1.Sora简介
Sora是一个基于大规模训练的文本控制视频生成扩散模型。 Sora能够生成高达1分钟的高清视频,涵盖广泛的视觉数据类型和分辨率。 Sora使用简单的文本描述,使得视频创作变得前所未有的简单和高效。
Sora的一些能力:
- Text-to-video: 文生视频
- Image-to-video: 图生视频
- Video-to-video: 改变源视频风格or场景
- Extending video in time: 视频拓展(前后双向)
- Create seamless loops: Tiled videos that seem like they never end
- Image generation: 图片生成 (size最高达到 2048 x 2048)
- Generate video in any format: From 1920 x 1080 to 1080 x 1920 视频输出比例自定义
- Simulate virtual worlds: 链接虚拟世界,游戏视频场景生成
- Create a video: 长达60s的视频并保持人物、场景一致性
2.Sora模型训练
2.1 Sora技术报告
原文链接:https://openai.com/research/video-generation-models-as-world-simulators
Video generation models as world simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. **Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.**
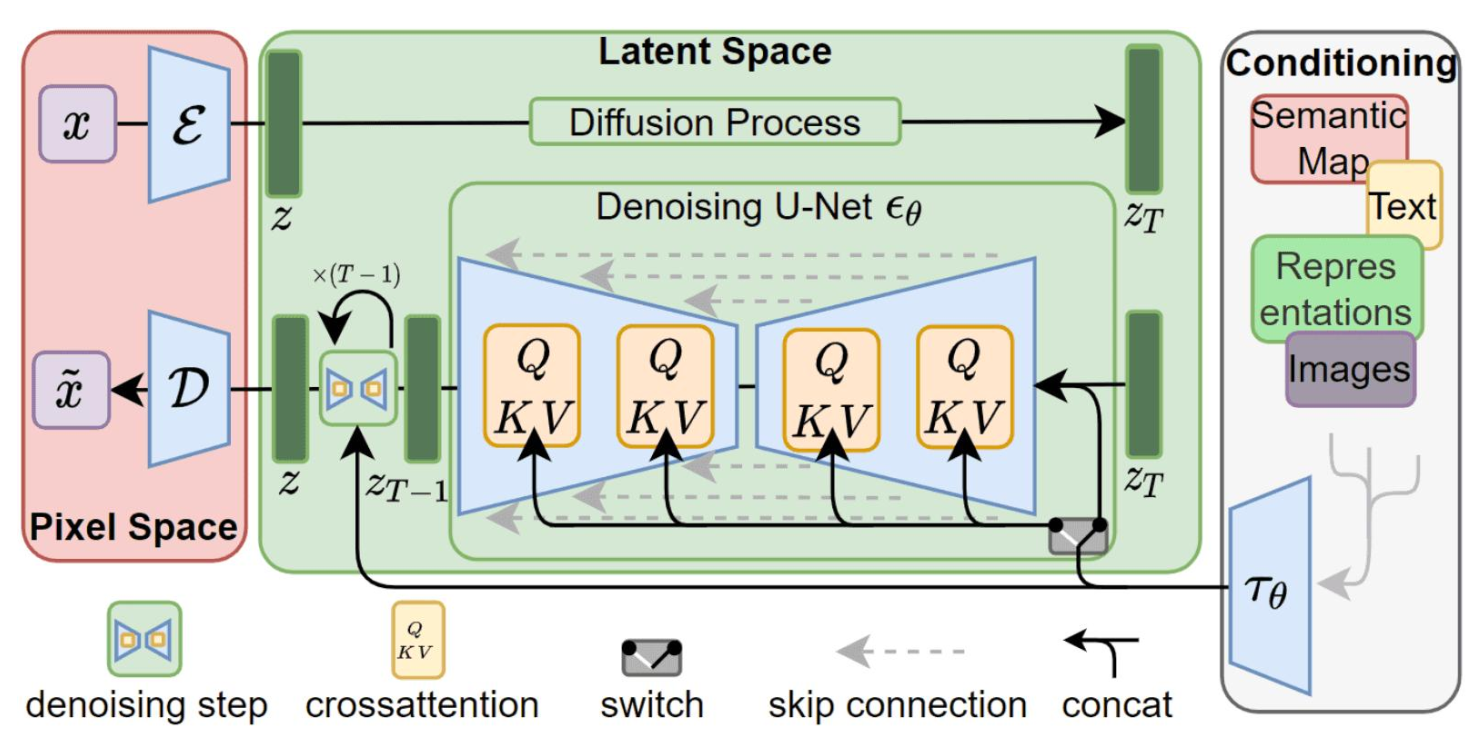
2.2 模型训练流程
- 原始视频数据被切分为 Pathes,通过VAE编码器压缩成低维空间表示;
- 基于 Diffusion Transformer 完成从文本语义到图像语义的再映射;
- DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据。
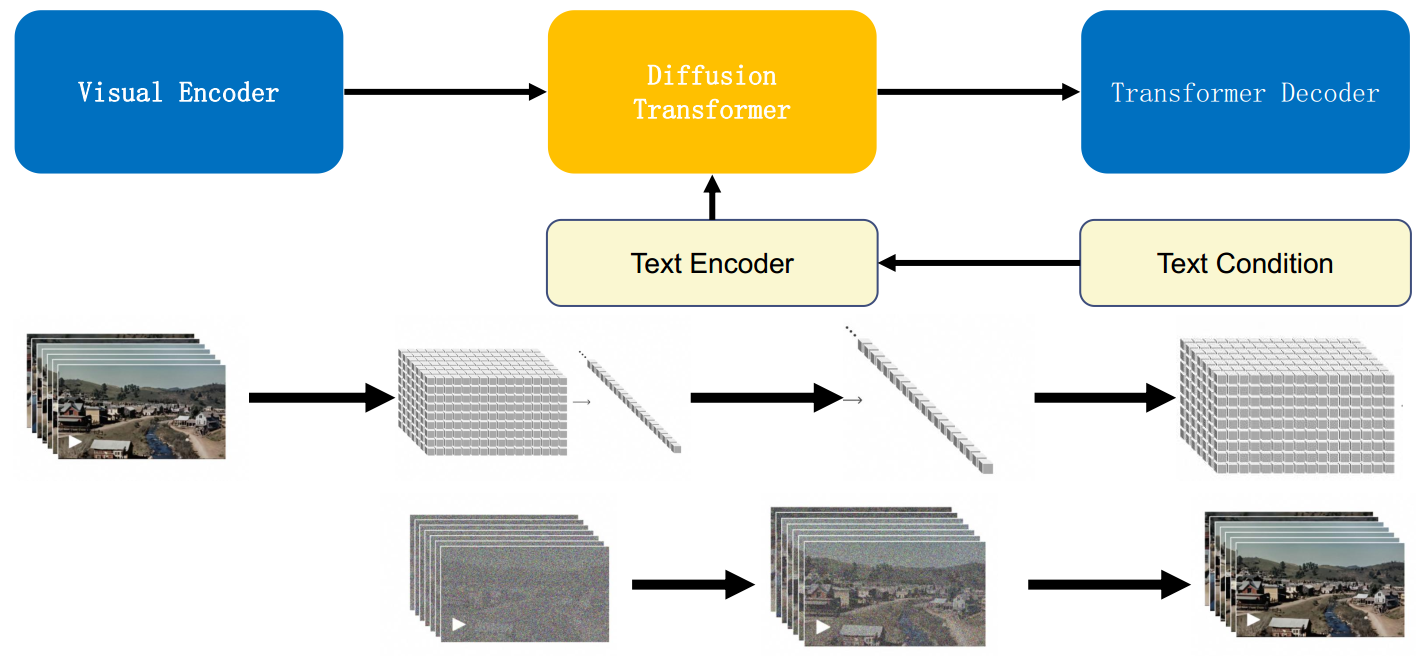
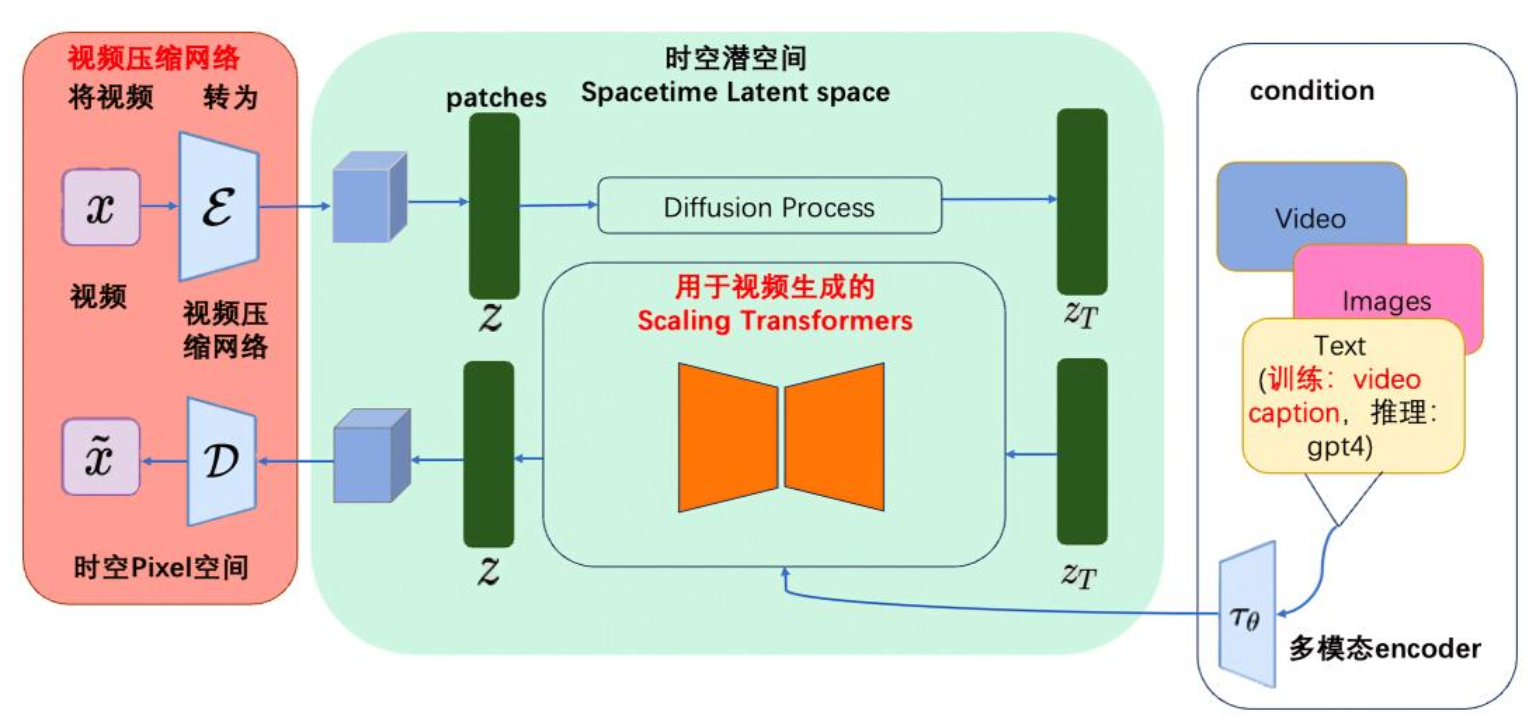
