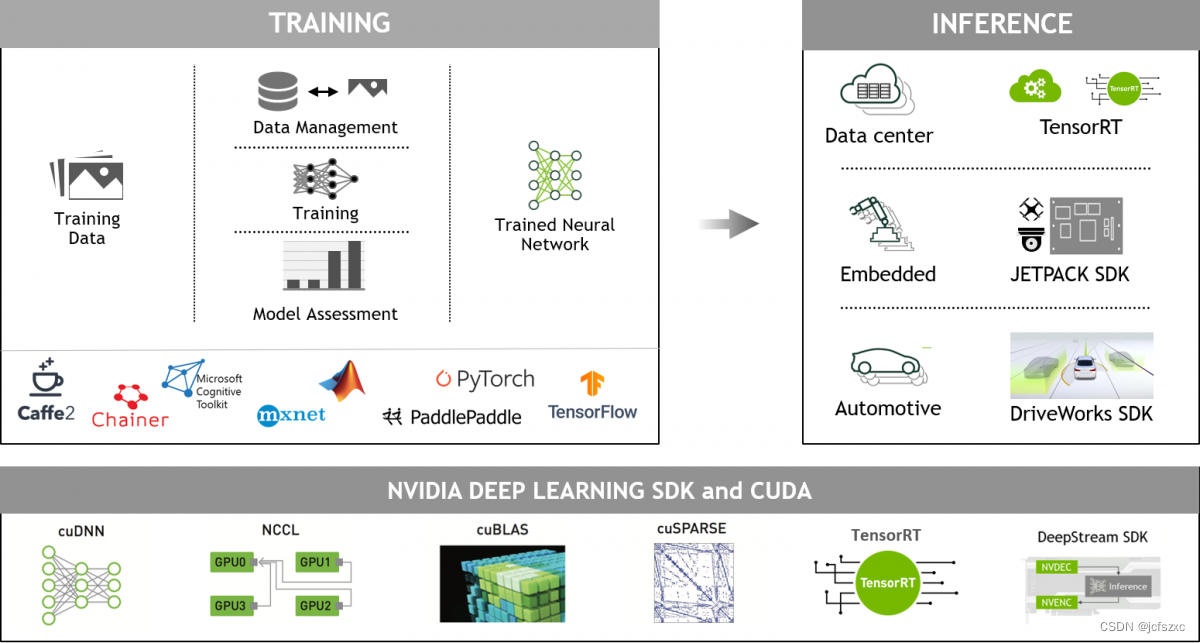
推荐系统(或推荐系统)是一类机器学习,它使用数据来帮助预测、缩小范围并在呈指数级增长的选项中找到人们正在寻找的内容。
【机器学习:Recommendation System】推荐系统
- 什么是推荐系统?
- 用例和应用
- 电子商务与零售:个性化营销
- 媒体与娱乐:个性化内容
- 个性化银行服务
- 推荐系统的好处
- 推荐器如何工作
- 用于推荐的矩阵分解
- 用于推荐的深度神经网络模型
- 神经协同过滤
- 用于协同过滤的变分自动编码器
- 情境序列学习
- 宽而深
- DLRM
- 为什么推荐系统使用 GPU 运行得更好
- 为什么选择 NVIDIA Merlin 推荐系统应用框架?
- NVIDIA GPU 加速的端到端数据科学和深度学习
- NVIDIA GPU 加速的深度学习框架
什么是推荐系统?
