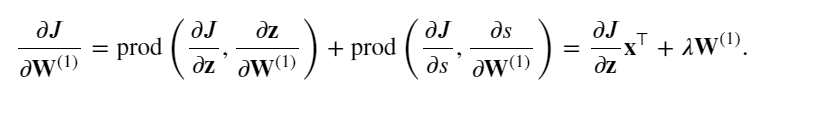最后一部分了,要开始进行我们的训练了。
先上代码:
import os
import numpy as np
from tqdm import tqdm
import tensorflow as tf
from thetwo import NeuralStyleTransferModel
import theone
import thethree
#创建模型
model=NeuralStyleTransferModel()
#加载内容图片
content_image= thethree.load_images(theone.CONTENT_IMAGE_PATH)
#风格图片
style_image= thethree.load_images(theone.STYLE_IMAGE_PATH)
#计算出内容图片的内容特征备用
target_content_features = model([content_image,])['content']
target_style_features = model([style_image, ])['style']
M= theone.WIDTH * theone.HEIGHT
N=3
def _compute_content_loss(noise_features,target_features):
"""
计算指定层上两个特征之间的内容loss
:param noise_features: 噪声图片在指定层的特征
:param target_features: 内容图片在指定层的特征
:return:
"""
content_loss=tf.reduce_sum(tf.square(noise_features - target_features))
#计算系数
x=2.*M*N
content_loss=content_loss/x
return content_loss
def compute_content_loss(noise_content_features):
"""
计算当前图片的内容loss
:param noise_content_features:噪声图片的内容特征
:return:
"""
#初始化内容损失
content_losses=[]
#加权计算内容损失
for(noise_feature,factor),(target_feature,_) in zip(noise_content_features,target_content_features):
layer_content_loss=_compute_content_loss(noise_feature,target_feature)
content_losses.append(layer_content_loss*factor)
return tf.reduce_sum(content_losses)
def gram_matrix(feature):
"""
计算给定特征的格拉姆矩阵
:param feature:
:return:
"""
#先交换维度,把channel维度提到最前面
x=tf.transpose(feature,perm=[2,0,1])
#reshape,压缩为2d
x=tf.reshape(x,(x.shape[0],-1))
#计算x和x的逆的乘积
return x@tf.transpose(x)
def _compute_style_loss(noise_feature,target_feature):
"""
计算指定层上的两个特征之间的风格损失
:param noise_feature: 噪声图片在指定层的特征
:param target_feature: 风格图片在指定层的特征
:return:
"""
noise_gram_matrix=gram_matrix(noise_feature)
style_gram_matrix=gram_matrix(target_feature)
style_loss=tf.reduce_sum(tf.square(noise_gram_matrix-style_gram_matrix))
x=4.*(M**2)*(N**2)
return style_loss/x
def compute_style_loss(noise_style_features):
"""
计算并返回图片的风格loss
:param noise_style_features:噪声图片的风格特征
:return:
"""
style_losses=[]
for(noise_feature,factor),(target_feature,_) in zip(noise_style_features,target_style_features):
layer_style_loss = _compute_style_loss(noise_feature,target_feature)
style_losses.append(layer_style_loss*factor)
return tf.reduce_sum(style_losses)
def total_loss(noise_features):
"""
计算总损失
:param noise_features: 噪声图片特恒数据
:return:
"""
content_loss=compute_content_loss(noise_features['content'])
style_loss=compute_style_loss(noise_features['style'])
