文章目录
- 1.单例模式
- 2. 阻塞队列
- 3. 定时器
- 4.线程池
前言 :
前面的一些文章,我们已经将有关多线的基础知识了解了, 下面我们来写一些关于多线程的代码案例,来强化对多线程的理解,另外通过这些案例补充一下其他方面的知识。
1.单例模式
单例模式 : 设计模式的一种。
此时就有问题了 ,什么是设计模式呢?
比如 : 下棋 (象棋,围棋 , 五子棋等) , 如果我们想要 下棋下的比较厉害 ,肯定会去研究研究棋谱 , 这里棋谱就相当于 大佬们,将一些常见的对局场景,给推演出来的结果.
这里我们照着棋谱来下棋, 基本上棋力就不会差到哪里去.
同理 : 在计算机圈子里面, 水平参差不齐 , 大佬们为了能够让小菜鸡们 (特指 本人) 能够 把这个代码写的不要太差 , 也就发明了一组 棋谱 称为 设计模式 .
所以设计模式 就是针对一些典型的场景,给出了一些典型的解决方案.
只要我们能够熟悉设计模式,并且按照设计你模式来开发,此时代码也就不会写的差哪去.
简单的了解了啥是单例模式,下面来学习一下,最常用的两种设计模式
1.单例模式
2.工厂模式
单例模式 : 单个实例(对象)
在有些场景中 , 有的特定的类 , 只能创建出一个实例, 不应该创建多个实例 .
使用了单例模式后,此时想要创建多个实例,很难 .
注意 : 像这样的需求不依靠单例模式 , 就是靠君子协议能不能行 , 也是可以的 ,比如在古代,帝王可以后宫佳丽3千 ,此时的帝王,就可以对自己喜欢的人说我只娶你一个 (君子协定),但是否真的只有一个,还得看帝王自己 , 放到现代, 如果你娶多个老婆,是会构成重婚罪的。 此时就不单单是君子协定 ,还有法律规定.
我们的单例模式就是针对上述的需求场景进行了强制的保证, 通过 巧用 java 的现有语法,达成了 某个类只能被创建出一个实例,这样的效果, (当我们不小心创建了多个实例,就会编译报错).
回顾 : 在 学习jdbc时 DataSource 这样的类,其实就非常适合于使用单例模式 , DataSource 只是描述数据在哪里, 我们的数据都是来自于一个 MySQL 此时创建多个 DataSource 指的都是同一个,所以搞多个 DataSource 就会浪费.
在我们的jdbc 中 DataSource 的确是使用单例模式的.
下面继续 , 关于单例模式 ,有两种典型的实现 .
1.饿汉模式
2.懒汉模式
下面通过 代码来学习 这两种实现方式
饿汉模式
饿汉模式 : 类加载阶段就把实例创建出来了 (类加载是比较靠前的阶段) , 这种效果就给人一种特别急切的感觉 . 通过这种感觉就起了一个比较形象的名字 饿汉模式 。

懒汉模式
举个例子 : 一家 四口 中午吃饭, 剩下 4 个碗但是不着急洗,等下次吃饭的时候,有多少人洗多少个碗.
如: 晚饭只有 2 个人吃那么就洗两个碗, 我们的懒汉模式就是这样 ,需要用到对象的时候才会去创建对象 。
这里拿洗碗 饿汉模式的例子 就是 吃完饭直接将碗洗掉,不会拖到下次要用的时候才去洗。

在计算机中 普遍 懒汉模式 比 饿汉模式更好 , 因为更高效
下面继续 , 上面写的懒汉模式其实是 存在问题的, 下面来看看到底有啥问题呢 ?
看到文章标题吗 , 多线程 , 那么有没有考虑,懒汉模式和饿汉模式 ,在多线程模式下 调用 getInstance(获取对象) 是否是线程安全的呢?
回忆一下上文说过线程安全问题的几种情况 :
1.线程之间抢占式执行
2.多个线程操作同一个变量
3.内存可见性
4.指令重排
另外 :还补充了 多个线程读取同一个对象是不会触发线程安全问题的。
饿汉模式 : 在多线线程下是线程安全的 , 因为 多线程调用只会涉及到读操作 。

懒汉模式 : 懒汉模式既涉及到了 读操作,又涉及到了写操作(创建对象) , 此时就会出现线程安全问题.

下面 还是通过 画图来 解释一下 懒汉模式为啥会出现 线程安全 :
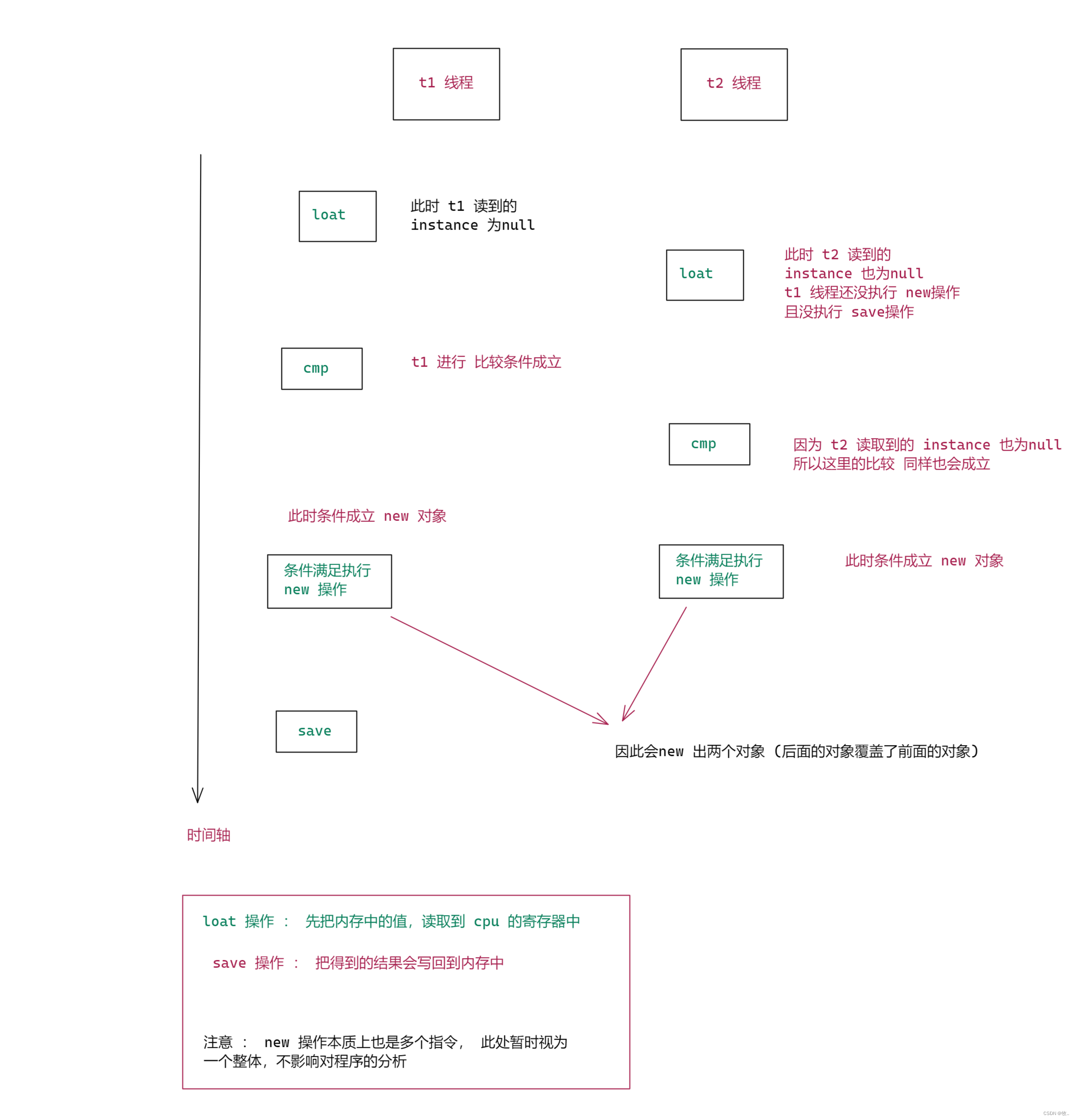
分析得出我们的懒汉模式会存在 线程安全问题,下面我们就来通过 加锁操作解决当前的线程安全问题.