2.3 视频数据统一表示(Transforming Visual Data into Patches)
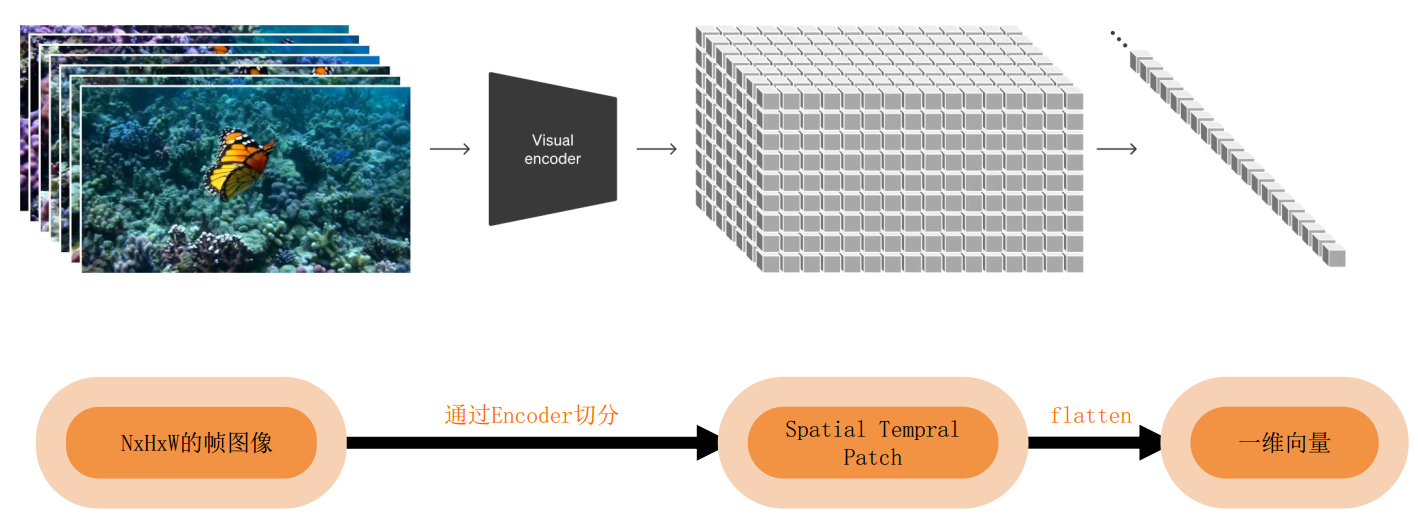
Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模型,同时采用了Transformer架构

2.4 扩散模型DDPM
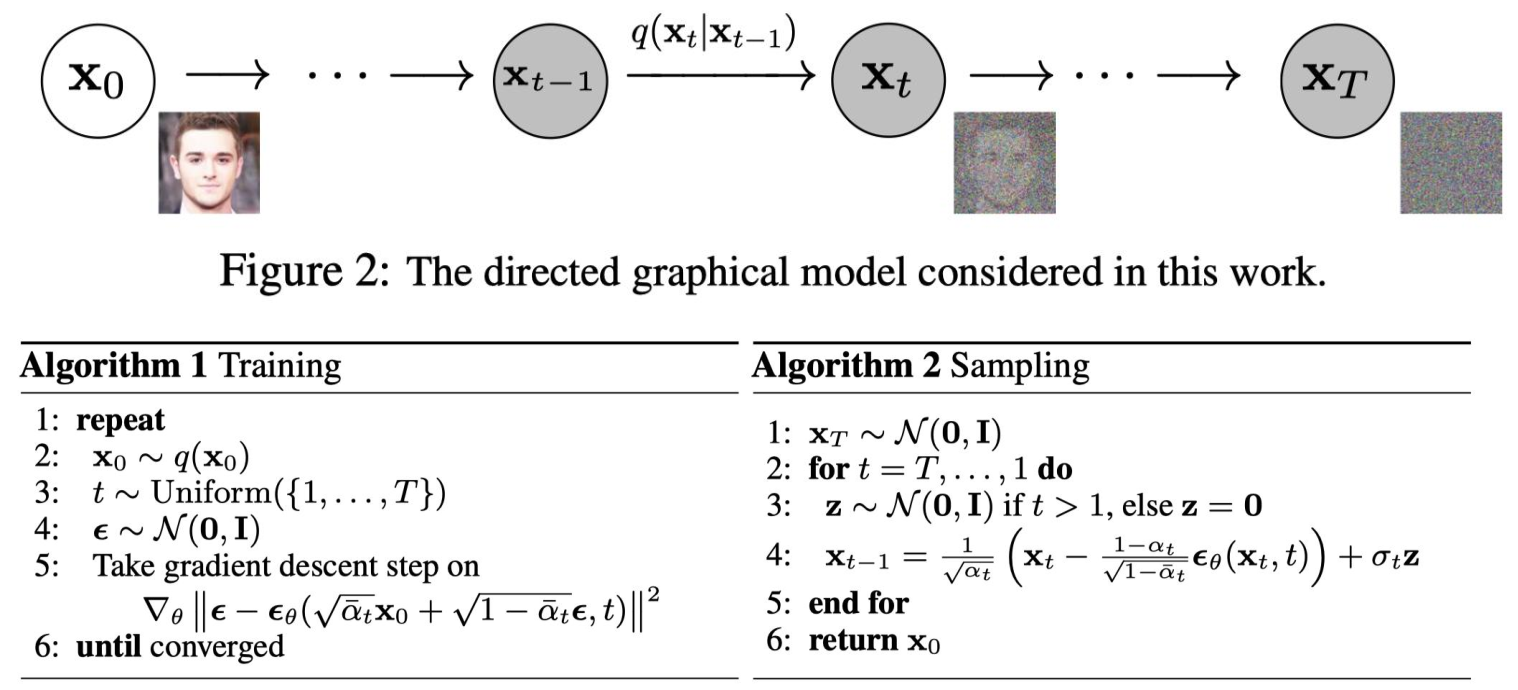
