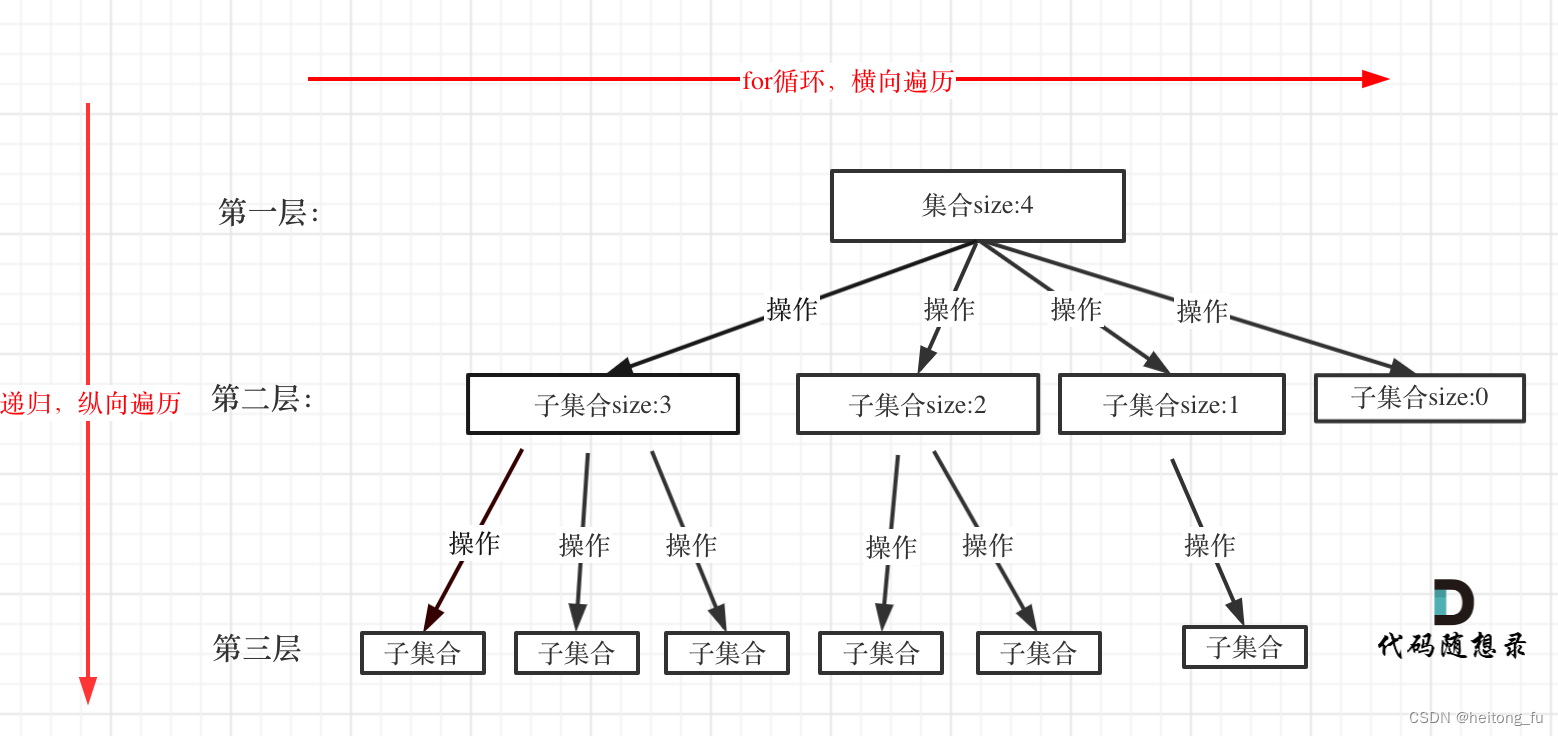
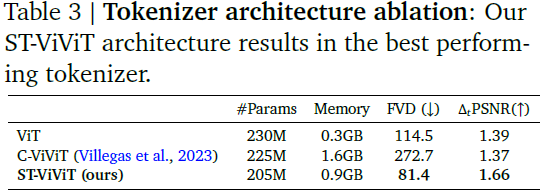
此系列为基础学习系列,请自行学习,课程资源免费获取地址:
https://download.csdn.net/download/weixin_68126662/88866689久菜盒子工作室:大数据科学团队/全网可搜索的久菜盒子工作室 我们是:985硕博/美国全奖doctor/计算机7年产品负责人/医学大数据公司医学研究员/SCI一区2篇/Nature子刊一篇/中文二区核心一篇/都是我们 主要领域:医学大数据分析/经管数据分析/金融模型/统计数理基础/统计学/卫生经济学/流行与统计学/ 擅长软件:R/python/stata/spss/matlab/mySQL
团队理念:从零开始,让每一个人都得到优质的科研教育
目录
1数据读取与预处理
2提取特征变量和目标变量
3划分训练集和测试集
4模型训练和搭建
5模型预测及评估
6预测不离职和离职的概率
7模型预测效果评估
8特征重要性评估
9决策树模型可视化呈现及决策树要点理解
| 模型搭建 | |||||||||||||||
1数据读取与预处理 | # 引入pandas库,别名pd import pandas as pd # 读取文件 df = pd.read_excel('员工离职预测模型.xlsx') # 离职为1,不离职为0 print(df.head()) # 工资数据分别为“高”、“中”、“低”三级 # Python数学建模中无法识别文本内容 # 对“工资”列内容数字化处理,高中低用2、1、0表示 df = df.replace({'工资': {'低': 0, '中': 1, '高': 2}}) print(df.head()) 显示: 工资 满意度 考核得分 工程数量 月工时 工龄 离职 0 低 3.8 0.53 2 157 3 1 1 中 8.0 0.86 5 262 6 1 2 中 1.1 0.88 7 272 4 1 3 低 7.2 0.87 5 223 5 1 4 低 3.7 0.52 2 159 3 1 工资 满意度 考核得分 工程数量 月工时 工龄 离职 0 0 3.8 0.53 2 157 3 1 1 1 8.0 0.86 5 262 6 1 2 1 1.1 0.88 7 272 4 1 3 0 7.2 0.87 5 223 5 1 4 0 3.7 0.52 2 159 3 1 | ||||||||||||||
2提取特征变量和目标变量 | # 提取特征变量和目标变量 x = df.drop(columns='离职') # DataFrame类型 y = df['离职'] # Series类型 | ||||||||||||||
3划分训练集和测试集 | # 划分训练集和测试集 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1) # print(x_train) # print(x_test) # print(y_train) # print(y_test) | ||||||||||||||
4模型训练和搭建 | # 模型训练和搭建 from sklearn.tree import DecisionTreeClassifier # 设置决策树最大深度为3,随机状态保持一致 model = DecisionTreeClassifier(max_depth=3, random_state=1) # 代入训练数据 model.fit(x_train, y_train) | ||||||||||||||
5模型预测及评估 | |||||||||||||||
