作者:来自 vivo 互联网服务器团队
本文根据甘青、黄荣杰老师在“2023 vivo开发者大会"现场演讲内容整理而成。
伴随 vivo 互联网业务的高速发展,数据中心的规模不断扩大,成本问题日益突出。在离线混部技术可以在保证服务质量的同时,极大的提升数据中心资源利用率,降低成本。混部技术涉及任务调度、资源隔离、运维观测等一系列技术难题,本文将介绍 vivo 在混部技术方面的实践和探索,为读者提供借鉴和参考
一、在离线混部技术背景
1.1 为什么混部
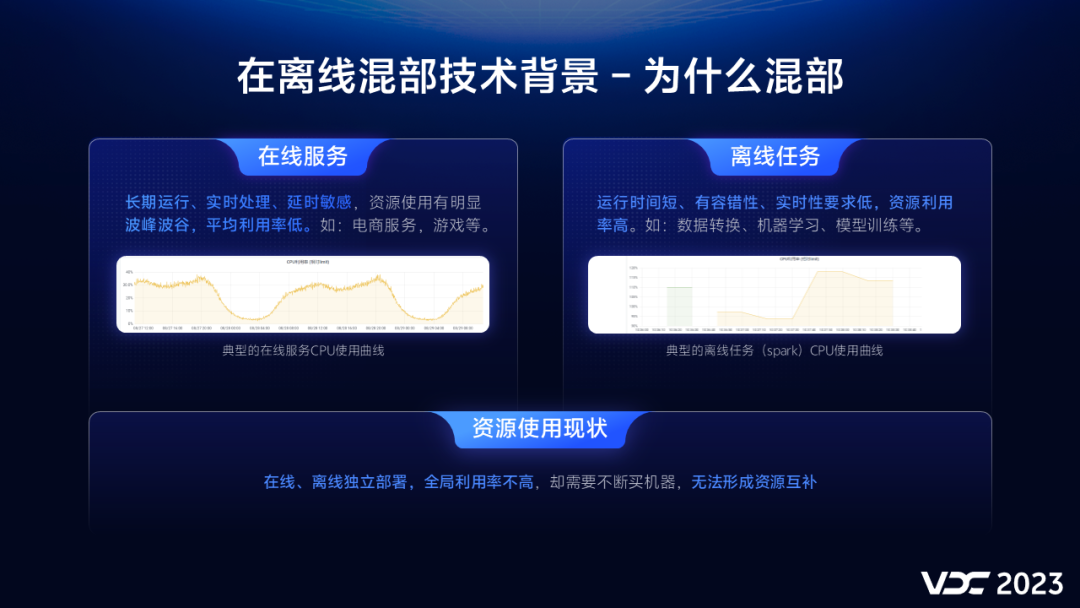
数据中心运行的服务可以分为在线服务和离线任务两大类,它们具有不同的资源使用特征。
在线服务是指那些长时间运行、对时延非常敏感的服务,如电商、游戏等,在线服务的资源利用率存在明显的波峰波谷现象,平均利用率较低。离线任务是指那些运行周期短,有容错性,对实时性要求低的服务,如数据转换、模型训练等,离线任务在执行过程中资源利用率很高。
在混部之前,在线和离线都是分开独立部署,机器不共享,无法形成有效的资源互补,这导致数据中心整体资源利用率不高,却要不断购买新机器,造成了资源浪费。
1.2 混部技术定义
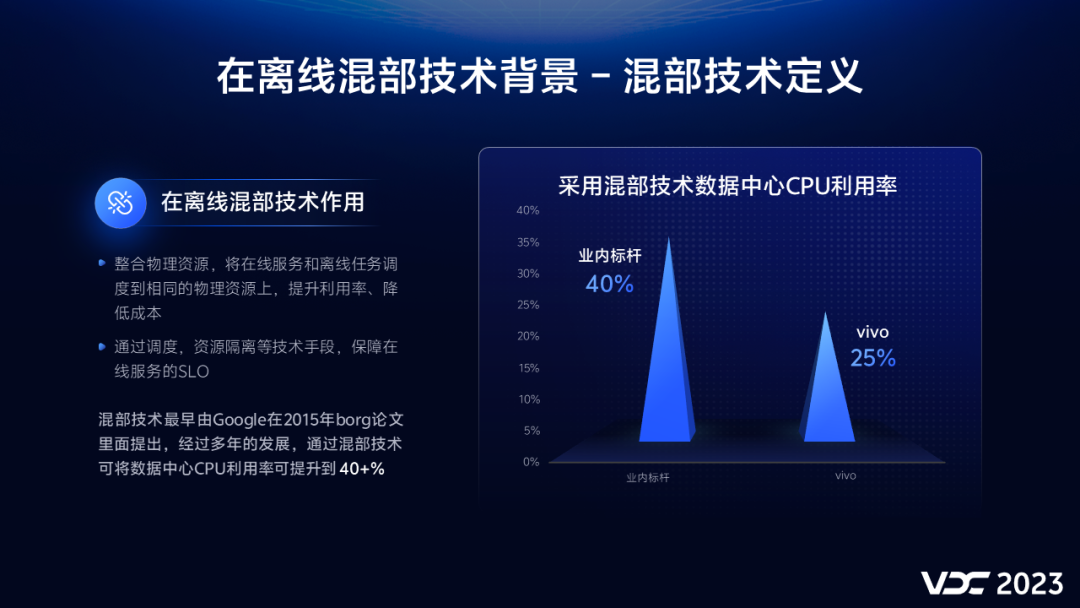
通过混部技术,我们可以将在线和离线部署到同一台物理机上,形成资源互补,提升物理机的资源利用率,降低成本。混部技术最早由谷歌在2015年提出,经过多年的发展,混部技术已经趋于成熟,目前业内利用混部技术可以将数据中心的CPU利用率提升至40%左右 。
vivo在2020年开始调研混部技术,2023年混部平台投入生产,目前我们已经将部分混部集群的CPU利用率提升至25%(最新已达30%)左右。相较业界标杆这还有一定的差距,但随着混部规模的扩大,我们将挑战更高的目标。
二、在离线混部平台实践
2.1 混部平台产品能力

混部平台必须具备两个产品能力:
-
第一、强大的调度、隔离能力
-
第二、完善的监控、运维能力
强大的调度能力解决了,我们如何将离线任务高效、合理的调度到在线服务所在的物理机上。而强大的隔离能力保障了在线服务的质量不受离线任务干扰。完善的监控和运维能力则可以让我们洞悉整个混部平台的运行情况,及时发现潜在风险,帮助运维人员更高效的完成系统和业务的运维工作,保障集群的高稳定性。