推荐系统是一种人工智能或人工智能算法,通常与机器学习相关,它使用大数据向消费者建议或推荐其他产品。这些可以基于各种标准,包括过去的购买、搜索历史、人口统计信息和其他因素。推荐系统非常有用,因为它们可以帮助用户发现他们自己可能找不到的产品和服务。
推荐系统经过训练,可以使用收集的有关人员和产品的交互数据来了解人员和产品的偏好、先前的决策以及特征。其中包括展示次数、点击次数、点赞次数和购买次数。由于推荐系统能够在高度个性化的水平上预测消费者的兴趣和愿望,因此受到内容和产品提供商的喜爱。他们可以吸引消费者购买他们感兴趣的任何产品或服务,从书籍、视频、健康课程到服装。

推荐系统的类型
虽然推荐算法和技术有大量,但大多数都属于以下几大类:协作过滤、内容过滤和上下文过滤。
协作过滤算法根据许多用户的偏好信息(这是协作部分)推荐项目(这是过滤部分)。这种方法利用用户偏好行为的相似性,考虑到用户和项目之间之前的交互,推荐算法学习预测未来的交互。这些推荐系统根据用户过去的行为构建模型,例如之前购买的商品或对这些商品的评分以及其他用户的类似决定。这个想法是,如果有些人过去做出了类似的决定和购买,比如选择电影,那么他们很有可能会同意未来的其他选择。例如,如果协同过滤推荐器知道您和另一个用户对电影有相似的品味,它可能会向您推荐一部它知道该其他用户已经喜欢的电影。

相比之下,内容过滤使用项目的属性或功能(这是内容部分)来推荐与用户偏好类似的其他项目。这种方法基于项目和用户特征的相似性,给定有关用户和他们与之互动的项目的信息(例如用户的年龄、餐厅菜肴的类别、电影的平均评论),对新产品的可能性进行建模相互作用。例如,如果内容过滤推荐器看到您喜欢电影《你收到邮件》和《西雅图不眠夜》,它可能会向您推荐另一部具有相同类型和/或演员阵容的电影,例如《乔大战火山》。

混合推荐系统结合了上述类型的优点,创建了更全面的推荐系统。
上下文过滤包括推荐过程中用户的上下文信息。 Netflix 在 NVIDIA GTC 上谈到了通过将推荐构建为上下文序列预测来提供更好的推荐。此方法使用一系列上下文用户操作以及当前上下文来预测下一个操作的概率。在 Netflix 的例子中,给每个用户一个序列——他们观看电影的国家、设备、日期和时间——他们训练了一个模型来预测接下来要看什么。

用例和应用
电子商务与零售:个性化营销
