文章目录
- 1. 写在前面
- 2. 页面分析
- 3. 字符知识
- 4. 加密分析
【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
1. 写在前面
目前市面上有不少的网站使用了字体加密技术,像一些重要的数字内容使用字体加密很常见!从早期的静态固定字体文件随着不断的对抗演进到目前的动态字体文件,从PC端的应用到目前APP页面的普及使用
本期文字将以红色小番茄为例,咱们使用OCR识别技术来攻克一下字体加密
2. 页面分析
我们打开首先网站分析一下,可以看到响应的HTML内容中网页显示的本文内容,均是看起来晦涩难懂的字符,这就是字体加密。如下所示:
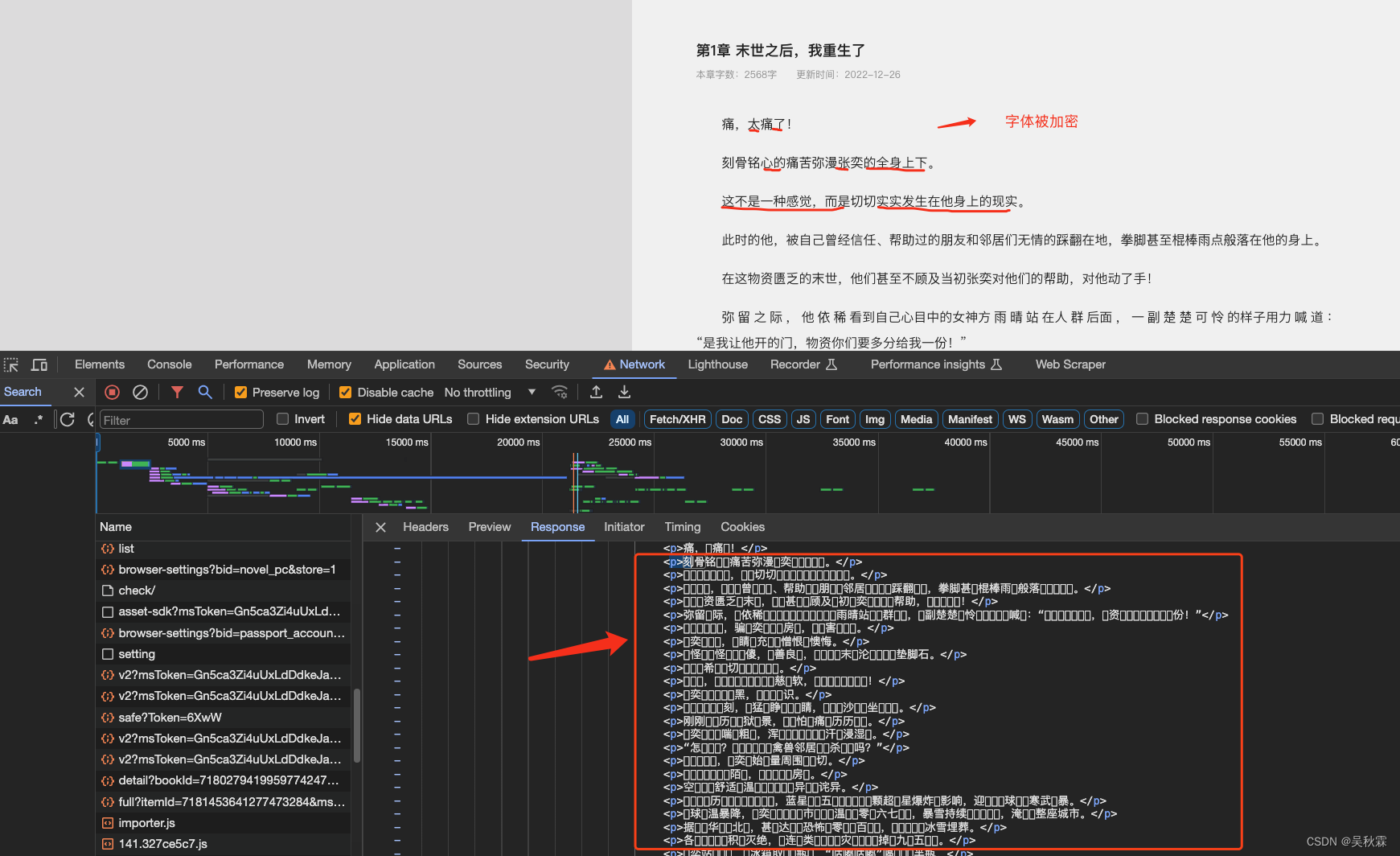
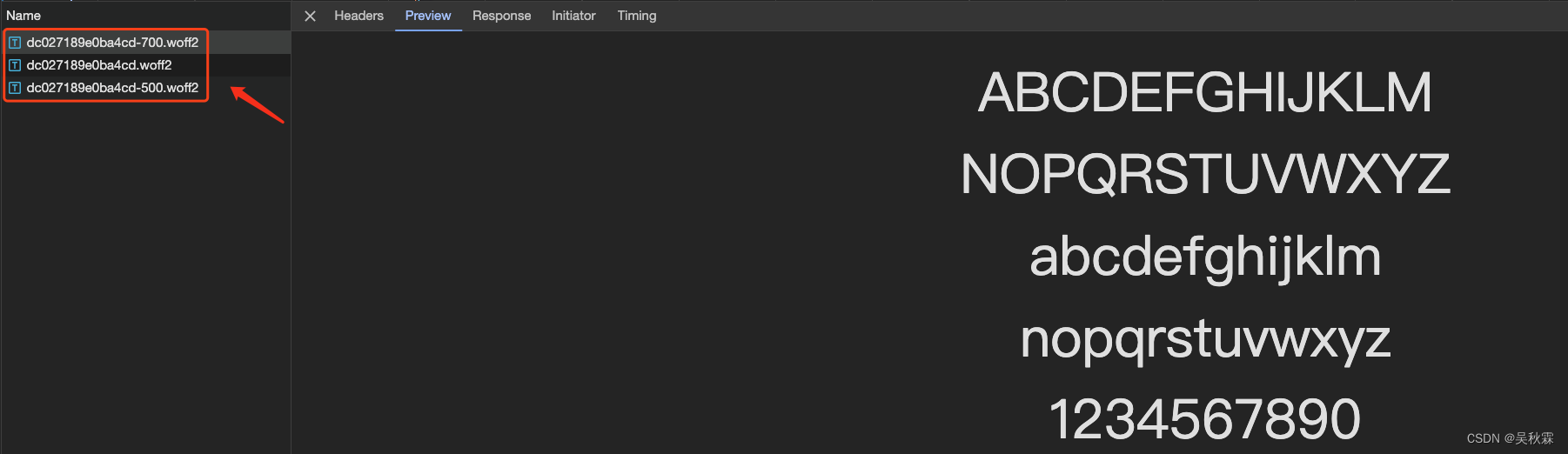
对于Web端的字体加密,我们可能都知道会有相应的woff类型的文件,存储着自定义的字体,它的作用则是让网站能够使用这些自定义的字体来显示加密的文本内容,如下所示:
3. 字符知识
在真正的内容分析开始之前,我们需要了解的一些知识点。这里不知道的朋友认真学,所有的中文汉字它都自己对应的一串数字码,也叫做Unicode码点,这是一种国际化的字符编码标准!为世界上几乎所有的字符集提供了一个唯一的标识