2.2 混部差异化资源视图
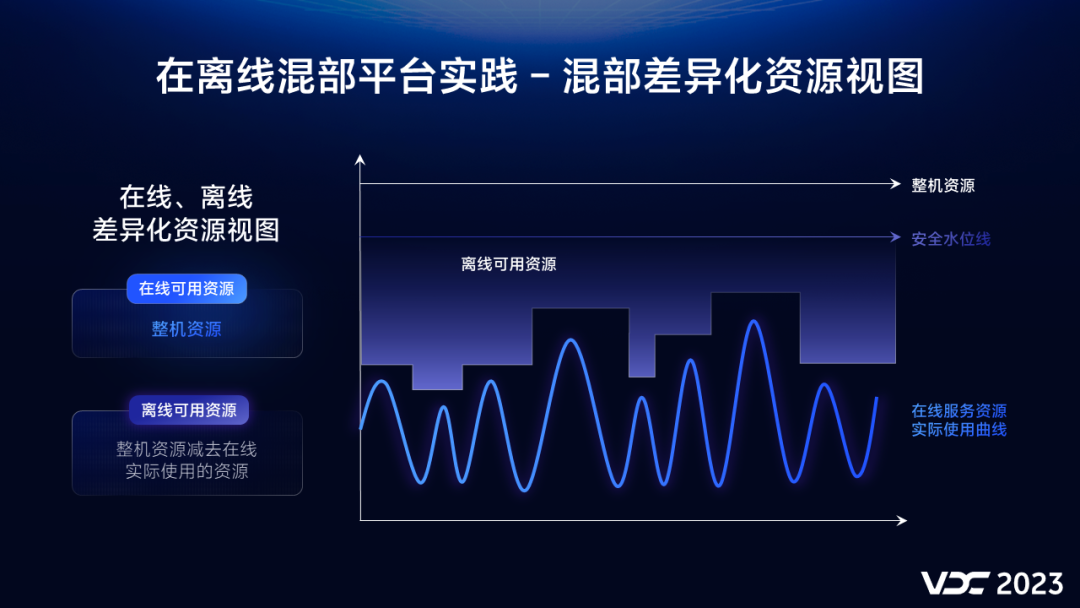
混部首先要解决的一个问题是离线使用哪一部分资源。
在vivo混部系统中在线和离线看到的资源视图是不同的:
-
在线可用资源为 整机资源
-
离线可用资源为 整机资源减去 在线实际使用的资源
同时为了避免整机负载太高影响系统的稳定性,我们设置一个安全水位线,用于调节离线可用资源大小。
2.3 混部QoS等级

为了保障混部系统的slo,我们将服务分为三个等级:高、中,低。
不同等级的服务对物理资源如:CPU、内存 使用时有不同的优先级。高优先级服务支持绑定CPU模式,适用对延时非常敏感的在线服务。一般的在线服务可设置为中优先级。离线任务设置为低优先级,通过这样的等级划分,我们很好的实现在线对离线的资源压制和隔离,保障了在线服务质量。
2.4 混部核心组件架构

我们所有的混部组件都是以插件方式独立运行,对原生K8s无侵入。我们实现了一个混部调度器,在线和离线统一使用这个调度器,避免了多调度器资源账本冲突的问题。
每台物理机上都会部署一个混部agent,它可以实时采集容器资源使用数据,并根据安全水位线对离线任务进行压制、驱逐等操作。
内核层面我们使用了龙蜥OS,它具备强大的资源隔离能力,可以帮助我们更好的隔离在线、离线资源使用,保障在线服务质量。
2.5 混部组件功能

我们把混部组件分为管控组件和单机组件两大类。
管控组件主要负责调度和控制,根据vivo业务使用场景,我们对调度器做了一些增强,提供了numa感知、负载感知,热点打散,批量调度等能力。
混部控制器主要提供了一些配置管理能力:如资源画像统计、node slo配置、node扩展资源变更等。
2.6 混部可视化监控
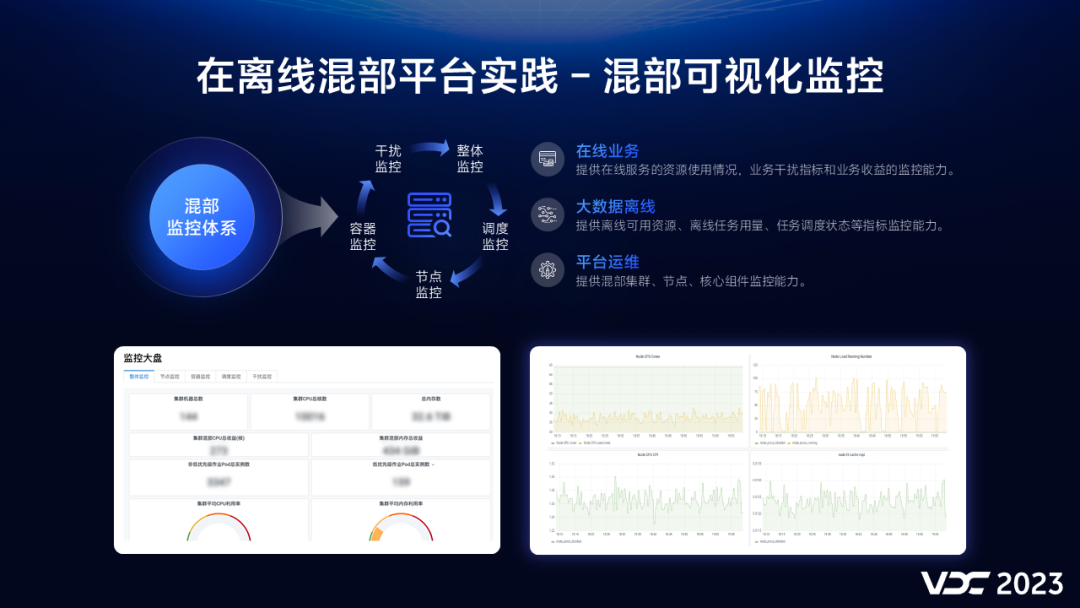
我们为混部建立一套完整的可视化监控体系。
针对在线服务我们提供了:容器资源使用指标,受离线干扰指标、业务混部收益指标等监控能力。
针对离线任务,我们提供了离线可用资源、任务异常状态等监控能力。