到此我们的加锁操作就完了, 你以为就结束了吗, 其实我们的代码还是有问题的 ,性能上的问题 .

写到这里 我想问问,这段代码还有没有问题 ?
这里就不卖关子了, 其实还有两个问题, 内存可见性 和指令重排序 。
内存可见性 :

指令重排 :

这里 单例模式中 : 懒汉模式 和 饿汉模式就学习完了, 下面,就来学一下另外一个案例 , 阻塞队列.
2. 阻塞队列
回忆一下: 队列特点先进先出 , 这里阻塞队列 也是一个队列,所以也满足这个特点
另外 : 一些特殊的 队列,不一定遵守先进先出这一特点 ,像优先级队列 PriorityQueue 就不是先进先出 , 要不是先出最小的, 要不先出最大的,看你是大根堆还是小根堆 。
而我们的阻塞队列 也是一个特殊的队列, 虽然满足 先进先出这个特点,但是带有特殊的功能 :
功能 : 阻塞
1.如果队列为空 , 执行出队列操作,就会阻塞, 阻塞到另外一个线程往队列里添加元素(此时队列中就不为空) 为止.
2.如果队列满了 , 执行入队列操作 ,也会阻塞 ,阻塞到另外一个线程从队列中取走元素(此时队列不是满的) 为止.
扩充 : 消息队列也是一种特殊的队列 , 相当于在阻塞队列的基础上,加上了 “消息的类型” 按照指定类别进行先进先出 .
举个例子 :
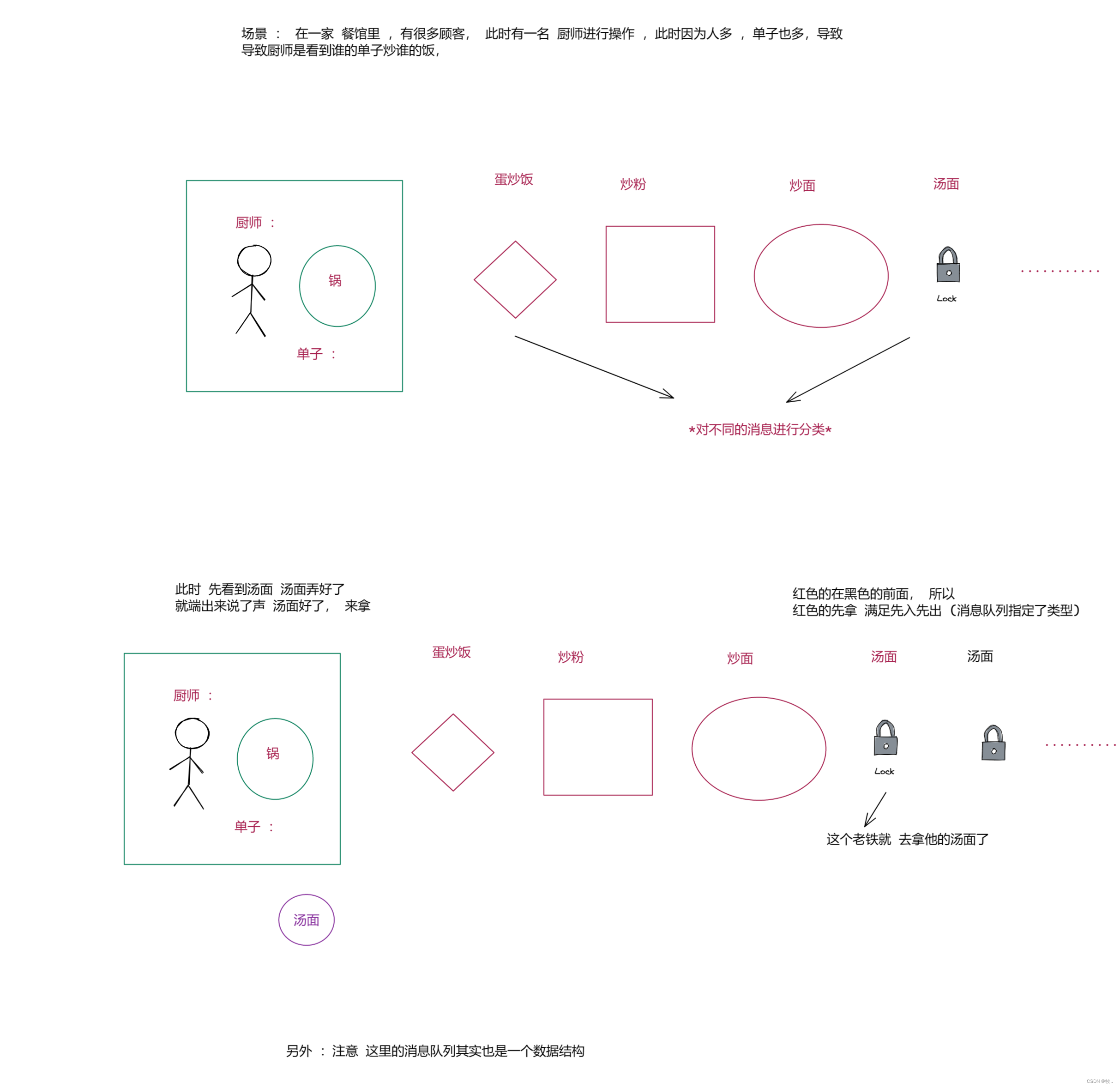
了解 :
另外 正因为消息队列有这样的性质, 比较香,所以大佬们 , 就将这样的数据结构,单独实现成了一个程序, 这个程序可以通过网络的方式和其他程序进行通信 。
