一、常量与变量
常量:程序中使用的具体的数、字符。在运行过程中,值无法更改
变量:表示一一个存储单元,其中存储的值可以修改 如:a=5,b=6
变量命名:
1、只能包含字母、数字、下划线
2、只能以字母、下划线开头
3、不要使用关键字作为变量名称
二、基础数据类型
整数: int
浮点数: float (存在误差)
字符串: str
布尔: bool
获取变量类型: type函数
强制类型转换 :
整数: int()
浮点数: float ()
字符串: str()
布尔: bool()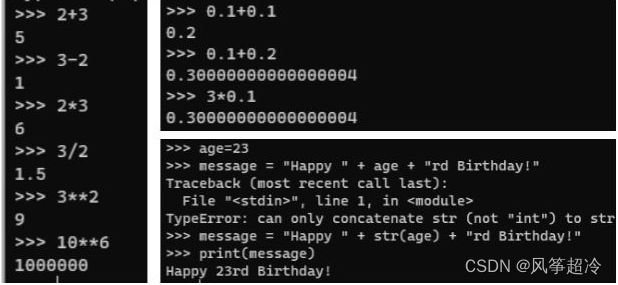
三、 数据类型转换
int转float:直接转换 7 -> 7.0
float转int:舍弃小数
int转bool:非0: True、 0: False
bool转int: False: 0、 True: 1
转str:直接转换
四、常用运算符
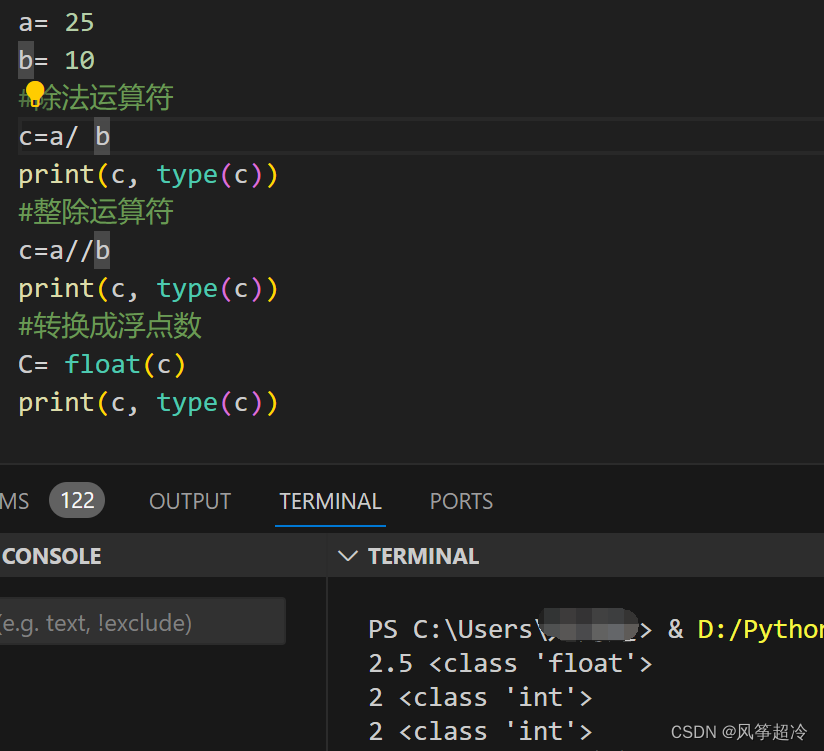
算术运算符:+、-、*、/、//(整除)、%(求余)、**(幂)
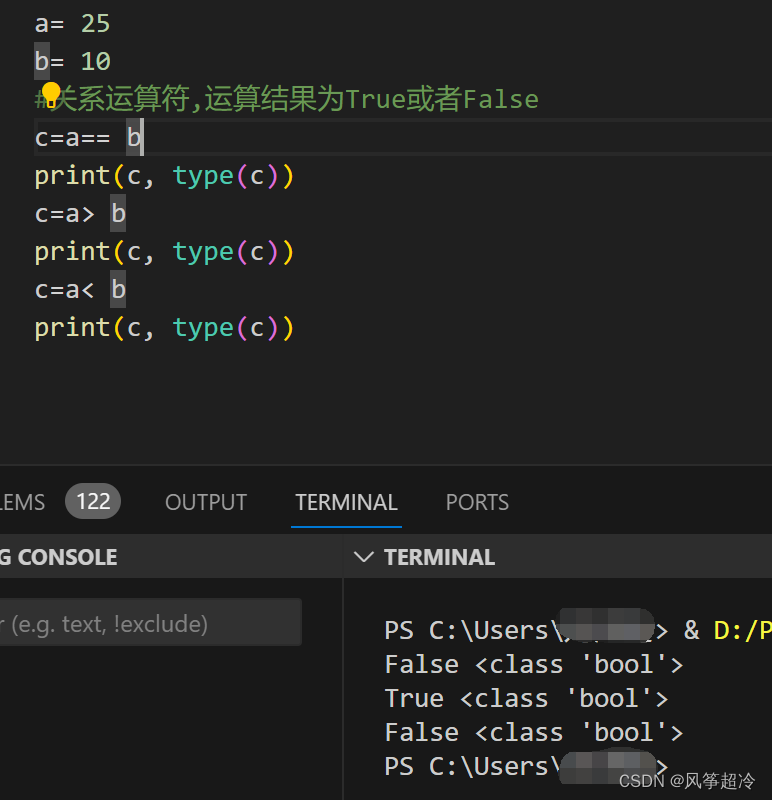
关系运算符:>、<、==、!=、>=、<=
赋值运算符: =、+=、-=、
*=、/=、%=、//=、**=
逻辑运算符: and、 or、 not

成员运算符: in、 not in
身份运算符: is、 is not
五、输入输出 函数
print()用于打印输出,是最常见的一个函数。
语法: print(*objects, sep=' ', end="\n', file=sys.stdout, flush=False)
参数说明:
1、objects:表示输出一个或者多个对象。输出多个对象需要用sep分隔。
2、sep:输出多个对象时使用sep分隔,默认值是一一个空格。
3、end: 输出结束以end结尾,默认值是换行符\n,可以换成其他字符串。
print(1)
print("Hello World")
a= 1
b= 'runoob '
print(a,b)
print("aa","bbb" )
print("aa" ,"bbb")
print("www",lanqiao, "cn",sep="+") #设置间隔符
input()输入输出函数
语法: input([prompt])
参数说明: prompt: 提示信息
输入的变量均为str字符串类型
int()可以转换成整数
a = input("请进行输入:")
print(a,type(a))
a = int(input("请进行输入:"))
print(a,type(a))

六、选择结构
if语句
if condition:
# 在条件满足时执行的代码块
# 可以是一条语句或多条语句,必须相同缩进级别
elif another_condition:
# 如果上一个条件不满足,但是这个条件满足时执行的代码块
# elif子句是可选的,可以有一个或多个
else:
# 如果上面的条件都不满足时执行的代码块
# else子句也是可选的
Python使用缩进来表示代码块的层次结构,因此在if语句中,每个代码块都必须有相同的缩进级别。
在Python中可以在一个if语句块内部嵌套另一个if语句:
x = 10
y = 5
if x > 5:
print("x is greater than 5")
if y > 2:
print("y is also greater than 2")
else:
print("y is not greater than 2")
else:
print("x is not greater than 5")
for语句
range() 函数用于生成一系列数字,在 Python 中常用于 for 循环中,以便迭代一系列数字。
range(start, stop, step)
start:可选参数。序列的起始值,默认为0。stop:必需参数。序列的结束值。该值不包括在序列中。step:可选参数。序列的步长或增量值,默认为1。
range() 函数返回一个数字序列,从 start 开始,以 step 递增,直到但不包括 stop。
for num in range(10, 0, -1):
