3分,共28分)
一. 单项选择题 (共20题,每题1.5分,共计30分。每题有且仅有一个正确答案.)。
1、在以下各项中,( )不是CPU的组成部分
A.控制器
B.运算器
C.寄存器
D.主板
正确答案: D
CPU(中央处理器)主要由控制器、运算器和寄存器三个部分组成。控制器负责指挥和控制计算机的操作,运算器负责执行算术和逻辑运算,寄存器用于暂时存储数据和指令。
而主板是计算机系统中的一个重要组件,它提供了连接 CPU、内存、硬盘、显卡等其他硬件设备的接口和电路。主板上还包含了芯片组、扩展插槽、BIOS 等组件,但它本身并不是 CPU 的一部分。
2、在关系数据库中,存放在数据库中的数据的逻辑结构以()为主。
A.二叉树
B.多叉树
C.哈希表
D.二维表
正确答案:D
二维表是由行和列组成的表格,每行代表一个记录,每列代表一个字段。关系数据库通过将数据组织成二维表的形式来进行存储和管理。
这种结构具有简单、直观、易于理解和操作的特点。通过定义表的结构(包括字段名和数据类型),以及建立表之间的关联关系,可以方便地进行数据的插入、查询、更新和删除等操作。
关系数据库的设计和使用遵循了一系列的规范和原则,例如实体-关系模型(ER 模型)等,以确保数据的完整性和一致性。
3、在下列各项中,只有( )不是计算机存储容量的常用单位
A.Byte
B.KB
C.UB
D.TB
正确答案: C
计算机存储容量的常用单位包括 Byte(字节)、KB(千字节)、MB(兆字节)、GB(吉字节)和 TB(太字节)等。这些单位用于表示存储设备(如硬盘、内存等)的容量大小。
例如,1 KB 等于 1024 Byte,1 MB 等于 1024 KB,1 GB 等于 1024 MB,1 TB 等于 1024 GB。通过使用这些单位,可以更方便地衡量和比较不同存储设备的容量。
4、ASCII码的含义是( )
A.二→十进制转换码
B.美国信息交换标准代码
C.数字的二进制编码.
D.计算机可处理字符的唯一编码
正确答案: B
ASCII 码的含义是“美国信息交换标准代码”(American Standard Code for Information Interchange)。
ASCII 码是一种字符编码标准,它定义了 128 个字符的编码,包括英文字母、数字、一些特殊字符和控制字符。每个字符都被分配了一个唯一的七位二进制数表示。
ASCII 码的设计目的是为了确保不同计算机系统之间能够进行文本数据的交换和共享,使得字符可以在不同的计算机和通信系统中被正确地识别和处理。
5、一个完整的计算机系统应包括( )
A.系统硬件和系统软件
B.硬件系统和软件系统
C.主机和外部设备
D.主机、键盘、显示器和辅助存储器
正确答案: B
一个完整的计算机系统确实应该包括硬件系统和软件系统。
硬件系统是计算机的物理部分,包括主机(如 CPU、内存、硬盘等)、外部设备(如键盘、鼠标、显示器等)以及其他相关的硬件组件。硬件系统提供了计算机的基础结构和运算能力。
软件系统则是运行在硬件之上的一系列程序和数据,包括操作系统、应用软件、编程语言、数据库管理系统等。软件系统使计算机能够实现各种功能,并提供了用户与计算机交互的界面。
硬件系统和软件系统相互配合,共同实现计算机的各种任务和应用。
6、IT的含义是( )
A.通信技术
B.信息技术
C.网络技术
D.信息学
正确答案: B
“IT”的常见含义是“信息技术”(Information Technology)。
信息技术是一个广泛的领域,包括计算机硬件和软件、通信技术、数据处理和存储、网络技术、互联网和移动应用等。它涉及到利用技术来收集、处理、存储、传输和管理信息。
信息技术在现代社会中扮演着重要的角色,影响着各个行业和人们的日常生活。它的发展推动了数字化转型、提高了生产力、改善了沟通和信息共享,并且催生了许多创新的应用和业务模式。
7、LAN的含义是( )
A.因特网
B.局域网
C.广域网
D.城域网
正确答案: B
“LAN”的含义是“局域网”(Local Area Network)。
局域网是指在一个相对较小的地理区域内,如一个办公室、一栋建筑物或一个校园内,通过网络设备(如交换机、路由器)将计算机、服务器、打印机等设备连接在一起形成的网络。
局域网通常使用高速的有线或无线技术进行连接,例如以太网、Wi-Fi 等。它允许设备之间进行数据传输、共享资源和相互通信。局域网的目的是为了方便内部设备之间的协作和共享,提高工作效率。
与局域网相对应的是广域网(WAN),它覆盖的地理范围更广,例如城市、国家甚至全球,通过公共网络(如因特网)进行连接。
1.因特网(Internet):又称互联网,是全球范围内连接各种计算机网络的一个巨大网络。它由许多互相连接的网络和服务器组成,可以实现全球范围内的信息交流、资源共享和互相通信。
2.局域网(Local Area Network,LAN):正如我们刚才所说,局域网是在较小地理范围内组成的网络,比如一个家庭、办公室、学校或企业。局域网内的设备可以共享资源,如文件、打印机等,并且传输速度通常较快。
3.广域网(Wide Area Network,WAN):广域网覆盖的范围比局域网更广,它可以连接不同地区甚至跨越国家的多个局域网。广域网通常由电信运营商提供的网络连接,如电话线、光纤等。