想象一下,用户已经购买了一条围巾。为什么不提供一顶配套的帽子,这样造型就会更完整呢?此功能通常通过基于人工智能的算法来实现,如亚马逊、沃尔玛、塔吉特等电子商务平台中的“完成外观”或“您可能也喜欢”部分。
平均而言,智能推荐系统可将网络产品的转化率提高 22.66%。
媒体与娱乐:个性化内容
基于人工智能的推荐引擎可以分析个人的购买行为并检测模式,这将有助于为他们提供最有可能符合其兴趣的内容建议。这就是谷歌和 Facebook 在推荐广告时积极应用的做法,或者是 Netflix 在推荐电影和电视节目时在幕后所做的事情。
个性化银行服务
银行业是数百万人以数字方式消费的大众市场产品,是推荐的首选。了解客户的详细财务状况和他们过去的偏好,再加上数千名类似用户的数据,是非常强大的。
推荐系统的好处
推荐系统是推动零售、娱乐、医疗保健、金融和其他行业个性化用户体验、与客户更深入互动以及强大决策支持工具的关键组件。在一些最大的商业平台上,推荐占收入的比例高达30%。推荐质量提高 1% 可以转化为数十亿美元的收入。
公司实施推荐系统的原因有多种,包括:
提高保留率。通过不断迎合用户和客户的偏好,企业更有可能留住他们作为忠实的订户或购物者。当客户感觉到品牌真正理解他们,而不仅仅是随机向他们提供信息时,他们更有可能保持忠诚度并继续在您的网站上购物。
增加销量。各种研究表明,由于准确的“您可能也喜欢”产品推荐,追加销售收入增加了 10-50%。通过推荐系统策略可以增加销售额,就像在购买确认中添加匹配的产品推荐一样简单;从废弃的电子购物车中收集信息;分享“客户现在购买什么”的信息;并分享其他买家的购买和评论。
帮助形成客户习惯和趋势。持续提供准确且相关的内容可以触发线索,从而养成强烈的习惯并影响客户的使用模式。
加快工作节奏。当为进一步研究所需的资源和其他材料提供量身定制的建议时,分析师和研究人员可以节省多达 80% 的时间。
提高购物车价值。拥有数万种待售商品的公司将面临为此类库存硬编码产品建议的挑战。通过使用各种过滤手段,这些电子商务巨头可以找到合适的时间来建议客户可能购买的新产品,无论是在他们的网站上还是通过电子邮件或其他方式。
推荐器如何工作