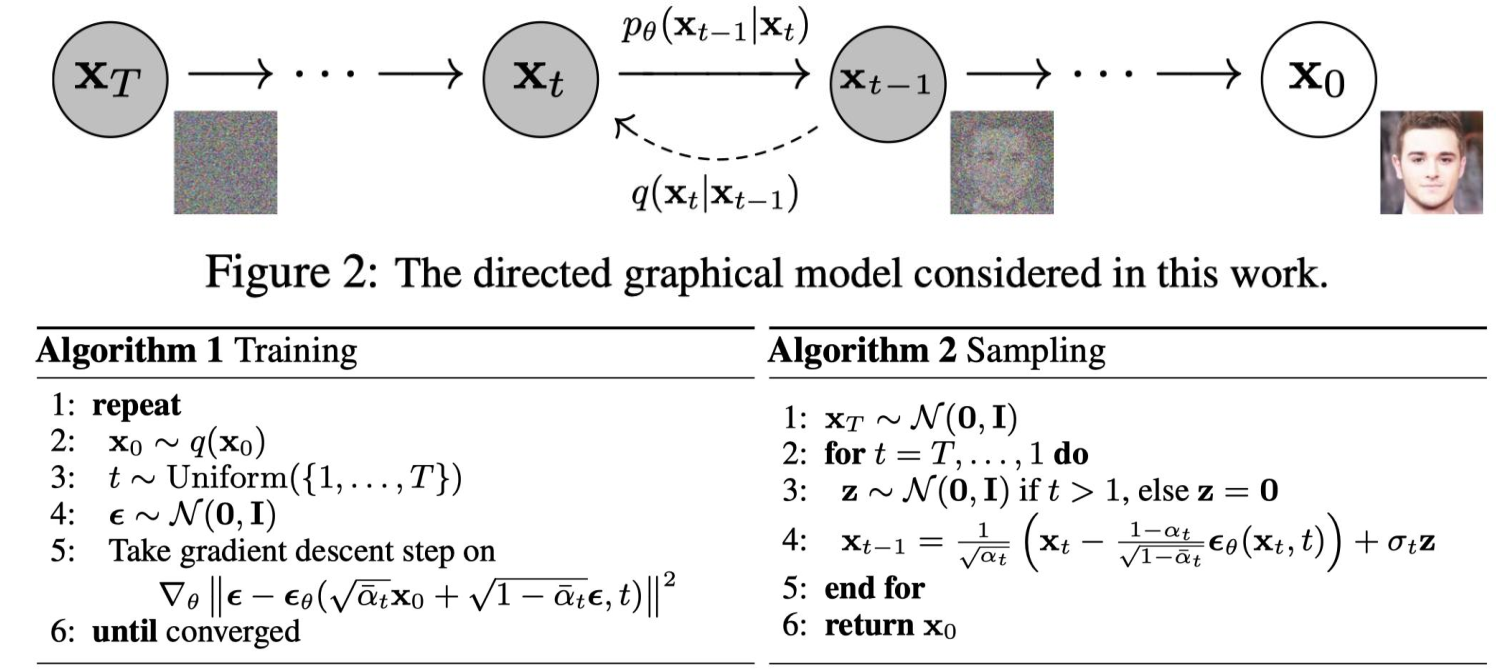
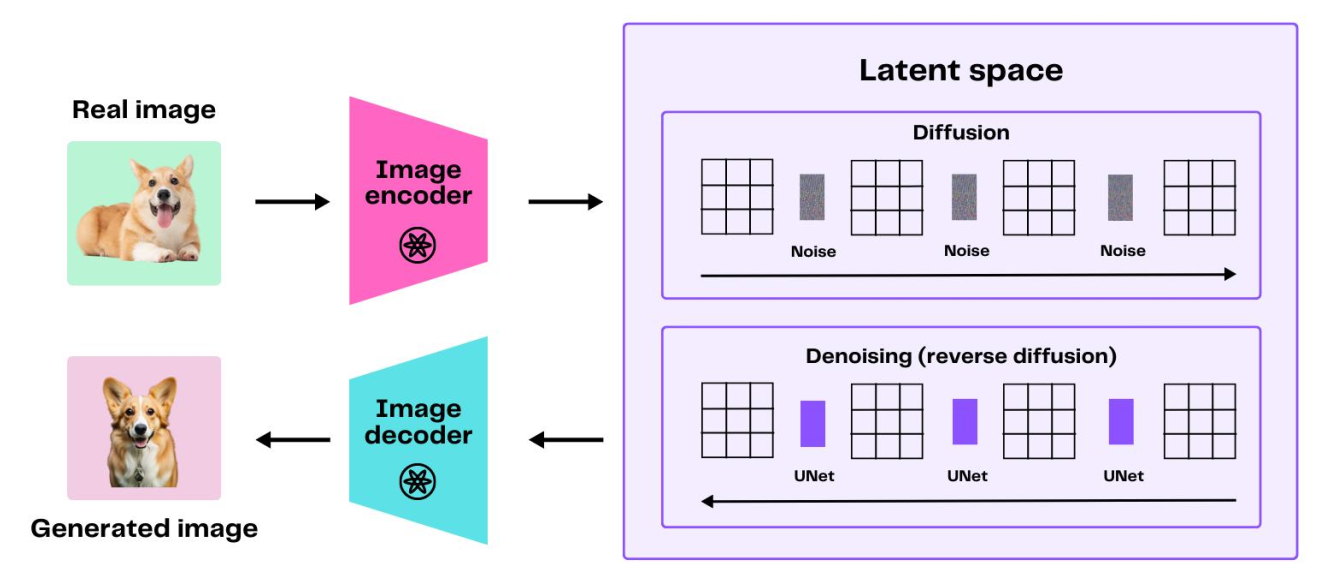
2.5 基于扩散模型的主干网络
- U-Net 网络模型结构把模型规模限定;
- SD/SDXL 作为经典网络只公布了推理和微调;
- 国内主要基于 SD/SDXL 进行二次创作
3.关键技术
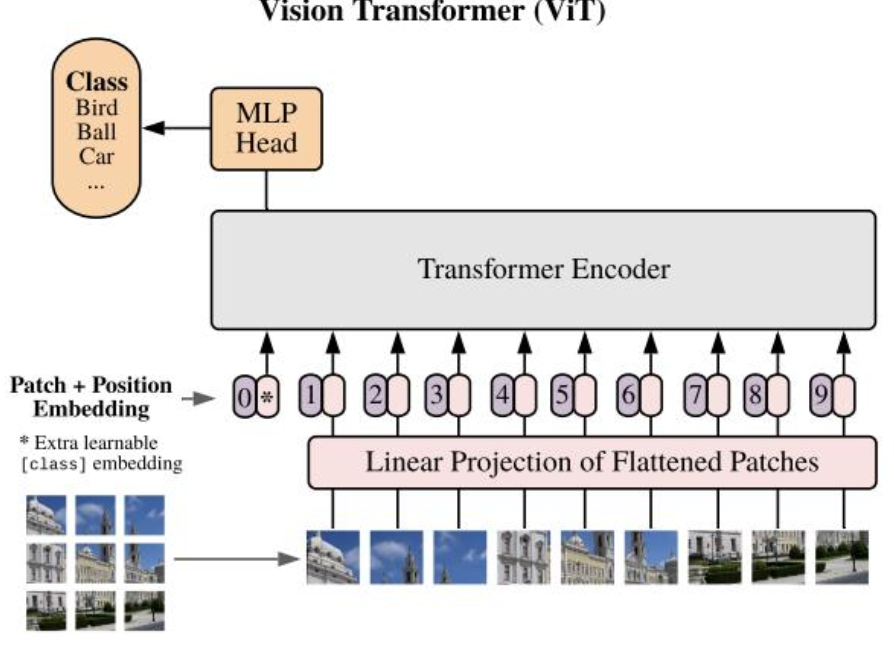
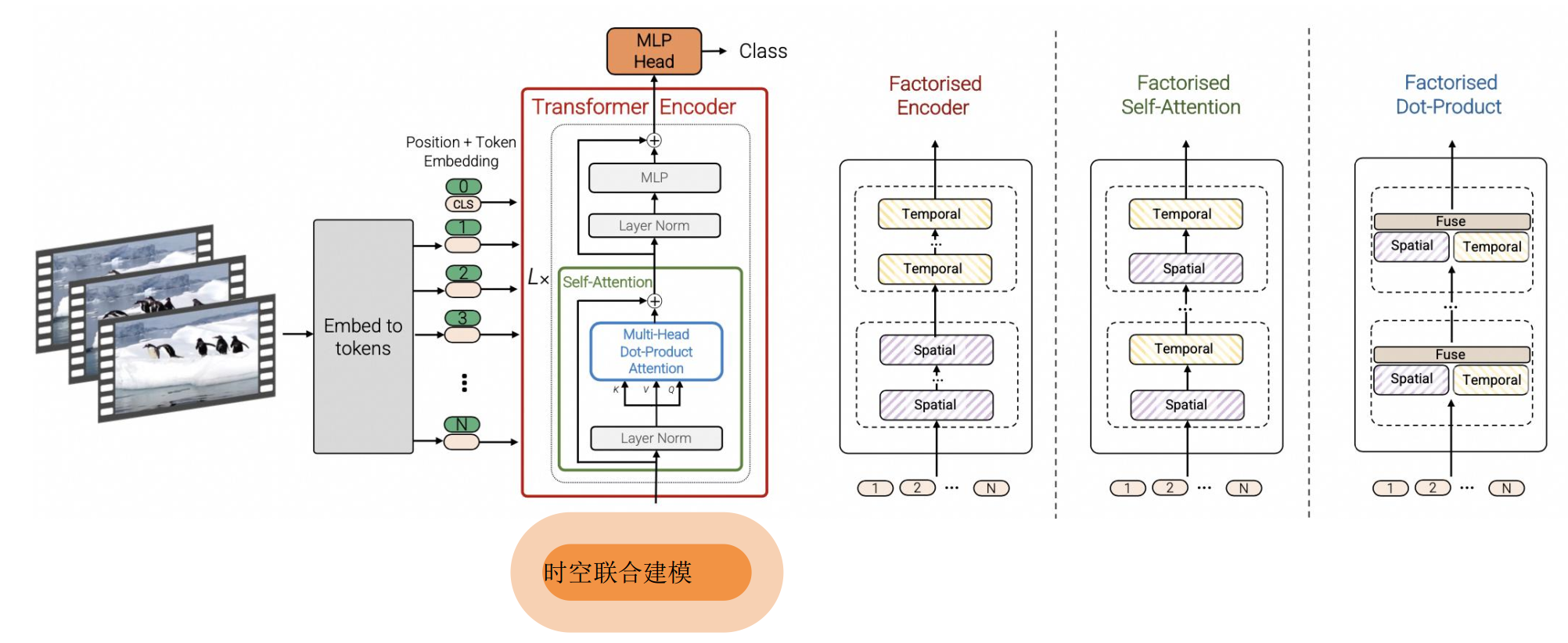
3.1 ViT
