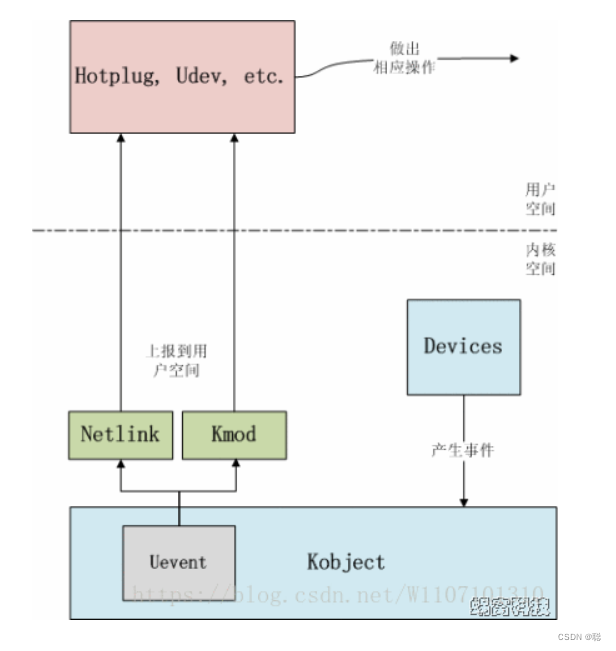
MySQL技术——存储引擎和索引机制
- 一、存储引擎概述
- 二、常见存储引擎的区别
- 三、索引机制
- 四、索引的底层实现原理
- 五、InnoDB主键和二级索引
- 六、聚集索引和非聚集索引
- 七、哈希索引
- 八、InnoDB的自适应哈希索引
- 九、索引常见问题
- 十、慢查询日志
- 总结
一、存储引擎概述
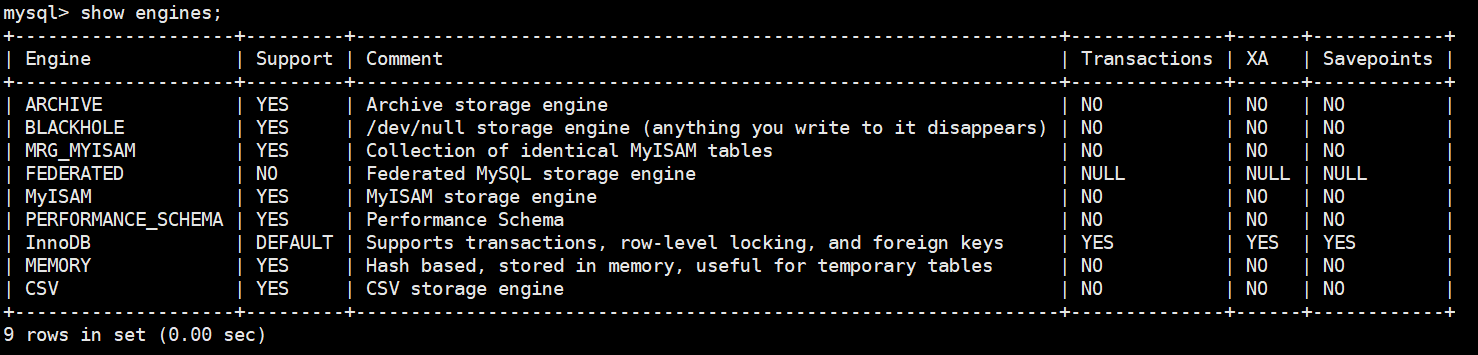
插件式存储引擎是MySQL数据库最重要的特性之一,用户可以根据应用的需要选择如何存储和索引数据、是否使用事务等。MySQL默认可以支持多种引擎,适用于不同领域的数据库用于需要,常见的MySQL存储引擎有:InnoDB、MyISAM、Memory、NDB Cluster等等,在mysql 的命令行窗口中,我们可以通过命令show engines查看
二、常见存储引擎的区别
- InnoDB存储引擎:具有提交、回滚和崩溃恢复能力的事务安全,支持自动增长列,外键等功能,采用聚集索引,即索引和数据存储在同一个文件,文件名和表名相同,扩展名分别为:.frm(存储表的定义)、.idb(存储数据和索引)
- MyISAM存储引擎:不支持事务、也不支持外键,索引采用非聚集索引,优势为访问速度快,对事务完整性没有要求,以select、insert为主的可以使用这个引擎来创建表,它在磁盘上存储成3个文件,扩展名为:.frm(表定义)、.MYD(数据)、.MYI(索引)
- MEMORY存储引擎:使用存在内存中的内容来创建表,每个表对应一个磁盘文件,由于它的数据是放在内存中的,因此该类型的表访问非常快,并且默认使用hash索引(不适合于范围查询),但是一旦服务关闭,表中的数据就会丢失
| 存储引擎 | 锁机制 | B-树索引 | 哈希索引 | 外键 | 事务 | 索引缓存 | 数据缓存 |
|---|---|---|---|---|---|---|---|
| InnoDB | 行锁 | 支持 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| MyISAM | 表锁 | 支持 | 不支持 | 支持 | 不支持 | 支持 | 不支持 |
| Memory | 表锁 | 支持 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
锁机制:数据库在并发请求访问的时候,多个事务在操作时,并发操作的粒度
B-树索引和哈希索引:加速SQL的查询速度
外键:子表的字段依赖父表的主键,设置两张表的依赖关系
事务:多个SQL语句,保证它们共同执行的原子操作
索引缓存和数据缓存:与MysSQL Server的查询缓存相关,在没有对数据和索引进行修改前,重复查询可以不进行磁盘I/O,直接上一次内存中查询的缓存
三、索引机制
当表中的数据量达到了几十万甚至上百万时,SQL查询所花费的时间会很长,有时会导致业务出现超时出错,这时我们需要使用索引来加速SQL的查询速度。但索引本身也是需要存储成索引文件1的,因此对索引的使用也会涉及到磁盘I/O操作,如果索引创建过多或使用不当,仍然会造成SQL查询时的大量的无用的磁盘I/O操作,降低查询效率,因此我们需要理解清楚索引创建的原则
-
索引的优点:提高查询效率
-
索引的缺点:过多的索引会导致CPU使用了居高不下,数据的改变造成索引文件的改动,过多的磁盘I/O造成CPU负荷太重
-
索引的分类:
- 普通索引:没有任何限制条件,可以给任何类型的字段创建普通索引,数量不限
- 唯一性索引:使用unique修饰的字段,值不能重复,主键索引就隶属于唯一性索引
- 主键索引:使用primary key修饰的字段会自动创建索引
- 单列索引:在一个字段上创建索引
- 多列索引:在表的多个字段上创建索引
- 全文索引:使用FULLTEXT参数可以设置全文索引,只支持CHAR、VARCHAR、TEXT类型的字段,常用于数据量较大的字符串类型上,可以提高查询速度(如elasticsearch,简称es C++开源的搜索引擎 workflow)
-
使用索引的原则:
- 一般情况,一次查询只能使用一条索引
- 对查询where条件中区分度高的字段加索引
- 联合索引,叶子节点存储的顺序以创建时指定的顺序为准,因此区分度高的放左边,能被多个查询复用的放左边
- 只select需要用到的字段,尽量避免使用select*
- 如有必要,可以使用
force index强制索引,select * from xxx force index(ix_addtime); - 多表
join,按各表的查询条件比较哪个表开销小,从小表取出符合条件的,到大表循环查找 - 以下情况无法使用到索引:
- like通配符在最左 ‘%xxx%’,not in,!=,<> 涉及到类型强转,mysql函数调用、表达式计算等等
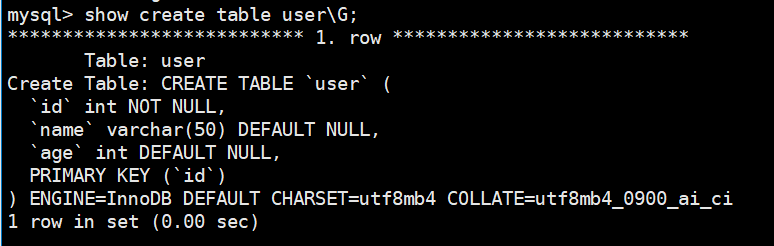
查看表的索引:有一个主键索引
索引的创建和删除
//创建时指定的索引字段
create table user(
id int primary key,
name varchar(50),
age int,
index(name, age); //这是多列索引
);
//在已经创建的表上添加索引
create index name_idx on user(name);
//删除索引
drop index name_idx on user;
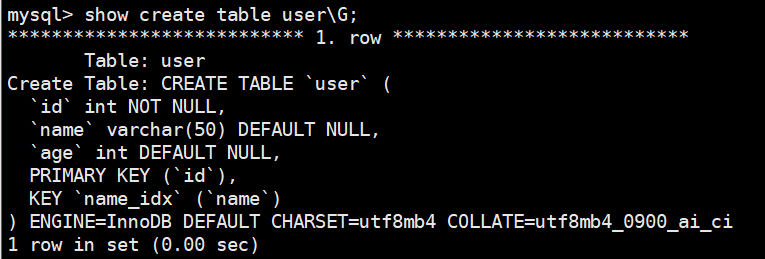
这是添加了name_idx的结果
查找指定的 id = 10000
查找指定的 name = ‘Test_50000’
删除name_idx索引,再查找指定的 name = ‘Test_50000’



通过上述的查询操作,效果可见一斑,现在给出explain结果字段分析
-
select_type
- simple:表示不需要union操作或者不包含子查询的简单select语句。有连接查询时,外层的查询为simple且只有一个。
- primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary且只有一个。
- union:union连接的两个select查询,除了第一个表外,第二个以后的表的select_type都是union。
- union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null。
-
table
- 显示查询的表名;
- 如果不涉及对数据库操作,这里显示null;
- 如果显示为尖括号就表示这是个临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生的;
- 如果是尖括号括起来<union M,N>也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集;
-
type
- const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type就是const。
- ref:常见于辅助索引的等值查找,或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找会出现;返回数据不唯一的等值查找也会出现。
- range:索引范围扫描,常见于使用<、>、is null、between、in、like等运算符的查询中。
- index:索引全表扫描,把索引从头到尾扫一遍;常见于使用索引列就可以处理不需要读取数据文件的查询,可以使用索引排序或者分组的查询。
- all:全表扫描数据文件,然后在server层进行过滤返回符合要求的记录。
-
ref
- 如果使用常数等值查询,这里显示const;
- 如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段;
-
Extra
- using filesort:排序时无法用到索引,常见于order by和group by语句中。
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
四、索引的底层实现原理
索引搜索的具体过程 !!!