| 直接预测是否离职 | # 直接预测是否离职 y_pred = model.predict(x_test) # y_pred为数组类型 print(y_pred[0: 100]) # 显示前100项 # 将预测值y_pred与实际值y_test对比 a = pd.DataFrame() a['预测值'] = y_pred a['实际值'] = y_test.values print(a) # 查看整体准确度 from sklearn.metrics import accuracy_score score = accuracy_score(y_pred, y_test.values) print('整体准确度:'+str(score)) # 利用模型自带的score()函数查看预测准确度 print('自带函数预测准确度:'+str(model.score(x_test, y_test))) # 准确度一致 显示: [0 0 0 0 1 1 0 1 0 0 0 0 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0] 预测值 实际值 0 0 0 1 0 0 2 0 0 3 0 0 4 1 1 ... ... ... 2995 0 0 2996 0 0 2997 0 0 2998 0 0 2999 1 0 [3000 rows x 2 columns] 整体准确度:0.9583333333333334 自带函数预测准确度:0.9583333333333334 | ||||||||||||||
6预测不离职和离职的概率 | # 显示预测不离职和离职的概率 y_pred_proba = model.predict_proba(x_test) # y_pred_proba为数组类型,二维数组 b = pd.DataFrame(y_pred_proba, columns=['不离职概率', '离职概率']) print(b.head()) # 自取第二列 # :表示所有行,1表示第1列;注意0为开始 print(y_pred_proba[:, 1]) 显示: 不离职概率 离职概率 0 0.986412 0.013588 1 0.986412 0.013588 2 0.986412 0.013588 3 0.986412 0.013588 4 0.287056 0.712944 [0.01358811 0.01358811 0.01358811 ... 0.04830918 0.07778669 0.71294363] | ||||||||||||||
7模型预测效果评估 | 对于分类模型而言,我们不仅关心其预测的准确度,更关心下面两个指标: 命中率 (TPR)(所有实际离职的员工中被预测为离职的比率) 假警报率 (FPR)(所有实际不离职的员工中被预测为离职的概率) 通过两者绘制的ROC曲线来评判模型。 | ||||||||||||||
| # 模型预测效果评估 from sklearn.metrics import roc_curve # 代入目标变量和预测离职率概率 # fpr、tpr、thres为数组类型 fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:, 1]) a = pd.DataFrame() # 创建一个空DataFrame a['阈值'] = thres a['假警报率'] = fpr a['命中率'] = tpr print(a.head()) 显示: 阈值 假警报率 命中率 0 2.000000 0.000000 0.000000 1 1.000000 0.000000 0.239011 2 0.940948 0.005722 0.667582 3 0.712944 0.032130 0.928571 4 0.077787 0.160211 0.954670 | |||||||||||||||
| # 通过Matplotlib库绘制ROC曲线 import matplotlib.pyplot as plt plt.plot(fpr, tpr) plt.show() 显示: | |||||||||||||||
| # 快速求出AUC值 from sklearn.metrics import roc_auc_score score = roc_auc_score(y_test, y_pred_proba[:, 1]) print('AUC值:'+str(score)) 显示: AUC值:0.9684401481001393 表明预测效果不错 | |||||||||||||||