在平台层面上我们提供了节点、内核,核心组件的监控,通过这些监控可及时发现平台潜在的风险。
2.7 混部平台运维

为了简化运维操作,提升运维效率,我们对混部集群搭建和节点扩缩容操作进行了白屏化改造,开发了资源池管理功能,简化了物理机接入流程,运维效率大幅提升。
在运维平台上运维人员可以快速调整混部隔离、水位线等参数,如果发现在线服务受到干扰,运维人员可以一键关闭混部,驱逐离线任务,保障在线服务质量。
2.8 问题与挑战
2.8.1 apiServer拆分
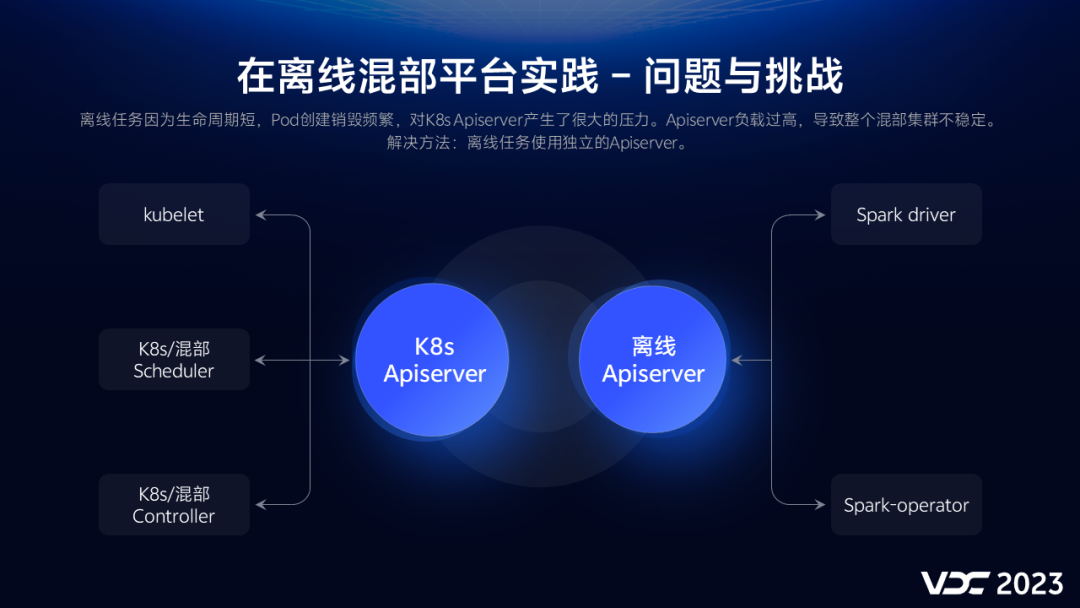
通过混部产品能力的建设,我们很好的实现了容器混部能力,但是在实践中我们还是遇到一些新的挑战:相对于普通K8s集群,混部集群中运行着更多的容器,而且离线任务由于生命周期短,容器创建销毁更为频繁,这对K8s apiServer 产生了很大的压力。
所以我们拆分了apiServer ,离线任务使用独立的apiServer ,保障了集群apiServer 负载一直处于一个安全水平。
2.8.2 监控架构优化
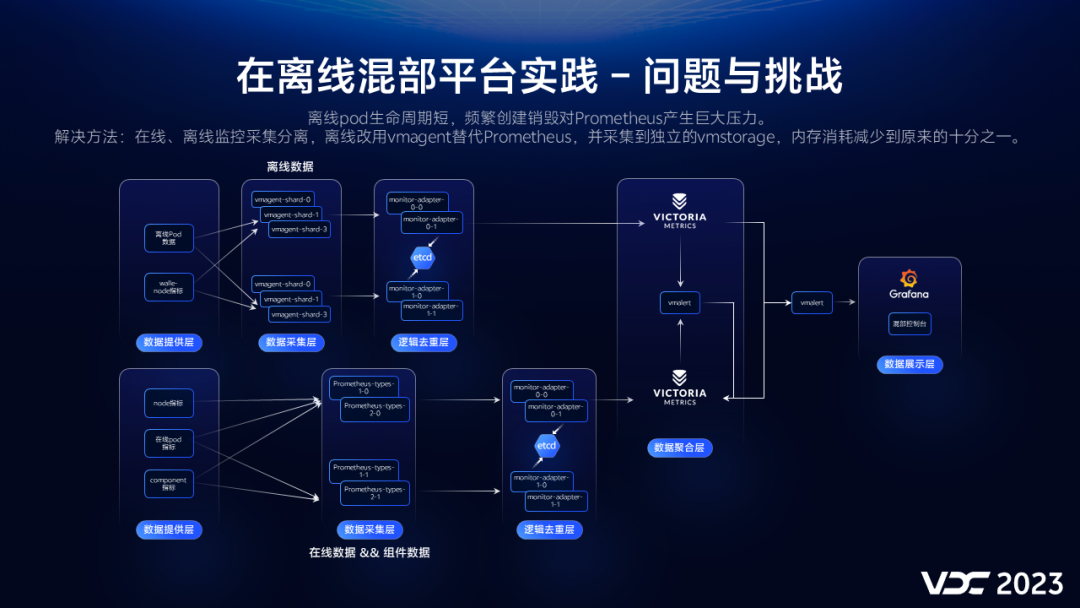
同样混部之后由于采集了更多的监控指标,导致Prometheus内存消耗过多,无法满足平台指标 采集需求。针对这个问题,我们优化了监控架构,将在线和离线监控组件分开部署,离线改用性能更好的vmagent,通过这个优化,监控组件内存消耗减少到原来的十分之一。
2.9 利用率提升
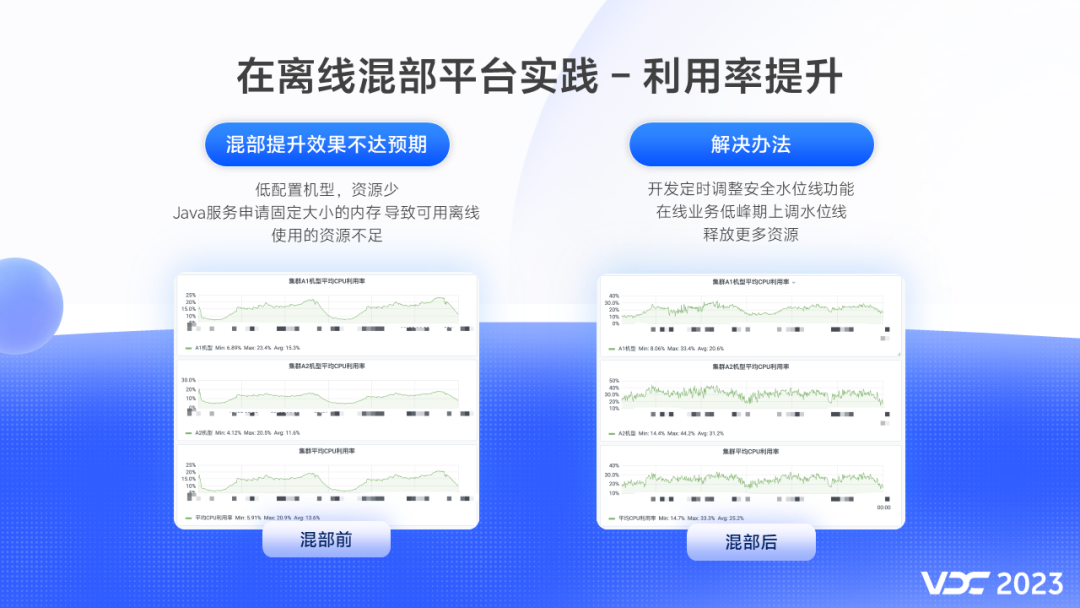
混部初期虽然集群CPU利用率有所提升,但是还是没有达到我们的预期,主要原因有:
-
一、部分低配置机器资源本身较少。
-
二、Java 类应用堆会固定占用大量内存,导致可提供给离线使用内存资源不足。
针对这些问题,我们开发了定时调整安全水位线功能,在业务低峰期上调安全水位线,释放更多的资源给离线使用。通过一系列的优化手段,我们将其中一个混部集群的CPU利用率由13%提升到了25%左右,几乎翻倍,混部效果得到了有效的验证。
三、Spark on K8s 弹性调度实践