推荐模型如何提出推荐将取决于您拥有的数据类型。如果您只有有关过去发生的交互的数据,您可能会对协作过滤感兴趣。如果您有描述用户和他们与之交互的项目的数据(例如用户的年龄、餐厅美食的类别、电影的平均评论),您可以根据当前这些属性来建模新交互的可能性通过添加内容和上下文过滤。
用于推荐的矩阵分解
矩阵分解(MF)技术是许多流行算法的核心,包括词嵌入和主题建模,并且已成为基于协作过滤的推荐中的主导方法。 MF可用于计算用户评分或交互的相似度以提供推荐。在下面的简单用户项矩阵中,Ted 和 Carol 喜欢电影 B 和 C。Bob 喜欢电影 B。为了向 Bob 推荐一部电影,矩阵分解计算出喜欢 B 的用户也喜欢 C,因此 C 是 Bob 可能的推荐。

使用交替最小二乘 (ALS) 算法的矩阵分解将稀疏用户项目评分矩阵 u×i 近似为两个稠密矩阵(大小为 u × f 和 f × i 的用户和项目因子矩阵)的乘积(其中 u 是用户数量,i 项目数量,f 潜在特征数量)。因子矩阵表示算法试图发现的潜在或隐藏的特征。一个矩阵试图描述每个用户的潜在或隐藏特征,一个矩阵试图描述每部电影的潜在属性。对于每个用户和每个项目,ALS 算法迭代地学习代表用户或项目的 (f) 数字“因子”。在每次迭代中,该算法交替地固定一个因子矩阵并优化另一个因子矩阵,并且该过程一直持续到收敛。

CuMF 是一个基于 NVIDIA® CUDA® 的矩阵分解库,可优化交替最小二乘 (ALS) 方法来求解超大规模 MF。 CuMF 使用一组技术来最大限度地提高单个和多个 GPU 的性能。这些技术包括利用 GPU 内存层次结构智能访问稀疏数据、将数据并行性与模型并行性结合使用以最大限度地减少 GPU 之间的通信开销,以及新颖的拓扑感知并行缩减方案。
用于推荐的深度神经网络模型
人工神经网络 (ANN) 有不同的变体,例如:
信息仅从一层向前馈送到下一层的 ANN 称为前馈神经网络。多层感知器 (MLP) 是一种前馈 ANN,由至少三层节点组成:输入层、隐藏层和输出层。 MLP是灵活的网络,可以应用于多种场景。
卷积神经网络是识别对象的图像处理程序。
循环神经网络是解析语言模式和排序数据的数学引擎。
深度学习 (DL) 推荐模型建立在现有技术(例如分解)的基础上,对变量和嵌入之间的交互进行建模,以处理分类变量。嵌入是表示实体特征的数字的学习向量,以便相似的实体(用户或项目)在向量空间中具有相似的距离。例如,协作过滤的深度学习方法根据用户和项目与神经网络的交互来学习用户和项目嵌入(潜在特征向量)。
