学习java后端也有一段时间了,在网上寻一些教程和github上的开源库,学习从零开始手写一个RPC,学习各位大牛的代码适当修改,并贴上自己的一些见解和注释。
目录
- RPC简介
- RPC和HttpClient的区别和共同点
- 常见RPC框架
- RPC框架设计
- 常见序列化协议
RPC简介
RPC (Remote Procedure Call)是一种技术,允许程序调用在不同地址空间(通常是在另一台计算机上)的过程或函数,就像调用本地过程一样,隐藏了网络通信的细节。RPC 框架通常负责打包调用的参数,通过网络发送给服务提供者,然后将结果返回给调用者。
RPC由六个部分实现:
1. 客户端(服务消费端) :调用远程方法的一端。
2. 客户端 Stub(桩) : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
其负责将方法、参数等组装成能够进行网络传输的消息体(序列化):RpcRequest;找到远程服务的地址,并将消息发送到服务提供端;接收到消息并将消息反序列化为 Java 对象:RpcResponse ,这样也就得到了最终结果。
3. 网络传输 : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
4. 服务端 Stub(桩) :这个桩就不是代理类了。理解为桩实际不太好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。
其收到消息将消息反序列化为 Java 对象: RpcRequest;根据RpcRequest中的类、方法、方法参数等信息调用本地的方法;得到方法执行结果并将组装成能够进行网络传输的消息体:RpcResponse(序
列化)发送至消费方;
5. 服务端(服务提供端) :提供远程方法的一端。
RPC和HttpClient的区别和共同点
之前学习过HttpClient
它们都是在网络编程中常见的技术,用于在不同的计算机之间进行数据交换和通信。它们各自有不同的应用场景和特点,但也存在一些共同点。
RPC特点:
透明性: 对于开发者而言,远程调用和本地调用非常相似,隐藏了网络请求的复杂性。
多协议支持: 支持多种传输协议,如 HTTP、TCP、UDP 等。
高效: 通常使用专门的二进制协议,效率比 HTTP 更高。
强类型: 调用通常基于接口定义,具有强类型校验。
RPC应用:
微服务架构中服务间通信
分布式系统中不同组件间的交互
HttpClient 是一个用于发送 HTTP 请求和接收 HTTP 响应的类库或接口,存在于多种编程语言和框架中。它是 Web 开发中常用的工具,用于执行 HTTP 操作(如 GET、POST、PUT、DELETE 等)。
HttpClient 特点:
灵活性: 支持广泛的 HTTP 功能,包括各种方法、头部、身份验证等。
文本基础: 基于文本的请求和响应(如 JSON、XML),易于阅读和调试。
广泛支持: 几乎所有的 Web 开发语言和框架都支持 HTTP 客户端库。
状态无关: HTTP 是无状态的,每个请求都是独立的。
HttpClient 应用:
Web API 调用
微服务架构中的服务间通信
任何需要 Web 资源交互的场景
尽管 RPC 和 HttpClient 在设计和使用场景上有所不同,但它们也有一些共同点:
网络通信: 两者都用于在网络中的不同计算机之间进行数据交换。
服务消费: 无论是通过 RPC 还是 HttpClient,都可以作为服务消费者,调用远程服务或 API。
抽象层: 它们提供了与远程系统通信的抽象层,封装了底层的网络细节。
总的来说,选择 RPC 还是 HttpClient 取决于具体的应用场景和需求。RPC 更适合于对性能有高要求和需要强类型支持的内部服务通信,而 HttpClient 更适合于 Web API 调用和需要灵活性和广泛兼容性的场景。
常见RPC框架
RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架
Apache Dubbo
一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案, 涵盖 Java、Golang 等多种语言 SDK 实现。提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh (Dubbo3 赋予了很多云原生友好的新特性)等特性。
由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。是比较优秀的国产开源项目。
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的
github
官网
Motan
新浪微博开源的一款 RPC 框架,网上的资料比较少,更像是一个精简版的 Dubbo,设计更加精简,功能更加纯粹。公司实际使用的话,还是推荐 Dubbo 。
Motan 中文文档
从 Motan 看 RPC 框架设计
Dubbo 和 Motan 主要是给 Java 语言使用。如果需要跨多种语言调用的话,可以考虑使用 gRPC。
gRPC
Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
Github
官网
Thrift
Facebook 开源的跨语言的 RPC 通信框架,目前已经捐献给 Apache 基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用。相比于 gRPC 支持的语言更多。
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是它们只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑。
官网
RPC框架设计
参考RPC框架Dubbo的架构:
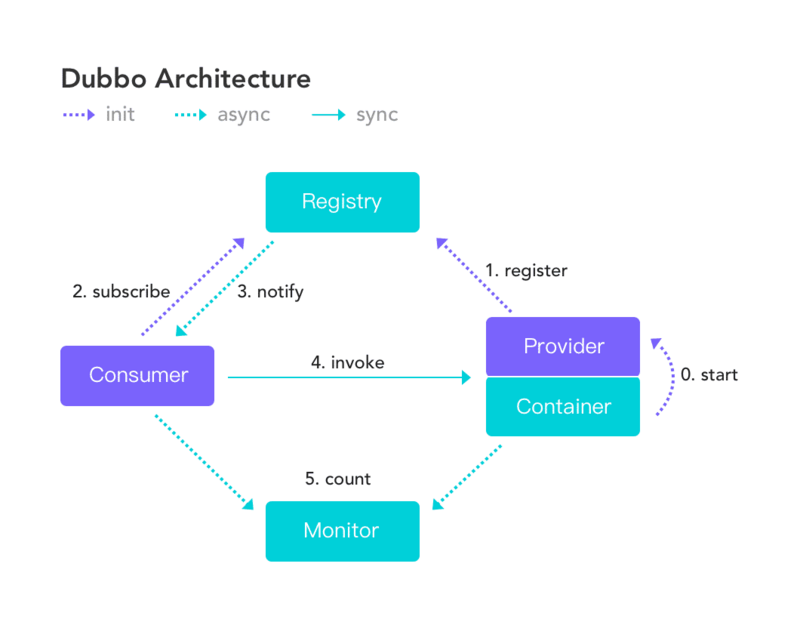
可以看到大体分为这几个部分服务提供方与运行服务的容器、服务注册与发现中心、服务消费方、监控中心。
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。我们不实现监控模块,有兴趣可以研究一下Dubbo 的监控模块的设计。
实现一个最基本的 RPC 框架需要哪些东西:
注册中心
注册中心负责服务地址的注册与查找,相当于目录服务。服务端启动的时候将服务名称及其对应的地址(ip+port)注册到注册中心,服务消费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消费端就可以通过网络请求服务端了。