3.1 方案选型
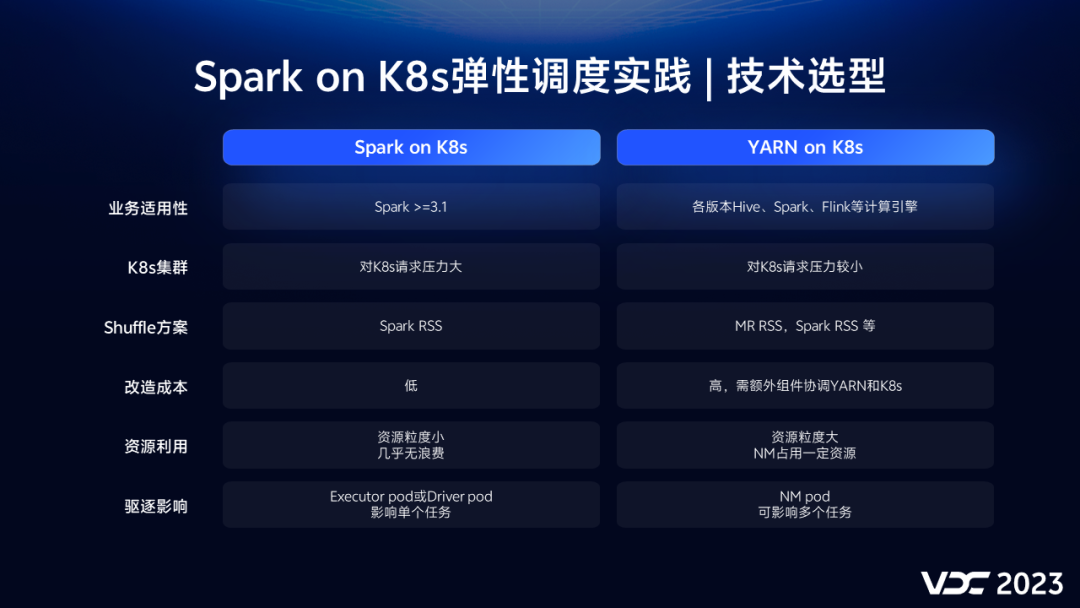
在大方向的技术选型上,我们选择了 Spark on K8s,在业内,也有一些公司采用了 YARN on K8s的方案。我们也对这两种方案进行过对比。
从业务适用性来说,YARN on K8s 是通用的,可以兼容Hive、Spark、Flink这些引擎,它不需要频繁创建Nodemanager pod,对K8s的压力比较小。这些都是它的优点,但另一方面,Nodemanager ESS服务是对磁盘有容量和读写性能要求的,混部机器磁盘一般难以满足。所以我们要支持不同引擎的remote shuffle service。
如果计算引擎有不同的版本,那么RSS也要支持不同版本,比如Spark2,Spark3。如果你有不同的引擎,不同的版本,很可能一种RSS还满足不了需求。另外Nodemanager需要根据K8s混部节点的剩余资源,动态调整可用的vcore和内存,所以还需要一个额外的组件来做这个事情,这需要较高的改造成本。在资源利用上,NM的资源粒度相对大,自身也会占用一些资源,存在一定的浪费。在资源紧张的情况下,Nodemanager作为整体被驱逐,会影响多个任务。这些是YARN on K8s的劣势。
作为对比,Spark on K8s 劣势有哪些?
首先这个特性在Spark 3.1以上版本才正式可用。Spark on K8s由于会频繁的创建、查询、销毁大量的executor pod,对K8s的调度能力以及master节点会造成比较大的压力。另一方面,它的优势在于只需要能支持spark3.X的RSS,这有较多的开源产品可选择。而且改造成本比较低,不需要额外的组件。资源粒度小,更有利于充分利用集群资源。在资源紧张时,会逐个pod进行驱逐,任务的稳定性会更高。
两方案各有优劣势,为什么我们选择了Spark on K8s?一方面因为Spark3.X是vivo当前及未来2~3年的主流离线引擎,另一方面vivo内部对K8s研发比较深入,能有力支持我们。基于以上原因,我们最终决定使用spark on K8s
3.2 三步走战略

