Paper name
EfficientFormer: Vision Transformers at MobileNet Speed
Paper Reading Note
URL: https://arxiv.org/pdf/2206.01191.pdf
TL;DR
- 本文目标是回答一个问题:transformer 是否可以在比 cnn 运行更快的时候同时精度更高?本文提出了 EfficientFormer 在修改一些耗时多的模块与进行网络结构搜索的情况下对前面的问题给了正向回复。
Introduction
背景
- Vision Transformer (ViT) 在计算机视觉的很多任务中取得了优异的表现,不过因为模型的大参数量和模型结构(attention mechanism) 导致其在运行时一般比轻量级卷积网络慢
- transformer 运行速度慢的原因分析:
- 参数量大
- 随着 token 长度增加计算复杂度呈二次增加
- norm layer 不可融合
- 缺乏编译器级别优化 (比如 CNN 中的 Winograd)
- 之前的一些 ViT 的轻量化方案主要是通过网络结构搜索或结合 MobileNet block 的混合结构设计,但是这样的测试时间依然难以达到实时应用需求
- 这就引起了一个问题:transformer 是否可以在比 cnn 运行更快的时候同时精度更高
本文方案
- 本位提出了一种 dimension-consistent 的纯 transformer 网络,另外通过 latency-driven slimming 来得到一系列最终模型 (面向运行时间优化,而不是 MAC 或参数量),起名为 EfficientFormer
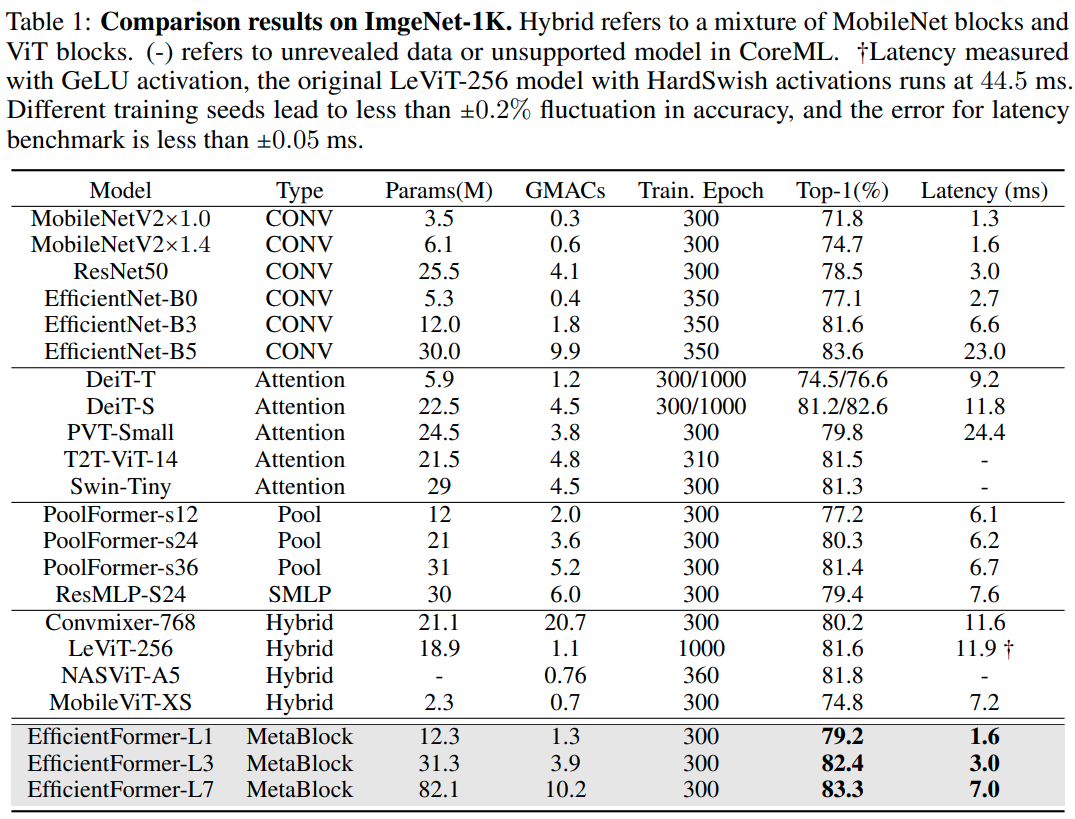
- EfficentFormer-L1 在 Imagenet-1K 上 top1 acc 为 79.2%,iphone12 上运行耗时为 1.6 ms (基于 CoreML 编译测试)
- 对比数据: MobileNetV2×1.4 (1.6 ms, 74.7% top1)
- EfficientFormer-L7 (7ms, 83.3% top1)
Dataset/Algorithm/Model/Experiment Detail
实现方式
模型运行延迟分析