这时这个消息队列就可以单独部署到一组服务器上(分布式) , 存储能力和转发能力都大大提升了 。
很多大型项目里都可以看到这样的消息队列的身影 , 此时消息队列 就已经成了 可以和 mysql , redis 这种相提并论的一个重要组件了 “中间件”
rabbit mq就是消息队列中的一种典型实现.
另外 还有很多其他的实现 , active mq , rocket mq , kafka … 都是业界知名的消息队列 .
前面说了, 消息队列是根据阻塞队列进行修改的,加上了"消息类型" , 所以我们想要认识清楚消息队列, 就得先认识清楚 “阻塞队列” 。
下面我们来了解一下我们的 生产者消费者模型:
生产者消费者模型 , 就是基于阻塞队列阻塞的特性实现的。
举例 : 一家人 包饺子
包饺子 需要 擀面杖 来擀饺子皮 , 然后将肉馅包入饺子皮 . 这两个步骤 .
此时就有两种典型的包法
1.每个人 ,分别 进行擀饺子皮 , 包饺子
2.一个人 专门负责擀饺子皮 , 另外几人 负责包 . 负责擀饺子皮的 , 擀好一个饺子皮 ,放在盖帘上(用来放置饺子皮的东西) , 包饺子的人就可以直接在盖帘上取 。
此时 大家觉得是第一种好还是第二种好 ?
明显第二种 :
第一种 :因为擀面杖只有一个 , 所以大家都会进行竞争 ,导致 没有 拿到 擀面杖的进行等待 ,影响效率, 这里就好比锁 没有获取到锁 阻塞等待。
第二种 : 因为有专门的人员 ,进行各自的本职工作, 就不会出现竞争的情况 。效率自然就高了 , 这种就是消费者生产者模型