确定了方案选型,那在vivo我们是如何推进spark on K8s大规模的应用落地呢?回顾总结我们走过的路,可以大致归纳为三步走的战略。
-
第一,是任务跑通跑顺的初期阶段
-
第二,是任务跑稳、跑稳的中期阶段
-
最后,是任务跑得智能的成熟阶段
接下来的内容,我们将对每个阶段展开细说。
3.2.1 任务跑通跑顺
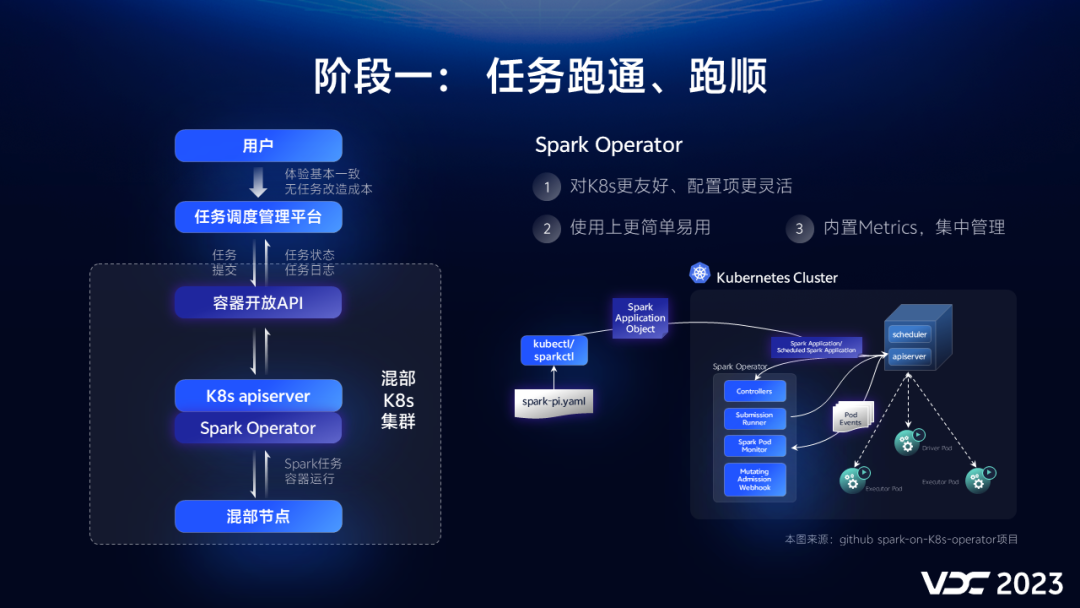
在任务跑通、跑顺的第一阶段,我们要解决的是怎么将任务提交K8s集群,同时要求易用性、便利性方面能够达到与on YARN 一致的用户体验。将我们最后采用的方案架构简化一下,就如同这张图所示。
首先,为了降低任务提交的复杂性、避免用户改造任务的成本。我们在任务调度管理平台做到了对原有Spark任务的兼容,通过vivo内部的容器开放API-这个代理层,我们不需要维护额外的K8s client环境,就可以轻松实现任务提交,提交后也能近实时获取任务的状态和日志信息。
另外一个关键点是,我们选用了Spark Operator作为Spark任务容器化的方案。Spark Operator是谷歌基于K8s Operator模式开发的一款的工具,用于通过声明式的方式向K8s集群提交Spark作业。
Spark Operator的方式还有其他优点:
-
Operator方式对K8s更友好,支持更灵活、更全面的配置项
-
使用上更简单易用
-
内置Metrics,有利于我们做集中管理
要达到阶段一的目标,让任务跑通、跑顺。我们主要克服了哪些关键问题和挑战?

第一个是日志查看,因为Spark Operator方式并没有提供已结束作业的日志查看方式,包括driver和executor日志。在Driver侧,我们通过定期请求容器开放API,能准实时地获取Driver Pod状态与日志。在Executor侧,我们参考了on yarn的方式,Executor Pod结束后,日志上传HDFS,与YARN日志聚合类似。
另一方面,我们也在Spark HistoryServer做了二次开发工作,增加了on K8s方式的日志查看接口。用户查看已完成的Executor日志时,不再请求JobHistory Server,而是请求Spark HistoryServer接口。在体验上做到了基本与yarn一致。