print(num)
for num in range(2, 10, 2):
print(num)
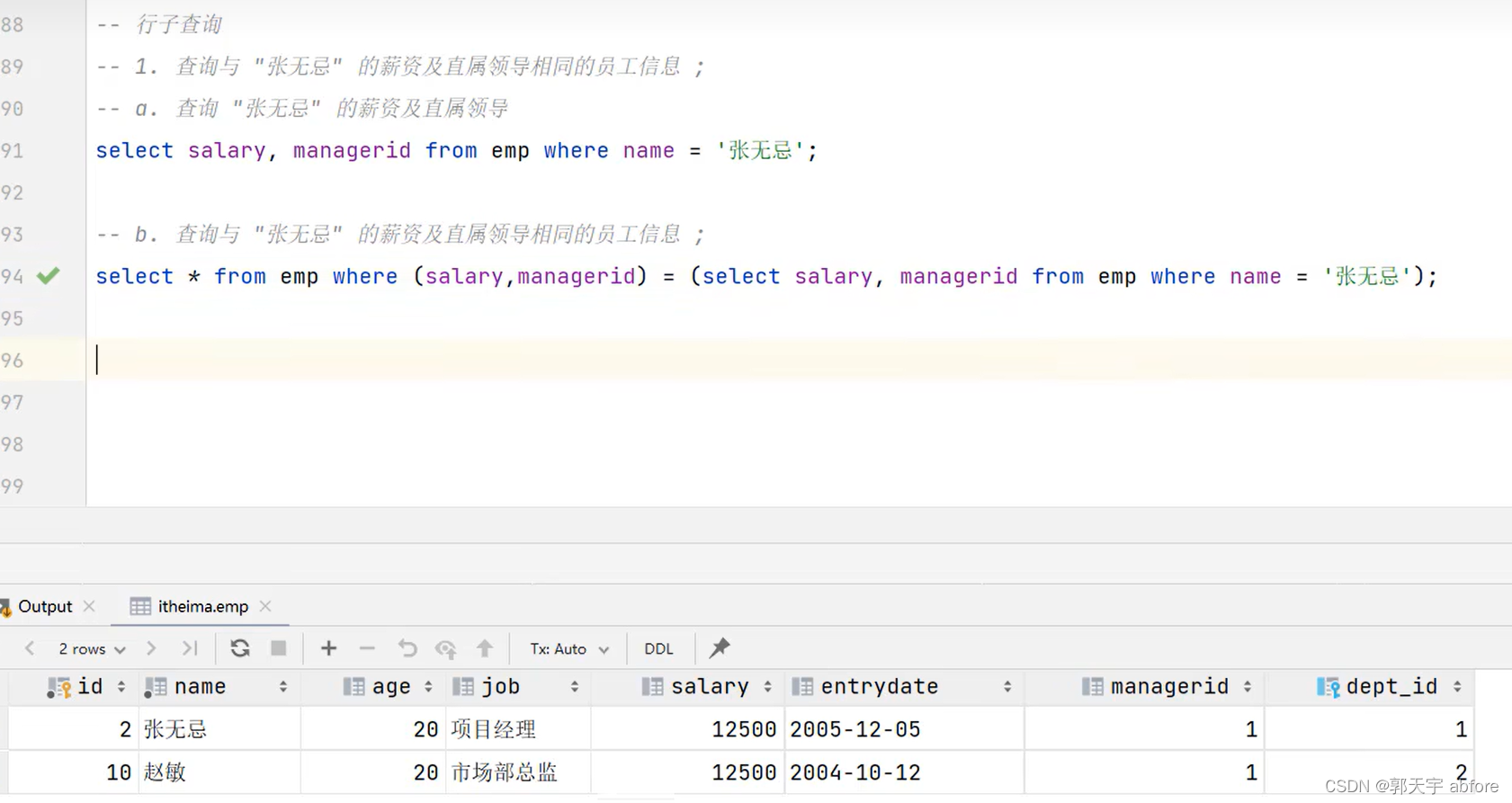
for 变量 in 序列:
执行代码块
变量:在每次迭代中,将序列中的元素赋值给变量。序列:可以是列表、元组、字符串等序列类型,或者是可迭代对象。执行代码块:在每次迭代中,执行缩进的代码块,这是循环体。
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)sum() 函数是 Python 内置函数之一
sum(iterable, start=0)
iterable:必需,一个可迭代的对象,如列表、元组等。start:可选,默认为0,指定初始值。
sum实现奇数求和
n = int(input("请输入整数 n(实现n以内奇数求和):"))
result = sum( range(1,n+1,2))
print(result)
while语句
while 条件:
执行代码块
条件是一个表达式,如果该表达式的值为True,则继续执行循环体中的代码块;如果为False,则退出循环,继续执行循环之后的代码。执行代码块是循环体,包含在while循环中要重复执行的代码。
total = 0
num = 1
while num <= 5:
total += num
num += 1
print("1 到 5 的和为:", total)
![]()
辗转相除法
辗转相除法,也称为欧几里德算法,是一种用于计算两个整数的最大公约数(Greatest Common Divisor,GCD)的算法。其基本原理是利用整数除法的性质以及两个数的除余操作。
辗转相除法的步骤如下:
- 将两个整数中较大的数除以较小的数,并计算余数。
- 将较小的数与余数进行同样的操作,直到余数为 0。
- 当余数为 0 时,最后一次的除数就是两个整数的最大公约数。
def gcd(a, b):
while b != 0:
a, b = b, a % b
return a
# 例子
num1 = 48
num2 = 18
print("48 和 18 的最大公约数是:", gcd(num1, num2))
初始时,a 为较大的数,b 为较小的数
break 和 continue
break 和 continue 是 Python 中用于控制循环的两个关键字。
break 关键字:
break关键字用于跳出当前所在的最内层循环(for 或 while 循环),并继续执行循环之后的代码。- 当
break被执行时,循环立即终止,不再执行循环体中未执行的代码,也不会继续下一次循环。 break通常用于在满足某些条件时强制退出循环,提前结束循环的执行。-
for i in range(5): if i == 3: break print(i)
continue 关键字:
continue关键字用于跳过当前循环中的剩余代码,并直接进入下一次循环的迭代。- 当
continue被执行时,循环中continue之后的代码不会被执行,而是直接开始下一次循环迭代。 continue通常用于在某些条件下跳过当前循环迭代,继续下一次迭代。-
for i in range(5): if i == 2: continue print(i)

七、基础数据结构
7.1 列表
列表的创建
列表使用方括号 [] 来表示,其中的元素用逗号 , 分隔。
# 创建一个空列表
my_list = []
# 创建一个包含整数元素的列表
my_list = [1, 2, 3, 4, 5]
# 创建一个包含字符串元素的列表
my_list = ['apple', 'banana', 'cherry']
# 列表中的元素可以是不同类型的
mixed_list = [1, 'apple', True, 3.14]
访问列表元素
my_list = ['apple', 'banana', 'cherry']
print(my_list[0]) # 输出:'apple'
print(my_list[1]) # 输出:'banana'
print(my_list[2]) # 输出:'cherry'
列表的切片
my_list = [1, 2, 3, 4, 5]