8特征重要性评估 | 模型搭建完成后,有时我们希望能够知道各个特征变量的重要程度,即哪些特征变量在模型中起的作用更大,这个重要性称为特征重要性。 一个特征变量对模型整体的基尼系数下降的贡献越大,它的特征重要性就越大。 举个例子,模型分裂到最后的叶子节点,整个系统的基尼系数下降数值为0.3,如果所有根据特征A进行分裂的节点产生的基尼系数下降的数值和为0.15,那么特征A的特征重要性则为50%,也即0.5 # 特征重要性评估 print(model.feature_importances_) 显示: [0. 0.60360106 0.14117765 0.10417268 0.00462175 0.14642687] 特征重要性之和为1 | ||||||||||||||
| # 特征重要性评估,对应关系显示 features = x.columns # 获取特征名称,相当表头 # print(features) # 获取特征重要性 importances = model.feature_importances_ # 以二维表格形式显示 importances_df = pd.DataFrame() # 创建空白表格 importances_df['特征名称'] = features importances_df['特征重要性'] = importances # 按照'特征重要性'降序排列 print(importances_df.sort_values('特征重要性', ascending=False)) 显示: 特征名称 特征重要性 1 满意度 0.603601 5 工龄 0.146427 2 考核得分 0.141178 3 工程数量 0.104173 4 月工时 0.004622 0 工资 0.000000 “工资”的特征重要性为0,不合常理。 主要原因是:
| |||||||||||||||
| 决策树模型可视化呈现及决策树要点理解 | 如果想将决策树模型可视化展示出来,可以使用Python的graphviz插件。因为模型可视化呈现主要是为了演示和教学,在真正实战中应用较少 | ||||||||||||||
| graphviz插件的安装及使用 | |||||||||||||||
| graphviz插件安装与环境变量部署 | graphviz插件下载 下载地址为:https://graphviz.gitlab.io/download/
安装的时候,可以选择是否配置路径 建议选择配置路径,否则需要手工配置 | ||||||||||||||
| 在Python中使用graphviz | graphviz库安装 pip install graphviz | ||||||||||||||
| graphviz库的使用 # graphviz库的使用 # 引入使用graphviz相关的库 from sklearn.tree import export_graphviz import graphviz # 配置graphviz路径 # 即使安装graphviz的时候,已经选择配置路径,这里还是要手动配置 import os os.environ['PATH'] = os.pathsep + r'C:\Program Files\Graphviz\bin' # 用export_graphviz()函数将之前搭建的决策树模型model转换为字符串格式,并赋值给dot_data # 需要设定out_file为None,转换后获得的内容才为字符串格式 dot_data = export_graphviz(model, out_file=None, class_names=['0', '1']) # 将dot_data转换成可视化格式 graph = graphviz.Source(dot_data) # 输出可视化结果,默认输出一个名为“决策树可视化”的PDF文件 graph.render('决策树可视化') 结果:
x[1]就表示第2个特征变量:满意度 x[3]则表示第4个特征变量:工程数量 x[5]则表示第6个特征变量:工龄 gini则表示该节点的基尼系数 samples则表示该节点中的样本数,比如说第一个节点,也即根节点中的12000也即训练集中的样本数量 value则表示不同种类所占的个数,比如说根节点中value左边的9156则表示不离职员工的数量,2844则表示离职员工的数量 class=0则是认为该节点为“不离职”节点(1为“离职”) | |||||||||||||||