这里擀饺子皮 的人 就相当于 生产者 , 负责包饺子 就是 消费者. 盖帘 就相当于 交易场所 (生产者和消费者进行沟通交互的桥梁) .
如果 ,生产者生产的太慢 就可以 让消费者 等待 ,如果消费的太慢,就可以让生产者等待。
既然知道了啥事消费者生产者模型, 下面来看看生产者消费者模型 给我们的程序带来的两个非常重要的好处 .
1.实现了发送方和接收方之间的 解耦
这里解耦 就是降低耦合的过程, 相比大家一定听过 ,高内聚低耦合的吧 。
高内聚 : 尽量将相同类型数据放在一起,节省空间,提升空间利用率。
低耦合 : 希望 程序 与 程序之间 联系尽量少
如何 做到 降低耦合呢 ?
先来看一个例子 : 服务器之间的调用(开发中典型的场景)
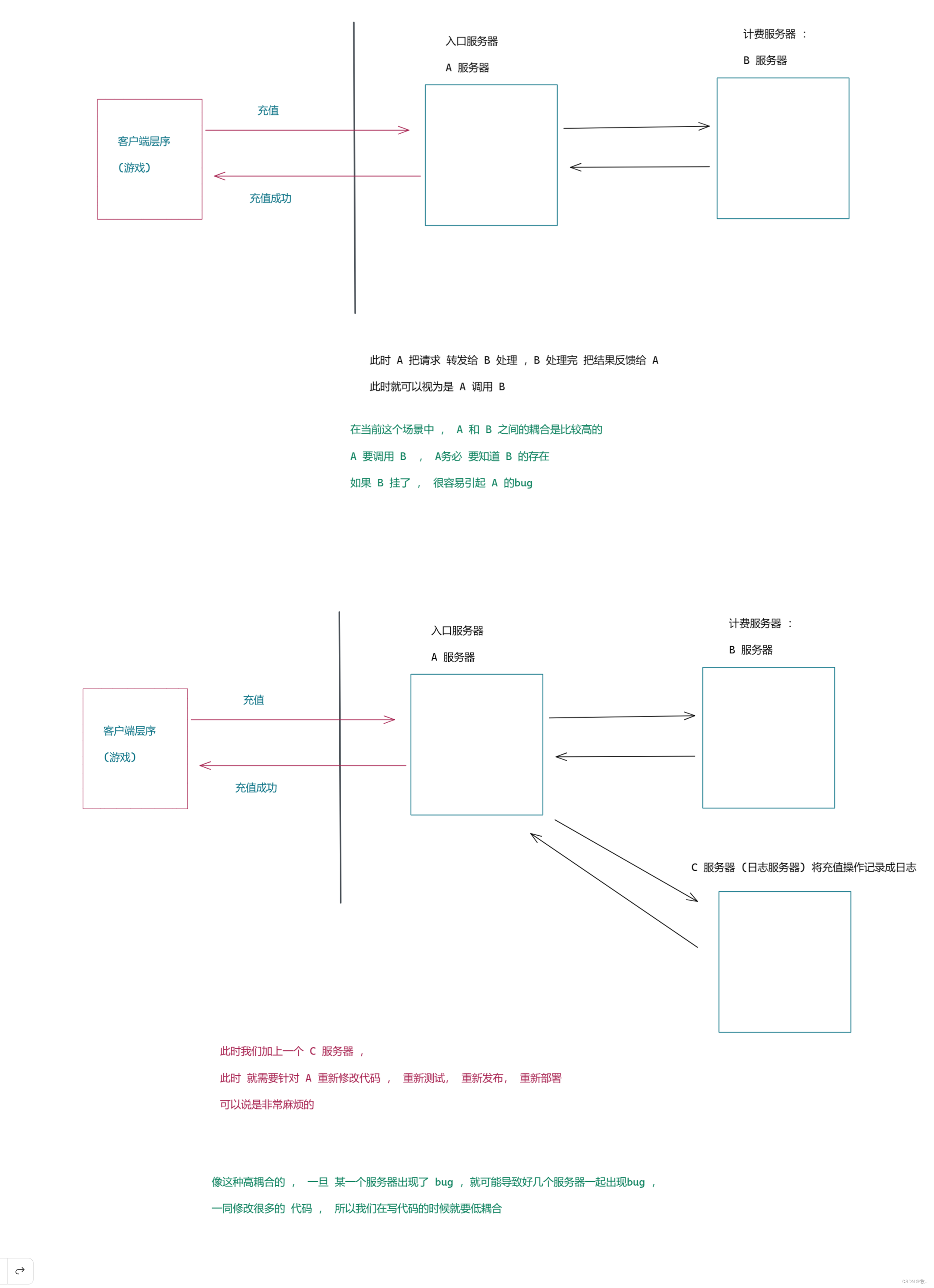
使用消费者生产者模型 ,进行降低耦合 .
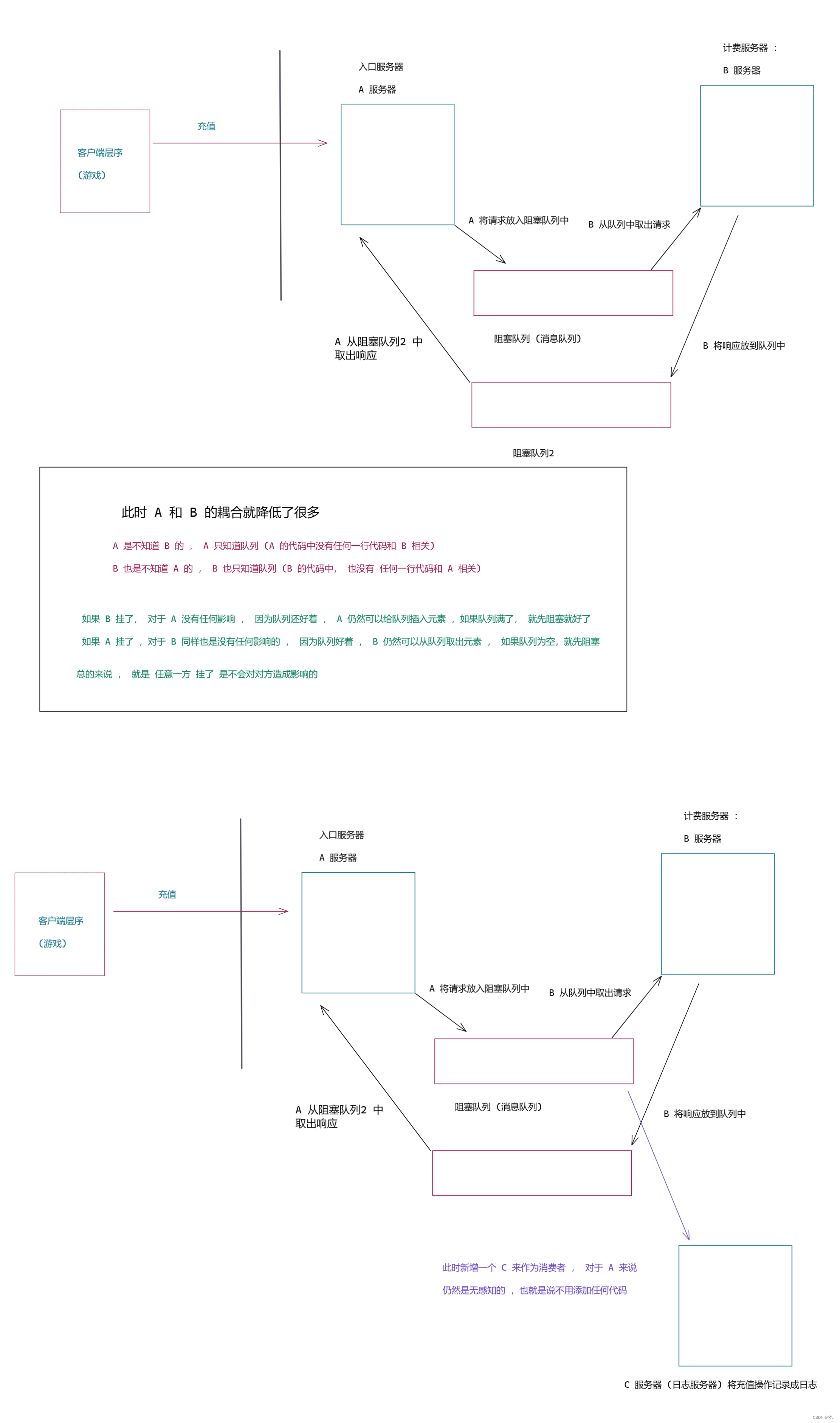
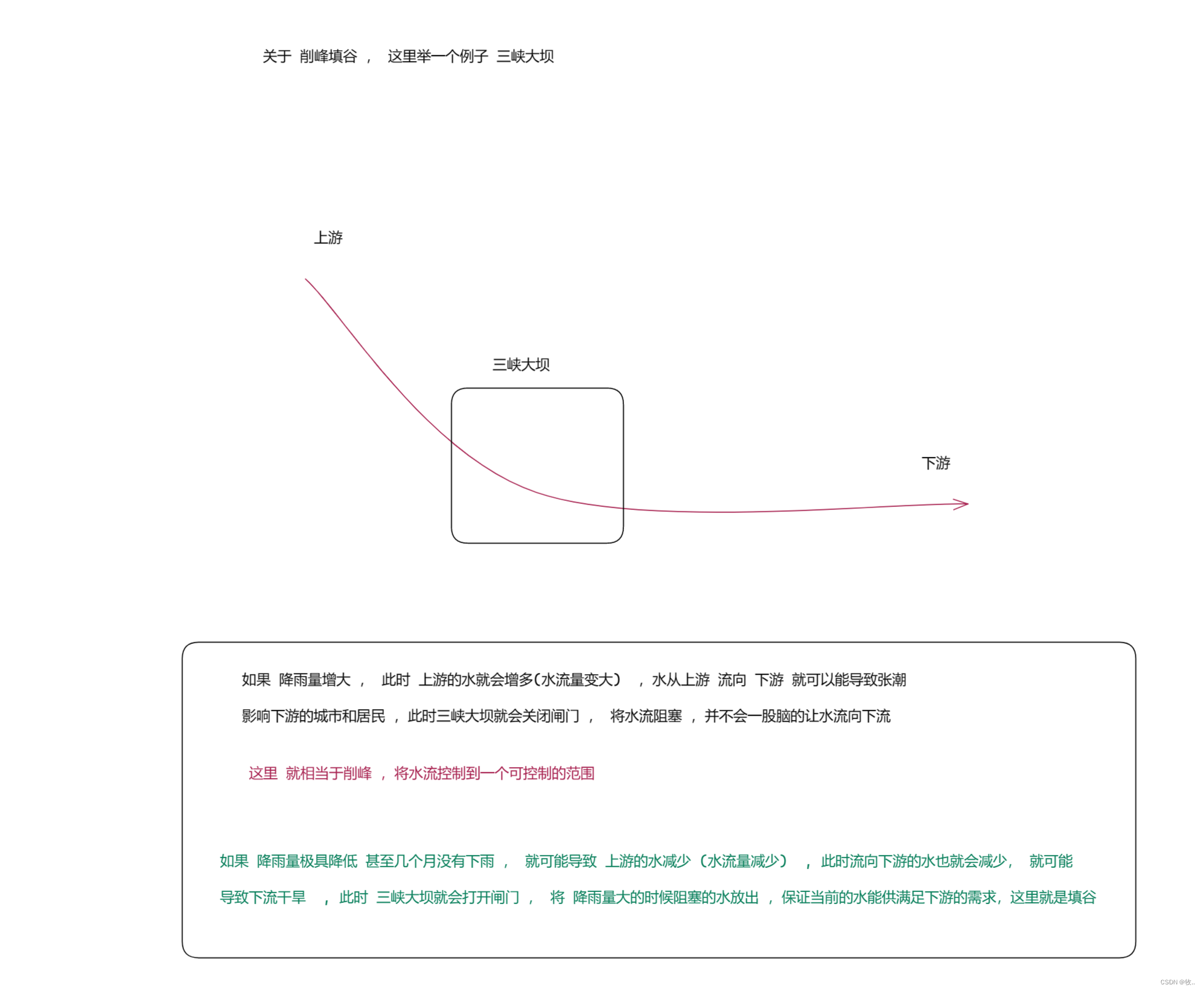
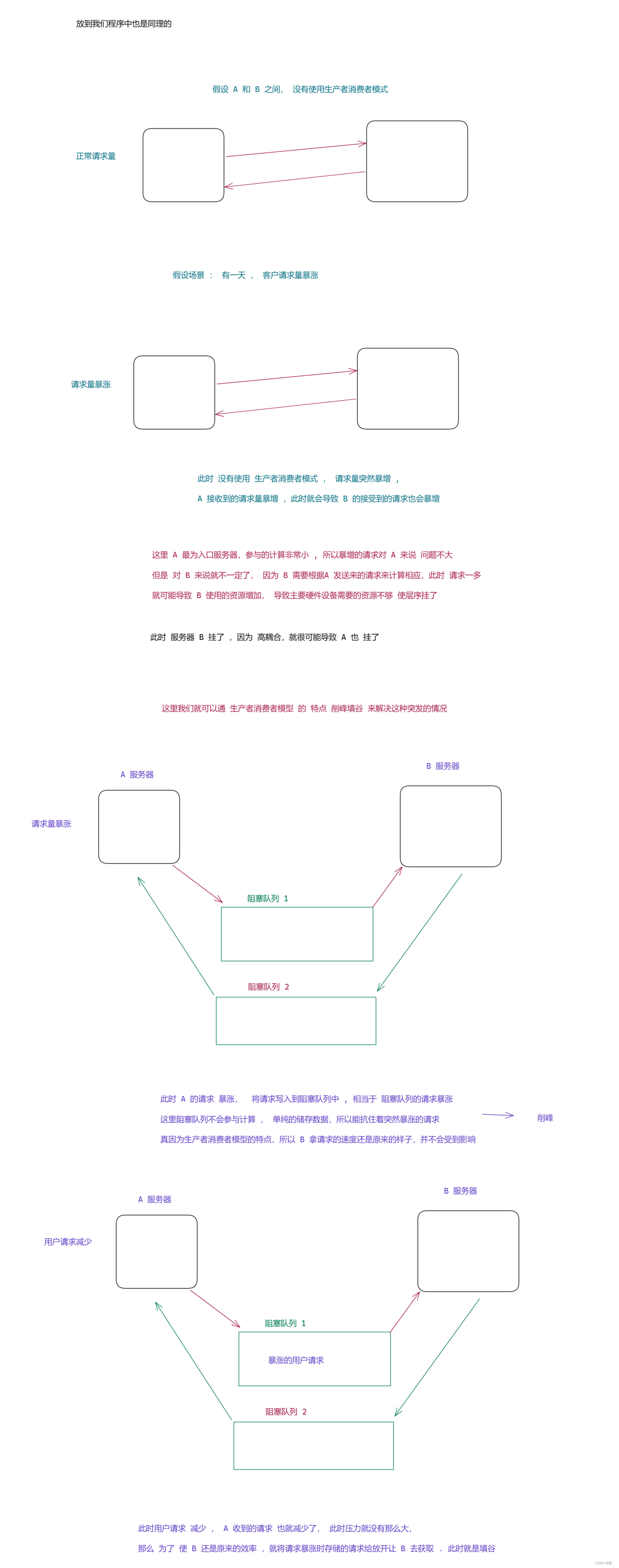
第一个好处 看完, 下面我们来了解一下第二个好处 : 削峰填谷 保证系统的稳定性
例子 :
理论知识就这些, 下面来通过代码来学习一下 ,阻塞队列
这里我们主要 通过两个方面来学习
1.会使用标准库提供的阻塞队列
2.会实现一个简单的阻塞队列
标准库中的阻塞队列