4.城域网(Metropolitan Area Network,MAN):城域网是一种覆盖城市范围的网络,介于局域网和广域网之间。它主要用于连接城市内的各个机构、企业和公共设施,提供高速的数据传输和互联互通。)
8、冗余数据是指可以由其它数据导出的数据。例如,数据库中已存放了学生的数学、语文和英语的三科成绩,如果还存放三科成绩的总分,则总分就可以看作冗余数据。冗余数据往往会造成数据的不一致。例如,上面4个数据如果都是输入的,由于操作错误使总分不等于三科成绩之和,就会产生矛盾。下面关于冗余数据的说法中,正确的是( )。
A.应该在数据库中消除一切冗余数据
B.用高级语言编写的数据处理系统,通常比用关系数据库编写的系统更容易消除冗余数据
C.为了提高查询效率,在数据库中可以保留一些冗余数据,但更新时要做相容性检验
D.做相容性检验会降低效率,可以不理睬数据库中的冗余数据
正确答案: C
虽然冗余数据可能会导致数据的不一致,但在某些情况下,保留一些冗余数据可以提高查询效率。例如,在数据库中存储总分可以方便地获取学生的总成绩,而无需进行复杂的计算。
然而,为了避免数据不一致,在更新数据时需要进行相容性检验,以确保冗余数据与其他相关数据的一致性。
消除所有冗余数据并不总是可行的,因为有时冗余数据可能是必要的,或者在数据处理和查询效率方面可能更有益。
选项 A 过于绝对,有时冗余数据是不可避免的;选项 B 并没有直接关联,高级语言和关系数据库的编写与消除冗余数据的容易程度并无直接关系;选项 D 忽略相容性检验可能会导致数据不一致问题,这是不可取的。
9、在下列各软件,不属于NOIP竞赛(复赛)推荐使用的语言环境有( )。
A.gcc
B.g++
C.TurboC
D.FreePascal
正确答案: C
在 2007 年的实际情况下,TurboC 不属于 NOIP 竞赛(复赛)推荐使用的语言环境。
NOIP(全国青少年信息学奥林匹克竞赛)通常推荐使用一些主流的编程语言和相应的编译器或集成开发环境。在选项中,gcc 和 g++是常用的 C/C++编译器,FreePascal 则是 Pascal 语言的编译器。
然而,TurboC 是一个较旧的 C 语言编译器,在当时可能已经不是 NOIP 竞赛推荐使用的环境。NOIP 竞赛可能更倾向于使用更新、更流行的编译器和开发环境,以适应现代编程的需求。
需要注意的是,编程语言和编译器的选择可能会随着时间的推移而变化,所以对于具体的竞赛或项目,最好参考相关的官方指南或规定来确定推荐使用的语言环境。
10、以下断电后仍能保存数据的有( )。
A.硬盘
B.高速缓存
C.显存
D.RAM
正确答案: A
硬盘是一种可以在断电后仍能保存数据的存储设备。
硬盘通常使用磁存储技术,将数据存储在磁盘上。即使计算机断电,硬盘上的数据也不会丢失,除非硬盘本身受到损坏。
高速缓存和显存通常是用于提高计算机性能的临时存储,它们的数据在断电后会丢失。
RAM(随机存取存储器)也是一种易失性存储器,类似于高速缓存和显存,断电后数据也会丢失。
所以,在这四个选项中,只有硬盘可以在断电后保存数据。
11、在下列关于计算机语言的说法中,正确的有( )。
A.高级语言比汇编语言更高级,是因为它的程序的运行效率更高
B.随着Pascal、C等高级语言的出现,机器语言和汇编语言已经退出了历史舞台
C.高级语言比汇编语言程序更容易从一种计算机上移植到另一种计算机上
D.C是一种面向对象的高级计算机语言
正确答案: C
高级语言相对于汇编语言来说,更易于编程和理解,但并不一定在运行效率上更高。实际上,在一些对性能要求极高的场景中,汇编语言可能仍然是必要的。
虽然高级语言的使用越来越广泛,但机器语言和汇编语言在某些特定的领域和情况下仍然有其应用,比如硬件驱动程序的开发。
高级语言的优点之一是相对更容易移植到不同的计算机体系结构上,因为它们通常不依赖于特定的硬件架构。
至于选项 D,C 语言本身并不是一种面向对象的语言,它是一种过程性的语言。然而,C++是一种基于 C 语言扩展的面向对象的高级语言。
12、近20年来,许多计算机专家都大力推崇递归算法,认为它是解决较复杂问题的强有力的工具。在下列关于递归算法的说法中,正确的是( )。
A.在1977年前后形成标准的计算机高级语言FORTRAN77禁止在程序使用递归,原因之一是该方法可能会占用更多的内存空间
B.和非递归算法相比,解决同一个问题,递归算法一般运行得更快一些
C.对于较复杂的问题,用递归方式编程一般比非递归方式更难一些
D.对于已经定义好的标准数学函数sin(x),应用程序中的语句“y=sin(sin(x));”就是一种递归调用
正确答案: A
FORTRAN77 禁止在程序中使用递归的一个原因确实是递归可能会占用更多的内存空间。递归算法在解决问题时会不断地调用自身,形成嵌套的函数调用,这可能导致内存使用的增加。
与非递归算法相比,递归算法的运行速度并不一定更快,实际上,在某些情况下,非递归算法可能更有效。
对于复杂问题,递归方式编程并不一定更难,它可以提供一种简洁和直观的解决方案,但在某些情况下,递归可能会导致堆栈溢出等问题。
而标准数学函数 sin(x)的递归调用并非如此,它是通过数学定义和计算来实现的,不是递归算法。
