🎬慕斯主页:修仙—别有洞天
♈️今日夜电波:会いたい—Naomile
1:12━━━━━━️💟──────── 4:59
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
再谈地址空间及物理内存
再谈页表
缺页中断
再次理解线程
线程的优缺点
线程的优点
线程的缺点
面试常问
再谈地址空间及物理内存
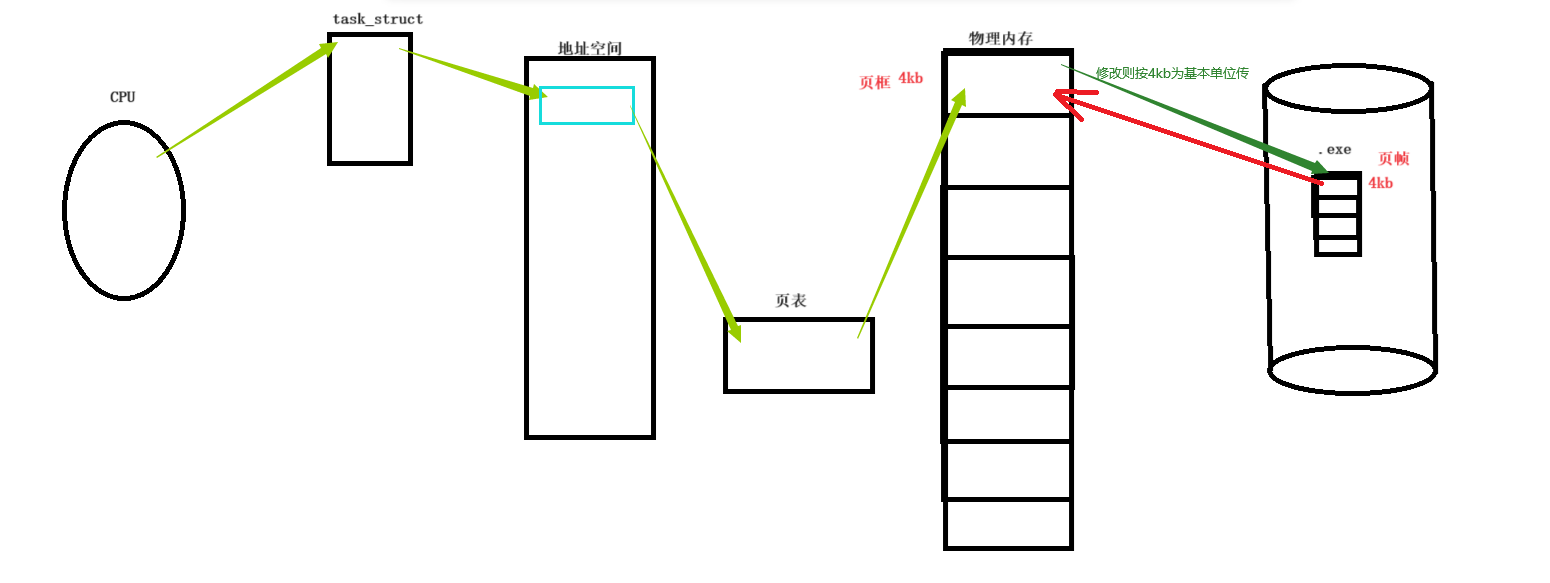
前面我们谈到,一个可执行程序或者文件中无论他的属性还是数据块都是以4kb为单位进行储存在磁盘上的(当然这个4kb这个基本单位是可以修改的!但是,这属于特殊情况,大多数还是基本单位还是4kb),如果我们要执行某可执行程序,需要以4kb为基本单位映射到物理内存当中,再通过页表映射到地址空间上供对应的进程进行控制。现在,我们进一步的进行理解:对此,我们将可执行程序中一个形成为4kb的大小称为页帧,而物理内存中也需要像exe中以4kb为基本单位来进行存储,磁盘将exe中的页帧映射到物理内存中,而物理内存对应的映射块称为页框,exe将多少个页帧映射到物理内存上,则物理内存就需要有多少个页框进行承装!如果我们要对某个文件进行修改,那么也是按这个基本单位将物理空间上以一个一个的页框为io的基本单位刷新到磁盘上的!如下图所示:
我们都知道inode是128b的,则一个基本单位4kb可以存储32个inode,如果我们要访问一个文件,我们加载inode时,可能会一次性加载多个inode。
前面谈到了文件缓冲区的概念,这里进一步阐述,文件缓冲区实际上就是对内存当中属于这个文件的一个个内存页中对应的数据结构以及数据对象进行关联。如下图所示:
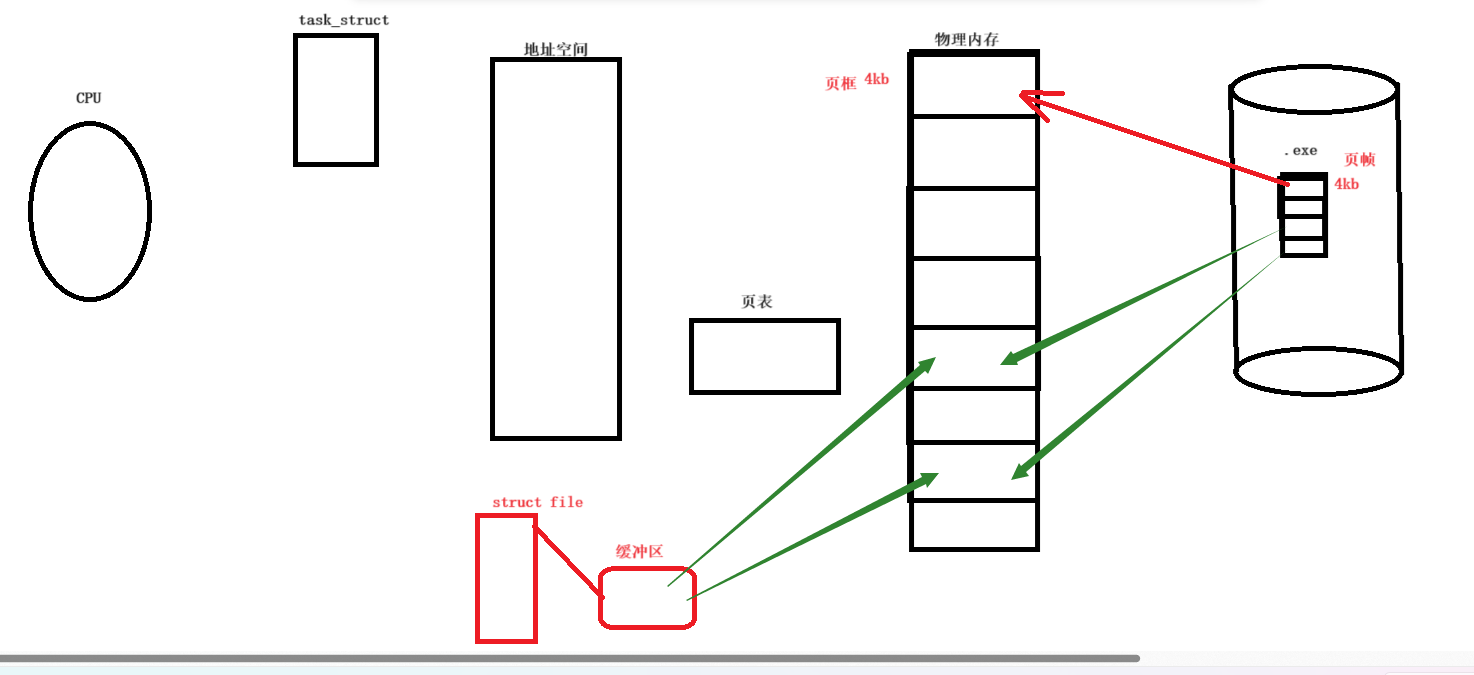
当然,我们的页框的使用情况操作系统也是需要知道的,因此操作系统需要管理全部页框,因此要先描述,在组织。操作系统会维护一个数据结构struct_page,这个数据结构实际上不大,大概只有10几kb。如下:
struct page
{
//描述一个page的使用情况 int flag; //用比特位来表示如正在被使用,
