一首歌,包含作词作曲两个部分。擅长作词or作曲就已经很牛了。比如方文山是周杰伦的御用作词人,而周杰伦写过很多耳熟能详的曲子。而兼具作词作曲才华的全能创作人却是难得一见。
最近港中文发布了一款歌曲创作大模型SongComposer,作词作曲都不在话下。 并且擅长让歌词和旋律相互交融,让整首歌听起来更加和谐。

先来几个小demo一起欣赏一下:
根据歌词编写旋律:
歌词:突如其来的那一场 谁在路旁 在路旁 听见我自由放声唱 和我一样 背上行囊 脚步丈量远方
Given Lyrics,夕小瑶科技说,13秒
根据旋律作词:
给出以下旋律:
melody,夕小瑶科技说,23秒
生成的歌词:他们也曾像我一样 追着风跑着 却找不到方向 只能像我这样 停在路上 有一点累 却也不觉的 有一点心为了追逐梦想 我总是选择最难的路
最终合成的歌曲:
melodyGsong,夕小瑶科技说,20秒
续写歌曲:
给出歌曲的开头
songprompt,夕小瑶科技说,5秒
续写结果
songpromptContinuation,夕小瑶科技说,16秒
根据文本生成歌曲:
甚至你需要输入“用悠扬的旋律和缓慢的节奏创作一首关于爱和自由的歌曲”,SongComposer就能根据文本提示生成一首包含词曲的歌:
Given Text,夕小瑶科技说,22秒
怎么样,是不是听起来还不错,有那味了。如果再加上编曲老师的润色,一首完整度较高的流行歌曲就完成了!

除此之外,作者还发布了用于训练的歌词-旋律配对数据集,以及一套评估生成歌曲质量的指标,相信可以推动智能音乐创作往前迈进一大步!
论文标题:
SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation
公众号「夕小瑶科技说」后台回复“SongComposer”获取论文PDF!
SongCompose-PT Dataset
本节概述了SongCompose-PT数据集的编制、创建和结构,其中包括单独的歌词、旋律和在单词级别上将歌词与旋律同步的歌词-旋律配对集合。
纯歌词数据集
从两个在线来源收集纯歌词数据集:
-
Kaggle数据集,包括带有Spotify Valence标签的15万首歌曲的歌词。
-
Music Lyric Chatbot数据集,包含14万首中文歌曲的歌词。从28.3万首中英文歌曲中删选而来的高质量的歌词。
纯旋律数据集
为了将旋律数据集组织成基于文本的结构,使用MIDI文件作为纯旋律数据集,其结构简单,能够在没有复杂音频处理的情况下高效提取和操作旋律。
使用pretty midi解析MIDI文件,仅从中提取“旋律”或“人声”轨道,由于MIDI中的旋律被表示为随时间推移的一系列音符,每个音符具有特定的音高、开始和结束时间戳,最终获得一个旋律属性三元组列表,包括{音符音高、音符持续时间、休止符持续时间}。
其中约4.5万条条目来自LMD-matched MIDI数据集,约8万条来自网络爬虫。再进行必要的数据过滤以删除重复和质量不佳的样本,最终剩下大约2万个MIDI样本。
配对歌词-旋律数据集
大量歌词和旋律配对数据对于训练LLM进行歌曲创作非常重要。但是歌曲与旋律的对齐非常困难,需要详细的注释和特定的专业知识。它包括确保歌词与一个或多个旋律音符精确匹配,并标注精确的时间戳,如下图所示:

本文利用了来自LMD-full数据集的7,998首歌曲,以及来自Reddit数据集的4,199首歌曲。此外,还结合了OpenCpop数据集其中100首中文流行歌曲,以及M4Singer数据集其中700首高质量中文歌曲。
为了进一步丰富配对歌词-旋律数据,本文还抓取网络信息创建了一个包含4,000首经典中文歌曲的数据集。收集歌词-旋律数据的流程如下图所示:
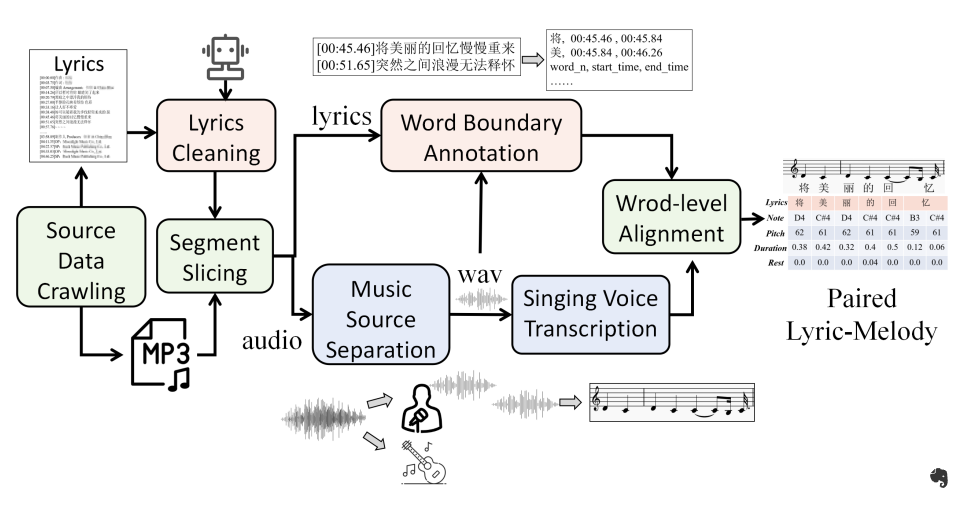
-
数据来源爬取:搜集大量的mp3文件及其对应的歌词文件,包括句级别的时间戳。
-
歌词清理:使用GPT-4清理歌词文本中的不相关细节,如歌曲标题、艺术家姓名和制作信息。
-
分段切片:为了减轻长时间对齐的挑战和误差积累,根据歌词文件中提供的时间戳将音频和歌词切片为大约10秒的配对段落(每个段落大约三句)。
-
音乐源分离:利用UVR4这个公开的音乐分离工具,从原始音频中分离人声和伴奏部分。
-
歌声转录:使用数字音频工作站软件FL Studio5自动生成初步的乐谱,捕捉每个音符的音高和起始-结束时间。
-
词边界注释:通过Pypinyin6将歌词转换为音素序列,然后利用音频对齐工具——Montreal Forced Aligner获取歌词中每个词语的边界。
-
词级别对齐:利用动态时间扭曲(DTW)算法,根据起始-结束时间对单词和音符进行对齐。
最后,本文开发了一个包含约15K个配对歌词-旋律条目的数据集,其中约5K首为中文,10K首为英文。
SongComposer
LLM友好的歌曲表示
元组数据格式
为了将歌词和旋律输入到LLM中,一个直观的策略是按顺序排列它们,从一系列歌词开始,然后是一系列音符值和时长。然而,由于其顺序化方法,模型很难对齐歌词和旋律,导致产生不对齐的输出。
作者提出了一种统一的输入组织方式,利用基于元组的格式,其中每个元组代表一个离散的音乐单元,可以是一个歌词,一个旋律,或者一个歌词-旋律对。
具体来说,在纯歌词数据的情况下,在每个元组中插入一个单词。对于纯旋律,在每个元组中包括音调、音符时长和休息时长。对于歌词-旋律对,将歌词和相应的音符元素合并在同一个元组内。由于一个单词可以对应多个音符,一个单元组可能包含一个单词以及多个音符和它们各自的时长。使用竖线(|)来分隔不同的元组,并将元组序列作为LLM的输入,如下图所示。

