开启root
修改root用户的密码
sudo passwd root
SSH放行
sudo sed -i 's/^#\?PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config;
sudo sed -i 's/^#\?PasswordAuthentication.*/PasswordAuthentication yes/g' /etc/ssh/sshd_config;
重启服务
sudo service sshd restart
修改主机名
分别在四台机器上修改
hostnamectl set-hostname --static "server100"
hostnamectl set-hostname --static "server101"
hostnamectl set-hostname --static "server102"
hostnamectl set-hostname --static "server103"
查看主机名
hostname

修改hosts
vi /etc/hosts
添加以下内容
192.168.30.100 server100
192.168.30.101 server101
192.168.30.102 server102
192.168.30.103 server103
配置免密登录
生成密匙
四台机器上都执行执行
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub root@server100
ssh-copy-id -i ~/.ssh/id_rsa.pub root@server101
ssh-copy-id -i ~/.ssh/id_rsa.pub root@server102
ssh-copy-id -i ~/.ssh/id_rsa.pub root@server103
关闭防火墙
sudo ufw disable
查看防火墙状态
sudo ufw status
挂载硬盘(如果需要的话)
假设你想要将额外的空间添加到现有的 LVM 逻辑卷 /dev/ubuntu-vg/ubuntu-lv 中:
-
首先,使用
lvdisplay命令查看 LVM 逻辑卷的详细信息,确保有足够的未分配空间可用:sudo lvdisplay注意其中的 “Free PE / Size” 部分,确保有足够的空间。
-
如果有足够的未分配空间,使用
lvextend命令扩展现有的逻辑卷。假设你有 500G 的空闲空间,命令可能如下所示:sudo lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv这将利用所有可用的空闲空间进行扩展。
-
扩展逻辑卷后,你需要将文件系统扩展到新的空间。对于 ext4 文件系统,可以使用
resize2fs命令:sudo resize2fs /dev/ubuntu-vg/ubuntu-lv -
最后,使用
df -h命令检查文件系统的大小,确保已经成功扩展。df -h
如果你想要使用硬盘的剩余空间,你需要创建一个新的逻辑卷。以下是相应的步骤:
-
使用
lvcreate命令创建一个新的逻辑卷。假设你想要创建一个名为data-lv的逻辑卷,可以执行:sudo lvcreate -l +100%FREE -n data-lv ubuntu-vg这将使用硬盘上所有可用的空闲空间创建一个新的逻辑卷。
-
接下来,你需要创建一个文件系统。对于 ext4 文件系统,可以使用
mkfs命令:sudo mkfs -t ext4 /dev/ubuntu-vg/data-lv -
确保目标目录
/data存在,如果不存在,创建它:sudo mkdir /data -
然后,将新创建的逻辑卷挂载到
/data:sudo mount /dev/ubuntu-vg/data-lv /data -
最后,如果你希望系统启动时自动挂载
/data,你可以编辑/etc/fstab文件,添加一行:/dev/ubuntu-vg/data-lv /data ext4 defaults 0 0保存并退出编辑器。
修改可打开文件数(可选)
vi ~/.bashrc
末尾添加一行
ulimit -n 新的文件打开数
保存并关闭文件,然后重新加载配置文件:
source ~/.bashrc
使用以下命令验证更改是否已生效:
ulimit -n
设置时区:
sudo dpkg-reconfigure tzdata
运行上述命令后,你会看到一个交互式的界面,其中可以选择你所在的地区和城市。选择完毕后,系统将自动更新时区设置。
通过timedatectl命令查看时间状态
安装jdk
上传到/usr/loca目录,然后解压
tar -zxvf jdk-8u202-linux-x64.tar.gz
配置环境变量
vi /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_202
JRE_HOME=/usr/local/jdk1.8.0_202/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$HBASE_HOME/sbin:$PATH