在混部K8s集群,我们也做了三方面能力的加强。
-
一是,确保分配能力能支持离线任务频繁建删pod的需求,在优化后我们离线Pod分配能力达到数百pod/秒。
-
二是,在K8s侧提升了spark内部的Driver优先级,确保了在驱逐时Driver稳定性高于Executor。
-
最后一个是,发现并修复了spark-operator的一个bug,这个bu是Operator在多副本部署时,slave副本webhook处理有一点概率出现pod 找不到的问题。
3.2.2 任务跑稳跑准

在第二阶段,我们要保障的是任务跑稳,数据跑准,因此,我们有两个关键的举措:
-
大规模双跑,目的是确保Spark任务迁移到K8s集群后是兼容的,任务成功率有保障;任务执行时长是稳定的,不会明显变慢;数据是准确的,跟on YARN保持一致性。为此,我们需要对任务进行on YARN和on K8s两种模式下的双跑测试,我们分批次总共进行了7轮双跑,覆盖了2万+的线上正式任务。最终也取得了我们想要的结果:我们双跑最终达成的任务成功率超过了99.5%,绝大部分的任务在两种模式下的时长波动在25%以内,数据一致性是100%。
-
混部集群的压力联调,目的是确保混部集群的承载容量能够支撑大规模的离线任务调度,通过模拟未来1年的任务量来给混部集群做压力测试,充分发现和检测K8s集群可能存在的性能问题。最终,通过我们多轮压测和问题解决,我们在单个K8s集群能够支撑150+同时运行的Spark任务,1万+同时在运行的Pod数量。

在第二阶段,我们主要面临三个方面的问题和挑战。
首先是我们需要为Spark选择一个外部的shuffle服务,经过技术选型和比较,我们最终选择开源的celeborn作为我们的remote shuffle service组件。我们通过对机型和参数的测试调优,使celeborn的性能达到我们的预期需求。在大规模的应用场景中,我们还发现了会存在大任务会阻塞小任务,导致shufle read变慢的问题,我们对这种情况做了参数和代码上的优化,当前社区也针对shuffle read的问题有一些待优化的改进。另外celeborn进行了容器化部署,在提升自动化运维能力的同时,也可以为混部集群提供额外的计算资源。