13、一个无法靠自身的控制终止的循环成为“死循环”,例如,在C++语言程序中,语句while(1) printf( “*” );就是一个死循环,运行时它将无休止地打印 * 号。下面关于死循环的说法中,只有( )是正确的。
A.不存在一种算法,对任何一个程序及相应的输入数据,都可以判断是否会出现死循环,因而,任何编译系统都不做死循环检查
B.有些编译系统可以检测出死循环
C.死循环属于语法错误,既然编译系统能检查各种语法错误,当然也应该能检查出死循环
D.死循环与多进程中出现的“死锁”差不多,而死锁是可以检测的,因而,死循环也可以检测的
正确答案: A
要判断一个程序是否会出现死循环,需要考虑到程序的逻辑和可能的输入情况,这是非常复杂的。实际上,对于任何程序和输入数据,都无法保证能够准确地判断是否会出现死循环。
虽然有些编译系统可能会尝试检测一些常见的死循环情况,但这并不能涵盖所有可能的情况。死循环并不属于语法错误,而是一种逻辑错误或设计问题。
与死锁不同,死锁通常是在多进程或多线程环境中出现的,并且可以通过一些特定的算法和机制来检测和处理。然而,死循环是在单个进程或线程中的逻辑问题,通常更难以直接检测。
所以,一般来说,编译系统并不专门进行死循环检查,而是主要关注语法和语义错误。
14、在C++语言中,表达式23|2^5的值是( )
A.18
B.1
C.23
D.32
正确答案: C
按位运算符是一种用于对整数进行位级操作的运算符。它们直接操作整数的二进制表示,对每一位进行单独的运算。以下是一些常见的按位运算符:
按位与(&):对于每一位,如果两个操作数的该位都是 1,则结果的该位为 1;否则为 0。
按位或(|):对于每一位,如果两个操作数的该位至少有一个是 1,则结果的该位为 1;否则为 0。
按位异或(^):对于每一位,如果两个操作数的该位不同,则结果的该位为 1;否则为 0。
按位取反(~):对一个数的每一位进行取反操作,1 变成 0,0 变成 1。
左移(<<):将一个数的所有位向左移动指定的位数,右侧用 0 填充。
右移(>>):将一个数的所有位向右移动指定的位数,左侧用 0 或最高位填充(根据移动的是正数还是负数)。
运算符的优先级: 按位取反(~)的优先级最高,其次是按位与(&),再其次是按位异或(|),最后是按位或(|)。
本题:
先算2 ^ 5 = 010 ^ 101 = 111
再算23 | 7 = 10111 | 00111 = 10111
__15、在C++语言中,判断a等于0或b等于0或c等于0的正确的条件表达式是( ) __
A.!((a!=0)||(b!=0)||(c!=0))
B.!((a!=0)&&(b!=0)&&(c!=0))
C.!(a==0&&b==0)||(c!=0)
D.(a=0)&&(b=0)&&(c=0)
正确答案: B
选项 A:!((a!=0)||(b!=0)||(c!=0)) 表示对 a、b 或 c 不等于 0 的情况取反。这意味着只有当 a、b 和 c 都不等于 0 时,表达式才为真。
选项 B:!((a!=0)&&(b!=0)&&(c!=0)) 表示对 a、b 和 c 都不等于 0 的情况取反。这意味着当至少有一个变量等于 0 时,表达式为真。
选项 C:!(a == 0&&b==0)||(c!=0) 表示对 a 和 b 都等于 0 的情况取反,或者 c 不等于 0。这意味着当 a 和 b 不都等于 0 或者 c 不等于 0 时,表达式为真。
选项 D:(a=0)&&(b=0)&&(c=0) 这是一个赋值表达式,而不是条件判断。它将 a、b 和 c 都赋值为 0,并返回一个值,但不是用于判断条件的。
16、地面上有标号为A、B、C的三根柱,在A柱上放有10个直径相同中间有孔的圆盘,从上到下依次编号为1,2,3…,将A柱上的部分盘子经过B柱移入C柱,也可以在B柱上暂存。如果B柱上的操作记录为“进、进、出、进、进、出、出、进、进、出、进、出、出”。那么,在C柱上,从下到上的编号为( )
A.243657
B.241257
C.243176
D.243675
正确答案: D
根据“进、进、出、进、进、出、出、进、进、出、进、出、出”的记录,我们可以按照以下步骤进行分析:
“进、进、出”:表示将两个圆盘从 A 柱移入 B 柱,然后将一个圆盘从 B 柱移出。(1,2进)(2出)
“进、进、出、出”:表示将两个圆盘从 A 柱移入 B 柱,然后将两个圆盘从 B 柱移出。(3,4进)(4,3出)
“进、进、出”:表示将一个圆盘从 B 柱移出,然后将两个圆盘移入 B 柱,再将一个圆盘移出。(5,6进)(6出)
“进、出、出”:表示将一个圆盘移入 B 柱,然后将一个圆盘移出,再将一个圆盘移出。(7进)(7,5出)
通过以上步骤,我们可以发现,最终在 C 柱上的圆盘编号应该是按照“2、4、3、6、7、5”的顺序从下到上排列的。
17、与十进制数1770对应的八进制数是( )
A.3350
B.3351
C.3352
D.3540
正确答案: C
要将十进制数转换为八进制数,我们可以使用除 8 取余的方法。具体步骤如下:
将十进制数 1770 除以 8,得到商和余数。
将商继续除以 8,直到商为 0。
将每次的余数从右到左排列,得到的就是八进制数。
按照上述步骤,我们可以进行如下计算:
1770 ÷ 8 = 221 余 2
221 ÷ 8 = 27 余 5
27 ÷ 8 = 3 余 3
3 ÷ 8 = 0 余 3
将每次的余数从下到上排列,得到八进制数 3352
18、设A=B=True,C=D=False,以下逻辑运算表达式值为假的有( )
A.(﹁A∧B)∨(C∧D∨A)
B.﹁(((A∧B)∨C)∧D)
C.A∧(B∨C∨D)∨D
D.(A∧(D∨C))∧B
正确答案: D
首先,我们需要了解基本的逻辑运算符及其含义:
¬(或 ~):逻辑非,表示对某个逻辑值取反。如果内部为真(True),则结果为假(False);如果内部为假(False),则结果为真(True)。
∧:逻辑与,表示两个逻辑值都为真时,结果才为真。
∨:逻辑或,表示两个逻辑值中至少有一个为真时,结果才为真。
接下来,我们逐一分析每个选项:
A. (¬A ∧ B) ∨ (C ∧ D ∨ A)
¬A:因为 A = True,所以 ¬A = False。
B:B = True。
C ∧ D ∨ A:因为 C = False,D = False,A = True,所以 C ∧ D = False,C ∧ D ∨ A = False ∨ True = True。
(¬A ∧ B):False ∧ True = False。
最终 (¬A ∧ B) ∨ (C ∧ D ∨ A) = False ∨ True = True。
B. ¬(((A ∧ B) ∨ C) ∧ D)
A ∧ B:True ∧ True = True。
(A ∧ B) ∨ C:True ∨ False = True。
(((A ∧ B) ∨ C) ∧ D):True ∧ False = False。
¬(((A ∧ B) ∨ C) ∧ D):¬False = True。
C. A ∧ (B ∨ C ∨ D) ∨ D
B ∨ C ∨ D:True ∨ False ∨ False = True。
A ∧ (B ∨ C ∨ D):True ∧ True = True。
A ∧ (B ∨ C ∨ D) ∨ D:True ∨ False = True。
D. (A ∧ (D ∨ C)) ∧ B
D ∨ C:False ∨ False = False。
A ∧ (D ∨ C):True ∧ False = False。
(A ∧ (D ∨ C)) ∧ B:False ∧ True = False。
19、(2070)16 + (34)8的结果是()
A.(8332)10
B.(208A)16
C.(100000000110)2
D.(20212)8
正确答案: A
首先,我们需要将十六进制数 ( 2070 ) 16 (2070)_{16} (2070)16转换为十进制数。可以按照位权展开的方法,将每一位的数值乘以对应的权值,然后将所有的结果相加。在十六进制中,A~F 代表 10~15。
2070 = 2 × 1 6 3 + 0 × 1 6 2 + 7 × 1 6 1 + 0 × 1 6 0 = 2 × 4096 + 0 + 7 × 16 + 0 = 8192 + 112 = 8304 2070=2\times16^3+0\times16^2+7\times16^1+0\times16^0=2\times4096+0+7\times16+0=8192+112=8304 2070=2×163+0×162+7×161+0×160=2×4096+0+7×16+0=8192+112=8304
然后,我们将八进制数 ( 34 ) 8 (34)_{8} (34)8转换为十进制数。
34 = 3 × 8 1 + 4 × 8 0 = 3 × 8 + 4 = 24 + 4 = 28 34=3\times8^1+4\times8^0=3\times8+4=24+4=28 34=3×81+4×80=3×8+4=24+4=28
最后,将两个十进制数相加: 8304 + 28 = 8332 8304+28=8332 8304+28=8332
所以, ( 2070 ) 16 + ( 34 ) 8 (2070)_{16}+(34)_{8} (2070)16+(34)8的结果是 ( 8332 ) 10 (8332)_{10} (8332)10。
20、已知7个节点的二叉树的先根遍历是1245637(数字为节点的编号,以下同),中根遍历是4265173,则该二叉树的后根遍历是( )。
A.4652731
B.4652137
C.4231547
D.4653172
正确答案: A
首先,我们需要理解三种遍历方式的特点:
先根遍历(Preorder Traversal):先访问根节点,然后遍历左子树,最后遍历右子树。
中根遍历(Inorder Traversal):先遍历左子树,然后访问根节点,最后遍历右子树。
后根遍历(Postorder Traversal):先遍历左子树,然后遍历右子树,最后访问根节点。
根据题目给出的先根遍历和中根遍历的结果,我们可以逐步构建出二叉树的结构。
先根遍历的结果是 1245637,所以根节点是1。
在中根遍历的结果中,根节点1左边的节点是左子树的节点,右边的节点是右子树的节点。因此,左子树包括节点4、2、6、5,右子树包括节点7、3。
接下来,我们根据中根遍历的结果继续构建左子树和右子树。