| 如果想让可视化的图片里的内容更丰富些,可以在export_graphviz()的括号中增添一些参数 增加feature_names参数可以显示特征变量的名称,不过直接使用graphviz识别不了中文增添class_names参数则可以显示最后的分类结果,因为中文可能会出现乱码问题,所以用字符串'0'和'1'来代替'流失'和'非流失',注意不能写成数字格式的0和1,因为class_names参数中只能设置字符串格式的数据 将filled参数设置为True还可以给可视化的决策树添加颜色 # 添加名称(feature_names)和填充颜色(filled=True) dot_data = export_graphviz(model, out_file=None, feature_names=['income', 'satisfication', 'score', 'project_num', 'hours', 'year'], class_names=['0', '1'], filled=True) graph = graphviz.Source(dot_data) graph.render('决策树可视化_添加名称和填充颜色')
此时的特征变量就不再试通过x[4]这种形式来表示了,而是通过具体设置的名称来显示了。 因为设置了class_names,所以每一个节点有一个内容叫作class,其中0代表着不离职,1代表着离职。其判断依据为value中哪个类别占的数量多,则判定为该类别,比如根节点中的value,不离职员工为9156人,离职员工为2844人,那么则判断该节点的类别为0,即不离职。 在实际应用中,我们更关心最终叶子节点的分类类别,比如左下角的叶子节点的分类类别为1,即离职。如果员工通过该决策树模型分到左下角的叶子节点的话,那么则判断其为离职员工。 | |||||||||||||||
| 中文乱码问题解决办法 | # 中文乱码问题解决办法 dot_data = export_graphviz(model, out_file=None, feature_names=x_train.columns, class_names=['不流失', '流失'], rounded=True, filled=True) # model表示之前训练的模型,目的就是将其转换成字符串的格式然后再转换成图形 # out_file参数是用来设置生成的内容为字符串的 # feature_names则是用来设置特征变量的名称 # 其中x_train.columns则是测试训练集的表头名称,也即这个决策树模型的特征变量名称 # class_names则是设定最后的分类结果,直接设置成中文的'不流失'和'流失' # rounded参数需要设置成True,这样之后设置中文格式才会生效 # filled参数设置为True可以使得生产的决策树有颜色
# 中文乱码问题解决办法 dot_data = export_graphviz(model, out_file=None, feature_names=x_train.columns, class_names=['不流失', '流失'], rounded=True, filled=True) # model表示之前训练的模型,目的就是将其转换成字符串的格式然后再转换成图形 # out_file参数是用来设置生成的内容为字符串的 # feature_names则是用来设置特征变量的名称 # 其中x_train.columns则是测试训练集的表头名称,也即这个决策树模型的特征变量名称 # class_names则是设定最后的分类结果,直接设置成中文的'不流失'和'流失' # rounded参数需要设置成True,这样之后设置中文格式才会生效 # filled参数设置为True可以使得生产的决策树有颜色 # 将之前的dot_data字符串类型的数据写到txt文件中 f = open('dot_data.txt', 'w') f.write(dot_data) f.close() # 