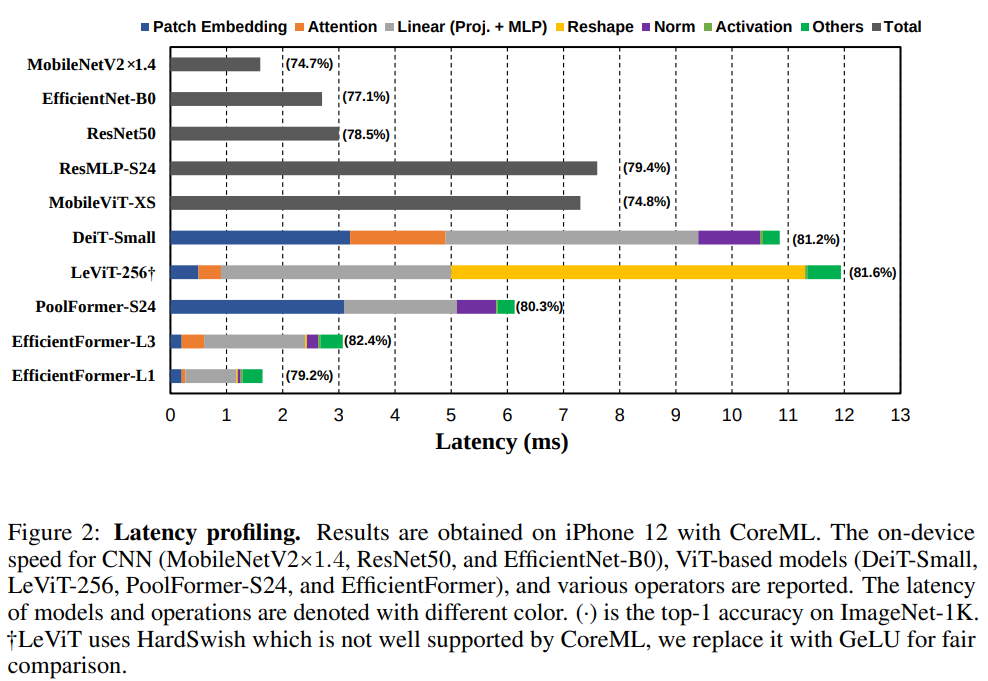
从以上测试结果得到的发现:
- 大 kernel 和 stride 的 patch embedding 是在移动设备上的速度瓶颈。由 DeiT-S、PoolFormer 与 LeViTate-256 的对比可以看出。慢的原因主要是 large-kernel 卷积在编译器级别没有类似 Winograd 之类的优化,这里替换成几个 3x3 卷积代替直连能加速
- 一致的特征维数对于 token mixer 的选择很重要。token mixer 的可选方案有传统的拥有去哪聚感受野的 MHSA mixer、更复杂的 shifted window attention、类似 pooling 的非参数化算子。其中 shifted window 算子目前大部分移动设备编译器都不支持,主要关心运算高效的 pooling token mixer 和精度更优的 MHSA。从上图对比 PoolFormer-s24 与 LeViT-256 可以看出 reshape 是瓶颈所在,保持特征维数一致非常重要。对比 DeiT-Small 和 LeViT-256,可以发现 MHSA 在特征维度保持一致的时候带来的延迟并不多。本文设计在 4D 特征和 3D MHSA 中尽量不用 reshape。
- conv-bn 的延迟比 LN(GN)-Linear 更优,掉点可接受。因为 BN 在测试阶段吸到 conv 中能降低测试延迟,从 DeiT-Small and PoolFormer-S24 等模型可以看出无法被吸的 norm 层在测试阶段占了总时长 10%-20%。本文中在 4D 特征中尽量使用 conv-bn 结构,3D 特征中使用 LN 为了获取更高精度。
- 非线性层的延迟取决于硬件和编译器。GeLU 在 iphone12 上几乎不比 relu 慢,但是 HardSwish 很慢(LeViT-256 在使用 HardSwish 时延迟为 44.5 ms,使用 GeLU 是 11.9 ms)。本文使用 GeLU 作为非线性层。
EfficientFormer 设计
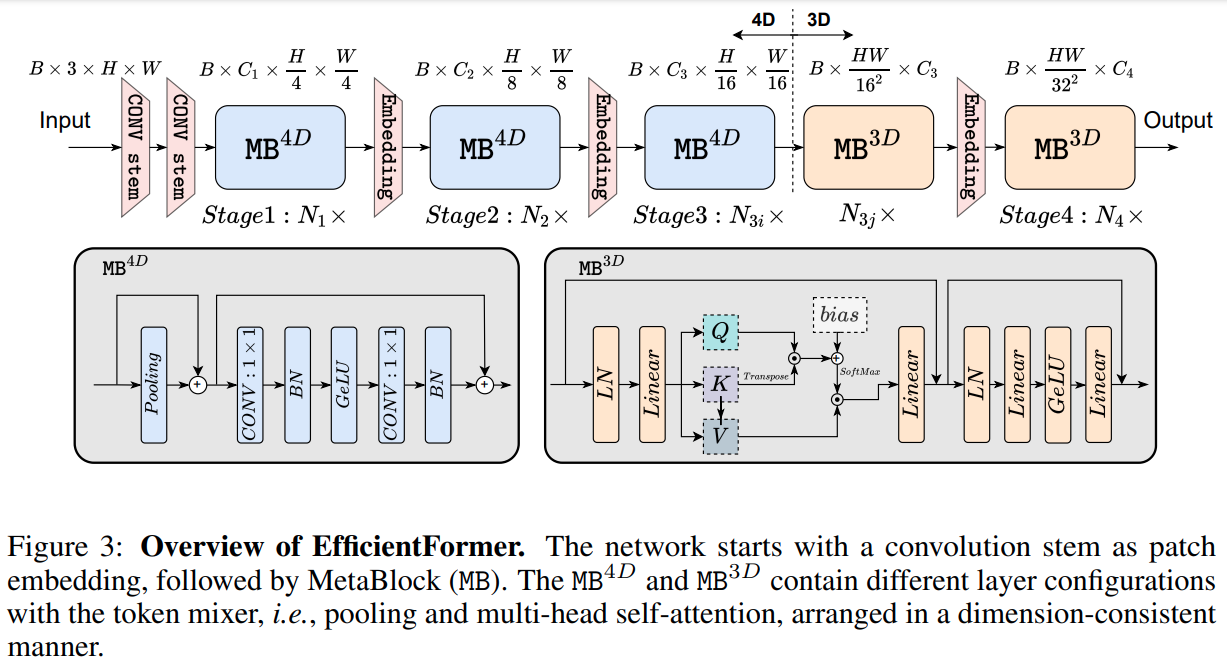
- 整个网络由一个 patch embeding 和一系列 meta transformer blocks (MB) 构成
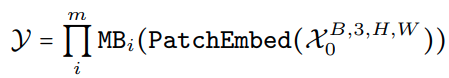