对于左子树,节点4是根节点,因为4在节点2和6的左边。节点2是节点4的左子节点,节点6是节点4的右子节点。节点5是节点6的左子节点。
对于右子树,节点7是根节点,因为7在节点3的左边。节点3是节点7的右子节点。
现在,我们已经构建出了整个二叉树的结构。接下来,我们根据后根遍历的特点,从叶子节点开始遍历,最后访问根节点。
后根遍历的顺序是:先遍历左子树(4652),然后遍历右子树(73),最后访问根节点(1)。
所以,后根遍历的结果是 4652731。
二. 问题求解(共2题,每题5分,共计10分)
1、(子集划分)将n个数(1,2,…,n)划分成r个子集。每个数都恰好属于一个子集,任何两个不同的子集没有共同的数,也没有空集。将不同划分方法的总数记为S(n,r)。例如,S(4,2)=7,这7种不同的划分方法依次为{(1),(234)},{(2),(134)},{(3),(124)},{(4),(123)},{(12),(34)},{(13),(24)},{(14),(23)}。当n=6,r=3时, S(6, 3) = ( )
(提示:先固定一个数, 对于其余的5个数考虑S(5, 3)与S(5,2),再分这两种情况对原固定的数进行分析)
正确答案: 90
2、(最短路线)某城市的街道是一个很规整的矩形网络(见下图),有 7 条南北向的纵街,5 条东西向的横街。现要从西南角的 A 走到东北角的 B ,最短的走法共有多少种?

正确答案: 210
最少走10条路径,其中选出4条竖线 或 6条横线,即 C 10 6 C_{10}^{6} C106 或 C 10 4 C_{10}^{4} C104 ,其结果一致
三. 阅读程序写结果(共4题,每题8分,共计32分)
1、看程序写结果:
#include<stdio.h>
int main()
{
int i, p[5], a, b, c, x, y = 20;
for ( i = 0; i <= 4; i++ )
scanf( "%d", &p[i] );
a = (p[0] + p[1]) + (p[2] + p[3] + p[4]) / 7;
b = p[0] + p[1] / ( (p[2] + p[3]) / p[4]);
c = p[0] * p[1] / p[2];
x = a + b - p[(p[3] + 3) % 4];
if ( x > 10 )
y += (b * 100 - a) / (p[p[4] % 3] * 5);
else
y += 20 + (b * 100 - c) / (p[p[4] % 3] * 5);
printf( "%d,%d\n", x, y );
return(0);
}
//注:本例中,给定的输入数据可以避免分母为 0 或数组元素下标越界。
输入: 6 6 5 5 3
输出: ________
正确答案: 15,46
我们使用给定的输入6 6 5 5 3来计算输出。
p 数组为 [6, 6, 5, 5, 3]。
a = (6 + 6) + (5 + 5 + 3) / 7 = 12 + 13 / 7 = 12 + 1 = 13(因为13除以7向下取整为1)。
b = 6 + 6 / ((5 + 5) / 3) = 6 + 6 / 3 = 6 +2 = 8。
c = 6 * 6 / 5 = 36 / 5 = 7(因为36除以5向下取整为7)。
x = 13 + 8 - p[(5 + 3) % 4] = 13 + 8 - p[0] = 21 - 6 = 15。
因为 x 大于 10,所以
y += (8 * 100 - 13) / (p[3 % 3] * 5)
y += (800 - 13) / (p[0] * 5)
y += 787 / 30
y += 26(因为787除以30向下取整为26)。
最终,y = 20 + 26 = 46。
2、看程序写结果:
#include<stdio.h>
void fun( int *a, int *b ){
int *k;
k = a; a = b; b = k;
}
int main(){
int a = 3, b = 6, *x = &a, *y = &b;
fun( x, y );
printf( "%d,%d ", a, b );
}
输出: ____
正确答案: 3,6
这段C++代码定义了一个函数fun,该函数接受两个整数指针作为参数,并试图交换这两个指针所指向的地址。然而,由于C语言中的参数传递是通过值传递的,这意味着函数内部对参数的修改不会影响函数外部的变量。因此,fun函数中的交换操作只会影响函数内部的局部变量,而不会影响到main函数中的x和y指针。
在fun函数中,我们定义了一个指针k,然后尝试用k来交换a和b的值。但是,这里的交换只影响fun函数内部的a和b变量,对main函数中的x和y没有任何影响。
在main函数中,我们定义了两个整数a和b,并初始化它们为3和6。然后,我们定义了两个指针x和y,分别指向a和b的地址。
我们调用fun函数,并将x和y作为参数传递。由于C语言中的参数传递是通过值传递的,fun函数接收的是x和y的副本,而不是它们的原始地址。
// 利用指针交换两个变量的方法
#include <iostream>
using namespace std;