当SELECT涉及到索引时,数据库系统会优先从内存中的索引缓存中查找匹配的数据行。如果索引缓存中不存在需要的索引,数据库系统会通过磁盘IO操作,从磁盘中读取索引页,找到匹配的数据行,然后将其加载到内存中加速查询数据的执行
MySQL能够支持两种索引:B-树索引、哈希索引(但实际上MySQL采用的是B+树结构)
B树索引
B树索引是一种特殊的B树,它被设计用于在磁盘上存储数据。因为磁盘的访问速度相对较慢,所以B树索引被优化为减少磁盘访问次数。它可以将大量的数据分层存储在不同的节点中,使得查询的时候只需要少量的磁盘读取操作。由于磁盘的读取也是按block块操作的(内存是按page页面操作的),因此B-树的节点大小一般设置为和磁盘块大小一致,这样一个B-树节点,就可以通过一次磁盘I/O把一个磁盘块的数据全部存储下来,所以当使用B-树存储索引的时候,磁盘I/O的操作次数是最少的
B树索引的原理如下:
-
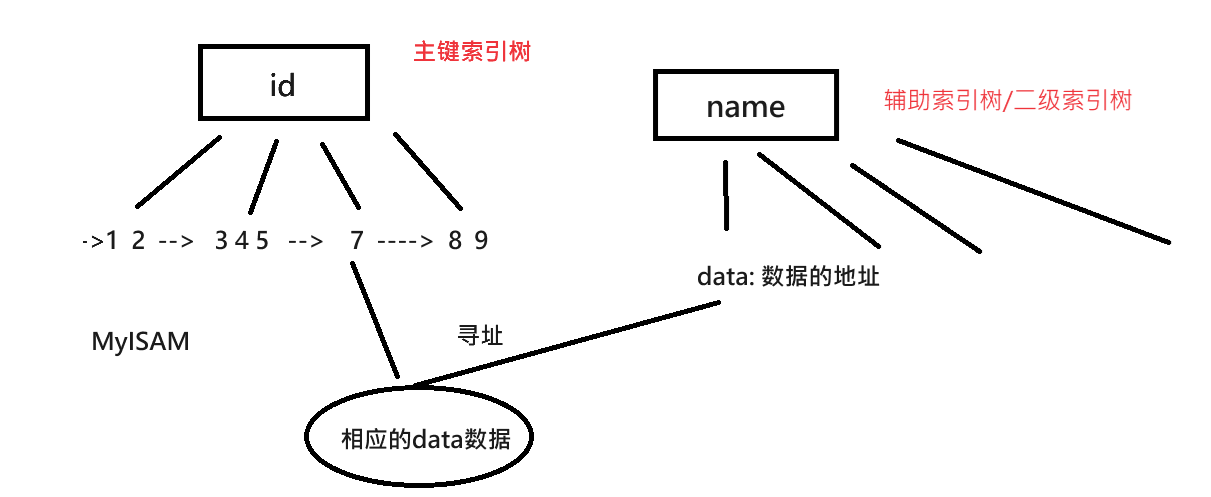
每个节点可以包含多个key-value对,其中key是索引列的值,value是对应的数据行的指针或位置(下图B-树是基于InnoDB存储引擎的,索引树上放的就是数据,所以data存储的直接就是数据本身的内容;而如果是MyISAM存储引擎,由于存放索引和数据的是两个不同的文件,其data存储的是在磁盘上包含的对应索引值记录的地址)
-
所有的节点都按照key的大小有序存储,也就是说,节点中的key是递增的
-
每个节点中的key可以重复,这样可以处理重复值的情况
-
每个节点中可以有多个子节点,子节点的key的范围必须满足一定的条件,使得它们可以作为查询的条件进行过滤
-