深度学习技术还利用庞大且快速增长的新型网络架构和优化算法来训练大量数据,利用深度学习的力量进行特征提取,并构建更具表现力的模型。
当前基于 DL 的推荐系统模型:DLRM、Wide and Deep (W&D)、神经协同过滤 (NCF)、变分自动编码器 (VAE) 和 BERT(用于 NLP)构成 NVIDIA GPU 加速的 DL 模型组合的一部分,涵盖推荐系统之外的许多不同领域的广泛网络架构和应用,包括图像、文本和语音分析。这些模型专为使用 TensorFlow 和 PyTorch 进行训练而设计和优化。
神经协同过滤
神经协同过滤 (NCF) 模型是一种神经网络,可提供基于用户和项目交互的协同过滤。该模型从非线性角度处理矩阵分解。 NCF TensorFlow 将一系列(用户 ID、项目 ID)对作为输入,然后将它们分别输入矩阵分解步骤(其中嵌入相乘)和多层感知器 (MLP) 网络。
然后,矩阵分解和 MLP 网络的输出被组合并馈送到单个密集层,该密集层预测输入用户是否可能与输入项交互。

用于协同过滤的变分自动编码器
自动编码器神经网络利用隐藏层中获得的表示在输出层重建输入层。用于协同过滤的自动编码器学习用户-项目矩阵的非线性表示,并通过确定缺失值来重建它。
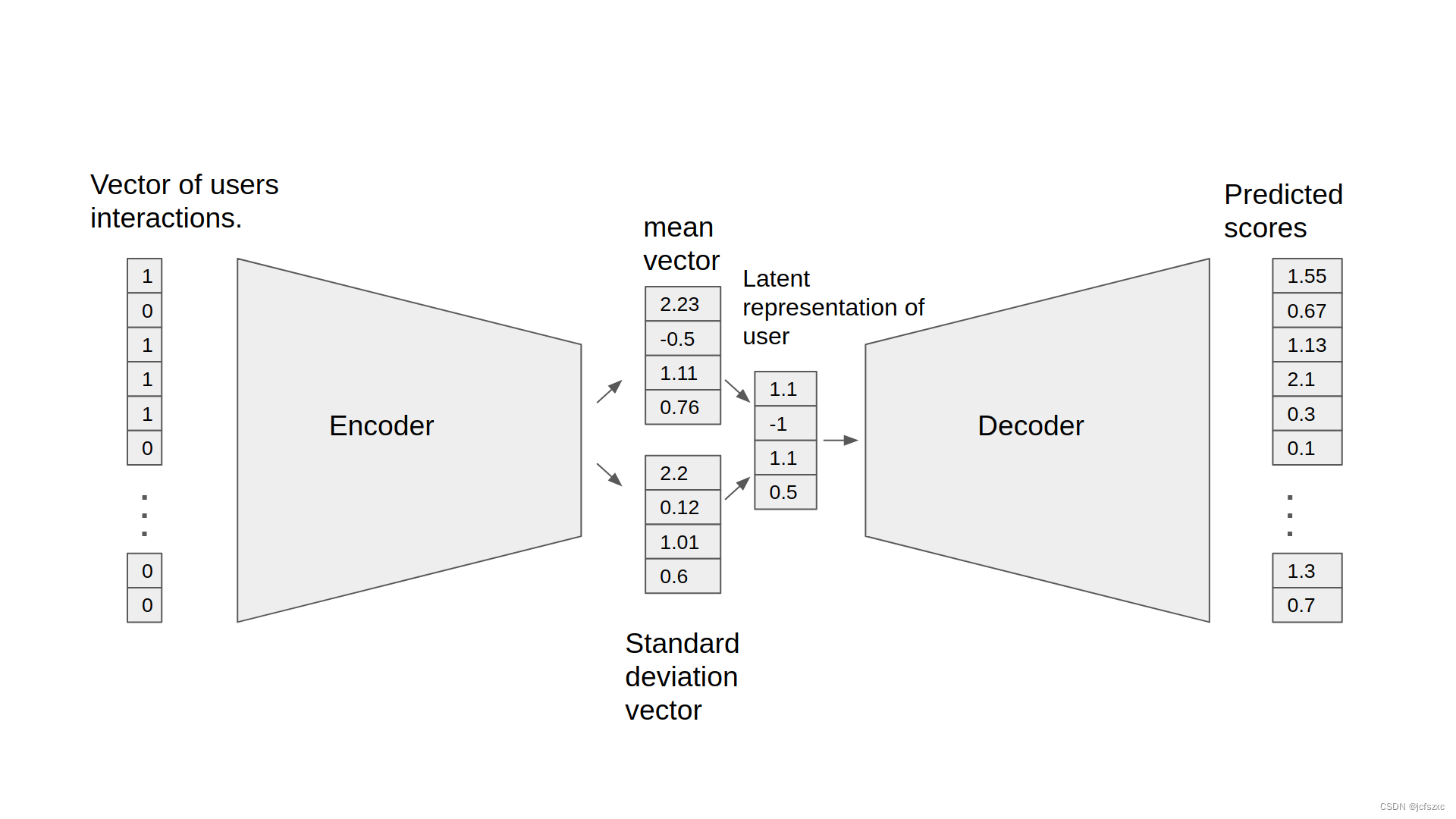
NVIDIA GPU 加速的协同过滤变分自动编码器 (VAE-CF) 是协同过滤变分自动编码器中首次描述的架构的优化实现。 VAE-CF 是一种神经网络,可提供基于用户和项目交互的协同过滤。该模型的训练数据由用户与项目之间每次交互的用户-项目 ID 对组成。
该模型由两部分组成:编码器和解码器。编码器是一个前馈、完全连接的神经网络,它将包含特定用户交互的输入向量转换为 n 维变分分布。这种变分分布用于获取用户的潜在特征表示(或嵌入)。然后,该潜在表示被输入到解码器中,解码器也是一个与编码器结构类似的前馈网络。结果是特定用户的项目交互概率向量。
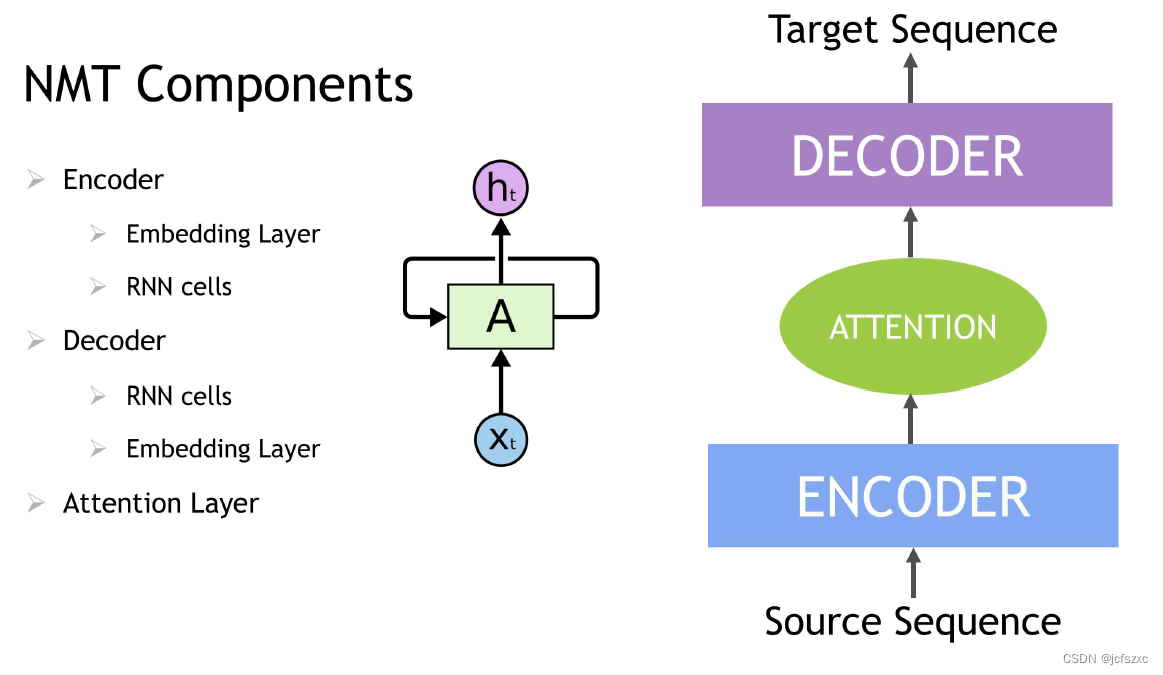
情境序列学习