void swap(int* a, int* b) {
// 交换两个指针所指向的值
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int a = 5;
int b = 10;
cout << "Before swap: a = " << a << ", b = " << b << endl;
// 调用swap函数,传入a和b的地址
swap(&a, &b);
cout << "After swap: a = " << a << ", b = " << b << endl;
return 0;
}
3、看程序写结果:
#include "math.h"
#include "stdio.h"
int main(){
int a1[51] = { 0 };
int i, j, t, t2, n = 50;
for ( i = 2; i <= sqrt( n ); i++ )
if ( a1[i] == 0 ){
t2 = n / i;
for ( j = 2; j <= t2; j++ )
a1[i * j] = 1;
}
t = 0;
for ( i = 2; i <= n; i++ )
if ( a1[i] == 0 ){
printf( "%4d", i ); t++;
if ( t % 10 == 0 )
printf( "\n" );
}
printf( "\n" );
}
1.每行四分:____
2.每行四分:____
正确答案:
2 3 5 7 11 13 17 19 23 29
31 37 41 43 47
这段代码是一个实现找出小于或等于50的所有质数,并将它们打印出来。
i 和 j 是循环计数器。
t 用于计算找到的质数的数量。
t2 是一个临时变量,用于存储 n / i 的结果。
n 是我们要搜索的最大数字,这里设置为50。
使用埃拉托斯特尼筛选法找出质数
for ( i = 2; i <= sqrt( n ); i++ )
if ( a1[i] == 0 ){
t2 = n / i;
for ( j = 2; j <= t2; j++ )
a1[i * j] = 1;
}
这是埃拉托斯特尼筛选法的基本实现。它首先从2开始,并标记所有其倍数为非质数。然后,对于下一个尚未标记的数字(即质数),再次标记其所有倍数。这个过程一直持续到 sqrt(n),因为任何大于 sqrt(n) 的因子都会与一个小于或等于 sqrt(n) 的因子配对。
最后遍历数组 a1,并打印所有值为0的索引,这些索引代表质数。每打印10个质数,它都会打印一个换行符,以使输出更加整齐。
// 打表过程
i = 2; a1[2] == 0 -> t2 = 50 / 2 = 25;
for(j = 2, j <= 25) j(2 - 25)
a1[2*j] = 1 下标: 4,6,8,10,...,50 为1 (2的倍数)
i = 3;a1[3] == 0 -> t2 = 50 / 3 = 16;
for(j = 2, j <= 16) j (2, 16)
a1[3*j] = 1 下标: 6,9,12,15,18,21,...,48为1 (3的倍数)
i = 4;a1[4] == 0 false
i = 5;a1[5] == 0 -> t2 = 50 / 5 = 10
for (j = 2, j <= 10) j (2, 10)
a1[5*j] = 1 下标 10,15,20,25,...,50为1(5的倍数)
i = 6; a1[6] == 0 false
i = 7; a1[7] == 0 -> t2 = 50 / 7 = 7
for (j = 2, j <= 7) j (2, 7)
a1[7*j] = 1 下标 14, 21,28,35,42,49为1(7的倍数)
t = 0
i = 2 - 50
2 3 5 7 11 13 17 19 23 29
31 37 41 43 47
4、看程序写结果:
#include "ctype.h"
#include "stdio.h"
void expand( char s1[], char s2[] ){
int i, j, a, b, c;
j = 0;
for ( i = 0; (c = s1[i]) != '\0'; i++ )
if ( c == '-' ){
a = s1[i - 1]; b = s1[i + 1];
if ( isalpha( a ) && isalpha( b ) || isdigit( a ) && isdigit( b ) ){
/*函数 isalpha(a) 用于判断字符 a 是否为字母,
isdigit(b) 用于判断字符 b 是否为数字,如果是,返回 1,否则返回 0 */
j--;
do
s2[j++] = a++;
while ( tolower( a ) < tolower( s1[i + 1] ) );
}
/*函数 tolower(a) 的功能是当字符 a 是大写字母,改为小写,其余情况不变*/
else s2[j++] = c;
}else s2[j++] = c;
s2[j] = '\0';
}
int main(){
char s1[100], s2[300];
