机器学习实践中,为防止模型出现过拟合问题,需要预先将数据划分为训练集和测试集,训练集用来建模,训练模型,测试集用来提前测试模型的实际预测能力,这期间就会出现不同的数据集划分和模型评价方法,且各有自己的优缺点。
数据集划分方法
随机划分
将数据集进行随机划分,每一次重新划分,训练集和测试集都会被随机确定,这种方法简便快捷,但是会出现数据集划分不均匀,或者训练集测试集数据分布差异过大,导致模型测试结果很差的问题,不能足够客观的去评价模型。
注:在实际应用中,可以通过设置随机种子random_state去保证每次随机划分的结果一样,便于不同模型的对比。
均匀划分
将整个数据集进行均匀划分,假设训练集占80%,测试集20%,共100个样本(按一定的数据分布有序排列),可以将原数据集索引0,5,10,15,20,25,30,…,90,95作为测试集,最终取得20个测试样本,其它索引的样本作为训练集。
时序划分
对于一些数据量较大,且跟时间关系比较大的数据,可以按时序划分,根据前n天的数据去预测后m天的数据,更能模拟一些实际业务中的场景。
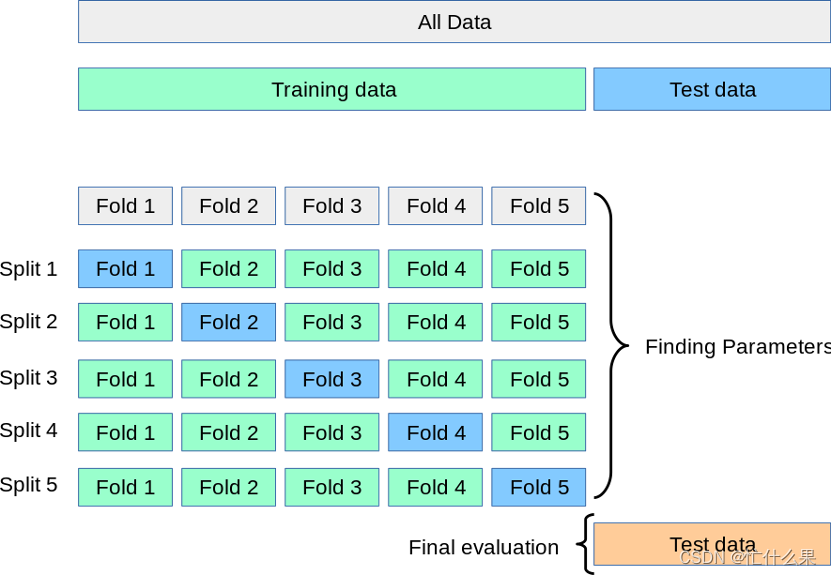
交叉验证
在实际应用中,测试集是作为最终对模型评估的数据集,完全不参与训练,但是建模者容易进入一个误区:训练出第一个模型A,拿测试集测试,测试结果不好,重新训练,训练出模型B,拿测试集测试,测试结果还是不好,继续重新训练,直到模型F在测试集上表现极佳,就认识模型F是一个预测精度和泛化能力都很强的模型,但是仔细想想,这种多次的尝试,为了使测试集精度达到最高,是不是相当于把测试集多多少少参与到了训练过程中去,强行凑到测试集精度很佳,结果上线后模型预测结果依旧很差,严重翻车。
为了解决这一问题,研究者引入了交叉验证的思想。交叉验证完全不考虑测试集,将上述训练集划分为建模集和验证集,建模集训练,验证集测试,直到最终测试出最好的模型,才去最终的测试集上进行测试。
交叉验证又分为K折交叉验证和留一交叉验证。
K折交叉验证是将训练集划分成K个大小相等的子数据集,遍历每个子数据集作为一次验证集,剩下的K-1个子数据集作为建模集,最终会得到K个子数据集的评估结果,求其均值作为最终精度结果,一般K取5或10。
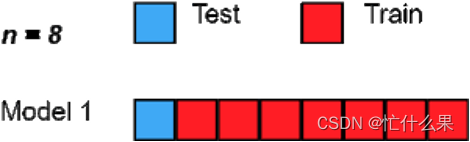
留一交叉验证和交叉验证的原理完全相同,只是每次只留一个样本作为测试集,训练样本如果有n个,那么会进行n次训练和验证,最终会得到n个评估结果。
自助法
考虑另一种情况,数据集样本量本身就很小,再按照比例划分训练集和测试集,会导致训练集和测试集的样本量更小,严重影响模型训练效果。自助法是对数据进行有放回采样,n次采样后,有些样本始终没被抽出过,那这些样本作为测试集即可。
参考文献
[1] 百面机器学习;
[2] 周志华.机器学习。