了解了上面这些, 我们就可以基于标准库的阻塞队列,写一个生产者消费者模型的代码了 .

附上代码 :
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();
// 创建两个线程, 来作为生产者和消费者
// 1. 消费者
Thread customer = new Thread(new Runnable() {
@Override
public void run() {
try {
while(true){
Integer result = blockingQueue.take();
System.out.println("消费元素 : " + result);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
// 2. 生产者
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
int count = 0;
while (true) {
try {
count++;
blockingQueue.put(count);
System.out.println("生产元素 : " + count);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
producer.start();
}
写完这个最简单的生产者消费者模型,相比对 阻塞队列因该有了比较清晰的认知,下面我们就来模式实现一个阻塞队列 .
这里为了简单直观 ,这里模拟实现的阻塞队列就不带上泛型, 直接使用 int 类型 .
准备工作 :

既然我们想要实现一个阻塞队列, 那么久需要先实现一个普通的队列 .
这个普通的队列, 我们可以基于数组 ,也可基于链表 .
其实在学习 数据结构时 , 就已经实现过了 : 队列-Queue
这里 基于链表实现比较简单, 如果感兴趣可以自行尝试 , 本文采用 基于数组实现 .
主要实现 :
class MyBlockingQueue {
private int[] items = new int[1000];
// 头
private int head = 0;
// 尾
private int tail = 0;
// 元素个数
private int size = 0;
// 入队列
public void put(int value) {
}
// 出队列
public Integer take() {
}
// 阻塞队列 无序提供获取队首元素的方法
}
下面动手实现 :
1.实现一个普通的队列
class MyBlockingQueue {
private int[] items = new int[1000];
// 头
private int head = 0;
// 尾
private int tail = 0;
// 元素个数
private int size = 0;
// 入队列
public void put(int value) {
if (size == items.length) {
// 队列满了 , 不能插入
return;
}
items[tail] = value;
tail++;
// 针对 tail 处理 两种做法
// 1. tail = tail % items.length
// 上面已经 tail++ ,所以 这里不是 +1 取膜
// 2.
if (tail >= items.length) {
tail = 0;
}
// 最后别忘了 了 size
size++;
}
// 出队列
public Integer take() {
if (size == 0) {
// 队列空不能出队列
return null;
}
int result = items[head];
head++;
if (head >= items.length) {
head = 0;
}
size--;
return result;
}
// 阻塞队列 无序提供获取队首元素的方法
}
public class Test {
public static void main(String[] args) {
MyBlockingQueue queue = new MyBlockingQueue();
queue.put(1);
queue.put(2);
queue.put(3);
queue.put(4);
int result = queue.take();
System.out.println("result = " + result);
result = queue.take();
System.out.println("result = " + result);
result = queue.take();
System.out.println("result = " + result);
result = queue.take();