printf( "input s1:" );
gets( s1 );
expand( s1, s2 );
printf( "%s\n", s2 );
}
正确答案: input s1:wer2345defgh45456782qqq
- 本题的重点是读懂expand函数的含义
- C语言的字符串以’\0’结尾, 因此(c = s1[i]) != '\0’代表循环到字符串S1末尾
- 第一个if是为了寻找’-',否则直接赋值到S2
- a,b去’-'左右两边的字符, 如果左右两边同是字母或者数字
- 第二个循环do while是关键,当’-'左边的字符比右边的字符字母顺序小的时候,
左边的字符复制到S2,直到左边的字符和右边的字符相等时停止- 注意: 符号’-'是被丢弃的
四. 完善程序 (前4空,每空2.5分,后6空,每空3分,共28分)
1、完善程序:
(求字符的逆序)下面的程序的功能是输入若干行字符串,每输入一行,就按逆序输出该行,最后键入 −1 终止程序。请将程序补充完整。
#include <iostream.h>
#include <string.h>
int maxline = 200, kz;
int reverse( char s[] ){
int i, j, t;
for ( i = 0, j = strlen( s ) - 1; i < j; 【①】 , 【②】 ){
t = s[i]; s[i] = s[j]; s[j] = t;
}
return(0);
}
int main(){
char line[100];
cout << "continue? -1 for end." <<endl;
cin>>kz;
while(【③】){
cin >> line;
【④】;
cout << line << endl;
cout << "continue ? -1 for end." << endl;
cin >> kz;
}
}
正确答案:
1.i++ / i=i+1 / i+=1 / ++i
2.j-- / j=j-1 / j-=1 / --j
3.kz!=-1
4.reverse(line)
解析:
1.最先突破的是③: kz != -1
2.第二个突破的是④:函数调用, 直接修改参数line,并返回
3.然后需要读懂reverse函数,显然这是一个双游标法逆转字符串
reverse 函数:这个函数的目的是将一个字符串逆序。它接受一个字符数组 s 作为参数,该数组存储了一个字符串。
函数首先声明了三个整数变量 i, j, 和 t,用于循环控制和交换字符。
使用 for 循环,初始化 i 为 0(字符串的开始),j 为 strlen(s) - 1(字符串的结束)。
在循环中,i 递增,j 递减,直到 i 不再小于 j。这样,我们可以确保只交换一半的字符,因为交换两次会回到原始位置。
在循环体中,使用临时变量 t 来交换 s[i] 和 s[j] 的值。
循环结束后,字符串 s 已经被逆序。
main 函数:这是程序的入口点。
声明了两个变量:maxline(最大行长度)和 kz(控制是否继续的变量)。
输出提示信息,让用户知道输入 -1 可以结束程序。
使用 while 循环来不断读取用户输入的字符串,直到用户输入 -1。
调用 reverse(line); 来逆序 line 中的字符串。
输出逆序后的字符串。
再次提示用户是否继续,并读取 kz 的值。
当用户输入 -1 时,while 循环结束,程序执行完毕。
2、完善程序:
(棋盘覆盖问题)在一个
2
k
×
2
k
2^k \times 2^k
2k×2k个方格组成的棋盘中恰有一个方格与其它方格不同(图中标记为 -1 的方格),称之为特殊方格。现 L 型(占 3 个小方格)纸片覆盖棋盘上除特殊方格的所有部分,各纸片不得重叠,于是,用到的纸片数恰好是
(
4
k
−
1
)
3
\frac{(4^k - 1)}{3}
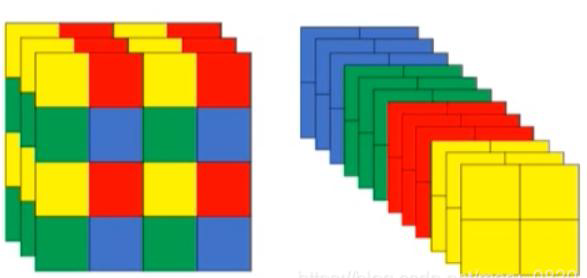
3(4k−1) 。在下表给出的一个覆盖方案中,k=2,相同的 3 各数字构成一个纸片。下面给出的程序使用分治法设计的,将棋盘一分为四,依次处理左上角、右上角、左下角、右下角,递归进行。请将程序补充完整。
2 2 3 3
2 -1 1 3
4 1 1 5
4 4 5 5
#include <iostream.h>
#include <iomanip.h>
int board[65][65], tile; /* tile为纸片编号 */
void chessboard( int tr, int tc, int dr, int dc, int size ){
/* dr,dc依次为特殊方格的行、列号 */
int t, s;
if ( size == 1 )
① ;
t = tile++;
s = size / 2;
if ( ② )
chessboard( tr, tc, dr, dc, s );
else{
board[tr + s -1][tc + s -1] = t;
[③];
}
if ( dr < tr + s && dc >= tc + s )
chessboard( tr, tc + s, dr, dc, s );
else{