# 获取索引 1 到 3 的子列表(不包括索引 3)
sub_list = my_list[1:3]
print(sub_list) # 输出:[2, 3]
修改列表元素
列表是可变的,可以通过索引来修改其中的元素。
my_list = ['apple', 'banana', 'cherry']
my_list[1] = 'orange'
print(my_list) # 输出:['apple', 'orange', 'cherry']
添加元素到列表
可以使用 append() 方法向列表末尾添加新元素,也可以使用 insert() 方法在指定位置插入新元素。
my_list = ['apple', 'banana', 'cherry']
my_list.append('orange')
print(my_list) # 输出:['apple', 'banana', 'cherry', 'orange']
my_list.insert(1, 'grape')
print(my_list) # 输出:['apple', 'grape', 'banana', 'cherry', 'orange']
删除列表元素
可以使用 del 关键字、remove() 方法或 pop() 方法删除列表中的元素。
my_list = ['apple', 'banana', 'cherry']
del my_list[1]
print(my_list) # 输出:['apple', 'cherry']
my_list.remove('cherry')
print(my_list) # 输出:['apple']
deleted_element = my_list.pop(0)
print(deleted_element) # 输出:'apple'
print(my_list) # 输出:[]
7.2 元组
在 Python 中,元组(Tuple)是一种有序、不可变的数据结构,用于存储一组元素。元组使用圆括号 () 来表示,其中的元素用逗号 , 分隔。元组与列表相似,但元组是不可变的,即创建后不能修改、添加或删除其中的元素。
元组的创建
元组使用圆括号 () 来表示,其中的元素用逗号 , 分隔。
# 创建一个空元组
my_tuple = ()
# 创建一个包含整数元素的元组
my_tuple = (1, 2, 3, 4, 5)
# 创建一个包含字符串元素的元组
my_tuple = ('apple', 'banana', 'cherry')
# 元组中的元素可以是不同类型的
mixed_tuple = (1, 'apple', True, 3.14)
访问元组元素
元组中的元素可以通过索引来访问,索引从 0 开始。
my_tuple = ('apple', 'banana', 'cherry')
print(my_tuple[0]) # 输出:'apple'
print(my_tuple[1]) # 输出:'banana'
print(my_tuple[2]) # 输出:'cherry'
元组的切片
可以使用切片操作从元组中获取子元组。
my_tuple = (1, 2, 3, 4, 5)
# 获取索引 1 到 3 的子元组(不包括索引 3)
sub_tuple = my_tuple[1:3]
print(sub_tuple) # 输出:(2, 3)
元组的不可变性
元组是不可变的,一旦创建后,就不能修改其中的元素。
my_tuple = ('apple', 'banana', 'cherry')
# 尝试修改元组中的元素会引发错误
my_tuple[1] = 'orange' # TypeError: 'tuple' object does not support item assignment
7.3 字符串(字符串对象不支持修改)
在Python中,字符串是一种表示文本数据的数据类型,它是一系列Unicode字符的有序序列。字符串可以由单引号(')、双引号(")或三引号(''' 或 """)来表示。
字符串的创建
可以使用单引号、双引号或三引号来创建字符串。
# 使用单引号创建字符串
single_quoted_string = 'Hello, world!'
# 使用双引号创建字符串
double_quoted_string = "Hello, world!"