System.out.println("result = " + result);
}
}
结果 :

2.普通队列实现完, 我们就可以加上wait 和 notify 来添加阻塞功能 .
另外 : 阻塞功能, 意味着 队列需要在多线程环境下使用 .
所以这里我们需要注意线程安全, 就需要加上锁操作 (使用 synchronized) .

写到这里我们自己的阻塞队列 算差不多完成了, 但是这里还有一点点小瑕疵 , 我们来修改一下

最总我们的代码 :
class MyBlockingQueue {
private int[] items = new int[1000];
// 头
private int head = 0;
// 尾
private int tail = 0;
// 元素个数
private int size = 0;
// 入队列
public void put(int value) throws InterruptedException {
synchronized (this) {
while (size == items.length) {
// 队列满了 , 不能插入
// return;
// 队列满了 ,插入元素阻塞等待
this.wait();
}
items[tail] = value;
tail++;
// 针对 tail 处理 两种做法
// 1. tail = tail % items.length
// 上面已经 tail++ ,所以 这里不是 +1 取膜
// 2.
if (tail >= items.length) {
tail = 0;
}
// 最后别忘了 了 size
size++;
// 此时队列添加元素, 不为空 ,可以唤醒为空时的
// 出队列的阻塞等待
this.notify();
}
}
// 出队列
public Integer take() throws InterruptedException {
synchronized (this) {
while (size == 0) {
// 队列空不能出队列
// return null;
// 队列为空想要出元素 就需要阻塞
this.wait();
}
int result = items[head];
head++;
if (head >= items.length) {
head = 0;
}
size--;
// 此时 相当于出了一个元素,那么队列满的时候阻塞就可以唤醒
this.notify();
return result;
}
}
// 阻塞队列 无需要提供获取队首元素的方法
}
下面针对我们自己的阻塞队列, 来使用 生产者消费者消费者模型 .
public class Test {
public static void main(String[] args) {
MyBlockingQueue queue = new MyBlockingQueue();
// 1. 生产者
Thread customer = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
while (true) {
Integer result = queue.take();
System.out.println("消费元素 : " + result);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
customer.start();
// 2. 生产者
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
int count = 0;
while (true) {
try {
count++;
queue.put(count);
System.out.println("生产元素 : " + count);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
producer.start();
}
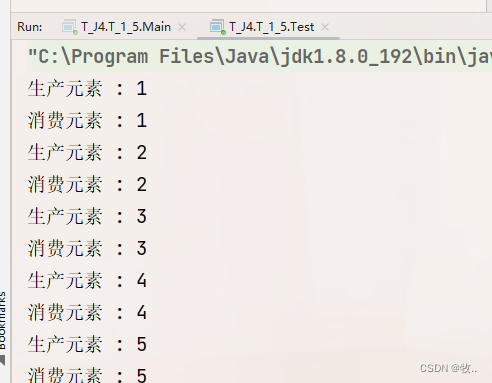
结果 :
阻塞队列看完,下面我们来 学习第三个案例,定时器 .
3. 定时器
定时器 就类似于闹钟 , 当过了指定时间段后,执行实现准备好的方法 / 代码 .
相当于 , 我要卷2个小时 ,然后去打游戏 ,过了2小时,此时就需要去打游戏了, 定时器就是这样。
另外 : 定时器也是开发中常用的组件 , 尤其是在网络编程中 , 比如我们在访问某个网站的时候,突然网不好,一直转圈圈,刷新不出页面,当转了一个指定的时间就会弹出网络不好的页面.这里相当于有一个等待的超时时间,当过了这个时间,就不会在等待了,直接返回一个访问失败,或网站不见了. 这里就运用了定时器 ,当执行超过某个时间,就返回错误信息。
这里定时器和阻塞队列类似,标准库 同样也给我们提供了 .
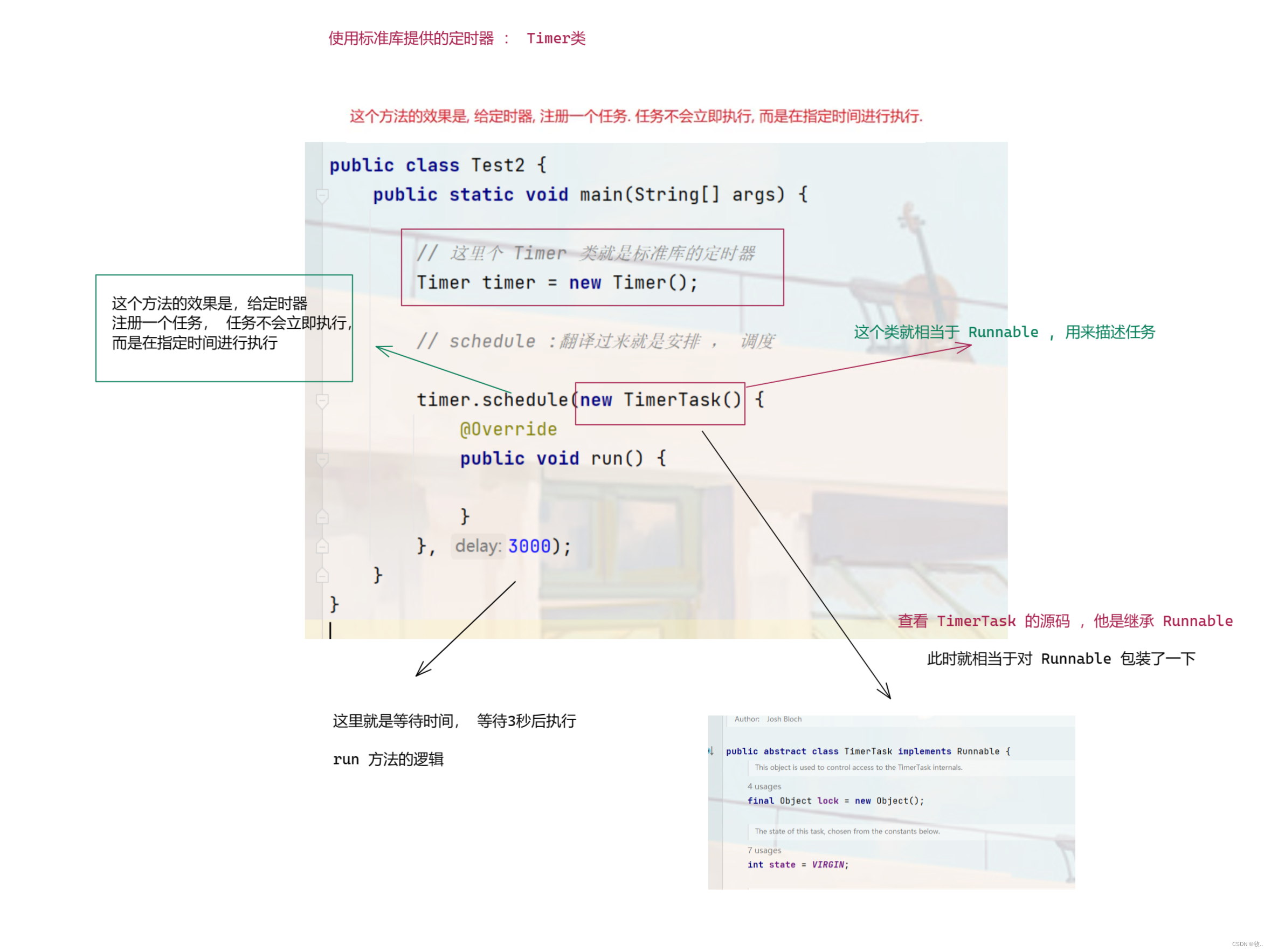
下面就来使用一下 :