比较推荐使用 Zookeeper 作为注册中心。也可以使用 Nacos ,甚至是 Redis。ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。并且,ZooKeeper 将数据保存在内存中,性能是非常棒的。在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。网络传输
要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的参数等数据到服务提供端。
网络传输具体推荐使用基于 NIO 的网络编程框架 Netty ,是最好的选择。Socket是Java 中最原始、最基础的网络通信方式,Socket 阻塞IO、性能低并且功能单一。使用同步非阻塞的 I/O 模型 NIO ,但是用它来进行网络编程太麻烦。
Netty 是一个基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。它极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。支持多种协议如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。序列化和反序列化
我们的 Java 对象没办法直接在网络中传输。为了能够让Java 对象在网络中传输我们需要将其序列化为二进制的数据。不仅网络传输的时候需要用到序列化和反序列化,将对象存储到文件、数据库等场景都需要用到序列化和反序列化。
JDK 自带的序列化,只需实现java.io.Serializable 接口即可,不过这种方式不支持跨语言调用并且性能比较差。现在比较常用序列化的有 hessian、kryo、protostuff、Protobuf等。动态代理
RPC 的主要目的就是让我们调用远程方法像调用本地方法一样简单,我们不需要关心远程方法调用的细节比如网络传输。动态代理就可以屏蔽远程方法调用的底层细节。
负载均衡
负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题。
传输协议
我们还需要设计一个私有的 RPC 协议,这个协议是客户端(服务消费方)和服务端(服务提供方)交流的基础。定义需要传输哪些类型的数据, 并规定每一种类型的数据应该占多少字节。这样在接收到二进制数据之后,就可以正确的解析出我们需要的数据,这有一点像密文传输。
一些标准的 RPC 协议包含下面这些内容:魔数 : 通常是 4 个字节。这个魔数主要是为了筛选来到服务端的数据包,有了这个魔数之后,服务端首先取出前面四个字节进行比对,能够在第一时间识别出这个数据包并非是遵循自定义协议的,也就是无效数据包,为了安全考虑可以直接关闭连接以节省资源。
序列化器编号 :标识序列化的方式,比如是使用 Java 自带的序列化,还是 json,kryo 等序列化方式。
消息体长度 : 运行时计算出来。
…
基于此,我们实现一款基于 Netty+kryo+Zookeeper的RPC 框架。
常见序列化协议
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存在安全问题,而且不支持跨语言调用。JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差。
JDK 自带的序列化方式
只需实现 java.io.Serializable接口即可:
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Builder
@ToString
public class RpcRequest implements Serializable {
private static final long serialVersionUID = 1905122041950251207L;
private String requestId;
private String interfaceName;
private String methodName;
private Object[] parameters;
private Class<?>[] paramTypes;
private RpcMessageTypeEnum rpcMessageTypeEnum;
}
serialVersionUID 作用
序列化号 serialVersionUID 属于版本控制的作用。反序列化时,会检查serialVersionUID 是否和当前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出InvalidClassException 异常。强烈推荐每个序列化类都手动指定其serialVersionUID ,如果不手动指定,那么编译器会动态生成默认的 serialVersionUID 。
serialVersionUID 不是被 static 变量修饰了吗?为什么还会被“序列化”?
static 修饰的变量是静态变量,位于方法区,本身是不会被序列化的。 static 变量是属于类的而不是对象。你反序列之后, static 变量的值就像是默认赋予给了对象一样,看着就像是static 变量被序列化,实际只是假象罢了。
如果有些字段不想进行序列化怎么办?
使用transient关键字修饰。transient 只能修饰变量,不能修饰类和方法。transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类型,那么反序列后结果就是0 。static 变量因为不属于任何对象(Object),所以无论有没有 transient 关键字修饰,均不会被序列化。
Kryo
Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。
Kryo专门针对 Java 语言序列化方式并且性能非常好,像 Protobuf、 ProtoStuff、hessian 这类都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
Github
Protobuf
Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不灵活,但是,另一方面导致protobuf 没有序列化漏洞的风险。
Github
ProtoStuff
protostuff 基于 Google protobuf,但是提供了更多的功能和更简易的用法。虽然更加易用,但是不代表 ProtoStuff 性能更差。
Github
Hessian
Hessian 是一个轻量级的,自定义描述的二进制 RPC 协议。Hessian 是一个比较老的序列化实现了,并且同样也是跨语言的。