# 使用三引号创建多行字符串
multi_line_string = '''This is a
multi-line
string.'''
字符串的访问
字符串中的每个字符都有一个索引,索引从0开始。
my_string = "Hello, world!"
print(my_string[0]) # 输出:H
print(my_string[7]) # 输出:w
字符串的切片
可以使用切片操作从字符串中获取子字符串。
my_string = "Hello, world!"
print(my_string[1:5]) # 输出:ello
字符串的拼接
可以使用 + 运算符来拼接字符串。
string1 = "Hello, "
string2 = "world!"
combined_string = string1 + string2
print(combined_string) # 输出:Hello, world!
字符串的常用方法
Python自带方法:
字符串长度: 使用 len() 方法可以获取字符串的长度。
字符串内部函数:
字符串大小写转换:
upper(): 将字符串中的所有字符转换为大写。lower(): 将字符串中的所有字符转换为小写。capitalize(): 将字符串的第一个字符转换为大写,其他字符转换为小写。
my_string = "Hello, World!"
print(my_string.upper()) # 输出:HELLO, WORLD!
print(my_string.lower()) # 输出:hello, world!
print(my_string.capitalize()) # 输出:Hello, world!
字符串查找和替换:
find(substring): 查找子字符串在原字符串中的位置,如果找到返回索引值,否则返回 -1。replace(old, new): 将字符串中的指定子字符串替换为新的子字符串。
my_string = "Hello, world!"
print(my_string.find("world")) # 输出:7
print(my_string.find("Python")) # 输出:-1
new_string = my_string.replace("world", "Python")
print(new_string) # 输出:Hello, Python!
字符串分割和连接:
split(delimiter): 将字符串根据指定的分隔符拆分成多个子字符串,并返回一个列表。join(iterable): 将可迭代对象中的字符串元素连接成一个字符串,以原字符串为连接符。
my_string = "apple,banana,orange"
split_string = my_string.split(",")
print(split_string) # 输出:['apple', 'banana', 'orange']
my_list = ['apple', 'banana', 'orange']
joined_string = ",".join(my_list)
print(joined_string) # 输出:apple,banana,orange
字符串去除空白:
strip(): 去除字符串两端的空白字符。lstrip(): 去除字符串左端的空白字符。rstrip(): 去除字符串右端的空白字符。
my_string = " Hello, world! "
print(my_string.strip()) # 输出:Hello, world!
print(my_string.lstrip()) # 输出:Hello, world!
print(my_string.rstrip()) # 输出: Hello, world!
字符串的格式化
可以使用字符串的格式化方法来创建具有动态内容的字符串。
name = "Alice"
age = 30
formatted_string = f"My name is {name} and I am {age} years old."
print(formatted_string) # 输出:My name is Alice and I am 30 years old.
