文章目录
- 一、简介
- 二、架构
- 三、Original/Strict Mode
- 四、Seccomp-bpf
- 五、seccomp系统调用
- 六、Linux Capabilities and Seccomp
- 6.1 Linux Capabilities
- 6.2 Linux Seccomp
- 参考资料
一、简介
Seccomp(secure computing)是Linux内核中的一项计算机安全功能,是在Linux内核版本2.6.12中首次引入的一种简单沙箱机制。它允许进程进行一次性的状态转换,进入一种“安全”状态,在此状态下,进程只能执行exit()、sigreturn()、read()和write()这几个与已打开文件描述符相关的系统调用。如果进程尝试执行其他系统调用,内核将仅仅记录该事件,或者终止进程并发送SIGKILL或SIGSYS信号。
随着时间的推移,seccomp得到了扩展:不再是一个固定且非常有限的系统调用集合,而是发展为一种过滤机制,允许进程指定一个任意的系统调用过滤器(以Berkeley Packet Filter程序表示),用于禁止特定的系统调用。这可以用于实现不同类型的安全机制;例如,Chromium网络浏览器的Linux版本就支持此功能,以在沙箱中运行插件。
// /kernel/seccomp.c
/*
* Secure computing mode 1 allows only read/write/exit/sigreturn.
* To be fully secure this must be combined with rlimit
* to limit the stack allocations too.
*/
static const int mode1_syscalls[] = {
__NR_seccomp_read, __NR_seccomp_write, __NR_seccomp_exit, __NR_seccomp_sigreturn,
-1, /* negative terminated */
};
static void __secure_computing_strict(int this_syscall)
{
const int *allowed_syscalls = mode1_syscalls;
do {
if (*allowed_syscalls == this_syscall)
return;
} while (*++allowed_syscalls != -1);
seccomp_log(this_syscall, SIGKILL, SECCOMP_RET_KILL_THREAD, true);
do_exit(SIGKILL);
}
从这个意义上说,seccomp并不是虚拟化系统资源,而是完全隔离进程与系统资源的接触。它通过限制进程能够执行的系统调用来实现安全隔离,从而减小进程的攻击面。
Seccomp常用于对安全性要求较高的环境,例如沙盒应用程序、容器运行时等场景。通过强制限制系统调用的使用,seccomp可以显著增强系统的安全性。
Seccomp模式可以通过prctl(2)系统调用使用PR_SET_SECCOMP参数启用,或者(自Linux内核3.17版本起)通过seccomp(2)系统调用启用。在过去的内核版本中(Linux 2.6.12 to Linux 2.6.22),可以通过写入/proc/self/seccomp文件来启用seccomp模式,但是这种方法在Linux 2.6.23已被prctl()方法取代。在某些内核版本中,seccomp会禁用RDTSC x86指令,该指令用于返回自上电以来经过的处理器周期数,用于高精度计时。
seccomp-bpf是seccomp的扩展,它允许使用可配置的策略通过Berkeley Packet Filter规则来过滤系统调用。它被OpenSSH和vsftpd等软件以及Google Chrome/Chromium浏览器在ChromeOS和Linux上使用。相比之前不再支持Linux的systrace,seccomp-bpf实现了类似的功能,但具有更高的灵活性和性能。
seccomp-bpf通过使用BPF(Berkeley Packet Filter)规则来定义策略,允许对系统调用进行细粒度的过滤和控制。这些规则可以基于进程的需求和安全策略来定义,从而限制进程的系统调用。通过使用BPF规则,seccomp-bpf提供了更大的灵活性,使开发人员能够定义自定义的系统调用策略。
进程的seccomp模式(自Linux 3.8起)。0表示SECCOMP_MODE_DISABLED(禁用),1表示SECCOMP_MODE_STRICT(严格模式),2表示SECCOMP_MODE_FILTER(过滤器模式)。仅当内核编译时启用了CONFIG_SECCOMP内核配置选项时,才提供此字段。
CONFIG_SECCOMP=y
CONFIG_SECCOMP_FILTER=y
在进程的/proc/pid/status文件中,Seccomp字段用于显示进程的seccomp模式。它指示进程当前的seccomp设置。具体取值如下:
(1)0:表示进程禁用了seccomp,即未启用任何seccomp模式。
(2)1:表示进程处于严格模式(SECCOMP_MODE_STRICT)。在此模式下,进程只能调用一组有限的系统调用。
(3)2:表示进程使用了过滤器模式(SECCOMP_MODE_FILTER)。在此模式下,进程使用BPF过滤器定义了允许的系统调用。
