在yolo系列中,很多网友都反馈过想要在目标检测的图片上,显示计数功能。其实官方已经实现了这个功能,只不过没有把相关的参数写到图片上。所以微智启软件工作室出一篇教程,教大家如何把计数的参数打印到图片上。
一、yolov5目标检测增加计数功能实现
1、在detect.py代码中的132行左右,找到这样的代码

{n}是指类别统计的数量
{names[int(c)]}则是标签名
所以只需要调整这两个参数,就可以得到想要的格式,对于我们常用的习惯,我把代码改成了如下的格式:

运行输出代码,发现前面多出一串,并不是我们想要的效果

所以需要我们自己定义一个变量,只接收后面的统计参数即可。我这里放在了55行,定义一个空的字符串
count=''
然后在s +=的后面接收【f"{names[int(c)]}{'s' * (n > 1)}:{n} |"】的值
count+= f"{names[int(c)]}{'s' * (n > 1)}:{n} |"
然后,只需要在合适的位置,通过cv2,把参数写到图片即可。我这里添加到了151行左右,也就是im0 = annotator.result()的后面。

cv2.putText(im0, f"{count}",(30,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2,cv2.LINE_AA)
关于cv2的参数含义如下:
im0: 这是输入图像,即要在其上添加文本的图像。f"{s}": 这是要添加到图像上的文本。在这里,s是一个变量,它被转换为字符串并作为文本添加到图像上。(30, 30): 这是文本在图像上的位置坐标。在这个例子中,文本将放置在图像的 (30, 30) 位置。cv2.FONT_HERSHEY_SIMPLEX: 这是字体类型。在这个例子中,使用了 Hershey Simplex 字体。1: 这是字体缩放因子。这个值决定了文本的大小。(0, 0, 255): 这是文本的颜色。在这个例子中,文本颜色为红色,表示为 BGR(蓝色、绿色、红色)格式的元组。2: 这是文本线条的粗细。这个值决定了文本边缘的粗细程度。cv2.LINE_AA: 这是线条类型。在这个例子中,使用了抗锯齿线条。
在cv2添加完后,再清空字符串,方便下次的统计

count=''二、yolov7目标检测增加计数功能
yolov7和yolov5其实差不多的,可以先运行看一下效果,这个是统计的输出如下,发现有现成的效果:
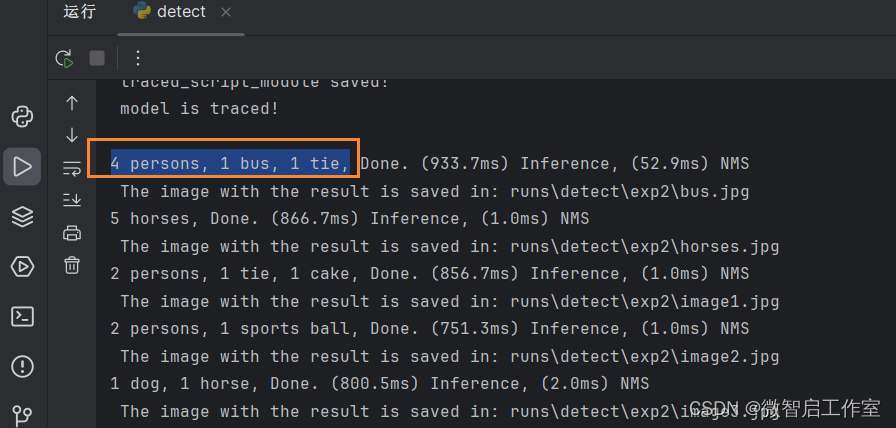
打开detect.py。找到117行左右

所以我们只需把{n}–这里的{n}也就是类别的数量,移动到后面就可以了,同时还可以把逗号换成自己想要的符号,我这里是“ | ”移动后如下(可以根据自己的需求更改):
s += f"{names[int(c)]}{'s' * (n > 1)}:{n}|" 接下来,在合适的位置,通过cv2来把文字显示图片上

cv2.putText(im0, f"{s}",(30,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2,cv2.LINE_AA)
im0: 这是输入图像,即要在其上添加文本的图像。f"{s}": 这是要添加到图像上的文本。在这里,s是一个变量,它被转换为字符串并作为文本添加到图像上。(30, 30): 这是文本在图像上的位置坐标。在这个例子中,文本将放置在图像的 (30, 30) 位置。cv2.FONT_HERSHEY_SIMPLEX: 这是字体类型。在这个例子中,使用了 Hershey Simplex 字体。1: 这是字体缩放因子。这个值决定了文本的大小。(0, 0, 255): 这是文本的颜色。在这个例子中,文本颜色为红色,表示为 BGR(蓝色、绿色、红色)格式的元组。2: 这是文本线条的粗细。这个值决定了文本边缘的粗细程度。cv2.LINE_AA: 这是线条类型。在这个例子中,使用了抗锯齿线条。
v7从115行到133行的完整代码如下,可以直接替换。
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{names[int(c)]}{'s' * (n > 1)} | {n} " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
# Print time (inference + NMS)
print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
cv2.putText(im0, f"{s}", (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA)三、yolov8目标检测计数功能实现
yolov8相对于前面两个的计数,稍微来说比较麻烦点,可能也有类似的参数,但是我没有找到,所以debug后发现【self.results[i].boxes.cls】这个属性里面,有类别的统计