使用 in 检查成员关系
in运算符用于检查某个值是否存在于序列中,如果存在,则返回True,否则返回False。
my_string = "Hello, world!"
print('H' in my_string) # 输出:True
print('X' in my_string) # 输出:False
使用 not in 检查非成员关系
not in运算符用于检查某个值是否不存在于序列中,如果不存在,则返回True,否则返回False。
my_string = "Hello, world!"
print('H' not in my_string) # 输出:False
print('X' not in my_string) # 输出:True
字符串转义字符
\n:换行符,将光标移动到下一行开头。\t:制表符,用于在文本中插入水平制表符。- \ : 续行符

\\:反斜杠,用于插入一个反斜杠字符。\':单引号,用于插入一个单引号字符。\":双引号,用于插入一个双引号字符。
print("Hello\nWorld!")
# 输出:
# Hello
# World!
print("This is a\ttabbed\ttext.")
# 输出:This is a tabbed text.
print("C:\\path\\to\\file.txt")
# 输出:C:\path\to\file.txt
print('He\'s a good boy.')
# 输出:He's a good boy.
print("She said, \"Hello!\"")
# 输出:She said, "Hello!"
字符串强制转换为List
s = "hello world"
print(list(s)) #['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']一行输入两个整数
s = input().split()
a , b = list( map(int , s) )
print( a, b ) #1 2一行输入多个整数
s = input().split()
a = list(map(int , s))
print(a)修改字符串的常用方法
使用切片替换部分内容:
s = "hello, world"
s = s[:5] + "Python" # 将 "hello" 替换为 "Python"
print(s) # 输出: "Python, world"
使用字符串的 replace() 方法:
s = "hello, world"
s = s.replace("hello", "Python")
print(s) # 输出: "Python, world"
使用列表操作,然后使用字符串的 join() 方法
s = "hello, world"
s_list = list(s)
s_list[0] = 'P' # 替换第一个字符
s = ''.join(s_list)
print(s) # 输出: "Pello, world"
使用字符串的格式化方法:
s = "hello, world"
s = "{} {}".format("Python", s.split(" ")[1])
print(s) # 输出: "Python, world"
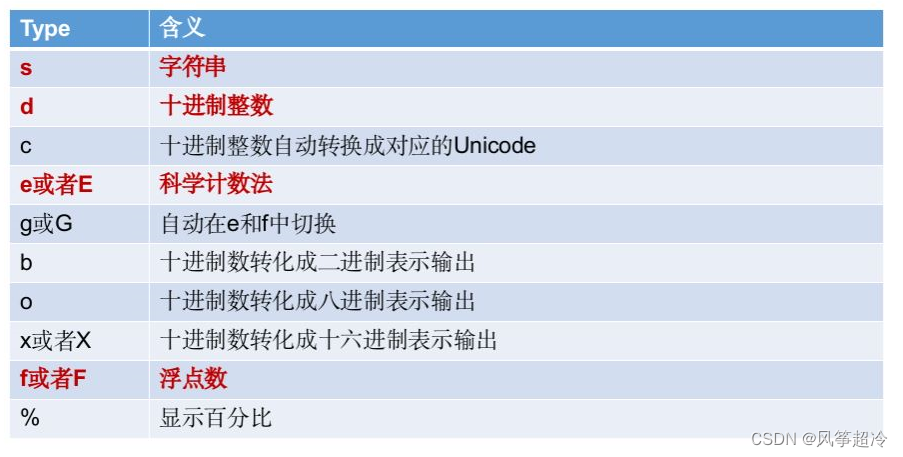
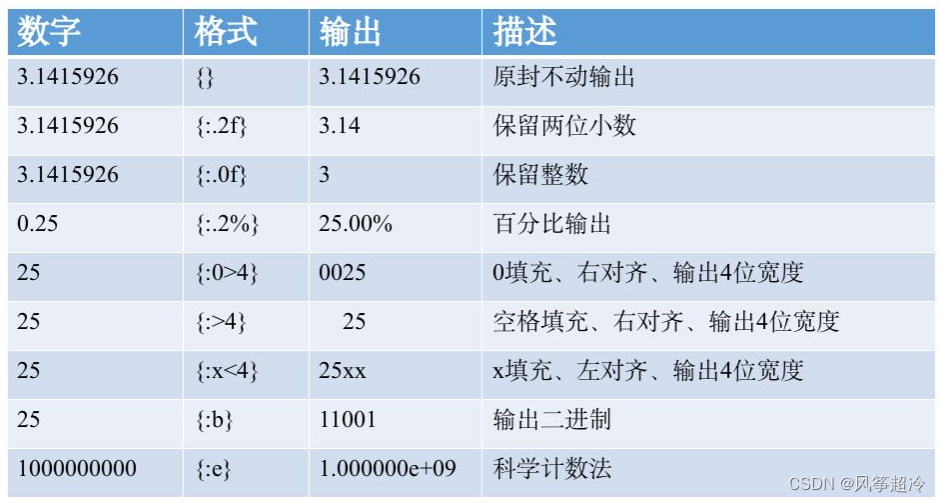
format 格式化
formatted_string = "Some text with {} and {}".format(value1, value2)
formatted_string = "Some text with {1} and {0}".format(value1, value2)
pi = 3.141592653589793
formatted_pi = "Value of pi: {:.2f}".format(pi) # 控制小数点后保留两位
print(formatted_pi) # Output: Value of pi: 3.14

'''python实现下列需求开放式编程:对于给定的一.大段不规范的英文文本,对其进行排版:
单词和单词之间有一个空格
句子中的符号和前一个单词之间没有空格
句子之间一一个空格分隔
句子首字母大写,其他字母小写
按照换行符划分段落,输出时每段空两个空格
输出时每行80个字符,对于单个单词-行超过80个单词,直接下一-行输出该单词
'''
def format_text(text):
formatted_text = ""
paragraphs = text.split('\n\n') # 根据换行符划分段落
for paragraph in paragraphs:
lines = []
words = paragraph.split()
line_length = 0
line = ""
for word in words:
if line_length + len(word) + 1 <= 80: # 考虑空格的长度
if line_length == 0:
line += word.capitalize()
else:
line += " " + word.lower()
line_length += len(word) + 1
else:
lines.append(line)
line = word.capitalize()
line_length = len(word)
lines.append(line)
formatted_paragraph = " ".join(lines) # 每段空两个空格
formatted_text += formatted_paragraph + "\n\n"
return formatted_text
# 示例文本
unformatted_text = """
this is a test. i am writing a python program to format text.