# cat /proc/2/status | grep -i seccomp
Seccomp: 0
Seccomp_filters: 0
Linux内核版本 2.6.12 中首次引入Seccomp功能。
Linux内核版本 3.5 中x86-64架构support for seccomp BPF(ARM since Linux 3.8、ARM-64 – since Linux 3.19)
Linux内核版本 3.17 中 add “seccomp” syscall。
二、架构
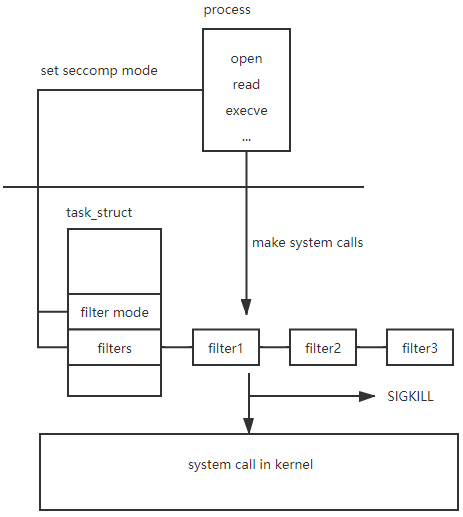
seccomp的基本思想非常简单。下面的图片展示了它的工作原理。首先,进程需要将seccomp策略设置为严格模式或过滤器模式。这会导致内核在task_struct结构中设置seccomp标志。如果进程设置了过滤器模式,内核会将程序添加到task_struct中的seccomp过滤器列表中。然后,对于进程发起的每个系统调用,内核都会基于seccomp过滤器进行检查。
// include/linux/seccomp.h
/**
* struct seccomp - the state of a seccomp'ed process
*
* @mode: indicates one of the valid values above for controlled
* system calls available to a process.
* @filter: must always point to a valid seccomp-filter or NULL as it is
* accessed without locking during system call entry.
*
* @filter must only be accessed from the context of current as there
* is no read locking.
*/
struct seccomp {
int mode;
atomic_t filter_count;
struct seccomp_filter *filter;
};
// include/linux/sched.h
struct task_struct {
......
struct seccomp seccomp;
......
}
(1)进程设置seccomp策略:进程通过seccomp策略指定希望以严格模式还是过滤器模式运行。通常,通过使用适当的参数调用seccomp()系统调用来完成此操作。
(2)内核设置seccomp标志:当进程设置seccomp策略时,内核会更新task_struct数据结构,以指示该进程启用了seccomp。内核使用此标志来确定是否需要对进程发起的系统调用进行seccomp过滤。
(3)内核将程序添加到seccomp过滤器列表(过滤器模式):如果进程将seccomp策略设置为过滤器模式,它会提供一个定义允许的系统调用及其过滤规则的BPF程序。内核将此程序添加到与task_struct相关联的seccomp过滤器列表中。BPF程序指定了进程发起的系统调用的过滤逻辑。
(4)内核针对每个系统调用检查seccomp过滤器:当进程发起系统调用时,内核会检查与进程相关联的seccomp过滤器。如果进程处于严格模式,内核会强制执行预定义的允许的系统调用,并拒绝其他系统调用。如果进程处于过滤器模式,内核会根据过滤规则评估进程提供的BPF程序,以确定是否根据过滤规则允许或拒绝系统调用。
三、Original/Strict Mode
在这种模式下,Seccomp仅允许使用已打开文件描述符的exit()、sigreturn()、read()和write()系统调用。如果进行了任何其他系统调用,进程将被使用SIGKILL信号终止。
Seccomp模式可以通过prctl(2)系统调用使用PR_SET_SECCOMP参数启用,或者(自Linux内核3.17版本起)通过seccomp(2)系统调用启用。
以prctl(2)系统调用为例子:
NAME
prctl - operations on a process
SYNOPSIS
#include <sys/prctl.h>
int prctl(int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5);
DESCRIPTION
prctl() is called with a first argument describing what to do (with values defined in <linux/prctl.h>), and further arguments with a significance depending on the first
one. The first argument can be:
PR_SET_SECCOMP (since Linux 2.6.23)
Set the secure computing (seccomp) mode for the calling thread, to limit the available system calls. The more recent seccomp(2) system call provides a superset
of the functionality of PR_SET_SECCOMP.
