本笔记资料来源于 http://www.ai-start.com/ml2014/,该笔记来自于https://blog.csdn.net/dadapongi6/article/details/105668394,看了忘,忘了看,再看一遍。
时间统计:2024.2.29 5个番茄钟,从week1开始,看完了week5反向传播算法。
week1
特征缩放是什么?
week3
http://www.ai-start.com/ml2014/html/week3.html
线性回归和逻辑回归是同一个算法吗?
线性回归是回归任务;
逻辑回归是logistic regression是2分类,是一个分类任务。在线性回归后又加了一个sigmoid函数,把线性回归的值映射到0-1之间。
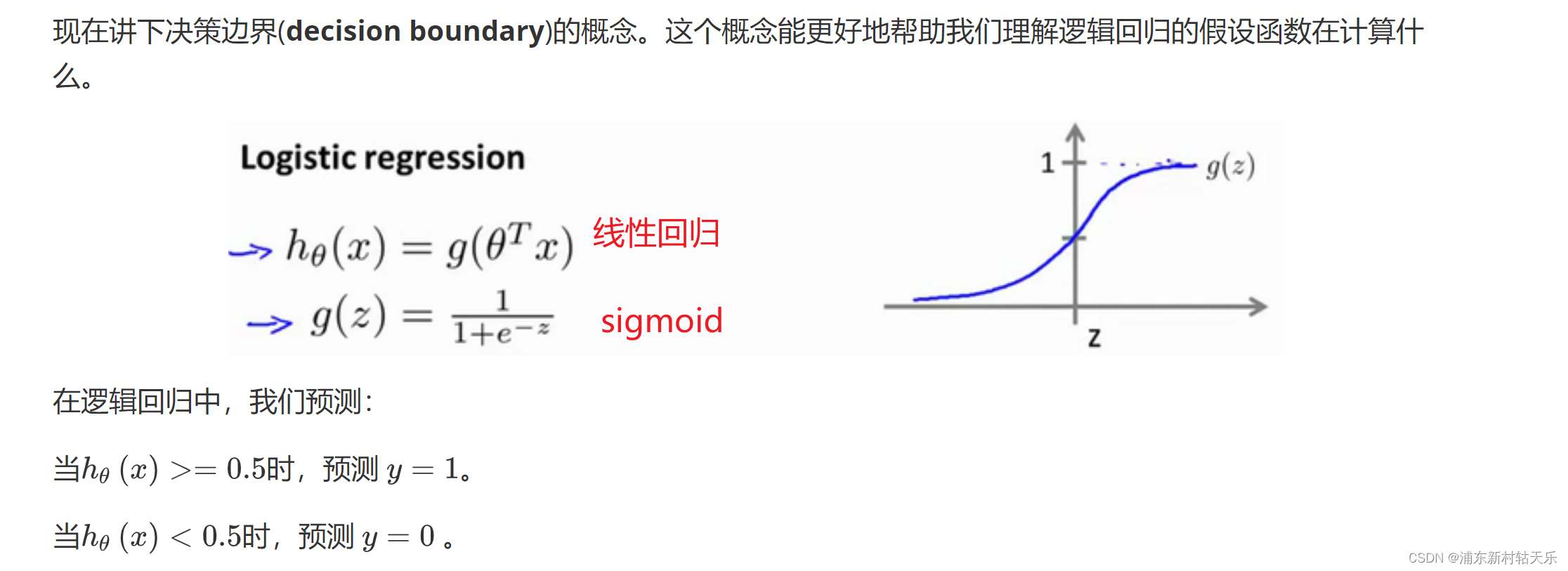
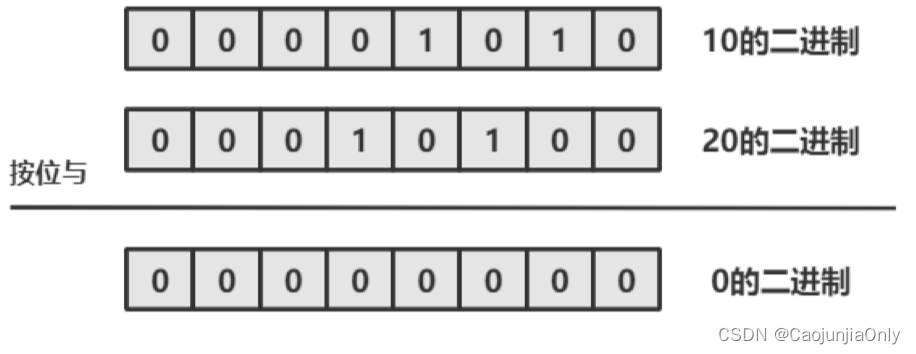
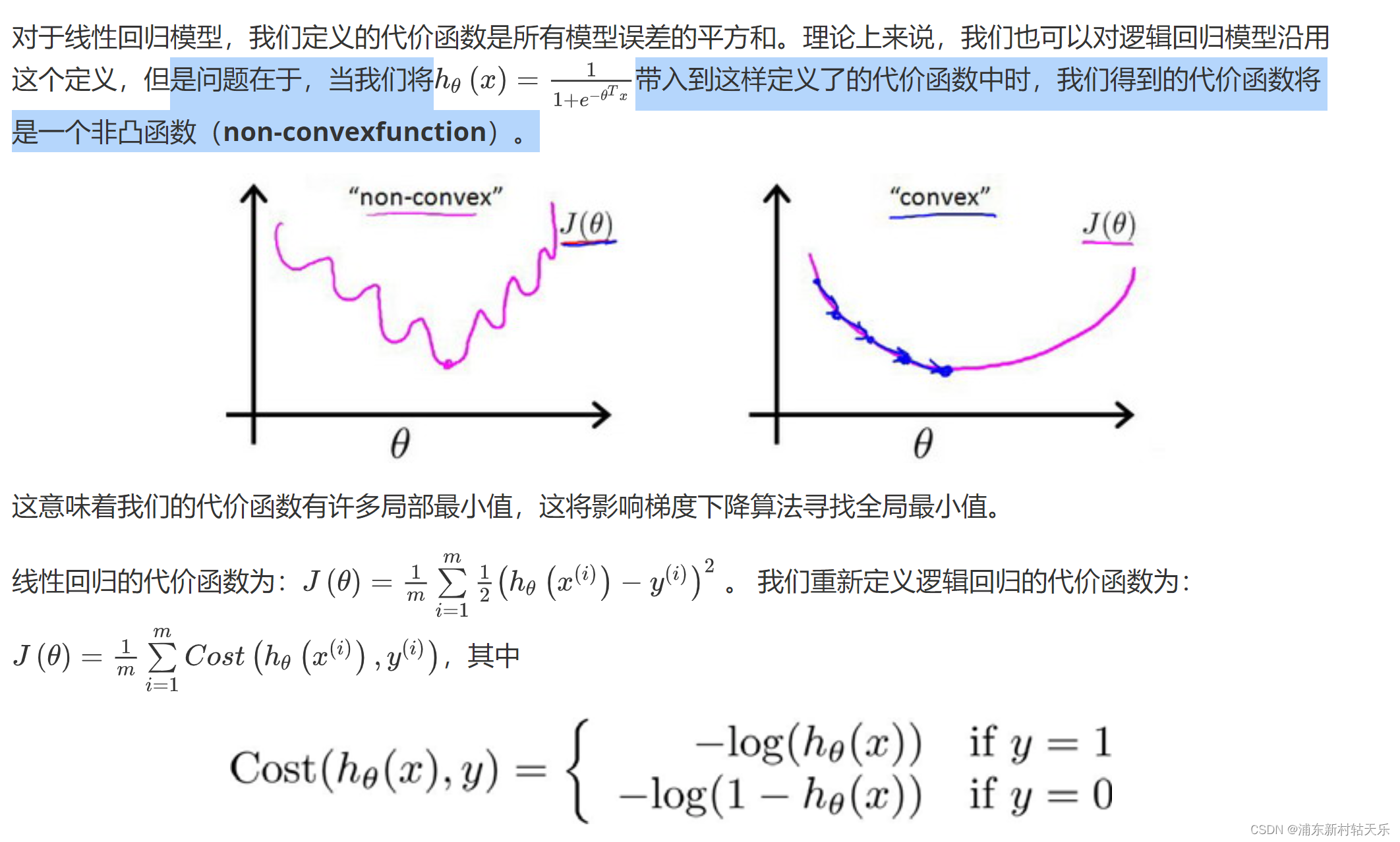
代价函数为什么不使用误差的平方和,而是使用交叉熵?