它们是一个非负整数,如下作者随机打印了几个示例:
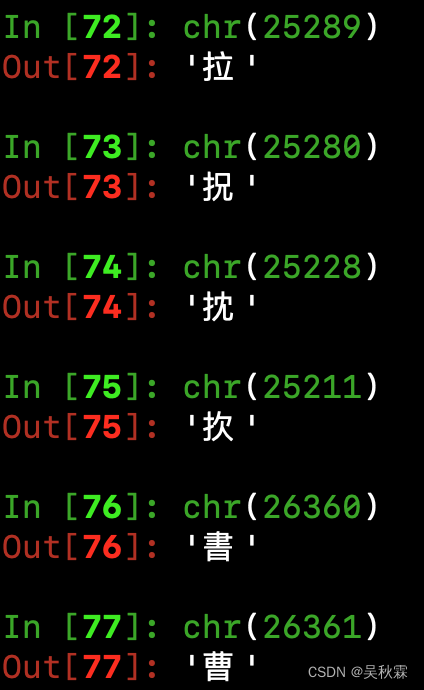
同理我们使用Python的内置函数ord可以查看字符的码点,chr函数则将码点转换为字符
4. 加密分析
接下来,这里将网页中加密的文本拿一小段下来简单的进行一个测试。使用ord打印一下所有字符的码点,可以看到一个特征!就是每一个被加密的字体对应的码点都是58…这样的,如下所示:
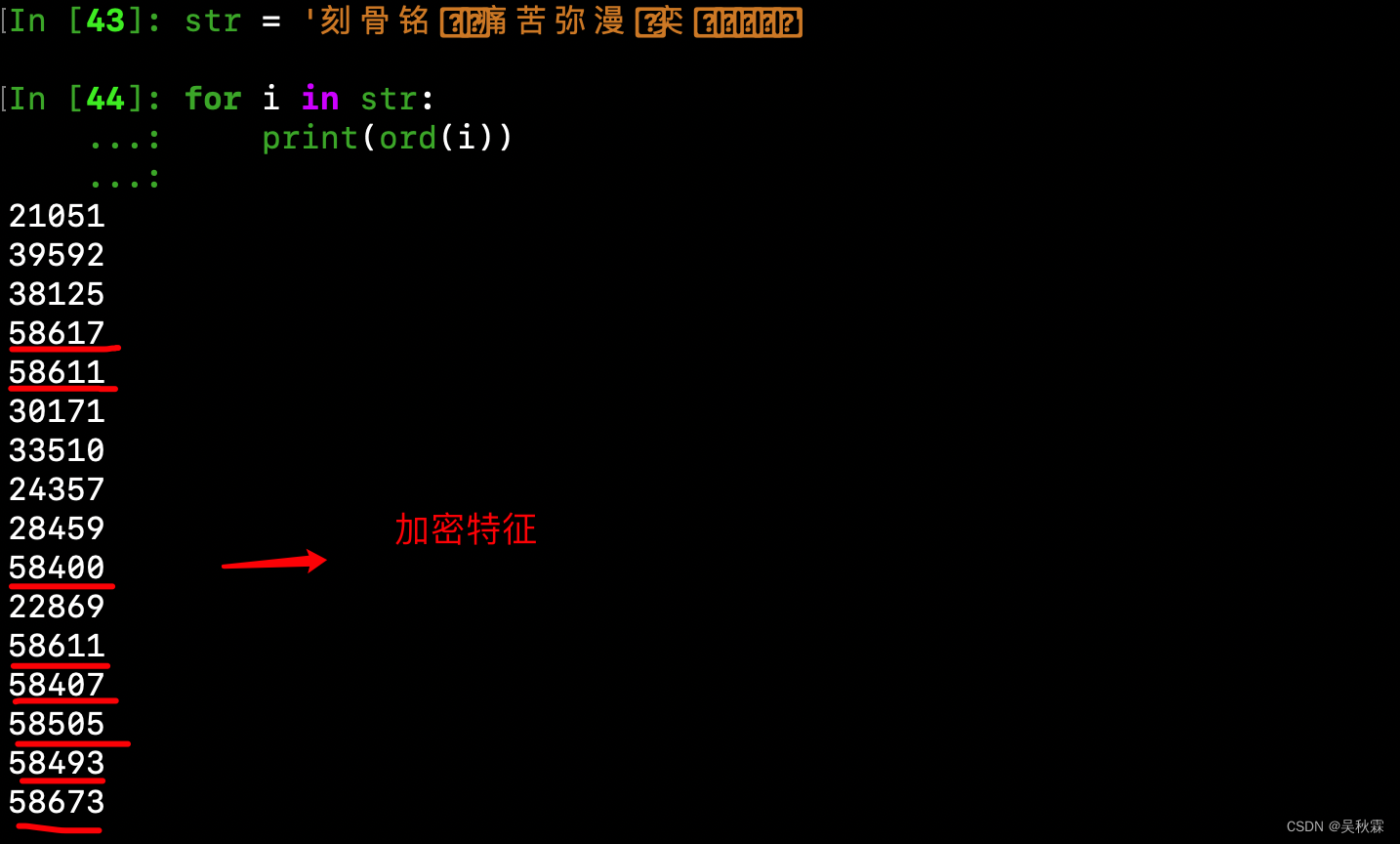
这个时候我们则需要将上面提到的woff文件下载下来,并使用fontTools库来加载字体并解析其结构,代码如下:
from fontTools.ttLib import TTFont
url = 'https://lf6-awef.bytetos.com/obj/awesome-font/c/dc027189e0ba4cd-700.woff2'
response = requests.get(url).content
with TTFont(BytesIO(response)) as font_parse:
u_d = font_parse.getBestCmap())