使用完库里面的定时器,下面我们就来自己实现一个定时器 .
这里主要完成 一下两点
1.让被注册的任务 , 能够在指定时间, 被执行
2.一个定时器是可以注册 N 个任务的 , N个任务会按照最初约定的时间,按照顺序执行
实现 思路 :
1.单独在定时器内部, 弄一个线程,让这个线程周期性的扫描,判定任务是否到时间了,如果到时间了,就执行,没有到时间就在等等 .
2.既然我们需要注册 N 个任务,这里我们就需要使用一个数据结构来保存任务 , 周期的扫描 这个数据机构 , 那个任务时间到了,就执行那个任务。
这里的核心 就两点
1.有一个扫描的线程,负责判断时间是否到了(是否执行任务)
2.有一个存放任务的数据结构
那么大家想一想这个数据结构 我们要使用那个呢 ?
链表 , 哈希表 ,栈 , 队列 还是优先级队列呢 ?
仔细想一想 , 优先级队列是不是就是我们需要的 。
优先级队列, 存放我们的任务, 任务是有执行时间的, 这里时间越靠前 ,就越先执行 . 这里优先级队列(堆) 就可以采用最小堆 ,让时间最小的排在前面,此时扫
描就可以扫描队首元素, 不必要扫描整个队列了(最小堆 , 最小的放在根部,如果队首元素还没到执行时间内, 后续元素更不可能到时间)
另外 : 我们的优先级队列会在多线程环境下使用 ,很明显 ,调用 schedule 是一个线程, 扫描是另外一个线程 (两个线程都可能对我们的队列进行修改, 一个是入 一个是出),此时 我们就需要考虑线程安全问题 , 这里就可以采用加锁操作来保证线程安全 。
另外一种方法 : 我们也可以使用 标准库里面实现好的 PriorityBlockingQueue 带优先级的阻塞队列
分析完这么多 ,下面来看代码 :
主要逻辑

解决错误一 : 确定优先级

解决错误二 :忙等问题
忙等 : 简单来说 ,再原本要休息的时候 确没有休息到,还一直再干无意义的事情.
比如 泡面,泡面需要3分钟,但一直盯着泡面 ,此时泡面会提前煮开吗? 显然不会,有这三分钟 看泡面番不香吗 .
这里忙等 就会一直吃 cpu的资源,但不会做实际性的工作 , 虽然忙等 会浪费资源,但并不是忙等就是不好的, 再某些特定的场景下忙等可能就是一个好的 选着
下面就来,修改代码 , 让它不要进行忙等了,而是进行 阻塞式 等待
这里 就可以使用 sleep 或 wait 。
这里就有一个小问题 , 此时我们的等待需要等待多久呢 ?
举例 : 当前是 13:00 队首元素是 14 :00 此时就需要等待 1个小时 .
上面这个举例 ,我们能够明确的知道等待时间,那么是不是就使用sleep 呢 ?
答案是 不的, 因为我们这里只是举出了一个例子, 知道其中一个等待时间,如果此时再添加一个 13点 40 的任务呢 ? 此时队首元素是不是就是 13 点 40 的任务了(最小堆 ,会指定调整队首元素保证是最小的, 之前给定了比较规则,根据时间来进行比较) .
所以 使用 sleep 就不太合理, 这里就需要使用 wait() ,
我们使用 wait 可以说是非常方便的 , 因为wait 可以随时唤醒, 当有新的任务来时 (此时调用 schedule 添加新的任务) ,就可以通过 notify 唤醒一下,重新检查一下时间, 重新计算要等待的时间, 并且 wait 也提供了一个 带有 超时时间 的版本 .
这里带有超时时间 的wait 就可以保证
1.当新的任务来了,随时通过notify 唤醒
2.如果没有新任务,则最多等到之前旧任务中的最早任务时间到(队首 :任务的时间到了)就被唤醒
下面就来修改代码 :

此时 上面的两个问题解决了, 其实代码中还有一个比较严重的问题 。
这个问题 和 线程安全 / 随机调度 密切相关 :