循环神经网络 (RNN) 是一类具有记忆或反馈循环的神经网络,可以更好地识别数据中的模式。 RNN 解决了处理上下文和序列的困难任务,例如自然语言处理,也用于上下文序列推荐。序列学习与其他任务的区别在于需要使用具有活动数据存储器的模型,例如 LSTM(长短期记忆)或 GRU(门控循环单元)来学习输入数据中的时间依赖性。这种对过去输入的记忆对于成功的序列学习至关重要。 Transformer 深度学习模型,例如 BERT(来自 Transformers 的双向编码器表示),是应用注意力技术的 RNN 的替代方案,即通过将注意力集中在句子前后最相关的单词来解析句子。基于 Transformer 的深度学习模型不需要按顺序处理顺序数据,与 RNN 相比,GPU 上的并行化程度更高,训练时间也更少。
在 NLP 应用程序中,使用词嵌入等技术将输入文本转换为词向量。通过词嵌入,句子中的每个单词都会被翻译成一组数字,然后输入 RNN 变体、Transformer 或 BERT 来理解上下文。这些数字随着时间的推移而变化,而神经网络会自我训练,对每个单词的语义和上下文信息等独特属性进行编码,以便相似的单词在这个数字空间中彼此靠近,而不相似的单词则相距很远。这些深度学习模型为特定语言任务(例如下一个单词预测和文本摘要)提供适当的输出,用于生成输出序列。

基于会话上下文的推荐将深度学习和 NLP 序列建模的进步应用于推荐。根据会话中的用户事件序列(例如查看的产品、数据和交互时间)进行训练的 RNN 模型学习预测会话中的下一个项目。会话中的用户项交互的嵌入方式与句子中的单词类似。例如,观看的电影会先转换为一组数字,然后再输入 LSTM、GRU 或 Transformer 等 RNN 变体以理解上下文。
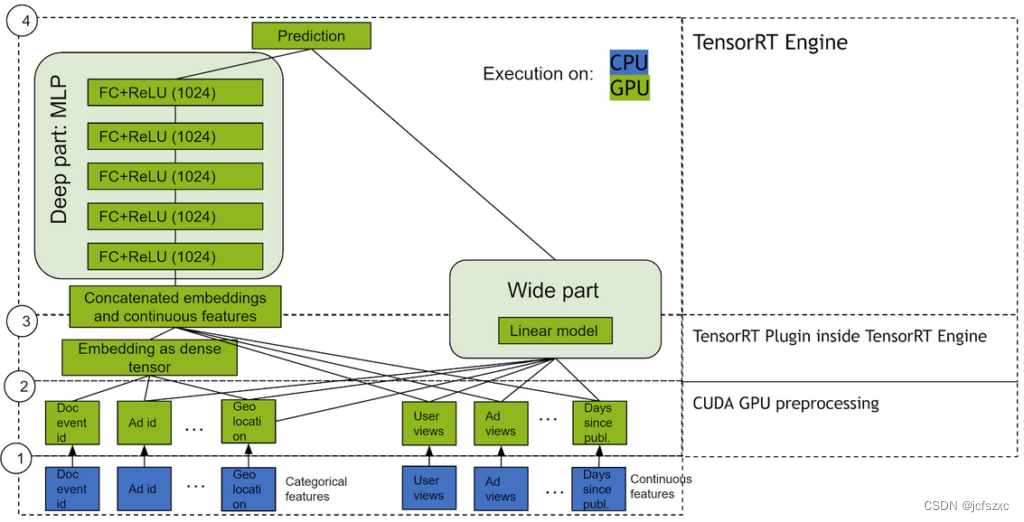
宽而深
Wide & Deep 是指一类网络,它使用并行工作的两个部分(宽模型和深度模型)的输出,将其输出相加以创建交互概率。宽模型是特征及其变换的广义线性模型。深度模型是密集神经网络 (DNN),它是一系列由 1024 个神经元组成的 5 个隐藏 MLP 层,每个层都以密集嵌入的特征开始。分类变量先嵌入到连续向量空间中,然后再通过学习的或用户确定的嵌入馈送到 DNN。
该模型在推荐任务中如此成功的原因在于,它提供了两种数据学习模式的途径:“深层”和“浅层”。复杂的非线性 DNN 能够学习数据中关系的丰富表示,并通过嵌入泛化到相似的项目,但需要查看这些关系的许多示例才能做得很好。另一方面,线性部分能够“记住”在训练集中可能只出现几次的简单关系。