board[tr + s -1][tc + s] = t;
④;
}
if ( dr >= tr + s && dc < tc + s )
chessboard( tr + s, tc, dr, dc, s );
else{
board[tr + s][tc + s -1] = t;
[⑤];
}
if ( dr >= tr + s && dc >= tc + s )
chessboard( tr + s, tc + s, dr, dc, s );
else{ board[tr + s][tc + s] = t;
[⑥]; }
}
void prtl( int b[][65], int n ){
int i, j;
for ( i =1; i <= n; i++ )
{
for ( j =1; j <= n; j++ )
cout << setw( 3 ) << b[i][j];
cout << endl;
}
}
void main(){
int size, dr, dc;
cout << "input size(4/8/16/64):" << endl;
cin >> size;
cout << "input the position of special block(x,y):" << endl;
cin >> dr >> dc;
board[dr][dc] = -1;
tile++;
chessboard( 1, 1, dr, dc, size );
prtl( board, size );
}
正确答案:
1.return
2.(dr<tr+s)&&(dc<tc+s) / dr<tr+s&&dc<tc+s
3.chessboard(tr,tc,tr+s-1,tc+s-1,s)
4.chessboard(tr,tc+s,tr+s-1,tc+s,s)
5.chessboard(tr+s,tc,tr+s,tc+s-1,s)
6.chessboard(tr+s,tc+s,tr+s,tc+s,s)
函数的参数解释:
tr, tc:当前要处理的棋盘区域的左上角坐标。
dr, dc:特殊方格在整个棋盘上的坐标。
size:当前棋盘区域的大小。
函数逻辑:
基本情况:如果棋盘区域的大小为1(即 size == 1),那么不需要任何纸片覆盖,因为只有一个方格,且它可能是特殊方格。函数直接返回。
确定是否需要L型纸片:根据特殊方格的位置,确定当前区域是否需要L型纸片。如果特殊方格在当前区域的左下角,那么我们在这个区域的右上角放置一个L型纸片。这是通过设置两个方格的值为当前纸片的编号 t 来实现的。
递归处理子区域:接下来,函数递归地处理四个子区域。根据特殊方格的位置,有些子区域可能不需要额外的纸片(因为它们已经被父区域的L型纸片覆盖了),但有些子区域可能需要。
左上角子区域:chessboard(tr, tc, dr, dc, s);
右上角子区域:如果特殊方格不在这个区域,则放置L型纸片并递归处理;否则,直接递归处理。
左下角子区域:类似右上角子区域的处理。
右下角子区域:如果特殊方格不在这个区域,则放置L型纸片;否则,已经放置了L型纸片,不需要额外处理。
打印棋盘:prtl 函数用于打印棋盘的状态。它遍历整个棋盘并打印每个方格的值。
主函数:main 函数是程序的入口点。它首先询问用户棋盘的大小和特殊方格的位置,然后调用 chessboard 函数来覆盖棋盘,并最后调用 prtl 函数来显示结果。
重要点:
棋盘是从 (0, 0) 开始的,而不是从 (1, 1) 开始。因此,用户的输入需要减去1以匹配数组索引。
纸片的编号从1开始,而不是从0开始。这是为了简化逻辑,因为特殊方格的值是-1,所以我们不需要担心与纸片的编号冲突。
程序的效率基于分治法,它将问题分解为更小的部分,并递归地解决这些部分。这种方法通常能够更快地解决问题,特别是对于大规模问题。
赠送知识点: 运算符分类
1级(左结合) () 圆括号;[]下标运算符;->指向结构体成员运算符;. 结构体成员运算符。
2级(右结合) !逻辑非运算符;~按位取反运算符;++前缀增量运算符;–前缀减量运算符;-负号运算符;(类型)类型转换运算符;*指针运算符;&地址运算符;sizeof长度运算符。
3级(左结合) *乘法运算符;/除法运算符;%取余运算符。
4级(左结合) +加法运算符;-减法运算符。
5级(左结合) <<左移运算符;>>右移运算符。
6级(左结合) <、<=、>、>=关系运算符。
7级(左结合) ==等于运算符;!=不等于运算符。
8级(左结合) &按位与运算符。
9级(左结合) ^按位异或运算符。
10级(左结合) |按位或运算符。
11级(左结合) &&逻辑与运算符。
12级(左结合) ||逻辑或运算符。
13级(右结合) ? :条件运算符。
14级(右结合) =、 +=、 -=、 *=、 /=、 %=、 &=、 ^=、 |=、 <<=、 >>=赋值运算符。
15级(左结合) ,逗号运算符。






![[VNCTF2024]-PWN:preinit解析(逆向花指令,绕过strcmp,函数修改,机器码)](https://img-blog.csdnimg.cn/direct/a25d17ccb3bd424f8e88d47e6ea67e8d.png)