其次,在任务稳定性方面,我们也解决了一系列的问题。
-
在双跑的时候,我们发现有不少任务在on K8s模式下很容易OOM,这是因为在on YARN模式下申请的container内存大小,不止是由Spark任务本身的内存参数决定,还会被YARN的资源粒度参数所影响。所以这块要做一些适配对标工作。
-
在任务量比较大的情况下,Spark operator的吞吐能力会遇到瓶颈,需要我们将并发worker数量、队列的相关参数调大。
-
CoreDNS因为Spark任务频繁的域名解释请求,导致压力增大,甚至可能影响在线服务。这个可以通过访问ip而不是域名的方式来规避,比如namenode节点、driver和executor。
-
横向扩展namespace,这样可以避免单namespace的瓶颈,也防止etcd出现问题。
-
我们K8s apiserver的压力随着任务量增长压力也会逐渐增大,这会影响整个集群的稳定性。我们主要通过优化Spark driver list pod接口、使用hostnetwork方式两个优化手段,有效降低了apiserver的压力。
最后要说的是数据一致性,关键点是要做到行级记录的MD5校验,发现有不一致的Case,我们做到100%的分析覆盖。排除了因为时间戳随机函数等一些预期内的不一致,我们发现并修复两种case会偶发导致不一致的问题:
-
celeborn Bug导致不一致,具体可参考CELEBORN-383解决
-
Java版本不一致导致的问题
3.2.3 任务跑得智能
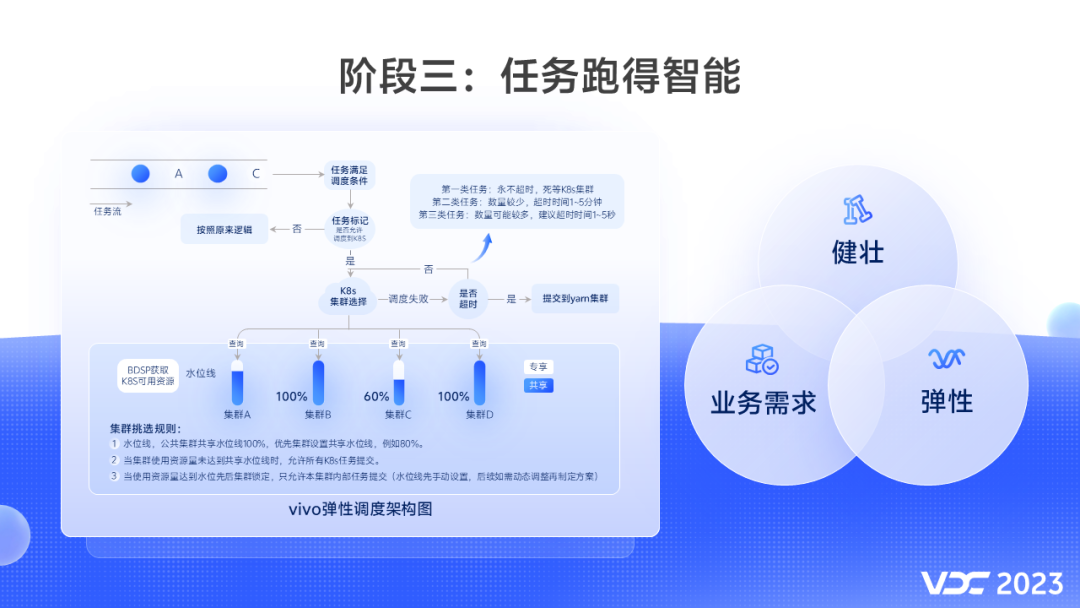
在第三阶段,我们需要解决的问题是让任务跑得智能,怎么定义智能,我想用三个词来概括弹性、健壮、业务需求。这是我们弹性调度的架构图,细节我就不讲了,这里我介绍下我们的调度系统重点支持的功能。

在弹性方面,我们需要做到实时根据混部集群资源闲忙,智能提交至混部集群或者Hadoop集群。在前期我们K8s集群的资源相对Hadoop是小头,通过合理的水位线控制,防止大量任务同时调度到K8s导致饿死。