修改字体设置 # 修改原来dot_data.txt中的字体及编码格式,并将其另存为一个新的dot_data_new.txt文件,为之后解决中文乱码问题做铺垫 # 首先引入正则表达式库re,为之后的替换字体做准备 import re # 通过open()函数读取原来的dot_data.txt中的文本内容 # 其中'r'表示以读取模式打开txt文件,将文件内容赋值给f_old变量 f_old = open('dot_data.txt', 'r') # 通过open()函数新建一个dot_data_new.txt文件,其中'w'表示以写入模型打开txt文件 # 每次写入时都会把原有内容清除 # encoding参数为编码方式,这里设置为能够支持中文显示的utf-8编码,这个编码方式的设置对解决中文乱码问题而言很重要 f_new = open('dot_data_new.txt', 'w', encoding='utf-8') # 这几行代码的目的就是用来替换原来dot_data.txt的默认的字体格式,替换成SimHei也即黑体格式 # 文档里面的fontname="helvetica",helvetica换成SimHei # 通过for循环语句遍历f_old,也即dot_data.txt中的每一行 for line in f_old: # 通过if判断语句来查看每一行中是否有fontname内容 # fontname的中文意思就是字体名字 # 对于含有fontname的行,通过正则表达式的非贪婪匹配(.*?)将默认的字体找到 # 通过replace()函数将旧的字体替换成想设置的字体,比如这里设置的SimHei,也即黑体字体 if 'fontname' in line: font_re = 'fontname=(.*?)]' old_font = re.findall(font_re, line)[0] line = line.replace(old_font, '"SimHei"') # 将这些替换完的新的行写入到新的txt文件f_new中 f_new.write(line) # 通过close()函数将f_old和f_new关闭 f_old.close() f_new.close() | ||||||||||||||
| 补充知识点:这里的SimHei是黑体的英文翻译,如果想采用其他字体,可参考下面的字体英文对照表:
| |||||||||||||||
| 生成可视化文件 生成完新的重新设置编码格式及字体的dot_data_new.txt文件后,可以通过graphviz插件生成可视化的文件 # 生成可视化文件 # 通过调用os.system()系统函数来使用graphviz插件 # 其中-Tpdf表示生成PDF格式的文件 os.system('dot -Tpdf dot_data_new.txt -o 决策树模型.pdf') # 如果将其改成-Tpng生成PNG格式的图片文件 os.system('dot -Tpng dot_data_new.txt -o 决策树模型.png')
| |||||||||||||||
9决策树模型可视化呈现及决策树要点理解 | |||||||||||||||
| 节点各元素含义 | 其分裂依据是根据满意度是否小于等于4.65作为分裂依据的;它当前的基尼系数为0.362 sample样本总数为12000 value中的左边的数值9156表示“是否离职”中的0,也即不离职员工,右边的数值2844表示“是否离职”中的1,也即离职员工 class表示分类,因为在这个节点上不离职员工数(9156)多于离职员工数(2844),所以class为不离职,不过根节点的class没有什么意义,我们主要看最后叶子节点的class情况。 此外,最后的叶子节点因为已经分裂完毕,所以不再有分裂依据这一项 | ||||||||||||||
| 节点划分与其依据验证 | 根节点分裂完后产生两个子节点,其中左边的子节点中大部分为离职员工,而右边的节点中大部分为不离职员工,这也的确符合现实中如果满意度较低则出现离职可能性较大的经验。 经过根节点分裂后的系统的基尼系数为: gini(T)=3348/12000*0.478+8652/12000*0.171=0.256653 这个也是机器通过不停的训练和计算获得的最优解,如果通过别的方式进行根节点分裂后的系统基尼系数一定会比这个大,基尼系数的下降值一定比这个小。 | ||||||||||||||