it's a simple program, but it should work well.
let's see how it goes.
"""
formatted_text = format_text(unformatted_text)
print(formatted_text)
7.4 字典
键: key, 值: value, 通过key来找value, key必须唯一, 因此同一个key只能对应着一个value
- Python中用{}表示字典,可以使用{}创建一个字典
- 字典中的key和value之间用冒号:分隔,元素之间用逗号,分隔。
- 字典的key只能为数字、字符串、元组,大多数情况使用字符串作为key
- 如果键重复,那么重复键对应的值后面会把前面的值覆盖掉,但是位
置还是原来的位置 - value的类型没有限制
#创建了一个空字典
a={}
print("type (a) = ", type (a) )
print("a = ", a)
#创建字典
a = {'a':123, 'b' :456, 0:789}
print("type (a) = ", type (a))
print("a = ", a)
'''
type (a) = <class 'dict'>
a = {}
type (a) = <class 'dict'>
a = {'a': 123, 'b': 456, 0: 789}
'''扩展: 不定长参数(位置参数和关键字参数)
def func(*args):
print(args)
func(1,2,3,4)def func( a, *args ):
print( args )
func( 1, 2, 3, 4 )def func( *args, a ):
print( args )
func( 1, 2, 3, a = 4 )def func( a, **args ): #参数以字典形式传输,双星号不定长放到关键字参数后
print( args )
func( a = 1, b = 2, c = 3, d = 4 )创建字典的六种方式
① 直接在空字典 {} 里面写键值对
a = {'name': 'Tom', 'age': 28}
print(a)
② 定义一个空字典,再往里面添加键值对
a = {} # a = dict()
a['name'] = 'Tom'
a['age'] = 28
print(a)
③ 把键作为关键字传入
a = dict(name="Tom", age=28)
print(a)
④ 可迭代对象方式来构造字典
a = dict([("name", "Tom"), ("age", 28)]) # 这里用元组/列表/集合都是可以的
print(a)
⑤ 通过 zip() 把对应元素打包成元组,类似于上一种方法
a = dict(zip(["name", "age"], ["Tom", 28]))
print(a)⑥ 利用类方法 fromkeys() 创建
d = my_dict( name = 'Tony', age = 28, height = 188 )
print( d )
dict(**kwarg) / dict(mapping) / dict(iterable)
用于创建一个字典并返回
print(dict(one=1, two=2, three=3)) # 传入关键字来构造字典
print(dict(zip(["one", "two", "three"], [1, 2, 3]))) #映射函数方式来构造字典
print(dict([("one", 1), ("two", 2), ("three", 3)])) # 可迭代对象方式来构造字典def my_dict( **kwargs ):
return kwargs
d = my_dict( name = 'Tony', age = 28, height = 188 )
print( d )
d = dict( name = 'Tony', age = 28, height = 188 )
print( d )
zip(*iterables)
- 返回一个元组的迭代器,其中的第 i 个元组包含来自每个可迭代对象
- 的第 i 个元素
- 当所输入可迭代对象中最短的一个被耗尽时,迭代器将停止迭代
- 不带参数时,它将返回一个空迭代器
- 当只有一个可迭代对象参数时,它将返回一个单元组的迭代器
result1 = zip( "abcd", "efgh" )
print(list( result1 ))
result2 = zip( "abcd", "efg" )
print(list( result2 ))
result3 = zip( )
print(list( result3 ))
result4 = zip( "abcd" )
print(list( result4 ))字典的对象方法
7.5 集合
Python中的集合和数学中的集合概念一样, 存储不重复的元素。
集合中的元素都是唯一的,互不相同。
集合中只能存储不可变的数据:数字、字符串、元组。
Python用{}表示集合,其中的元素用逗号分隔。
Python集合可以改变,不是序列,是无序的。
创建集合的方式:
- {元素1,元素2,元素3...}:把大括号中的所有元素构造成一个集合,如果有重复元素,只保留1个
- {}: 这是空字典,不是空集合
- set(x): 把x转换成集合,x一般为列表、元组等
- set(): 空集
set([iterable])
●返回一个新的set对象,其元素来自于iterable, 如果未指定
iterable,则将返回空集合
frozenset([iterable])
●返回一个新的frozenset对象,即不可变的集合,其元素来自于
iterable,如果未指定参数,则返回冻结的空集合
●作用: set中的元素必须是不可变类型的,而frozenset是可以作为set元素的
利用集合特性进行 去重 和 关系测试
#把一个列表变成集合,就会自动去掉重复的元素
li=[1, 2, 5, 7, 7, 4, 5]
a = set( li )
print(a)
#测试多组集合数据之间的交集、差集、并集等关系