return content_loss* theone.CONTENT_LOSS_FACTOR+style_loss* theone.STYLE_LOSS_FACTOR
optimizer=tf.keras.optimizers.Adam(theone.LEARNING_RATE)
noise_image=tf.Variable((content_image + np.random.uniform(-0.2, 0.2, (1, theone.HEIGHT, theone.WIDTH, 3))) / 2)
@tf.function
def train_one_step():
"""
一次迭代过程
:return:
"""
#求loss
with tf.GradientTape() as tape:
noise_outputs = model(noise_image)
loss = total_loss(noise_outputs)
#求梯度
grad = tape.gradient(loss,noise_image)
#梯度下降,更新噪声图片
optimizer.apply_gradients([(grad,noise_image)])
return loss
#创建保存生成图片的文件夹
if not os.path.exists(theone.OUTPUT_DIR):
os.mkdir(theone.OUTPUT_DIR)
#共训练theone.EPOCHS个epoch
for epoch in range(theone.EPOCHS):
#使用tqdm提示训练进度
with tqdm(total=theone.STEPS_PER_EPOCH, desc='EPOCH{}/{}'.format(epoch + 1, theone.EPOCHS)) as pbar:
#每个epoch训练theone.STEPS_PER_EPOCH次
for step in range(theone.STEPS_PER_EPOCH):
_loss=train_one_step()
pbar.set_postfix({'loss':'%.4f'%float(_loss)})
pbar.update(1)
#每个epoch保存一次图片
thethree.save_image(noise_image, '{}/{}.jpg'.format(theone.OUTPUT_DIR, epoch + 1))
下面我们来分析代码:
model=NeuralStyleTransferModel() #加载内容图片 content_image= thethree.load_images(theone.CONTENT_IMAGE_PATH) #风格图片 style_image= thethree.load_images(theone.STYLE_IMAGE_PATH) #计算出内容图片的内容特征备用 target_content_features = model([content_image,])['content'] target_style_features = model([style_image, ])['style'] M= theone.WIDTH * theone.HEIGHT N=3
先看第一部分,也可以说是准备工作。
model=NeuralStyleTransferModel()
首先,我们创建了一个神经风格迁移的实例对象,也就是我们之前定义的类模型,负责处理风格迁移的相关工作,主要是加载与训练集。
content_image= thethree.load_images(theone.CONTENT_IMAGE_PATH)
接下来,我们加载我们的数据,也就是图像,这里我们使用的是我们自定义的函数,参数是图片路径。这个函数(我们自定义的加载图片函数)包含了对图片进行处理等操作。
style_image= thethree.load_images(theone.STYLE_IMAGE_PATH)
同时,我们也要加载风格图片。
target_content_features = model([content_image,])['content']
将内容图片的变量作为参数传递给模型,调用call函数进行处理,返回的是字典,其中包含两个键值对,键分别是content和style。而在代码中我们指定的是content,即输出处理后得到的不同类型的特征。这些内容特征通常会在后序的神经风格迁移中用到,用于调整生成图片的内容以匹配院士图片的内容。
同理,
target_style_features = model([style_image, ])['style']
我们也提取了风格图片的特征。
M= theone.WIDTH * theone.HEIGHT N=3
M和N用于后序的计算中,N是通道数。
def _compute_content_loss(noise_features,target_features):
"""
计算指定层上两个特征之间的内容loss
:param noise_features: 噪声图片在指定层的特征
:param target_features: 内容图片在指定层的特征
:return:
"""
content_loss=tf.reduce_sum(tf.square(noise_features - target_features))
#计算系数
x=2.*M*N
content_loss=content_loss/x
return content_loss
作用是计算指定层上两个特征之间的内容损失,接受的参数就是指定层上的特征,(噪声图片和内容图片)。
content_loss=tf.reduce_sum(tf.square(noise_features - target_features))