结合起来,这两个表示通道通常最终会比单独使用任何一个表示通道提供更多的建模能力。 NVIDIA 与许多行业合作伙伴合作,他们报告称,通过使用 Wide & Deep 作为更传统的机器学习模型的替代品,离线和在线指标得到了改进。
DLRM
DLRM 是 Facebook 研究引入的基于 DL 的推荐模型。它的设计目的是利用推荐系统训练数据中通常存在的分类和数字输入。为了处理分类数据,嵌入层将每个类别映射到密集表示,然后再输入多层感知器 (MLP)。数值特征可以直接输入 MLP。
在下一个级别,通过计算所有嵌入向量对和处理后的密集特征之间的点积来显式计算不同特征的二阶交互。这些成对交互被输入到顶层 MLP 中,以计算用户和项目对之间交互的可能性。

与其他基于 DL 的推荐方法相比,DLRM 有两个不同之处。首先,它显式计算特征交互,同时将交互顺序限制为成对交互。其次,DLRM 将每个嵌入特征向量(对应于分类特征)视为单个单元,而其他方法(例如 Deep 和 Cross)将特征向量中的每个元素视为应产生不同交叉项的新单元。这些设计选择有助于降低计算/内存成本,同时保持有竞争力的准确性。
DLRM 是 NVIDIA Merlin 的一部分,NVIDIA Merlin 是一个用于构建高性能、基于 DL 的推荐系统的框架,我们将在下面讨论。
为什么推荐系统使用 GPU 运行得更好
推荐系统能够推动最流行的消费者平台的参与度。随着数据规模变得非常大(数千万到数十亿个示例),深度学习技术显示出相对于传统方法的优势。因此,更复杂的模型和快速数据增长的结合提高了计算资源的标准。
许多机器学习算法的数学运算通常是矩阵乘法。这些类型的操作具有高度并行性,并且可以使用 GPU 大大加速。
GPU 由数百个核心组成,可以并行处理数千个线程。由于神经网络是由大量相同的神经元创建的,因此它们本质上是高度并行的。这种并行性自然地映射到 GPU,它可以提供比纯 CPU 平台高 10 倍的性能。因此,GPU 已成为训练大型、复杂的基于神经网络的系统的首选平台,并且推理操作的并行特性也非常适合在 GPU 上执行。

为什么选择 NVIDIA Merlin 推荐系统应用框架?