每一个叶子节点都包含一个指向数据行的指针或位置,这样可以直接找到需要的数据
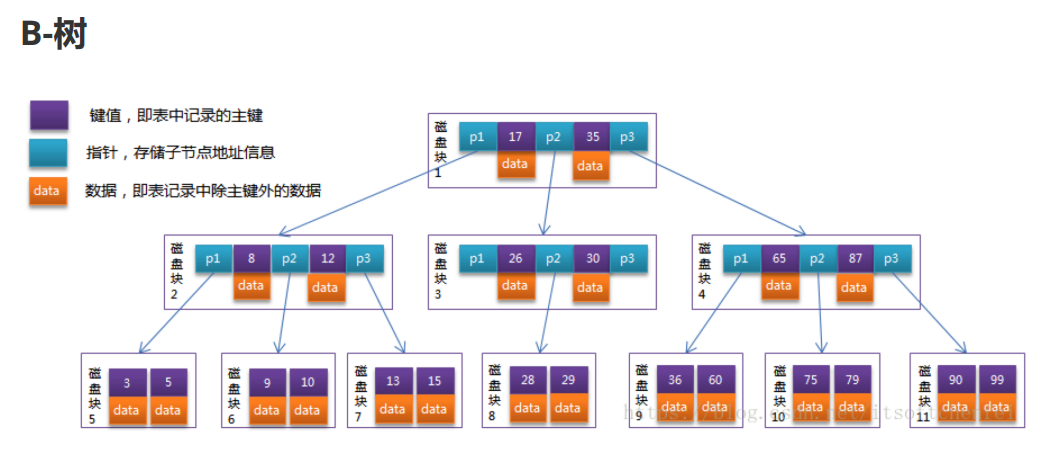
从上图可以看到B-树存在的缺点:
- 每个节点中有key,也有data,但是每一个节点的存储空间是有限的,如果data数据较大时会导致
- 每个节点能存储的key的数据很小
当存储的数据量很大时同样会导致B-树的高度较大,磁盘IO次数花费增大,效率降低
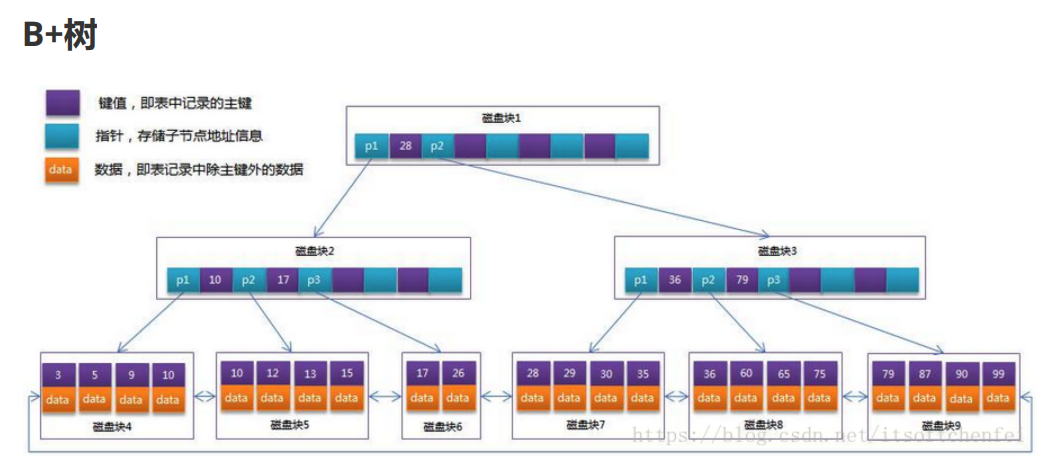
虽然B-树有很多优点,但在MySQL里,却是采用B+树存储索引结构的🤔🤔🤔
- B-树的每一个节点,存了关键字和对应的数据地址,而B+树的非叶子节点只存关键字,不存数据地址。因此B+树的每一个非叶子节点的关键字是远远多余B-树的,从树的高度上看,B+树的高度要小于B-树,使用的磁盘IO少,查询更快
- B-树由于每个节点都存储关键字和数据,因此离根节点近的数据,查询就快,离根节点远的数据,查询就慢;而B+树的所有数据都存在叶子节点上,在它上面搜索关键字,找到对应数据的时间是比较平均的,没有快慢之分
- 对于区间查找,在B-树上的遍历节点非常多;而B+树的所有叶子节点被连接成了有序链表结构,做整表遍历和区间查找非常容易
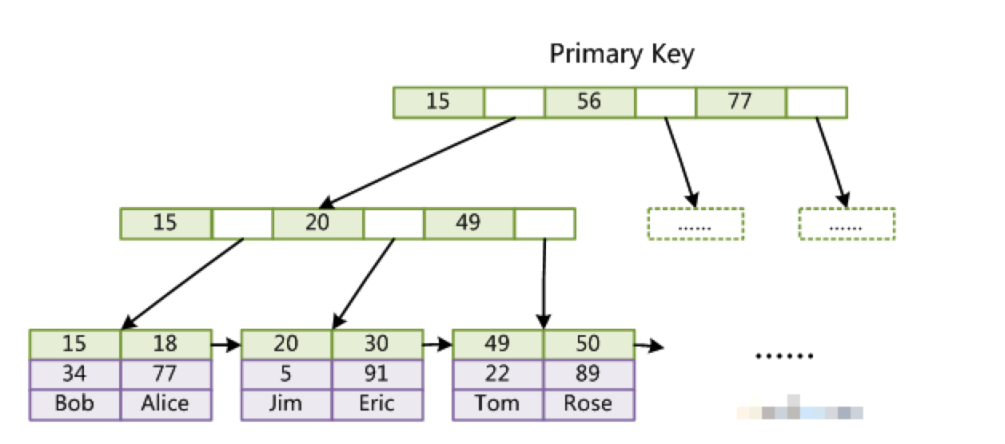
五、InnoDB主键和二级索引
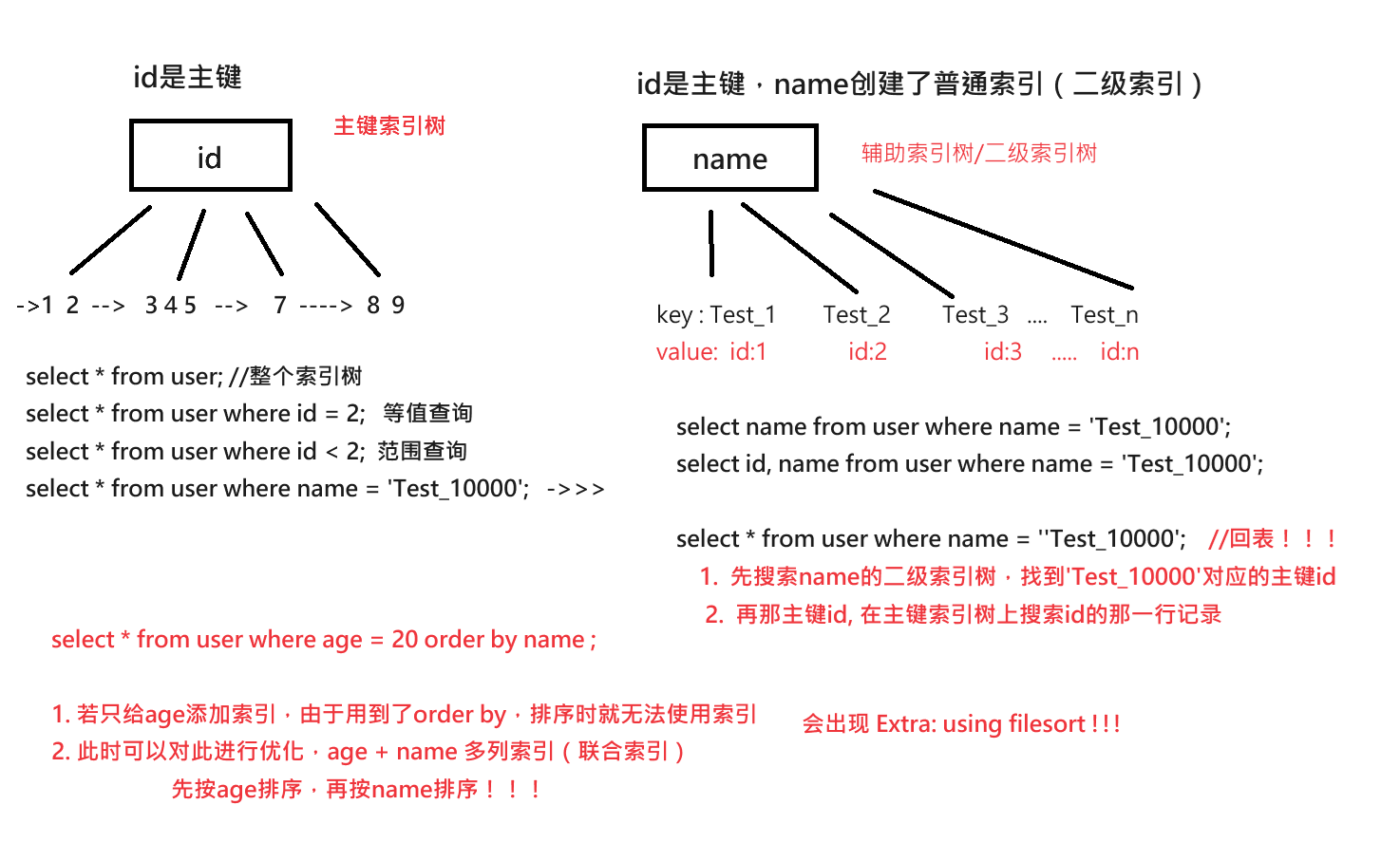
user表中 id为主键 这里默认InnoDB
1、explain select * from user where id = 1;做等值查询 type: const