这段代码是计算内容损失的核心部分。参数noise_features和target_features是通过某种深度学习模型(很明显是卷积神经网络)在指定层次上提取的特征表示。
tf.square:计算了噪声图片特征与目标图片特征之间的差值,并将差值的每个元素取平方,然后通过td.reduce_sum()函数来进行求和,作为损失。
x = 2.0 * M * N content_loss = content_loss / x
这段代码是计算一个归一化系数即尺寸*通道数,再*2是为了增加一个权重因子,以调整损失的量级,使其更适合当前的优化目标。这种调整可以根据具体的任务和数据集来确定,以便更好的平衡损失的大小与优化过程的效率。
通常情况下,损失函数的值越小越好,因为我们的优化目标通常是将损失最小化,但是有时候,如果损失值过小,可能会导致数值不稳定或者优化过程变得过于敏感,通过乘以一个适当的权重因子,可以调整损失的量级,使其更适合当前的优化过程。
content_loss = content_loss / x这一计算时将损失除以归一化系数,使其不受图像尺寸和通道数的影响,从而更好的用于神经风格迁移的优化过程。
def compute_content_loss(noise_content_features):
"""
计算当前图片的内容loss
:param noise_content_features:噪声图片的内容特征
:return:
"""
#初始化内容损失
content_losses=[]
#加权计算内容损失
for(noise_feature,factor),(target_feature,_) in zip(noise_content_features,target_content_features):
layer_content_loss=_compute_content_loss(noise_feature,target_feature)
content_losses.append(layer_content_loss*factor)
return tf.reduce_sum(content_losses)
for (noise_feature,factor),(target_feature,_)in zip(noise_content_features,target_content_features):
迭代噪声图片的内容特征和目标图片的内容特征,这两个特征在创建模型的call函数里面就已经论述过提取方法了。
layer_content_loss=_compute_content_loss(noise_feature,target_feature) content_losses.append(layer_content_loss*factor)
调用函数来计算其中的损失,并通过和权重进行相乘,添加到内容损失列表中。权重因子是用来调整每个层级对总体内容损失的贡献度,通过内容损失加权,更好控制了每个层级对整体损失的影响程度。
return tf.reduce_sum(content_losses)
我们将列表中所有元素进行求和,得到一个标量值,表示了当前图片的总的内容损失。
def gram_matrix(feature):
"""
计算给定特征的格拉姆矩阵
:param feature:
:return:
"""
#先交换维度,把channel维度提到最前面
x=tf.transpose(feature,perm=[2,0,1])
#reshape,压缩为2d
x=tf.reshape(x,(x.shape[0],-1))
#计算x和x的逆的乘积
return x@tf.transpose(x)
这段代码用于计算给定特征的格拉姆矩阵,参数是一个表示特征的张量。
x=tf.transpose(feature,perm=[2,0,1])这一行将特征张量的维度进行重新排列,将通道维度移动到最前面,参数perm=[2,0,1]表示将原始特征张量的通道维度(索引为2)放到最前面,其余维度保持不变。
x=tf.reshape(x,(x.shape[0],-1))
操作是将x张量进行重塑,x.shape[0]是取出张量x在第一个维度上的大小,通常表现的是批处理的大小。
这段代码的作用是将张量x重新塑造为一个二维张量,其中,第一个维度大小保持不变,即与原来张量的第一个维度大小相同(通常是指批处理的大小),而第二个维度则被设置为-1,这使得TensorFlow能够自动计算出第二个维度的大小。即剩下所有元素拉伸为单一的维度。这种操作通常用于准备特征张量以进行后续的矩阵运算或神经网络层的输入。
最后
return x@tf.transpose(x)
这段代码使用transpose函数来转置张量x,然后执行矩阵乘法操作。(两个维度是默认交换行和列的位置)。
在Python3.5以及以上的版本中@符号表示的是矩阵乘法操作,所以这一部分表示张量x与它的转置相乘。结果得到的是格拉姆矩阵,在神经网络中,格拉姆矩阵(Gram Matrix)用于捕捉特征之间的相关性,它的每个元素表示了相应特征之间的内积,从而反映它们之间的相似度和共同激活程度。
def _compute_style_loss(noise_feature,target_feature):
"""
计算指定层上的两个特征之间的风格损失
:param noise_feature: 噪声图片在指定层的特征
:param target_feature: 风格图片在指定层的特征
:return:
"""
noise_gram_matrix=gram_matrix(noise_feature)
style_gram_matrix=gram_matrix(target_feature)