这个图太形象了,使用误差的平方和会让loss函数是非凸的,导致loss函数会有很多局部最小值!
正则化为什么可以防止过拟合?
防止参数过大。

week4
神经网络的矩阵参数含义
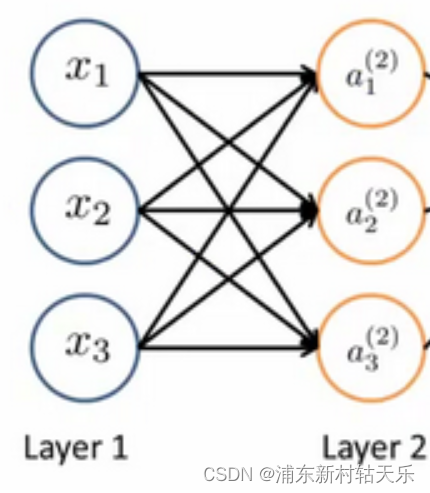
假设一个神经网络输入x是3维向量,输出a是10维向量,则神经网络的矩阵W就是(10x3),也就是神经网络的参数量
a=Wx。如下图所示,每个神经元跟输入的所有神经元都建立了连接。
由此可见,单纯的神经元线性层确实只是线性变换。
神经网络相比线性回归和逻辑回归的优势是什么?
隐藏层的输出表示更高维度的feature,相对于输入表达的更多。

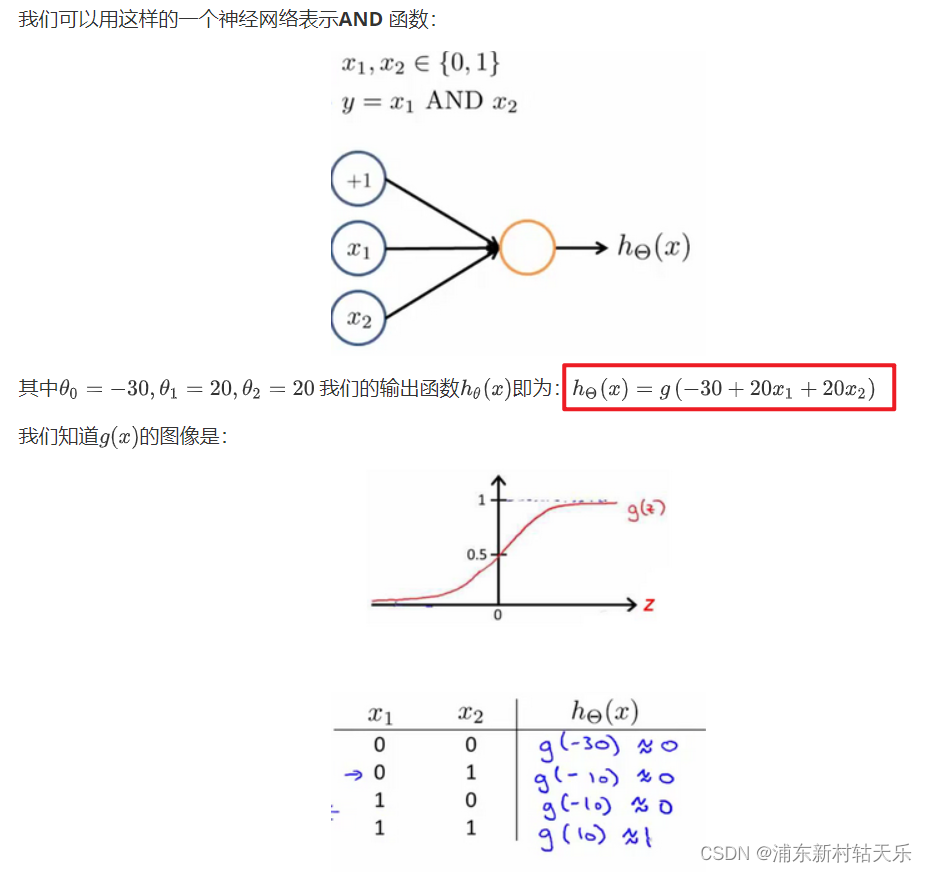
神经网络表示and or 非 同或(XNOR)
这个是真牛逼,我就想不到。当你神经网络是一个函数,对于一个and函数来说,它的输入就是2维的x1,x2,所以这个线性网络只需要三个参数。