| 特征重要性与整棵树的关系 | 可以看到这里重要性最高的便是满意度。同样这里可以更好地解释下为什么工资这一特征变量的特征重要性为0,这个是因为该因素在该模型中没有发挥作用,这可以从可视化的图形中看出,每一个分叉的节点都没有依据“工资”这个特征变量进行分裂,所以说这个特征变量并没有发挥作用。 | ||||||||||||||
| 在决策树模型中,特征重要性的大小在于该变量对于整体的基尼系数下降的贡献度大小,这里可以利用这个可视化后的决策树,通过演示第二个特征变量“满意度”的特征重要性为什么为0.603601来验证下该观点。 首先需要计算整体的基尼系数下降,根据不同叶子节点的样本数进行权重求和,新系统的基尼系数为0.081301,整体基尼系数下降为0.362-0.081301=0.280699 1287/12000*0.111+ 103/12000*0.143+ 711/12000*0.0+ 1247/12000*0.143+ 7065/12000*0.027+ 8/12000*0.0+ 621/12000*0.092+ 958/12000*0.409=0.081301 以“满意度”为例,在上面的决策树中它共在根节点和下部中间的节点(第2层第2个节点)发挥了作用,对系统产生的基尼系数下降分别为0.105347和0.06427575 0.362-(3348/12000*0.478+8652/12000*0.171)=0.105347 1958/12000*0.485-(711/12000*0.0+1247/12000*0.143)= 0.06427575 两者之和为0.16962275,这个就是“满意度”这一特征变量在整个模型中发挥的作用: 0.105347+ 0.06427575=0.16962275 将其除以整体的基尼系数下降值便是它的特征重要性,这个与代码的获得特征重要性基本一致(小数精度问题有影响): 0.16962275/0.256653=0.660903048 代码计算:[0. 0.60360106 0.14117765 0.10417268 0.00462175 0.14642687] | |||||||||||||||
| 叶子停止分裂的依据 | 叶子停止分裂的依据主要有两个:已经分裂结束无法再分裂,或者达到限定的分裂条件。 比如右下角的叶子节点的基尼系数都为0了,也就是说这个叶子节点的纯度已经最高了(即里面所有的元素都是同一类别),已经不需要也无法再分裂了。 有些叶子节点的基尼系数还没有到达0的,因为限制了树的最大深度为3,所以也不会继续向下分裂了。 | ||||||||||||||
| 不离职和离职概率与叶子节点的关系 | 不离职和离职概率的计算就是基于叶子节点,如果分到了左下角第三个叶子节点,那么其不离职概率为0,离职概率为100%,所以判断其为离职;如果分到最左边叶子节点,这个节点里总共有1287个数据,不离职的有76人,离职的有1211人,那么如果一个新的员工被分到该叶子节点,那么判定该员工离职概率为1211/1287=0.940947941,离职概率则为76/1287=0.059052059,因为离职概率大于不离职概率,所以判定其离职,其余则依次类推。 | ||||||||||||||
| ROC曲线与叶子节点的关系 | 绘制ROC曲线时使用的阈值并不是随意选取的,而是这些不同叶子节点反映出来的离职概率。ROC曲线的绘制就是以这些离职概率的值作为阈值来看不同阈值下的命中率(TPR)和假警报率(FPR)。此外,因为这里很多叶子节点的离职概率是100%,这也解释了为什么取100%作为阈值,仍然有24.7%命中率的原因。 通过这个图便能够较好的理解决策树的运行逻辑,当来了一个新的数据的时候,就会从最上面的根节点开始进行判断,如果满足满意度<=4.65,则划分到左边的节点进行之后一系列的判断,如果不满足则分到右边的节点进行之后一系列的判断,最终这个新的数据会被划分到其中的一个叶子节点中去,从而完成对数据的预测。 | ||||||||||||||