style_loss=tf.reduce_sum(tf.square(noise_gram_matrix-style_gram_matrix))
x=4.*(M**2)*(N**2)
return style_loss/x
定义计算风格损失函数,接受的参数是噪声图片在指定层的特征和风格图片在指定层的特征。
noise_gram_matrix=gram_matrix(noise_feature)格拉姆矩阵是用来衡量特征之间相关性的重要工具,通常用于计算风格损失,在风格迁移中,格拉姆矩阵捕捉了特征之间的相关性和共同激活程度,从而反映了风格的特征。这段代码的意思是将给定特征张量表示转化为格拉姆矩阵的形式,计算特征之间的相关性。
同理,下一句是将风格图片的特征张量转化为格拉姆矩阵。
然后计算表示噪声图片的格拉姆矩阵和表示风格图片的格拉姆矩阵之间的平方差。
归一化系数x,这里很明显是计算内容损失系数的平方,这个系数的计算是基于格拉姆矩阵的形式,格拉姆矩阵的计算设计特征之间的内积,这意味着其值与特征的数量有关。很明显,获得的风格损失矩阵是相比内容损失矩阵的二维拉伸,所以用于归一的系数也要二维拉伸。
同样我们返回归一化后的结果。
def compute_style_loss(noise_style_features):
"""
计算并返回图片的风格loss
:param noise_style_features:噪声图片的风格特征
:return:
"""
style_losses=[]
for(noise_feature,factor),(target_feature,_) in zip(noise_style_features,target_style_features):
layer_style_loss = _compute_style_loss(noise_feature,target_feature)
style_losses.append(layer_style_loss*factor)
return tf.reduce_sum(style_losses)
进行各层的风格损失汇总,类似于内容损失。
def total_loss(noise_features):
"""
计算总损失
:param noise_features: 噪声图片特恒数据
:return:
"""
content_loss=compute_content_loss(noise_features['content'])
style_loss=compute_style_loss(noise_features['style'])
return content_loss* theone.CONTENT_LOSS_FACTOR+style_loss* theone.STYLE_LOSS_FACTOR
计算总损失,content_loss=compute_content_loss(noise_features['content'])调用compute-content_loss函数计算总损失。下句同理。
返回的是将内容损失和风格损失加权之后求和的结果。
optimizer=tf.keras.optimizers.Adam(theone.LEARNING_RATE)
开始定义优化器喽:使用TensorFlow创建一个Adam优化器对象,Adam是一种常用的优化算法,使用羽于训练神经网络和深度学习模型。
在TensorFlow中,通过tf.keras.optimizers模块可以访问各种优化器,Adam优化器是一种自适应学习率优化算法,它能够在训练过程中自动调整学习率。参数是优化器的学习率,学习率决定了每次参数更新时所应用的步长大小,这通常是神经网络模型中事先定义好的超参数。
noise_image=tf.Variable((content_image + np.random.uniform(-0.2, 0.2, (1, theone.HEIGHT, theone.WIDTH, 3))) / 2)
这段代码创建一个TensorFlow变量noise_image,将其随机初始化为一个噪声图像,该图像是基于图像content_image而生成的。
np.random.uniform(-0.2, 0.2, (1, theone.HEIGHT, theone.WIDTH, 3))是一个NumPy函数调用,用于生成一个指定范围内均匀分布的随机数组,其形状为(1,theone.HEIGHT,theone.WIDTH,3)。
(-0.2,0.2)指定了随机数的范围,在这个例子中,随机数是从范围-0.2(包含)到0.2(不包含)之间的。数组中的元素是在-0.2到0.2之间的均匀分布的随机数,这个数组通常用于图像的随机噪声,用于引入一些随机性以便于训练模型。
@tf.function
def train_one_step():
"""
一次迭代过程
:return:
"""
#求loss
with tf.GradientTape() as tape:
noise_outputs = model(noise_image)
loss = total_loss(noise_outputs)
#求梯度
grad = tape.gradient(loss,noise_image)
#梯度下降,更新噪声图片
optimizer.apply_gradients([(grad,noise_image)])
return loss
这是神经风格迁移算法中的一次迭代过程。
@tf.function
是TensorFlow中的装饰器,用于将Python函数转化为TensorFlow计算图的一部分,以便提高计算效率。被@tf.function修饰的函数被编译为TensorFlow图,以便进行更有效的计算。
with tf.GradientTape() as tape:
这是TensorFlow中用于计算梯度的上下文管理器。在这个上下文中的操作会被记录下来,以便后序计算梯度。tf.GrandientTape()创建了一个新的梯度带,梯度带的作用是跟踪TensorFlow操作执行过程中所涉及的所有可训练变量的操作,并且能根据这些操作计算相对于这些变量的梯度。
with语句用于创建一个上下文环境,在这个环境中,所有的操作都会被记录在梯度带tape中,当退出这个上下文环境时,梯度带tape将被释放,其中的操作记录也将被删除,这样可以节省内存并提到效率。
noise_outputs = model(noise_image)
是得到噪声图像的输出,类型为字典,其中包括内容输出和风格输出。
loss = total_loss(noise_outputs)
用来计算总损失。
grad = tape.gradient(loss,noise_image) #梯度下降,更新噪声图片 optimizer.apply_gradients([(grad,noise_image)]) return loss
grad = tape.gradient(loss,noise_image)
这行代码计算损失loss相对于噪声图片noise_image的梯度,在上下文的梯度带中,我们使用tape记录了计算损失的过程,以便TensorFlow能够自动计算相对于noise_image的梯度。
optimizer.apply_gradients([(grad,noise_image)])
这是TensorFlow中用于应用梯度下降步骤的方法,优化器会根据计算得到的梯度来更新模型参数,以使损失函数尽可能小。[(grad,noise_image)]是一个由梯度-变量对构成的列表,每个对都是一个元组,其中包含了要应用的梯度和相应的变量。在这里,(grad,noise_image)表示要将梯度grad应用于变量noise_image上。当调用apply_gradients()方法时,优化器会使用梯度下降算法或者其他优化算法,根据给定的梯度更新相应变量的值。这个过程是优化模型参数的关键步骤,它使模型能够逐渐的优化损失函数,提高模型的性能和准确性。
return loss
最后返回计算得到的损失值,以便在训练过程中进行监控和记录。
if not os.path.exists(theone.OUTPUT_DIR):
os.mkdir(theone.OUTPUT_DIR)
#共训练theone.EPOCHS个epoch
for epoch in range(theone.EPOCHS):
#使用tqdm提示训练进度
with tqdm(total=theone.STEPS_PER_EPOCH, desc='EPOCH{}/{}'.format(epoch + 1, theone.EPOCHS)) as pbar:
#每个epoch训练theone.STEPS_PER_EPOCH次
for step in range(theone.STEPS_PER_EPOCH):
_loss=train_one_step()
pbar.set_postfix({'loss':'%.4f'%float(_loss)})
pbar.update(1)
#每个epoch保存一次图片
thethree.save_image(noise_image, '{}/{}.jpg'.format(theone.OUTPUT_DIR, epoch + 1))
if not os.path.exists(theone.OUTPUT_DIR):
os.mkdir(theone.OUTPUT_DIR)
代码首先检测是否存在指定的输出目录,如果不存在该目录,则使用os.mkdir函数创建该目录,这个目录用于 保存训练过程中生成的图片。
with tqdm(total=theone.STEPS_PER_EPOCH, desc='EPOCH{}/{}'.format(epoch + 1, theone.EPOCHS)) as pbar:
tqdm()函数用于创建一个进度条,用于显示训练进度。total参数设置了进度条的总步数。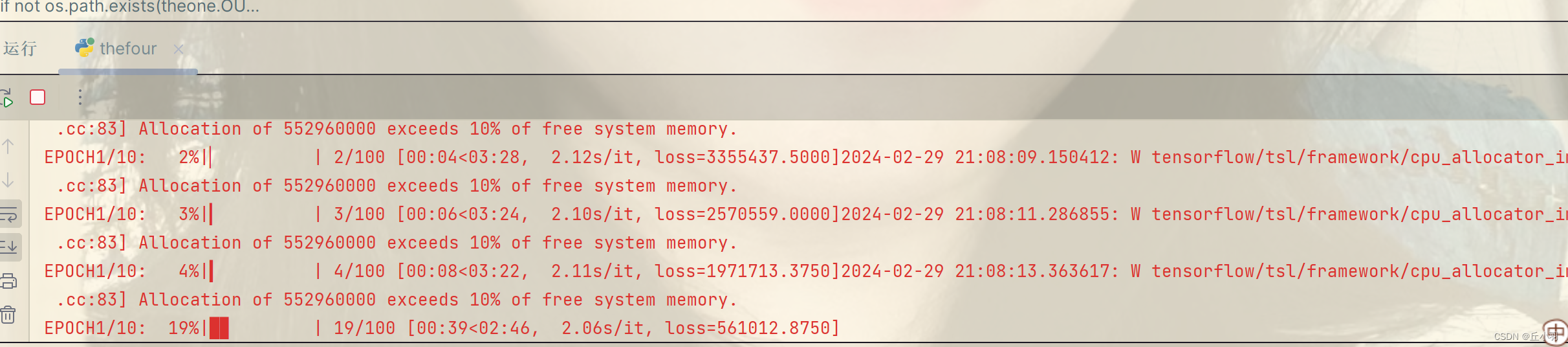
desc参数设置了进度条的描述,格式化字符串'EPOCH{}/{}'.format(epoch+1,theone.EPOCHS)显示当前EPOCH序号和epoch的数量。
for step in range(theone.STEPS_PER_EPOCH):
_loss=train_one_step()
pbar.set_postfix({'loss':'%.4f'%float(_loss)})
pbar.update(1)
进一步观察内部循环:
_loss=train_one_step()
进行了一步模型参数的更新。
pbar.set_postfix()方法更新了进度条的后缀,在这里,将损失值_loss格式化为四位小数,并将其作为进度条后缀,以便在训练过程中实时监控损失值变化。
之后使用pbar.update(1)的方法更新进度条,表示完成了当前的训练步骤,进度条的进度增加1。
最后一步了:
thethree.save_image(noise_image, '{}/{}.jpg'.format(theone.OUTPUT_DIR, epoch + 1))
!!!
使用thethree.save_image来保存生成的图片,该函数中有对张量转化为图像的操作,第二个参数是文件名,文件的路径是创建的文件夹下面加上轮数。







![基于51单片机的心率血压体温检测系统[proteus仿真]](https://img-blog.csdnimg.cn/direct/60d7f9d236c7413ab0e32ce0e2eddae8.png)