2、explain select * from user where id < 5;做范围查询 type: range
3、explain select * from user where name = 'Test_10000';做整表搜索
user表中 id为主键,name创建了普通索引(二级索引)
1、explain select name from user where name = 'Test_10000'使用辅助索引 type: ref
2、explain select id, name from user where name = 'Test_10000';使用辅助索引 type: ref
3、explain select * from user where name = 'Test_10000';这里涉及到了回表操作:
- 先搜索name的二级索引树,找到 'Test_10000’对应的主键id:10000
- 再那id = 10000回表,在主键索引树上搜索id对应的那一行记录






这里进行一次查询:
select * from user where age = 20 order by name,只给age添加索引,行不行?(不行)
Extra:using filesort排序时无法用到索引,常见于order by、group by中
因此我们需要使用多列索引(联合索引)优化,先按age排序,再按name排序;age相同,则按name排序


下面给张图辅助理解
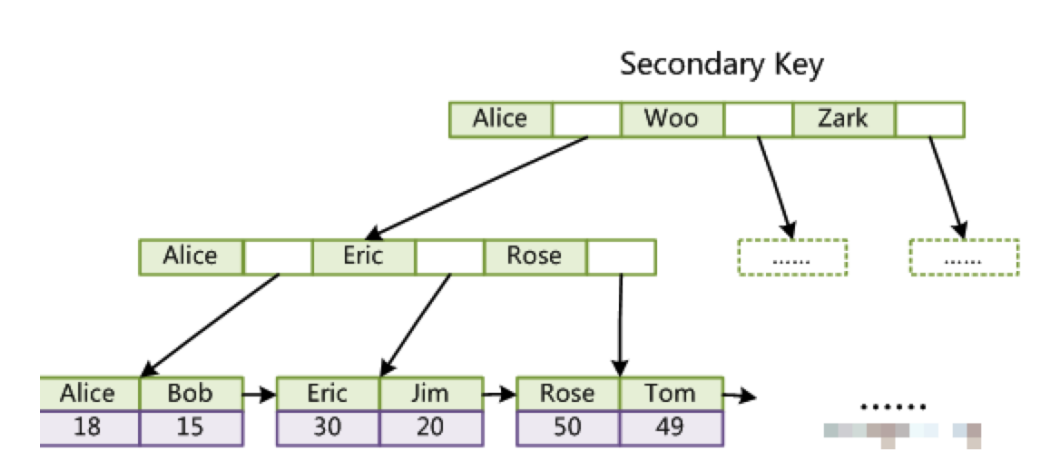
对于MyISAM存储引擎则是这样的
六、聚集索引和非聚集索引
-
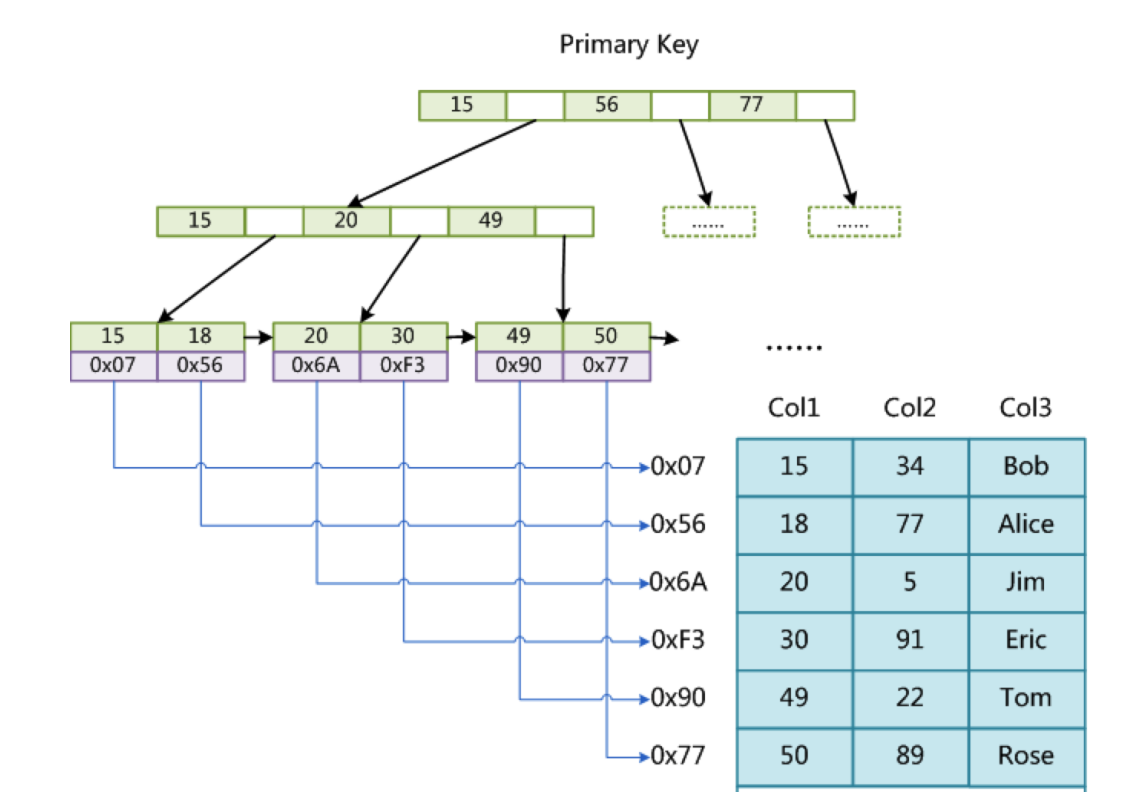