export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
export PATH=/usr/local/cmake/bin/:$PATH
export MAVEN_HOME=/usr/local/maven
export PATH=$MAVEN_HOME/bin:$PATH
配置生效
source /etc/profile
本次部署计划四台服务器server100,server102,server101,server103,其中server103作为master节点,其它三个节点作为数据节点
部署zookeeper
在三个agent节点安装zookeeper
上传到/usr/local
解压
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
建立软连接,方便后期升级
ln -s apache-zookeeper-3.7.1-bin/ zookeeper
修改配置文件
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/usr/local/zookeeper/tmp
server.1=server100:2888:3888
server.2=server101:2888:3888
server.3=server102:2888:3888
在data目录中创建一个空文件,并向该文件写入ID。
touch /usr/local/zookeeper/data/myid
echo 1 > /usr/local/zookeeper/data/myid
同步配置到其它节点
将配置好的ZooKeeper拷贝到其它节点
scp -r /usr/local/apache-zookeeper-3.7.1-bin root@server101:/usr/local
scp -r /usr/local/apache-zookeeper-3.7.1-bin root@server102:/usr/local
登录server101、server102,创建软链接并修改myid内容
server101
cd /usr/local
ln -s apache-zookeeper-3.7.1-bin zookeeper
echo 2 > /usr/local/zookeeper/data/myid
server102
cd /usr/local
ln -s apache-zookeeper-3.7.1-bin zookeeper
echo 3 > /usr/local/zookeeper/data/myid
运行验证
cd /usr/local/zookeeper/bin
./zkServer.sh start
查看启动状态
./zkServer.sh status

安装hadoop
将“hadoop-3.2.3.tar.gz”放置于server1节点的“/usr/local”目录,并解压。
cd /usr/local
tar -zxvf hadoop-3.2.3.tar.gz
建立软链接
ln -s hadoop-3.2.3 hadoop
修改配置文件
cd $HADOOP_HOME/etc/hadoop
修改hadoop-env.sh
echo "export JAVA_HOME=/usr/local/jdk1.8.0_202" >> hadoop-env.sh
echo "export HDFS_NAMENODE_USER=root" >> hadoop-env.sh
echo "export HDFS_SECONDARYNAMENODE_USER=root" >> hadoop-env.sh
echo "export HDFS_DATANODE_USER=root" >> hadoop-env.sh
修改yarn-env.sh
echo "export YARN_REGISTRYDNS_SECURE_USER=root" >> yarn-env.sh
echo "export YARN_RESOURCEMANAGER_USER=root" >> yarn-env.sh
echo "export YARN_NODEMANAGER_USER=root" >> yarn-env.sh
修改core-site.xml
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://server103:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_tmp_dir</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
修改hdfs-site.xml
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/data1/hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/data1/hadoop/dn</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>600</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>600</value>