a =set("abdefga")
b = set("abc")
c = set("aef")
print(c <= a)
#判断c是否是a的子集
print(a - b)
#返回a和b的差集
print(a| b)
#返回a和b的并集
print(a & b)
#返回a和b的交集
print(a ^ b)
#返回a和b中不同时存在的元素(对称差)
print(a | b| c)
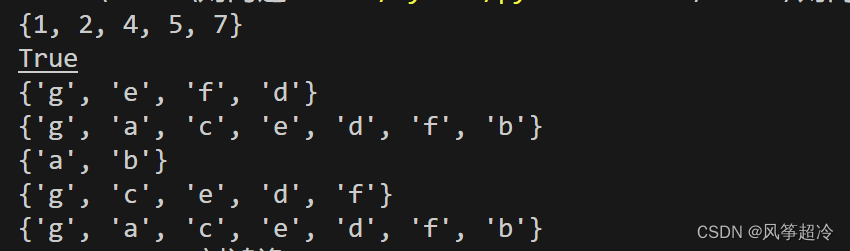
集合对象的方法 set frozenset对象都可用
isdisjoint(other)
●other: Iterable
●如果集合中没有与other共有的元素则返回True(注意变量类型)
str1 = "145"
list1 = [1, 4]
dic1 = {1:"1"}
set1 = {"1", 2, 3}
print(set1. isdisjoint(str1) )
#False
print(set1. isdisjoint(list1))
#True
print(set1. isdisjoint(dic1) )
#True
fset = frozenset(["1", 2, 3])
print(fset. isdisjoint(str1))
print(fset. isdisjoint(list1) )
print(fset. isdisjoint(dic1) ) issubset(other)
issubset(other)
●other: Iterable
●如果集合中的每个元素都在other之中,则返回True .
●对应的运算符版本set <= other要求参数为集合
str1 = "132"
list1 = [1, 4, "1", "2"]
dic1 = {1:"1", 2:"2"}
set1 = {"1", "2"}
print(set1. issubset(str1) )
#True
print(set1. issubset(list1) )
#True
print(set1. issubset(dic1) )
# False
fset = frozenset(["1", "2"])
print(fset. issubset(str1) )
print(fset. issubset(list1) )
print(fset. issubset(dic1) )
 issuperset(other)
issuperset(other)
●other: Iterable
●如果other中的每个元素都在集合之中,则返回True
●对应的运算符版本set >= other要求参数为集合
str1 = "12"
list1 = [1, "2"]
dic1 = {1:"1", 2:"2"}
set1 = {"1", "2", 1, 3}
print( set1.issuperset(str1) )
#True
print(set1. issuperset(list1) )
#True
print(set1. issuperset(dic1) )
# False
fset = frozenset(["1", "2", 1, 3])
print(fset. issuperset(str1) )
print(fset. issuperset(list1))
print(fset. issuperset(dic1) )
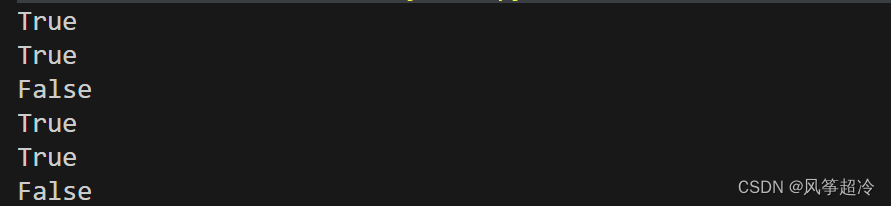 union(*others)
union(*others)
●others: Iterable
●返回一个新集合,其中包含来自原集合以及others指定的所有集合中的元素(即并集)
●对应的运算符版本set|other|...要求参数为集合
s1 = {'a', 'c', 'f', 1, 2, 3}
print(s1.union('acf123', {4:5, 6:7})) intersection(*others)
●others: Iterable
●返回一个新集合,其中包含原集合以及others指定的所有集合中共有的元素(即交集)
●对应的运算符版本set & other & ...要求参数为集合
s1 = {'a', 'c', 'f', 1, 2, 3}
print(s1.intersection('acf123')) difference(*others)
●others: Iterable
●返回一个新集合,其中包含原集合中在others指定的其他集合中不存在的元素(即差集)
●对应的运算符版本set - other- ... 要求参数为集合
str1 = "12"
list1 = [1, "2"]
dic1 = {"1":1, "2":2}
set1 ={"1", "2", 1, 3}
print(set1.difference(str1, list1, dic1) )
fset = frozenset(["1", "2", 1, 3] )
print( fset. difference(str1, list1, dic1))
symmetric_ difference(other)
●other: Iterable
●返回一个新集合,其中的元素或属于原集合或属于other指定的其他集合,但不能同时属于两者(即对称差)
●对应的运算符版本set^ other要求参数为集合

集合遍历操作:
- 与遍历list一样, for x in a,其中a是set, x是循环变量
- s.clear():清空集合
- X in S:
- 判断是否存在
- len(s):集合元素个数
s = {1,2 ,3,4}
for x in s:
print (x)
print ( sum(s), max(s) , min(s) )集合对象的方法 仅set 对象都可用
set.update(*others)
●others: Iterable
●更新集合,添加来自others中的所有元素
set.intersection_ _update(*others)
●others: Iterable
●更新集合,只保留其中在所有others中也存在的元素.