这种元组格式明确地为模型提供了歌词和旋律之间的相互映射,有助于掌握元素之间的对应关系。
离散化时长
为了有效处理旋律中的时长信息,采用对数编码方案将时长分为预定义数量的bin,将连续的时长范围转换为一组离散值。这种为LLM提供的组织良好且简洁的输入增强了模型捕捉音乐内容的精确时间变化的能力。
具体来说,根据时长的统计分布,将它们截取到 [xmin, xmax]。对于任意时长x,编码过程定义如下:
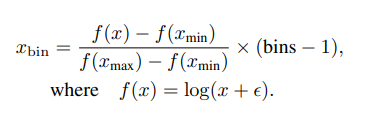
设置 [xmin, xmax] = [-0.3, 6],bins = 512,ϵ = 1,这使得时长可编码为512个离散整数,最高可达6.3秒。相反,要将离散化值解码为原始时长:
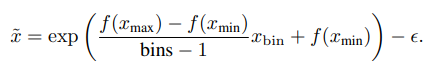
词汇扩展
为了确保清晰度,通过引入由〈•〉符号表示的辅助标记,针对离散化的时间单位和音符值在模型词汇中推广表示形式。对于时间离散化,扩展了512个独特token,表示为。对于音乐音符的表示,标记了十个八度内的12个音高类别,从而添加了120个不同的音乐token。
两阶段训练
预训练阶段
为了丰富LLM的基础音乐知识,首先在大量纯歌词和纯旋律的语料库上对模型进行预训练。
对于旋律,采用音高移调来增强数据集。具体来说,将音高移动高低四个半音,从而将数据集扩大了九倍。
对于歌词将整首歌曲的数据拆分成基于句子的样本,每个样本包含五到十行。这种制定使得模型能够获得更加专注和相关的学习上下文,有助于更连贯地生成歌曲。
通过这种纯歌词和旋律的训练过程,模型已经获得了扎实的音乐知识基础,为更加关注歌词和旋律之间对应关系的高级学习奠定了坚实基础。随后,使用配对数据引导模型生成对齐的歌词-旋律对。根据经验,为了保留模型处理旋律和歌词的能力,以1:1:1样本比例向模型输入相等数量的纯旋律、纯歌词和配对数据。
总共有0.23B个歌词tokens、0.28B个旋律tokens和0.16B个配对数据tokens。所有数据都是使用元组数据格式输入的。
监督微调阶段
在将大量乐谱和歌词引入模型后,为歌曲生成制作指令遵循数据,包括给定歌词创建旋律、为旋律写歌词、扩展歌曲部分以及根据文本描述生成歌曲。其中,为前三个任务手动准备了3K个问答对。对于最后一个任务,使用GPT-4生成了1K首歌曲摘要,这些摘要又形成了一个文本到歌曲的数据集,指导了歌曲创作过程。
客观评价指标
本文还构建了一个包含1188首歌曲的验证集。其中,415首是中文歌曲,773首是英文歌曲。在后续测试中,将一些歌曲随机分割成5至10个句子。客观评估的重点是评估生成的输出与真实样本之间的相似性。
旋律生成
对于旋律评估,采用了SongMASS(提出的度量标准。其中包括音高分布相似度(PD)、时长分布相似度(DD)和旋律距离(MD)。由于与SongMASS相比的校准策略的不同,通过加法对齐ground truth和生成音符的平均音高。
歌词生成
在歌词生成方面,使用CoSENT模型,评估句子级别的对齐。该模型允许输入歌词,并计算生成歌词与原始歌词之间的余弦相似性。此外,结合ROUGE-2分数和BERT分数作为另外两个用于评估歌词生成的度量标准。ROUGE-2分数关注生成文本和原始文本之间的二元组重叠。BERT分数利用BERT-base multilingual uncased 模型基于上下文嵌入来衡量文本相似度。
主观评价指标
选取30名参与者对每个任务中有10个案例进行评价。评分范围为1到5,得分越高表示质量更高。
歌词到旋律生成
歌词到旋律生成要求根据给定的歌词创作出一段合适的旋律。对旋律进行评估包括:(1)和声(HMY.):评估旋律的整体质量。
(2)旋律-歌词兼容性(MLC.):检查生成的旋律与给定歌词之间的契合程度。
旋律到歌词生成
旋律到歌词生成旨在产生与提供的旋律相匹配的歌词。对歌词进行评估包括:(1)流畅性(FLN.):考虑生成歌词的语法正确性和语义连贯性。
(2)旋律-歌词兼容性(MLC.):检查生成歌词与给定旋律的契合程度。
歌曲延续性
歌曲延续涉及在旋律和歌词方面延长已有歌曲的部分。评估延续的质量包括:(1)整体质量(OVL.):衡量生成歌曲的整体质量,以其音乐吸引力为标准。(2)与歌曲提示的一致性(COH.):分析延续与提供的歌曲提示之间的自然融合,评估旋律、歌词和其他音乐元素的连贯性。
文本到歌曲生成
歌曲延续根据文本描述生成完整的歌曲,以音乐和歌词的形式捕捉其本质。评估重点包括:(1)整体质量(OVL.):衡量生成歌曲的整体质量,以其音乐吸引力为标准。(2)与文本输入相关性(REL.):检查生成歌曲与输入文本的对齐度和相关性。
实验结果
歌词到旋律生成
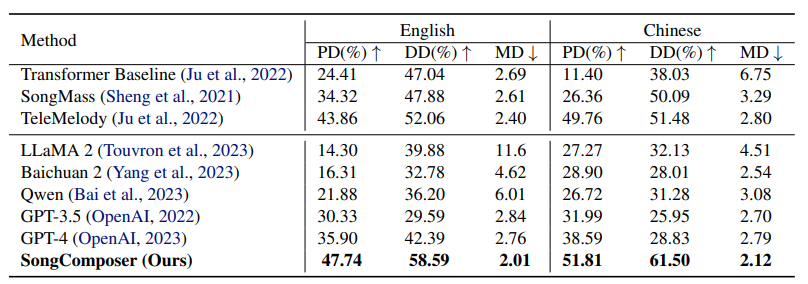
如上表所示,该方法在调性分布相似度(PD)和时长分布相似度(DD)方面优于先进的语言模型,比GPT-4高出10个多点,并在中英双语中实现了最低的旋律距离(MD)。