- ViT 尝试将标准 Transformer 结构直接应用于图像;
- 图像被划分为多个 patch后,将二维 patch 转换为一维向量作为 Transformer 的输入
3.2 时空编码(Spacetime latent patches)

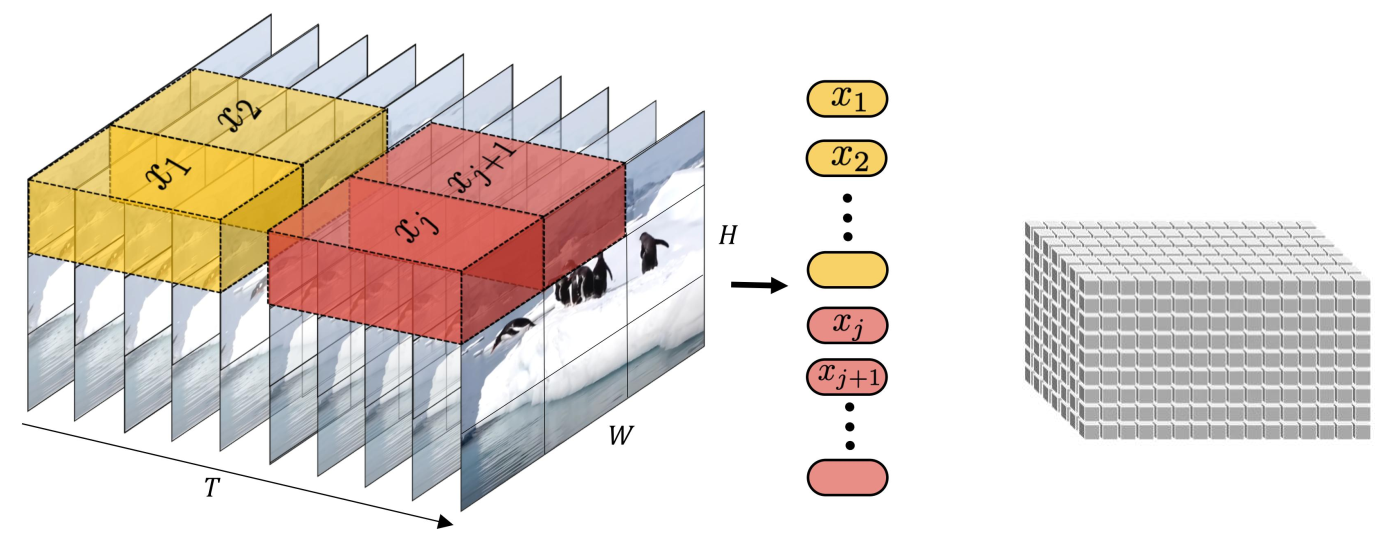
摊大饼法:从输入视频剪辑中均匀采样 n_t 个帧,使用与ViT相同的方法独立地嵌入每个2D帧(embed each 2D frame independently using