其中 MB 是 tokenmixer 后接 MLP 构成
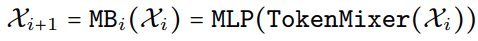
详细结构
- 4D partition 具体结构
- 2 个 stride=2 的 3x3 conv 进行 patch embedding

- pool 与 conv bn gelu 等算子用于提取 low level 特征
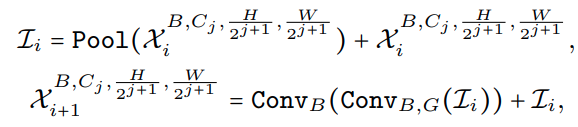
- 2 个 stride=2 的 3x3 conv 进行 patch embedding
- 3D partition 部分结构依然是和传统 ViT 结构一致
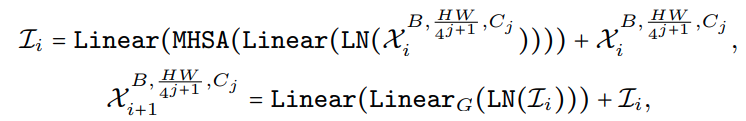

Latency Driven Slimming
- Design of Supernet,定义了每个 metapath 中可以选择的模块,其中 I 是 identity path,j 代表 j-th stage,i 代表 i-th block
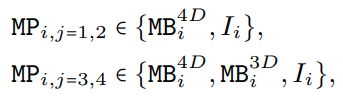
其中只在最后两个 stage 把 MB3D 放在搜索空间中,因为 MHSA 在 early stage 耗时明显,另外放置在后两个 stage 也符合 early stage 获取 low-level 特征,last stage 获取 long-term dependencies 的设计直觉。 - Searching Space:主要是每个 stage 的宽度 (Cj) 和每个 stage 的 block 数量(Nj),以及从最后的第 N 个 block 开始用 MB3D
- Searching Algorithm:提出了一种简单快速的基于梯度的搜索算法
- step1:使用 Gumble Softmax sampling 来训练 supernet,获取每个 metapath 中的每个 block 的重要性得分
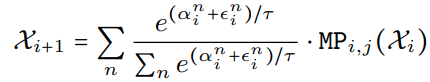
其中 α \alpha α 是代表选择一个 block 的概率,也即代表了该 block 的重要性; ϵ ∈ U ( 0 , 1 ) \epsilon \in U(0, 1) ϵ∈U(0,1) 确保探索; τ \tau τ 代表温度; n n n 代表 metapath 中的 block 类型; - step2:获取不同宽度的 MB4D 与 MB3D 在端上设备运行延迟的 LUT 表