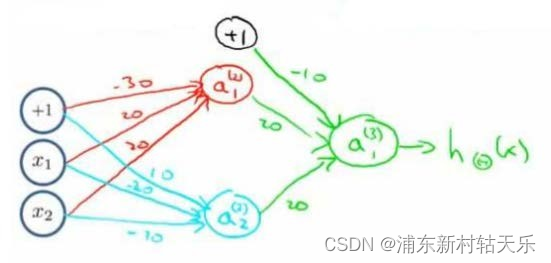
同或XNOR表示
多分类输出,有多少个类别,就输出多少个神经元,最后神经元的真值是onehot向量。
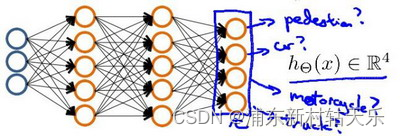
week5
训练神经网络的流程
- 参数的随机初始化
- 利用正向传播方法计算所有的h(x)
- 编写计算代价函数Loss的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
反向传播算法(直观理解,吴恩达视频讲解)比较清晰。
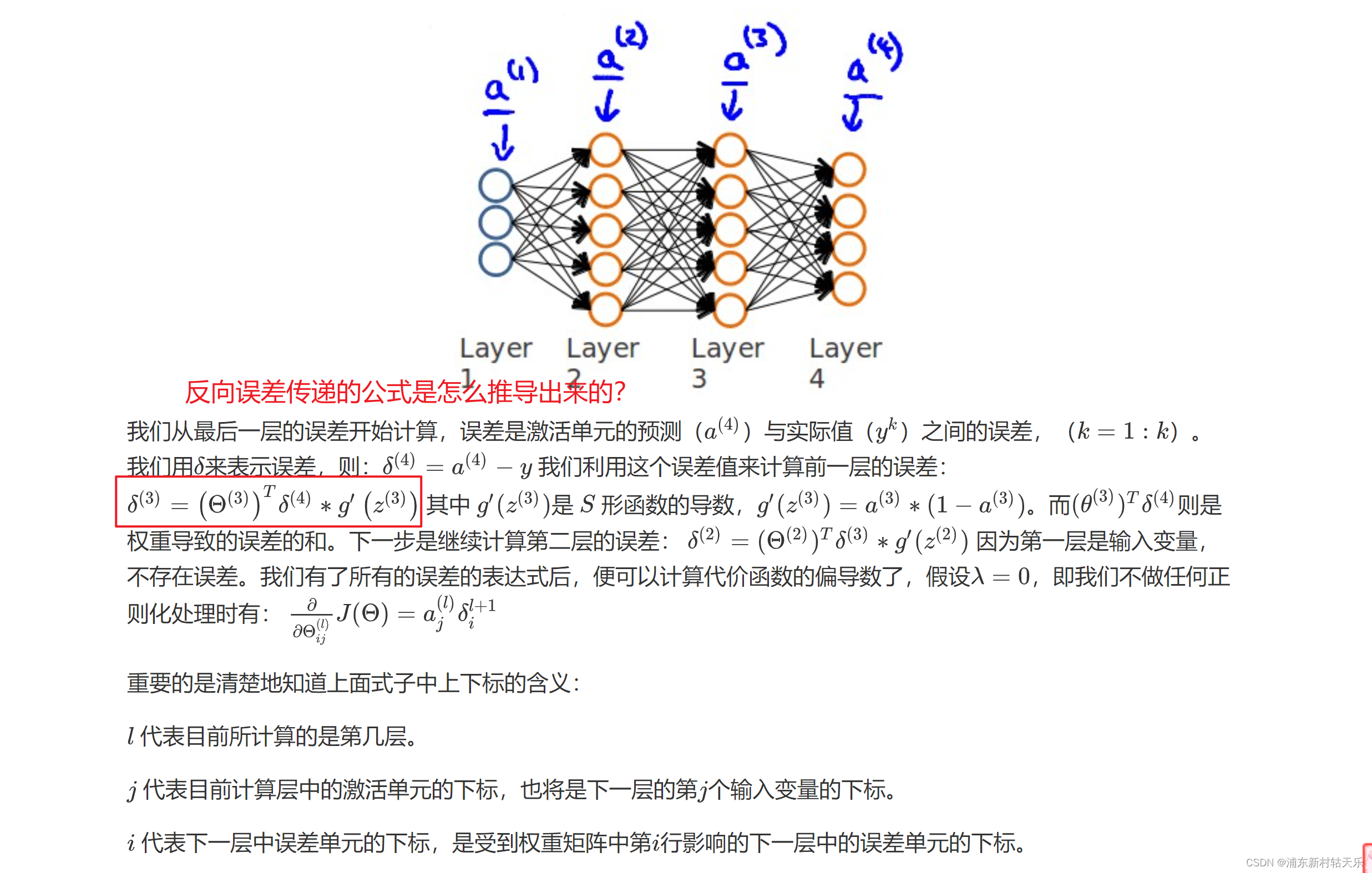
什么是反向传播算法?误差从最后一层,一层层往前传播;而前向传播指的是输入的数据,从前往后一层层往后传播,误差的传递公式看下图,其实就是梯度反传?
sigmoid函数求导 f’(x) = f(x)*(1-f(x))
问题1 反向传播公式怎么推导出来的?