MyISAM存储引擎,索引结构叶子节点存储关键字和数据地址,也就是说索引关键字和数据没有在一起存放,体现在磁盘上,就是索引在一个文件存储,数据在另一个文件存储,例如一个user表,会在磁盘上存储三个文件 user.frm(表结构文件)user.MYD(表的数据文件) user.MYI(表的索引文件)。MyISAM的索引方式也叫做非聚集索引。
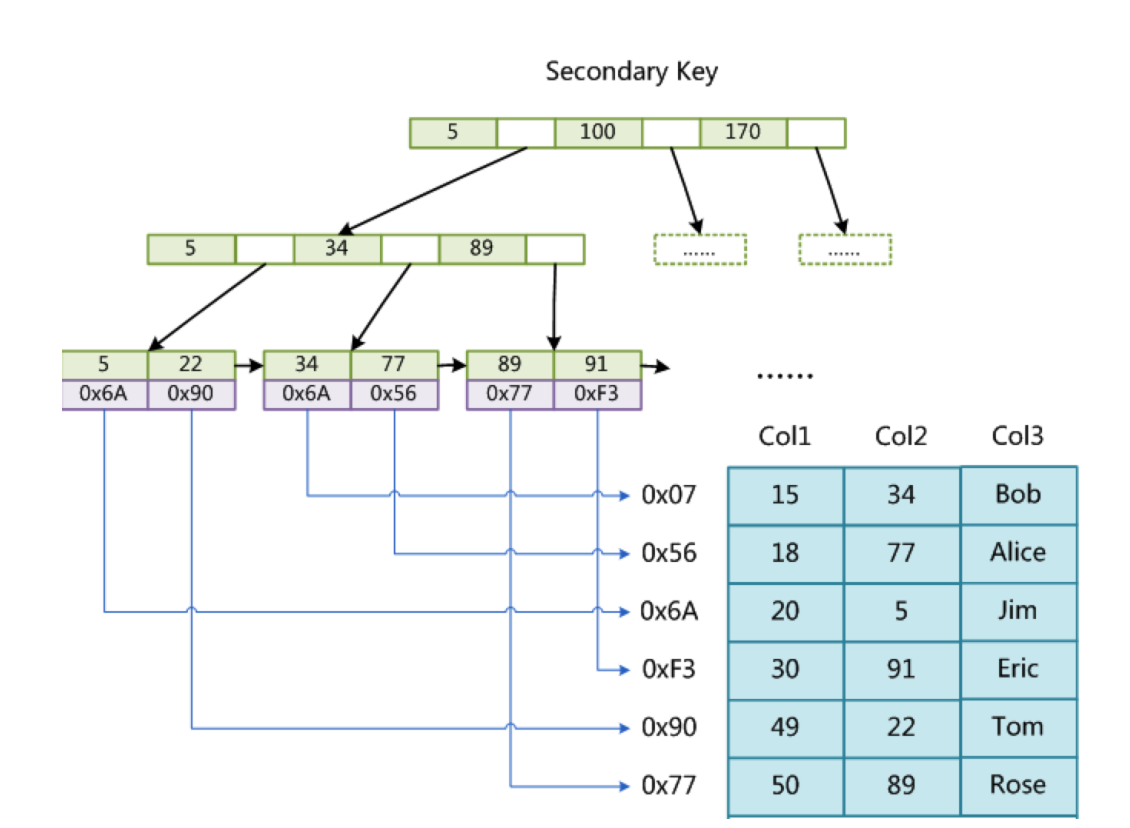
-
InnoDB的索引树叶节点包含了完整的数据记录,这种索引叫做聚集索引。 因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(区别于MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
七、哈希索引
> B+树索引 O(logn) : 搜索效率好、磁盘IO少
> 哈希索引 O(1): 基于Memory存储引擎
create index name_idx on user(name) using hash / btree; 创建哈希索引,InnoDB不支持
show create table user\G; //不准确
show indexes from user; //真实
- 哈希表中的元素没有任何顺序,只适合等值比较,—
select * from suer where name = 'Test_1';,对于like ‘xx%’,范围查询,前缀搜索,order by排序等等都不行 - 没办法处理磁盘上的数据,加载到内存上构建高效的搜索数据结构,因为它没法减少磁盘IO次数
- 只适合基于内存上的搜索