the same method as ViT),并将所有这些token连接在一起
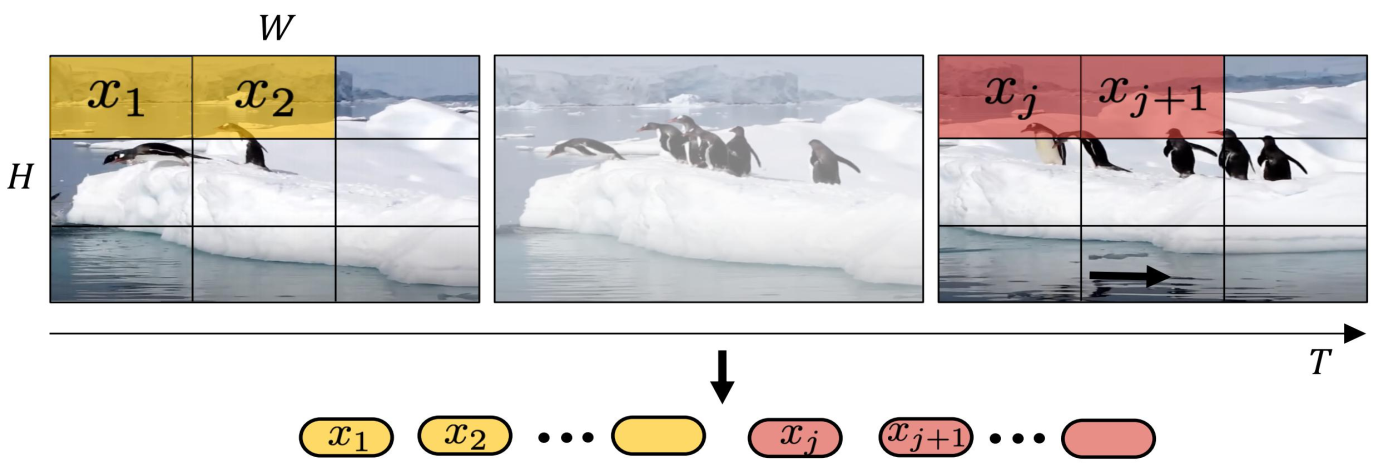
将输入的视频划分为若干tuplet,每个tuplet会变成一个token,经过Spatial Temperal Attention 进行空间/时间建模获得有效的视频表征token,即下图中灰色block。
参考资料
- https://datawhaler.feishu.cn/file/KntHbV3QGoEPruxEql2c9lrsnOb