//是否准备被释放等等使用情况,可以用一个整数+宏来表示。
//page的属性
}
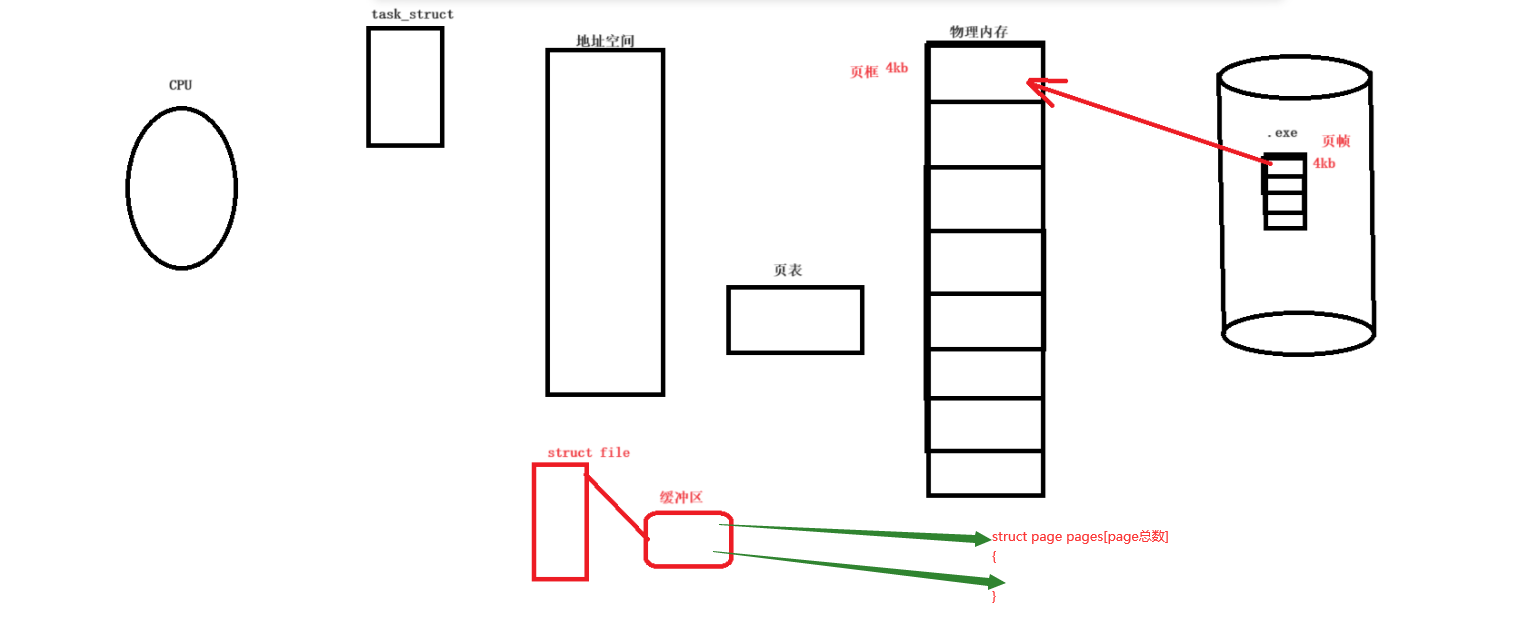
当然,我们上面的是一个page的情况,也就是先描述,后续我们可以定义一个大的数组来组织:struct page pages[page总数] 。当然,上述只是简化的情况,实际的数据结构会更复杂!会有内存管理的算法,比如LRU等等。对物理内存的管理,现在就变成了对于数组的增删查改。
在理解了page的相关知识后,我们再次理解缓冲区的概念,我们的缓冲区真的是直接指向物理内存吗?实际上他是指向了相关的struct page的地址或者数组下标即可。如下:
再谈页表
页表实际上的结构是怎么样的呢?虚拟地址到物理地址的转换实际上是怎么样的呢?CPU中有个组件MMU可以将寄存器中的虚拟地址转换为物理地址,虚拟地址到物理地址的转换实际上只是在CPU内部进行的。在此前我们只知道虚拟地址只是有32个比特位。如:1111 1111 1000 0000 1000 0000 0001 0001实际上会将虚拟地址按照10、10、12来划分为三个部分。分别为页目录、页表、偏移量。可以看到对应的大小为1024b、1024b、4kb。页目录是用于查找页表的,他会存储对应页表的地址(因为具体在什么位置操作系统也不知道),然后页表的内容会指向页框的起始地址,也就是说页表内存的是页框!因此,如果我们要将虚拟内存映射到物理内存只需要页目录+页表即可,也就是1024b*1024b大小,也就是2的20次方项地址。而后面的12位是可以看到是刚刚好4kb!那么我们要找到对应的物理内存只需要将页表内的页框地址加上对应的偏移量即可!具体的图示如下:

缺页中断
通过上面对于页表的理解,我们也理解到了通过页目录以及页表就可找到对应的物理地址。但是,当我们根据局部性原理集中的访问一段区域,后面的页表并没有访问过,那么我们可以不急着创建对应的页表,只有当要使用的时候,我们再去创建!
再次理解线程
再次理解了虚拟地址到物理地址的转换后,我们在理解一个线程要划分对应的资源时(如:代码和数据),本质上就是在划分页表!