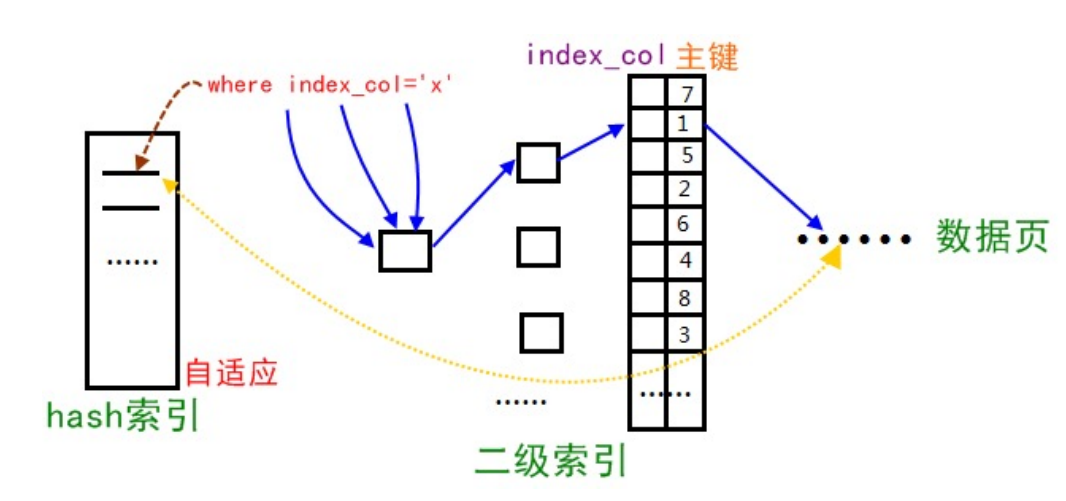
八、InnoDB的自适应哈希索引
当InnoDB存储引擎检测到有同样的二级索引不断被使用,那么它会对这个二级索引,在内存上根据二级索引树(B+树)上的二级索引值来创建一个哈希索引,加速搜索
#查看自适应是否开启
show variables like 'innodb_adaptive_hash_index';
#查看分区个数
show variables like 'innodb_adaptive_hash_index_parts';
#查看自适应哈希索引的使用情况
show engine innodb status\G;
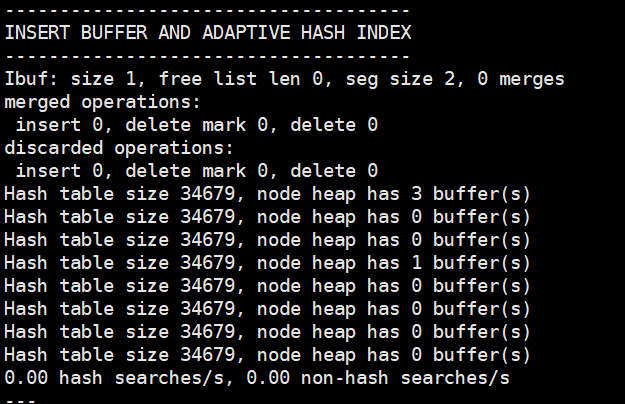
注意:自适应哈希索引本身也是需要耗费性能的,不一定会在任何情况下都能够提升二级索引的查询性能,需要根据参数指标,具体分析是否需要打开或者关闭,比如,当RW-latch等待的线程数量过多,同一个分区等待的线程过多, then it might be useful to disable adaptive hash indexing. /
九、索引常见问题
1、为什么有时我们给指定字段添加了索引,但是在搜索的时候,仍然是做的整表搜索?
- 因为该字段在表中的内容区分度不大,用索引搜索和直接整表搜索差别不大,索引搜索还需要加载磁盘文件,因此mysql会直接做整表搜索
2、查询条件有多个字段,也涉及不同的表JOIN,有些字段建立了索引,会使用哪一个?
- 由于每次查询只能用到一个索引,mysql会优先找小表的(在where条件过滤后,表行少的),即小表决定循环的次数,大表决定每次循环的时间
3、.............