将会得到一个码点与字体编码对应的字典,如下所示:
{58344: 'gid58344', 58345: 'gid58345', 58346: 'gid58346', 58347: 'gid58347', 58348: 'gid58348', 58349: 'gid58349', 58350: 'gid58350', 58351: 'gid58351', 58352: 'gid58352'}
接下来,我们需要将gid编码对应的文字信息拿到,并建立字典。方便我们后续在对文本内容进行还原的时候调用,加密字体编码如何对应明文数据,代码实现如下:
unicode_reuslt = []
for key, _ in u_d.items():
unicode_reuslt.append(key)
char_list = [chr(ch_unicode) for ch_unicode in unicode_reuslt]
normal_dict, error_dict = font_to_img(char_list, ttf_name)
new_dict = {ord(key): value for key, value in normal_dict.items()}
print(new_dict)
在这里将使用到OCR识别技术,去还原加密字体的文字,这也是当前比较主流的一种方案,代码实现如下所示:
def font_to_img(code_list, filename, score=0.95):
normal_dict = {}
ocr = CnOcr()
for char_list in code_list:
char_code = char_list.encode().decode()
img_size = 1024
img = Image.new('img', (img_size, img_size), 255)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(filename, int(img_size * 0.7))
x, y = draw.textsize(char_code, font=font)
draw.text(((img_size - x) // 2, (img_size - y) // 2), char_code, font=font, fill=0)
img = img.convert("RGB")
word = ocr.ocr_for_single_line(np.array(img))
normal_dict[char_code] = word["text"]