▲主观评估
另外,在主观评估中发现SongComposer在和声和旋律-歌词的搭配方面比GPT-3.5和GPT-4要好很多。这意味SongComposer更擅长让歌词和旋律相互配合得更好,让整首歌听起来更和谐。
旋律至歌词生成
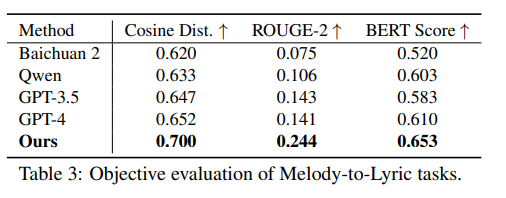
该方法在生成与原始歌词紧密匹配的歌词方面非常有效。主观评估显示,用户们一致认为SongComposer在产生歌词方面非常流畅且与旋律高度相关,能够有效地捕捉并补充底层旋律的节奏。
歌曲延续
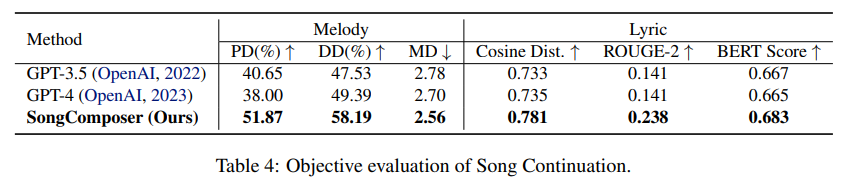
SongComposer不仅能够独立产出高质量的歌词和旋律,还能够将它们结合起来,使整首歌听起来更和谐。
文本至歌曲生成

在文本至歌曲生成的主观评估中,SongComposer可以根据文本提示创作出旋律优美、主题和情感完美契合的歌曲。
消融实验
在消融研究中本文报告了针对歌词到旋律和旋律到歌词任务的旋律距离(MD)和BERT分数。
预训练数据集
为了探究专门数据集对模型学习的影响,作者使用了不同纯歌词和纯旋律数据集的配对数据进行训练实验,结果如下表所示:

研究结果显示,如果省略了纯歌词和纯旋律的数据集,模型的性能会明显下降。这表明在训练的早期阶段,基础旋律和抒情知识的重要性。纯歌词数据集主要提高了旋律到歌词任务的性能,而纯旋律数据集则更明显地提高了旋律生成的水平。而结合歌词和旋律数据集能够带来最佳的效果。
旋律知识的扩展词汇
为了了解专门用于旋律知识的标记是否有利于SongComposer的性能,本文对不同的标记组合进行了消融,评估它们对模型处理和生成音乐内容的影响,如下表所示:

首先,在时长标记方面,直接将原始基于浮点数的秒数输入到SongComposer中,而非应用离散数字。缺乏特殊时间标记将导致模型无法为歌词到旋律任务生成正确结果。
相反,引入离散时长标记显著提高了旋律到歌词任务的表现,无论是否引入音符标记,BERT分数都提高了超过0.03。这验证了时长离散化对掌握旋律结构的重要性。
其次,采用音符标记在两个任务中都带来了显著改进,使用音符标记有助于模型更好地理解音符的含义,并提高了学习的效果。
结论
SongComposer利用符号化的歌曲表示法来生成旋律和歌词,在各种任务中表现出色,如将歌词转换为旋律、旋律生成歌词、歌曲延续和基于文本描述的歌曲创作,甚至在性能上超越了像GPT-4这样的先进LLM模型。
相信SongComposer可以为LLM在音乐领域的创意应用开辟新的途径。
公众号「夕小瑶科技说」后台回复“SongComposer”获取论文PDF!







![[回归指标]R2、PCC(Pearson’s r )](https://img-blog.csdnimg.cn/direct/39f0c9ad0e72430ebdf2082666e0b95c.png)