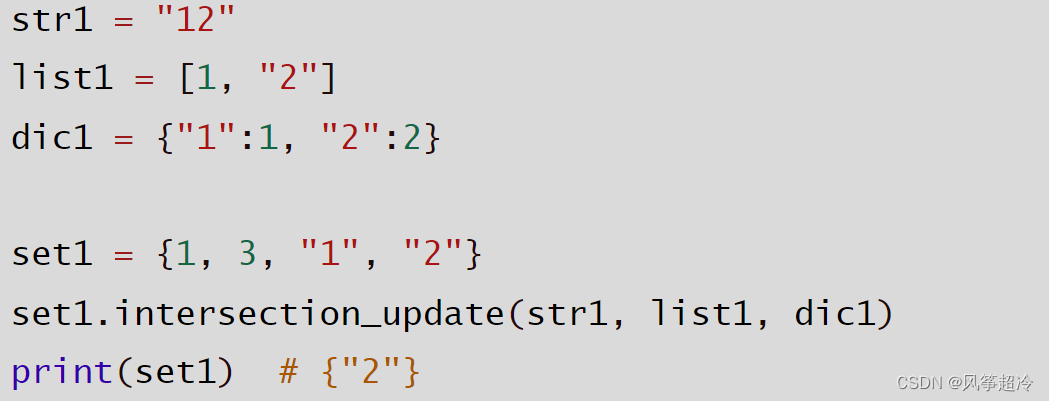
set.difference_ update(*others)
●others: Iterable
●更新集合,移除其中也存在于任意一个others中的元素

set.symmetric_ difference_ update(other)
●other: Iterable
●更新集合,只保留存在于一-方而非共同存在的元素

set. add(elem)
●将元素elem添加到集合中。如果元素已经存在,则没有影响

set.remove(elem)
●从集合中移除元素elem。 如果elem不存在于集合中则会引发KeyError

set.discard(elem)
●从集合中移除元素elem。如果elem不存在于集合中则不做任何操作

set.pop()
●从集合中移除并返回任意一个元素。如果集合为空则会引发KeyError set.clear()
set.clear()
●从集合中移除所有元素

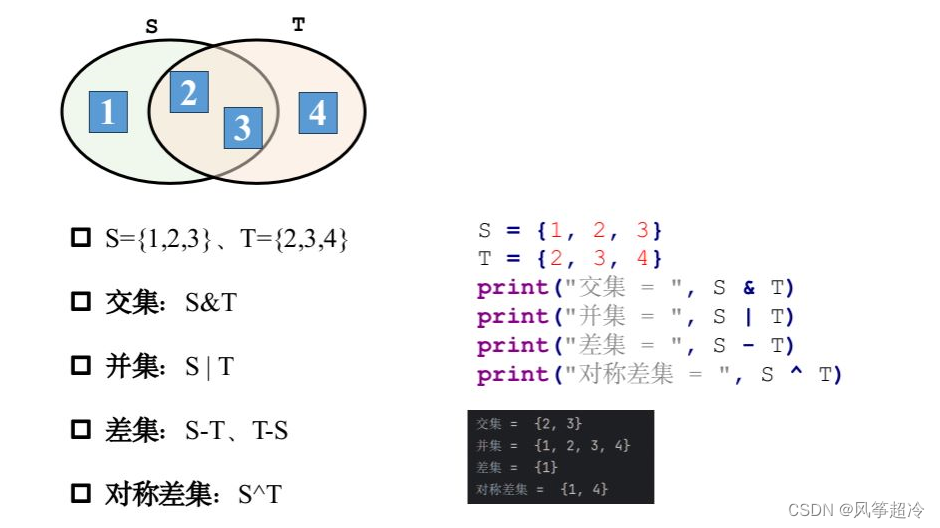
s = {1, 2, 3}
t = {2, 3, 4}
print ( "交集:", s.intersection(t) )
print ( "并集:", s.union(t) )
print ("差集:", s.difference(t) )
print ("对称集:", s.symmetric_difference(t) )输入若干数字,将所有元素去重后输出数字:
s = list (map(int, input().split()))
a = set (s)
print (a)'''
维护-一个数据结构管理表格,初始-个n行m列的表格,元素均为
空,需要完成若干次操作:
set x y value:将表格第x行第y列设置为value
findxy:查询第x行第y列对应的值
del x y:删除第x行第y列的值
Many value:查找value 是否在表格中,如果在表格中则出现次
数为多少
'''