划分页表的本质:划分地址空间!
划分地址空间的例子:线程创建的接口会传入一个函数,而这个函数经过汇编之后你会看到很多的虚拟地址,我们在申请对应的空间后会得到对应的虚拟地址,一个函数会有多行代码,也就是说有很多的地址。定义一个变量也会有对应的地址。划分地址空间实际上就是占有了虚拟地址上的一部分地址空间,划分了自己的势力范围!
变量拓展:我们在定义某个类型的变量的时候互得到一个虚拟地址,但是按照对应的定义他会有几个字节的空间,但是我们取地址又只能得到一个地址。这是因为类型的本质就是偏移量!当我们定义好一个变量时就决定了内存和CPU之间用怎么样的寄存器来存取!
在进程的视角:虚拟内存本身就是资源!
线程的优缺点
线程的优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
线程占用的资源要比进程少很多
能充分利用多处理器的可并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
合理的使用多线程,能提高CPU密集型程序的执行效率合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
线程的缺点
性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
面试常问
线程哪部分资源是私有的?
一定要答到线程是有独立的硬件上下文的(证明你是有动态切换的概念),每个线程要有自己的栈结构(证明你有动态运行的概念)。
更加详细:
线程共享进程数据,但也拥有自己的一部分数据:
线程ID、一组寄存器、栈、errno、信号屏蔽字、调度优先级
感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~










![[AutoSar]BSW_Com07 CAN报文接收流程的函数调用](https://img-blog.csdnimg.cn/direct/298b21f30103430c9548e0a41b8bd4b6.png)