附上代码 :
package T_J4.T_1_5;
import java.util.concurrent.PriorityBlockingQueue;
// 使用 这个类来表示 定时器中的任务
class MyTask implements Comparable<MyTask> {
// 要执行的任务
private Runnable runnable;
// 任务在啥时候执行 (使用毫秒级时间戳表示)
private long time;
public MyTask(Runnable runnable, long time) {
this.runnable = runnable;
this.time = time;
}
// 获取当前任务的时间
public long getTime() {
return time;
}
// 执行任务
public void run() {
runnable.run();
}
@Override
public int compareTo(MyTask o) {
return (int) (this.time - o.time);
}
}
class MyTimer {
// 扫描线程
private Thread t = null;
// 带阻塞功能的优先级队列 , 来保存任务
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
// 指定了两个参数 1. 任务内容 , 2. 任务在多少毫秒之后执行
public void schedule(Runnable runnable, long after) {
// 这里的 after 形如 1000 毫秒这样的, 这里就需要获取当前时间戳 加上这个多少秒后执行的时间
MyTask task = new MyTask(runnable, System.currentTimeMillis() + after);
// 将我们的任务放到 优先级队列中
queue.put(task);
synchronized (this) {
this.notify();
}
}
public MyTimer() {
t = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
// 1. 取出队首元素 ,检查队首元素任务是否到了时间(是否需要执行)
try {
synchronized (this) {
MyTask myTask = queue.take();
long curTime = System.currentTimeMillis();
if (curTime < myTask.getTime()) {
// 此时任务 还没到点, 先不执行
// 将任务重新放入 队列中
queue.put(myTask);
// 再 put 后 ,进行 一下 wait 操作 ,
this.wait(myTask.getTime() - curTime);
} else {
// 时间到了 执行任务
myTask.run();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
}
}
public class Test3 {
public static void main(String[] args) {
MyTimer myTimer = new MyTimer();
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("鸡哥");
}
}, 2000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("打篮球");
}
}, 1000);
}
}
看完了 定时器, 下面来看最后第一个代码案例,线程池 .
4.线程池
回忆一下 线程存在的意义 : 是不是因为使用进程来实现并发编程,太重了 (频繁创建销毁进程 ,开销比较大),此时就引入了 线程, 线程也叫做 轻量级进程 , 创建线程比创建进程更高效, 销毁线程比销毁进程更高效 , 调度线程比调度进程更高效 。
正因如此,使用多线程就可以再很多时候代替进程来实现并发编程 。
但是 随着并发程度的提高 ,随着我们对于性能要求标准的提高 , 此时发现 线程创建好像也没有那么轻量了 .
那么想要更进一步的提高这里的效率, 就有两种办法 :
1.搞一个 “轻量级线程” —> 协程 或者叫 纤程 这个东西,目前还没有被加入到 java 标准库中 ,这里不展开 。
在 Go 中就内置了 协程 , 因此Go开发并发编程程序就有一定的优势.
2.使用线程池来降低 创建/销毁的开销
线程池 就事先把需要使用的线程创建好 , 放到 池中 ,后面需要使用的时候 直接从池中获取 ,使用完后,不销毁直接放入池中 ,此时放和取的操作就比创建/销毁 更高效.
为啥将线程放入线程池和从线程池中获取线程的效率比创建线程和销毁线程高效呢?
这里就需要知道 操作系统中内核态和用户态的概念 。

概念看完 ,下面我们来使用一下java标准库为我们提供的线程池

构造出含有10个线程的线程池,下面我们就可以来安排这些线程来帮助我们干活 .
这里如何安排呢 ?
需要使用 线程池提供的一个重要的方法 submit , 使用 submit 方法,就可以给线程池提交诺干个任务 .

补充一点 :

到此就简单的了解到线程池最基本的使用,这里我们通过工厂方法,创建线程对象, 通过 submit往线程池中添加任务.
下面 我们就来看看 Executors 工厂类提供其他风格的线程池 .
图一 :
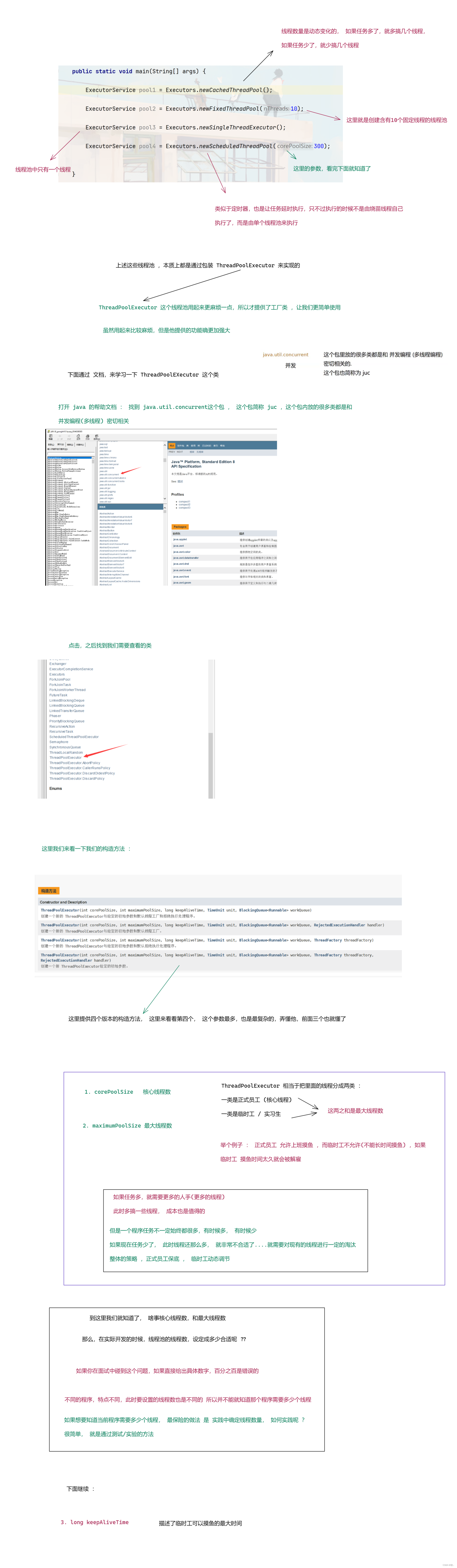
图二 :

到此,一些理论知识就了解完 了,下面来模拟实现一个简单的线程池
这里一个线程池,里面至少有两个大的部分
1.阻塞队列,保存任务
2.诺干个工作线程

附上代码 :
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
class MyThreadPoll {
// 此处不涉及到 时间
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
// n 表示线程的数量
public MyThreadPoll(int n) {
// 在构造方法中创建处线程 ---> 创建 n 个线程, 每个线程的 run 方法会取出任务 执行任务
for (int i = 0; i < n; i++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
}
}
// 注册任务给线程池
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class Test6 {
public static void main(String[] args) {
MyThreadPoll pool = new MyThreadPoll(10);
for (int i = 0; i < 1000; i++) {
int n = i;
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("任务执行序号 : " + n);
}
});
}
}
}
到此 关于多线程的几个代码案例就完成了 .
下文预告 : 关于多线程的一些面试题 + 不太常用的多线程的组件…