吴恩达老师说自己了解也不是很深入,但是不影响他使用。大家也是一样,不用太纠结。
从反向传播公式中可以看出loss的反向传播用到了上一层的梯度。
问题2 神经网络参数初始化不能为0?
为0的话会导致第二层所有激活值都是零。
week6
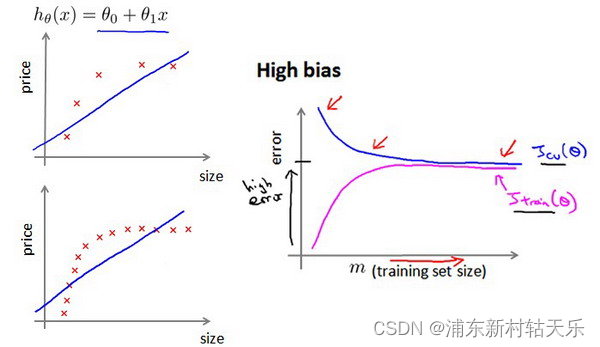
怎么判断欠拟合和过拟合?
随着训练次数的增加,训练集和验证集的loss趋于相同,且都比较大 。
欠拟合的情况下,增加数据到训练集不一定能有帮助。 比如用一个直线方程去拟合曲线方程,无论怎么增加数据都是没用的。
过拟合加数据肯定有用。
如何选择网络
选择比较大的神经网络并采用正则化的方法,要比采用小的神经网络更好。因为小的网络容易欠拟合,而大的网络可以通过正则化适应数据。
![[Vulnhub]靶场 Web Machine(N7)](https://img-blog.csdnimg.cn/direct/30f354c080344a68a49895887216bf89.png)