健壮,就是要保证任务的高可用。
我们建设的能力包括:
-
任务双跑成功后再混部
-
支持离线任务失败自动回滚到Hadoop集群执行
-
支持用户自主决定任务是否可调度至K8s集群
-
初期剔除重要核心任务、剔除不可重试任务
目的是在用户任务迁移时做到让用户无感。
在满足业务需求方面,我们支持优先调度本业务的离线任务, 优先满足业务部门的离线任务资源需求;支持只在指定时间段里调度离线任务,支持在出现异常情况下一键终止调度K8s。这些是为了确保在线服务的高可用性,免除在线业务的后顾之忧。
3.3 混部效果
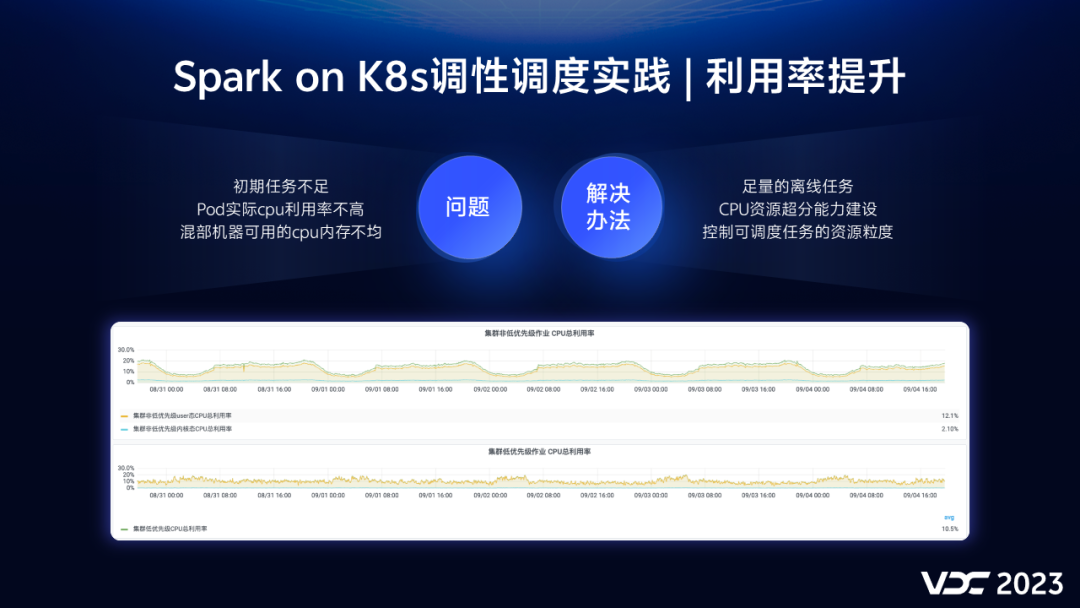
克服了三步走过程中的磕磕碰碰,我们终于可以将离线任务大规模混布到K8s混部集群了。但是我们很快发现,混部集群的整体利用率并没有达到我们的预期,主要有三方面的原因。
-
初期的Spark任务不足,这个我们通过加快双跑,迁移低版本的Spark任务,迁移Hive SQL任务来解决。
-
在混部的时候,我们也观察到,离线任务的pod cpu利用率其实没那么高。比如我们申请一个核,通常只能利用0.6个核,存在浪费的情况。我们上线了CPU资源超分的能力,目前是静态的固定比例超分,通过这个措施,我们能将pod的实际cpu利用率打到80%以上。
-
另外就是混部集群中的机器配置不均,部分机器cpu资源充足,但是内存不够。我们通过在调度侧控制可调度任务的资源粒度,尽量调度对内存资源需求较小的任务。
通过我们在任务调度侧,以及之前甘青提到过的其他措施。混部集群利用率得到了进一步的提升。
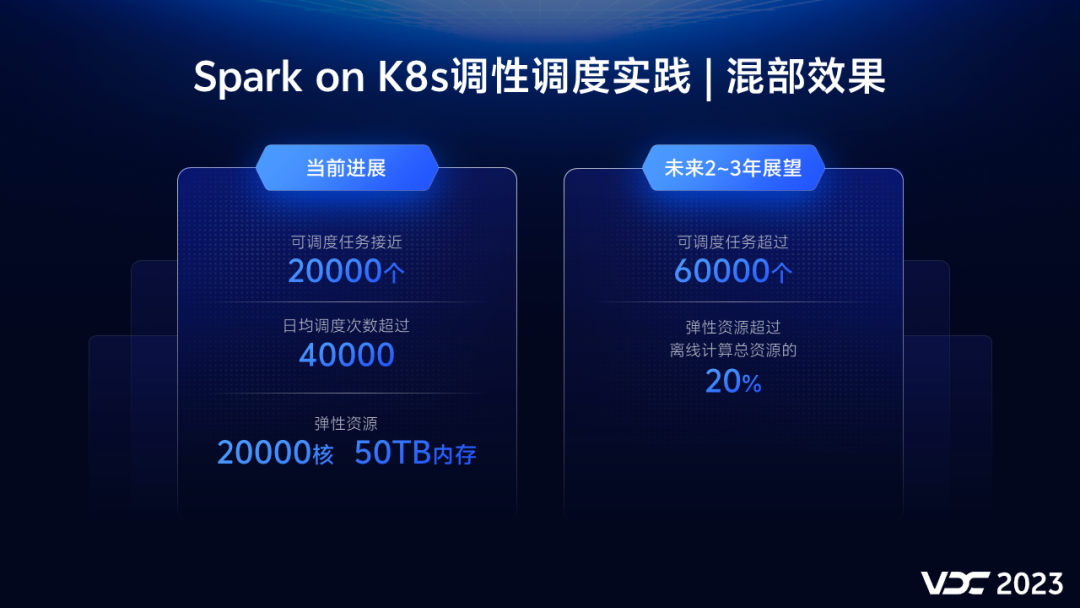
最后,我向大家同步下,当前我们达成的混部效果。
我们目前可供调度的任务接近2万个,这些任务每天调度的次数已经超过了4万次。在凌晨的高峰期,我们通过混部,能为离线任务额外增加2万核、50TB内存的计算资源。这个收益是相当可观的,我们也希望在未来的2到3年,将可调度的任务规模提升到6万个,弹性资源能够为离线计算总资源贡献20%的份额。
通过继续深度推进在离线混部技术,我们期望能够为vivo增效降本工作持续地贡献力量。
以上就是本次分享的全部内容。