return normal_dict
如上代码,这里简单解读一下!score参数表示OCR对该文本的识别得分,上面代码中没有使用的原因是有较小概率的丢失率!这个问题可以找一些更精准的模型来识别
再说说识别文字的流程与原理,上面使用Image来创建了一个白色的背景图像,然后使用ImageDraw在图像上绘制出字符,字体大小为图像大小的70%
然后将图像转换为RGB格式,最后使用Ocr对图像进行单行识别,获取识别结果以及识别得分,结果如下所示:

接下来,我门需要做的就是对加密的文本内容进行遍历,对每一个字符进行编码转换,得到对对应的码点!提取码点为58特征的加密字体,然后从上面字典获取对应的文字,如下所示:
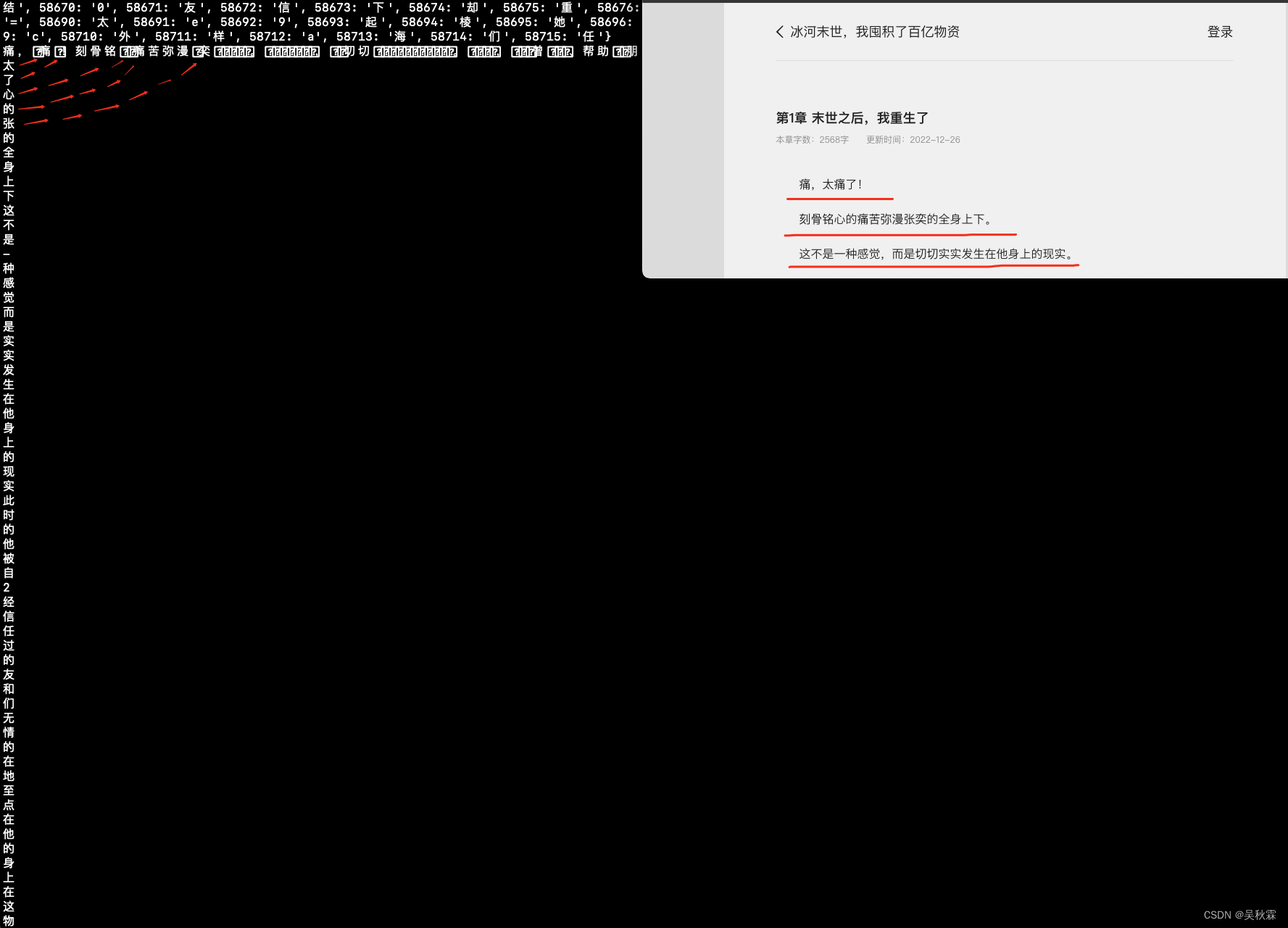
最终我们再通过上述的代码将加密打散还原出来的加密字体文字,拼接成完整的句子。这里的话我们将所有加密特征与非加密文字内容完成组装即可,最终内容还原如下所示:
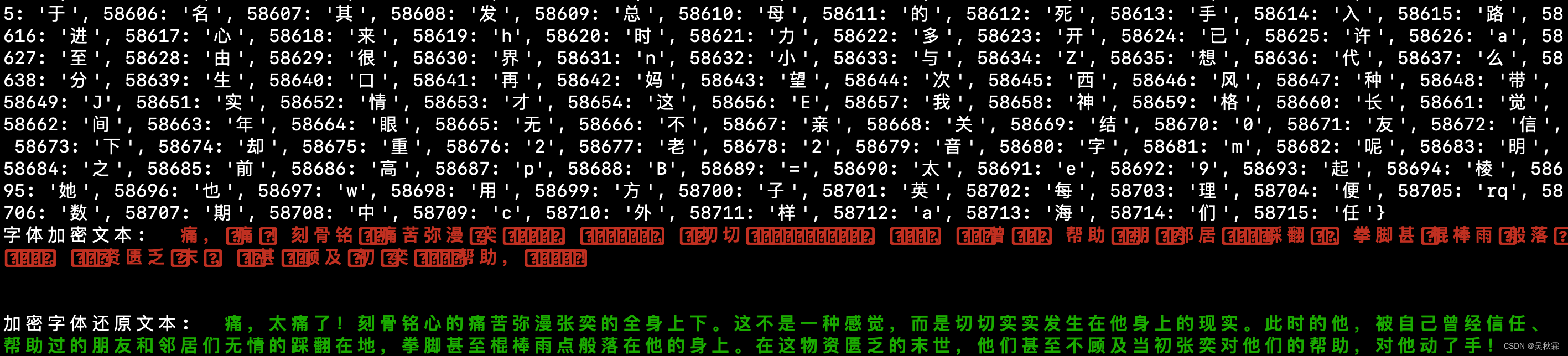
以上是加密字体文字内容还原的全部流程,如需要完整的Python代码进行测试或学习,可联系作者获取!
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章