打开【ultralytics/engine/predictor.py】只需要遍历统计这个类别序号的个数即可。
遍历完数据后,定义一个空的字典【names_dic = {}】

# 将结果转换为Python列表
result_list = self.results[i].boxes.cls.tolist()
# 初始化一个空字典用于存储数字和它们的出现次数
count_dict = {}
# 遍历列表,统计数字出现的次数
for number in result_list:
if number in count_dict:
count_dict[number] += 1
else:
count_dict[number] = 1
for k, v in count_dict.items():
names_dic[self.model.names[k]] = v
result_str = '| '.join([f'{key}:{value}' for key, value in names_dic.items()])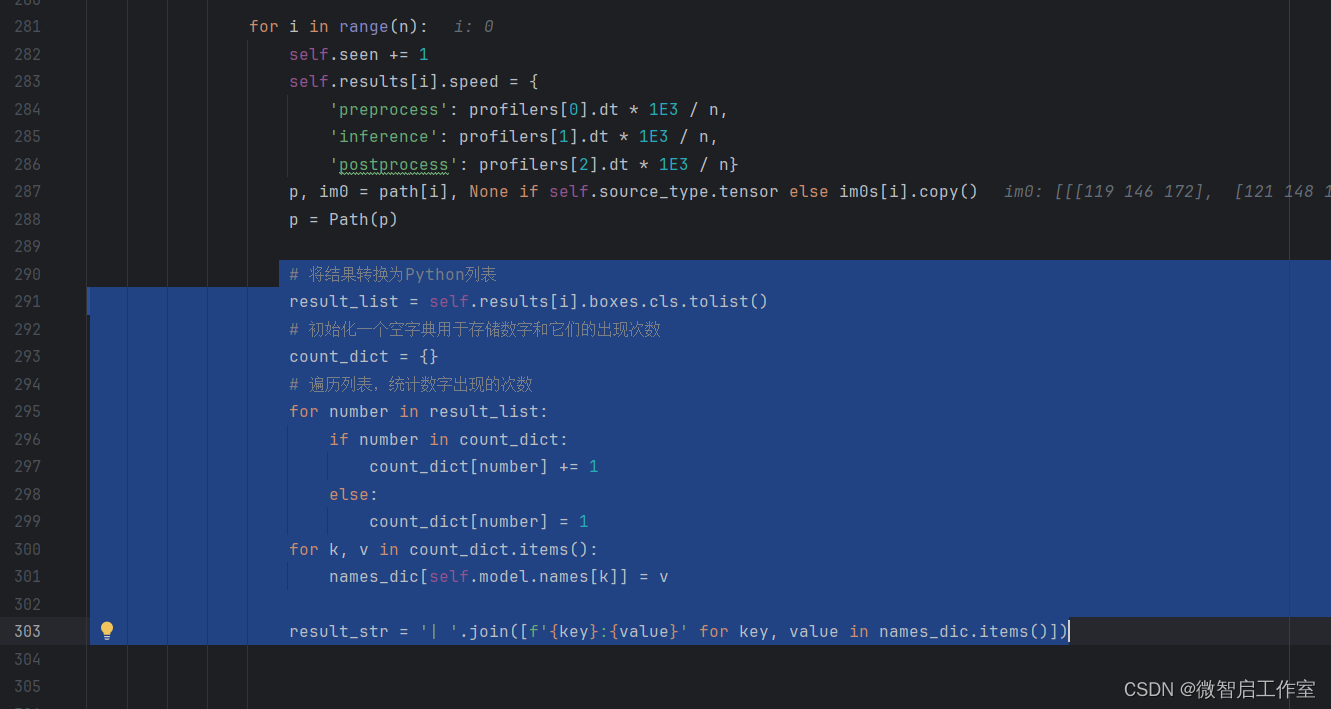
然后,在合格的位置,cv2,我添加在了
if self.args.verbose or self.args.save or self.args.save_txt or self.args.show:这个方法的后面,因为只有执行了它,self.plotted_img才会被赋值
cv2.putText(self.plotted_img, result_str, (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2,
cv2.LINE_AA) 
运行效果如下图:

至此,代码已经全部给出了,只要注意代码的缩进,就可以大功告成了。不过,有的朋友还是不懂得修改,那么我就把测试的python完整代码放到csdn上吧,设置的0积分下载。
代码下载地址:
https://download.csdn.net/download/weixin_41717861/88887348