- …
十、慢查询日志
虽然我们可以通过explain分析select语句来进行sql语句查询的性能,但是对于一个项目而言,可能包括了很多业务操作,其中mysql语句也是不计其数,这是我们可以依靠 慢查询日志,找出指定的运行时间长、耗性能的sql,进行分析优化
主要步骤:
- 开启慢查询日志,设置合理的慢查询时间
- 压测执行各种业务
- 查看慢查询日志,找出所有执行耗时的sql
- 用explain分析耗时的sql
- 举例…
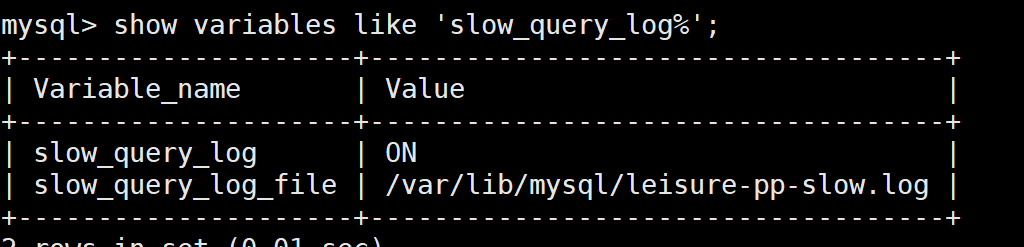
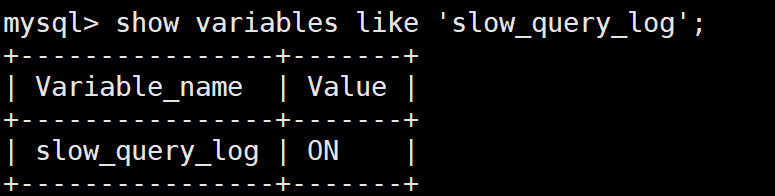
show variable like 'slow_query_log%'
set global slow_query_log=on/off
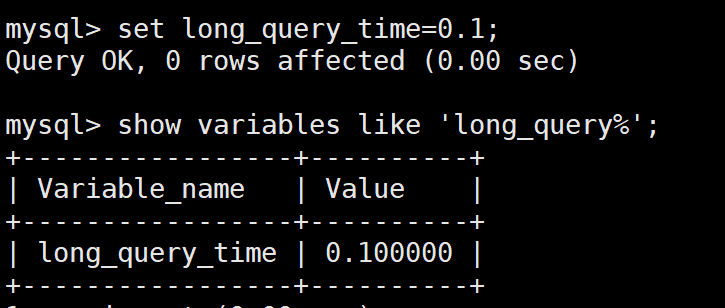
show variables like 'long_query_time%'
set long_query_time=0.1100ms,只对当前的section起作用,global对全局
这里我们进行一次耗时的查询
select * from user where name = 'Test_1000000';
进入root用户,在/var/lib/mysql/下查慢查询日志
由此,我们可以对它做explain分析
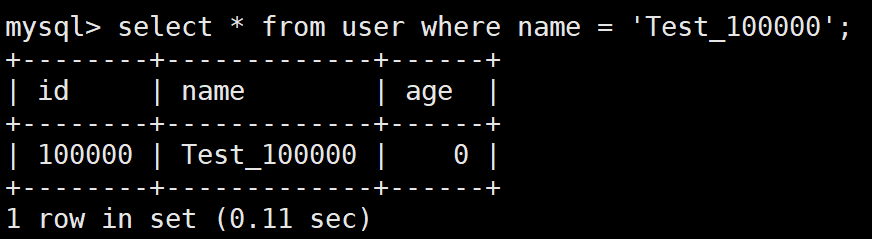


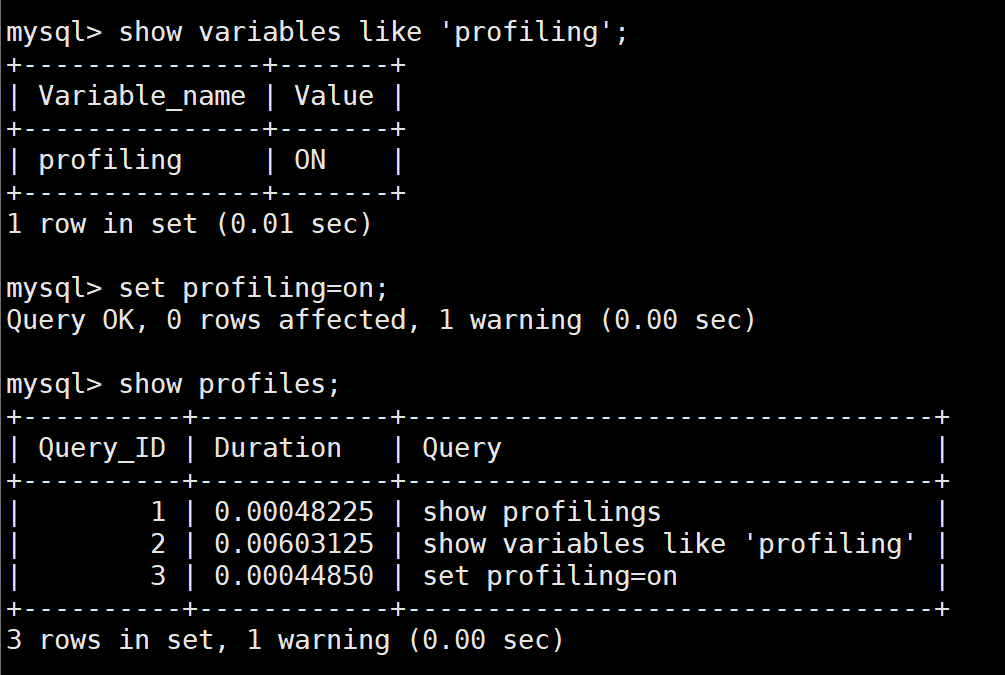
有些查询时间不是很长,若需要了解它,可以
show variable like 'profiling';set profiling=on;show profiles;
总结

🌻🌻🌻以上就是有关于MySQL存储引擎及索引机制的内容,如果聪明的你浏览到这篇文章并觉得文章内容对你有帮助,请不吝动动手指,给博主一个小小的赞和收藏 🌻🌻🌻





![[unity] c# 扩展知识点其一 【个人复习笔记/有不足之处欢迎斧正/侵删】](https://img-blog.csdnimg.cn/direct/f8e947272a5047ff9e66cc18b84923d2.png)