- step3:基于 LUT 表对 step1 中训练的 supernet 进行 gradual slimming;基于以下定义计算每个 block 的重要性得分,然后对每个 stage 中的所有 block 重要求和计算得到 stage 的重要性得分
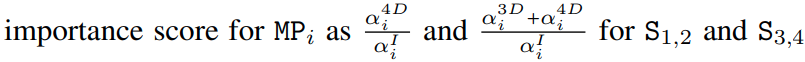
action space 如下:- action1:对于最不重要的 MP 使用 Identity path
- action2:移除第一个 MB3D
- action3:降低最不重要的 MP 的宽度
结合延迟 LUT 表计算以上 action 的延迟,然后评估每个 action 的精度降低程度,选择降低延迟大且掉点低的 action
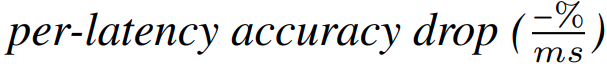
- step1:使用 Gumble Softmax sampling 来训练 supernet,获取每个 metapath 中的每个 block 的重要性得分
实验结果
- 实验配置:
- A100 + V100 cluster
- 测速: iphone12 (A14仿生芯片)
- CoreMLTools 部署模型
图像分类任务
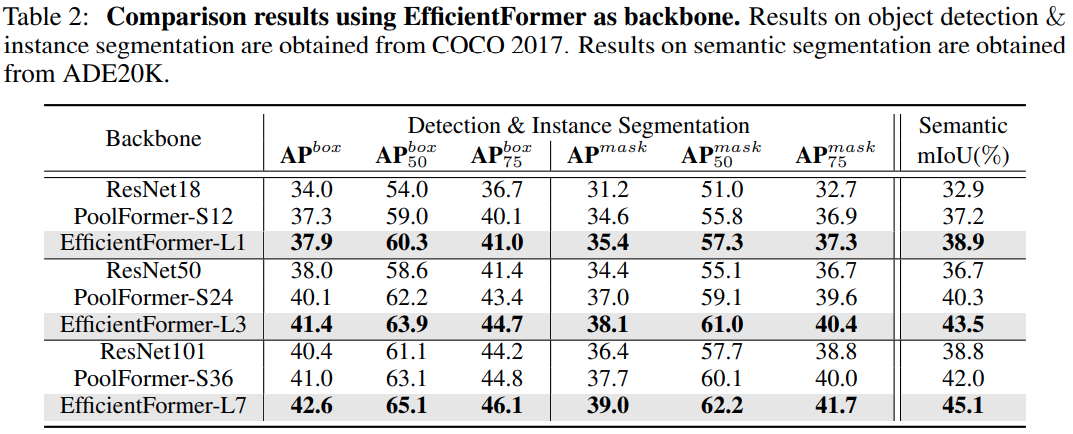
目标检测与实例分割任务
- 基于 mask-rcnn 进行验证
Thoughts
- 文章的整理思路非常简洁,从当前各种模型测速的 profile 结果出发,把耗时多的模块和设计改掉,然后加上网络结构搜索得到了性能更优的模型








![一篇彻底解决:Fatal error compiling: 无效的目标发行版: 11 -> [Help 1]](https://img-blog.csdnimg.cn/2290d48ccfae41d9b00ab797fc60e676.png)

![[ 数据结构 ] 二叉树详解--------前序、中序、后序、存储、线索化](https://img-blog.csdnimg.cn/img_convert/4a39faf22d6d244b3b2f1d5d256d5f45.png)