</property>
<property>
<name>dfs.namenode.service.handler.count</name>
<value>600</value>
</property>
<property>
<name>ipc.server.handler.queue.size</name>
<value>300</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
修改mapred-site.xml
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
<description>The runtime framework for executing MapReduce jobs</description>
</property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.88</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>6144</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>6144</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx5530m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2765m</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx2048m -Xms2048m</value>
</property>
<property>
<name>mapred.reduce.parallel.copies</name>
<value>20</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.job.counters.max</name>
<value>1000</value>
</property>
修改yarn-site.xml
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server1</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>371200</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>371200</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>64</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>64</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.client.nodemanager-connect.max-wait-ms</name>
<value>300000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/data1/hadoop/yarn/local,/home/data2/hadoop/yarn/local,/home/data3/hadoop/yarn/local,/home/data4/hadoop/yarn/local,/home/data5/hadoop/yarn/local,/home/data6/hadoop/yarn/local,/home/data7/hadoop/yarn/local,/home/data8/hadoop/yarn/local,/home/data9/hadoop/yarn/local,/home/data10/hadoop/yarn/local,/home/data11/hadoop/yarn/local,/home/data12/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name><value>/home/data1/hadoop/yarn/log,/home/data2/hadoop/yarn/log,/home/data3/hadoop/yarn/log,/home/data4/hadoop/yarn/log,/home/data5/hadoop/yarn/log,/home/data6/hadoop/yarn/log,/home/data7/hadoop/yarn/log,/home/data8/hadoop/yarn/log,/home/data9/hadoop/yarn/log,/home/data10/hadoop/yarn/log,/home/data11/hadoop/yarn/log,/home/data12/hadoop/yarn/log</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>server1</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
