被检项目源代码的识别在多个语言解析器的支持下工作,根据不同匹配算法,可以计算与特征值索引数据库的匹配情况。针对强匹配算法,源代码的特征值必须与索引数据库的特征值一致,才可认为是该开源组件;针对非强匹配算法,比如混淆后的代码,则需要计算特征值之间的相似度,根据相似度的阈值确定是否是该开源组件。输入是项目,输出的检测结果中给出具有与该项目相同或相似的项目、包、文件、类及函数。下面对分析流程进行简要说明,如下图所示:
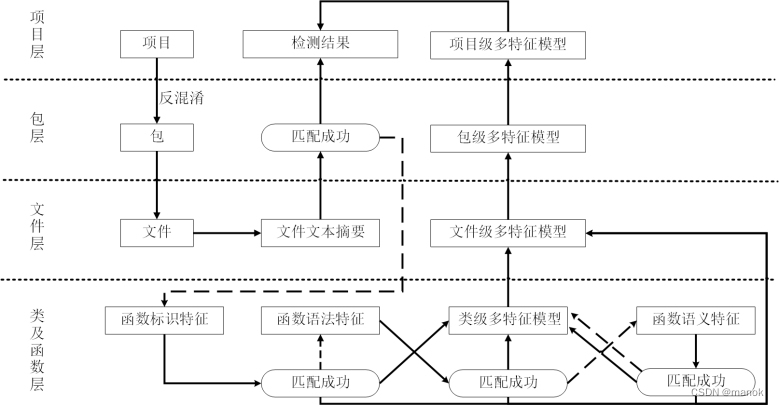
图 代码实体识别匹配
(1)将输入的项目首先使用反混淆技术进行预处理,然后按目录结构划分为多个包,每个包下有不同的文件;
(2)计算文件的文本摘要,并根据该摘要在数据库中匹配相同的文件。如果包下面所有的文件匹配成功,则该目录得到匹配。如果所有目录得到匹配,则项目找到对应的匹配,程序结束;
(3)否则,将未得到匹配的文件进行解析,得到函数级别的标识集合,并依次提取函数标识特征、语法特征和语义特征。如果基于相应特征在数据库中匹配到相同的文件,则建立类级和文件级多特征模型。否则,提取函数的下一层特征并进行匹配;
(4)依据类级和文件级多特征模型,在库中进行匹配,结合匹配结果形成包级多特征模型;
(5)根据包级多特征模型计算整个项目与库中项目、包、文件、类以及函数之间的相似性,得到项目的多特征模型,并报告检测结果。
基于特征库的匹配算法,则是从文本、标识、语法、语义四个方面进行匹配,称为指纹匹配算法。在每个方面存在三种匹配方式,第一种是依据摘要的匹配方式;第二种是依据特征向量或特征向量哈希值的匹配方式;第三种是针对标识袋(Bag-of-tokens)的部分索引的匹配方式。
使用的匹配算法分为四个层次。
(1)基于摘要的识别匹配算法
对于摘要特征,匹配算法可以精确匹配到相同摘要值的函数、类、文件以及包含该函数、类、文件的包和项目。
(2)基于词法的识别匹配算法
对于词法分析生成的标识袋特征,匹配算法可以利用其部分索引快速定位相似的函数、类、文件以及包含该函数、类、文件的包和项目。
(3)基于语法的识别匹配算法
对于语法分析生成抽象语法树的特征向量或其哈希值特征,匹配算法可以近似定位目标函数、类以及包含该函数、类的文件、包和项目。
(4)基于语义的识别匹配算法
对于语义分析生成程序依赖图或值依赖图的特征向量或其哈希值特征,匹配算法可以近似定位目标函数、类以及包含该函数、类的文件、包和项目。
(结束)