大规模推荐系统解决方案的性能面临多种挑战,包括庞大的数据集、复杂的数据预处理和特征工程管道以及大量的重复实验。为了满足大规模深度学习推荐系统训练和推理的计算需求,GPU 推荐解决方案提供快速特征工程和高训练吞吐量(以实现快速实验和生产再训练)。它们还提供低延迟、高吞吐量的推理。
NVIDIA Merlin 是一个开源应用程序框架和生态系统,旨在促进推荐系统开发的所有阶段(从实验到生产),并在 NVIDIA GPU 上加速。
该框架为推荐数据集常见的运算符提供快速特征工程和预处理,并为几种基于规范深度学习的推荐模型提供高训练吞吐量。其中包括 Wide & Deep、Deep Cross Networks、DeepFM 和 DLRM,以实现快速实验和生产再培训。对于生产部署,Merlin 还提供低延迟、高吞吐量的推理。这些组件结合起来提供了一个端到端框架,用于在 GPU 上训练和部署深度学习推荐系统模型,该框架既易于使用又高性能。

Merlin 还包含用于构建基于深度学习的推荐系统的工具,该系统可提供比传统方法更好的预测。管道的每个阶段都经过优化,可支持数百 TB 的数据,所有数据均可通过易于使用的 API 进行访问。
NVTabular 通过 GPU 加速特征转换和预处理来减少数据准备时间。
HugeCTR 是一个 GPU 加速的深度神经网络训练框架,旨在跨多个 GPU 和节点分布训练。它支持模型并行嵌入表和数据并行神经网络及其变体,例如广度和深度学习(WDL)、深度交叉网络(DCN)、DeepFM和深度学习推荐模型(DLRM)。

NVIDIA Triton™ 推理服务器和 NVIDIA® TensorRT™ 加速 GPU 上的生产推理,以实现特征转换和神经网络执行。
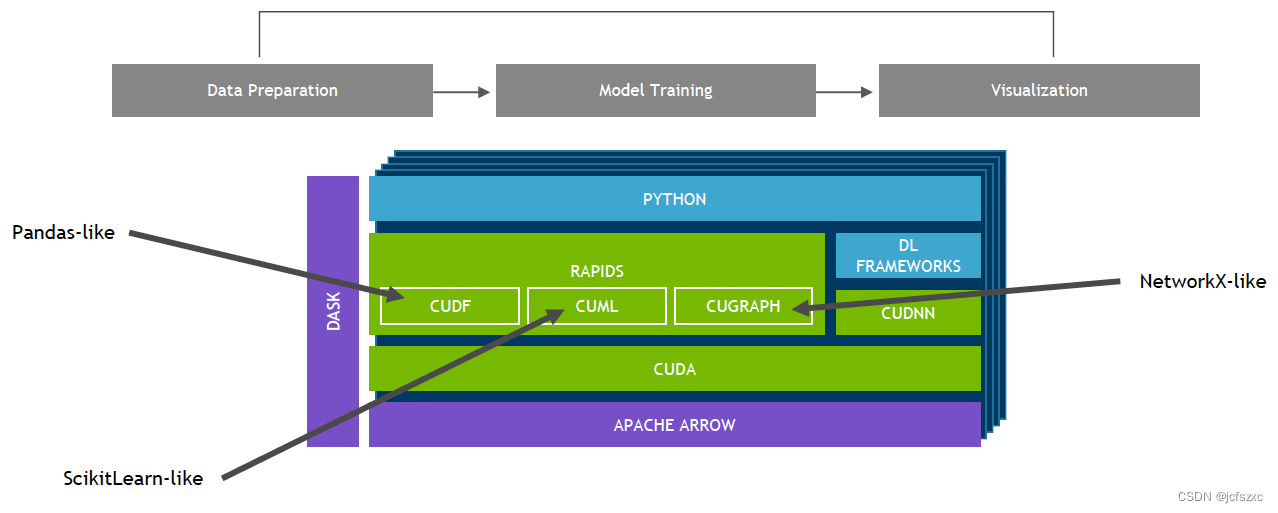
NVIDIA GPU 加速的端到端数据科学和深度学习
NVIDIA Merlin 构建于 NVIDIA RAPIDS™ 之上。 RAPIDS™ 开源软件库套件基于 CUDA 构建,使您能够完全在 GPU 上执行端到端数据科学和分析管道,同时仍使用 Pandas 和 Scikit 等熟悉的界面-学习API。
NVIDIA GPU 加速的深度学习框架
GPU 加速的深度学习框架提供了设计和训练自定义深度神经网络的灵活性,并提供了常用编程语言(例如 Python 和 C/C++)的接口。 MXNet、PyTorch、TensorFlow 等广泛使用的深度学习框架依赖 NVIDIA GPU 加速库来提供高性能、多 GPU 加速的训练。