修改workers
确认Hadoop版本,3.x以下的版本编辑slaves文件,3.x及以上的编辑workers文件
vi workers
修改workers文件,只保存所有agent节点的IP地址(可用主机名代替),其余内容均删除
server100
server101
server102
拷贝hadoop-3.2.3到server100、server101、server102节点的“/usr/local”目录。
scp -r /usr/local/hadoop-3.2.3 root@server100:/usr/local
scp -r /usr/local/hadoop-3.2.3 root@server101:/usr/local
scp -r /usr/local/hadoop-3.2.3 root@server102:/usr/local
分别登录到server100、server101、server102节点,为hadoop-3.2.3建立软链接。、
cd /usr/local
ln -s hadoop-3.2.3 hadoop
启动Hadoop集群
1、启动ZooKeeper集群。
分别在server100、server101、server102节点上启动ZooKeeper。
cd /usr/local/zookeeper/bin
./zkServer.sh start
2、启动JournalNode。
分别在server100、server101、server102节点上启动JournalNode。
只在第一次进行格式化操作时,需要执行2-4,完成格式化后,下次启动集群,只需要执行1、5、6。
cd /usr/local/hadoop/sbin
./hadoop-daemon.sh start journalnode
3、格式化HDFS
在server1节点上格式化HDFS。
hdfs namenode -format
启动hdfs
start-all.sh
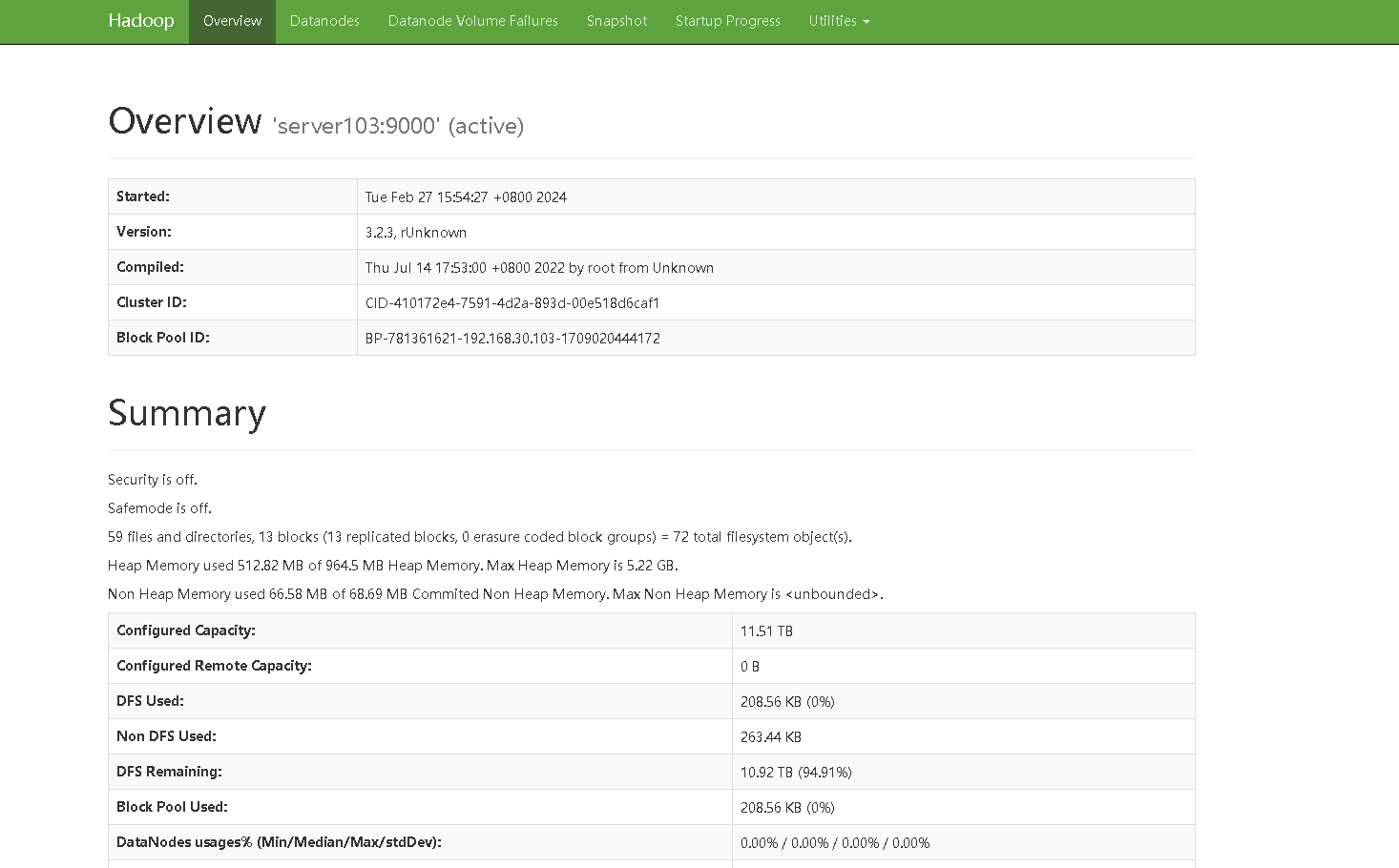
访问web页面验证
http://server103:9870
HBase部署
上传并解压到/usr/local
建立软连接
tar -zxvf hbase-2.3.7-bin.tar.gz
ln -s hbase-2.3.7 hbase
添加hbase到环境变量
vim /etc/profile
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$HBASE_HOME/sbin:$PATH
source /etc/profile
修改hbase配置文件
cd $HBASE_HOME/conf
vim hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_202
export HBASE_MANAGES_ZK=false
export HBASE_LIBRARY_PATH=/usr/local/hadoop/lib/native
vi hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://server1:9000/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase/tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>server100:2181,server101:2181,server102:2181</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
修改regionservers
vim regionservers
server100
server101
server102
拷贝hdfs-site.xml
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/hdfs-site.xml
拷贝hbase-2.3.7到server100、server101、server102节点的“/usr/local”目录。
scp -r /usr/local/hbase-2.3.7 root@server100:/usr/local
scp -r /usr/local/hbase-2.3.7 root@server101:/usr/local
scp -r /usr/local/hbase-2.3.7 root@server102:/usr/local
分别登录到server100、server101、server102节点,为hbase-2.3.7建立软链接
cd /usr/local
ln -s hbase-2.3.7 hbase
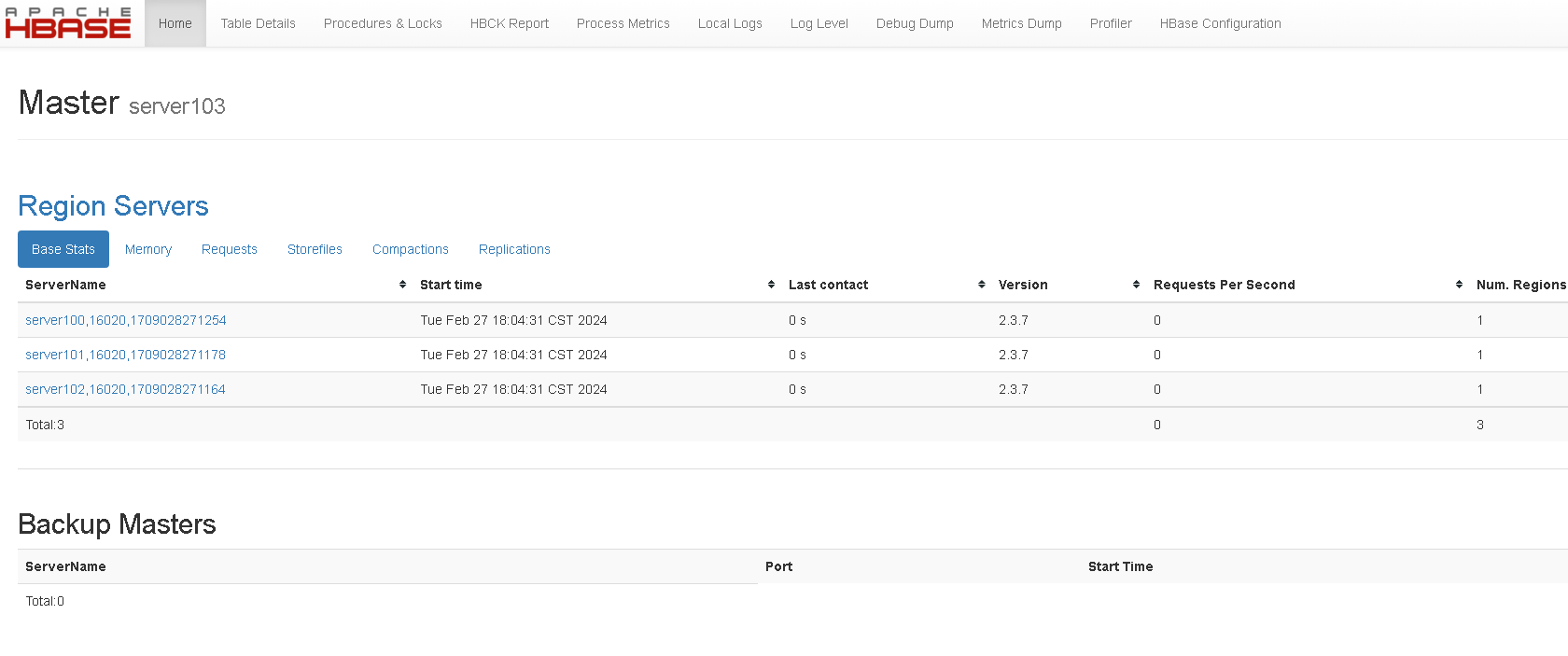
启动hbase
/usr/local/hbase/bin/start-hbase.sh
访问验证
http://server103:16010/