The seccomp mode is selected via arg2. (The seccomp constants are defined in <linux/seccomp.h>.)
With arg2 set to SECCOMP_MODE_STRICT, the only system calls that the thread is permitted to make are read(2), write(2), _exit(2) (but not exit_group(2)), and si‐
greturn(2). Other system calls result in the delivery of a SIGKILL signal. Strict secure computing mode is useful for number-crunching applications that may
need to execute untrusted byte code, perhaps obtained by reading from a pipe or socket. This operation is available only if the kernel is configured with CON‐
FIG_SECCOMP enabled.
With arg2 set to SECCOMP_MODE_FILTER (since Linux 3.5), the system calls allowed are defined by a pointer to a Berkeley Packet Filter passed in arg3. This argu‐
ment is a pointer to struct sock_fprog; it can be designed to filter arbitrary system calls and system call arguments. This mode is available only if the kernel
is configured with CONFIG_SECCOMP_FILTER enabled.
If SECCOMP_MODE_FILTER filters permit fork(2), then the seccomp mode is inherited by children created by fork(2); if execve(2) is permitted, then the seccomp
mode is preserved across execve(2). If the filters permit prctl() calls, then additional filters can be added; they are run in order until the first non-allow
result is seen.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <linux/seccomp.h>
#include <sys/prctl.h>
int main(int argc, char **argv)
{
int output = open("output.txt", O_WRONLY);
const char *val = "test";
//enables strict seccomp mode
printf("Calling prctl() to set seccomp strict mode...\n");
prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT);
//This is allowed as the file was already opened
printf("Writing to an already open file...\n");
write(output, val, strlen(val)+1);
//This isn't allowed
printf("Trying to open file for reading...\n");
int input = open("output.txt", O_RDONLY);
printf("You will not see this message--the process will be killed first\n");
return 0;
}
# gcc seccomp.c
# ./a.out
Calling prctl() to set seccomp strict mode...
Writing to an already open file...
Trying to open file for reading...
Killed
四、Seccomp-bpf
每个用户空间进程都暴露了大量的系统调用,其中许多在进程的整个生命周期中都未被使用。随着系统调用的变化和成熟,会发现并消除一些错误。某些特定的用户空间应用程序通过减少可用系统调用的集合来受益。这样的集合减少了应用程序所暴露给内核的总体界面。系统调用过滤用于这些应用程序。
Seccomp过滤提供了一种进程可以指定传入系统调用过滤器的方法。该过滤器以Berkeley Packet Filter(BPF)程序的形式表示,与套接字过滤器类似,但操作的数据与所进行的系统调用相关:系统调用编号和系统调用参数。这允许使用具有长期被用户空间使用和简单数据集的过滤程序语言对系统调用进行表达式过滤。
此外,BPF使得seccomp的用户无法成为时钟检查-使用时间(TOCTOU)攻击的受害者,而这在系统调用拦截框架中很常见。BPF程序不允许解引用指针,这限制了所有过滤器仅能直接评估系统调用参数。
系统调用过滤并不是一个沙箱。它提供了一种明确定义的机制,用于最小化内核暴露的接口。它旨在成为沙箱开发者使用的工具。除此之外,逻辑行为和信息流的策略应该通过其他系统加固技术的组合以及可能的自选LSM(Linux安全模块)进行管理。表达能力强、动态的过滤器为这条路径提供了进一步的选项,这可能被错误地解释为更完整的沙箱解决方案。
这种模式允许使用可配置的策略,通过使用基于Berkeley Packet Filter规则的实现来过滤系统调用。
通过配置策略和使用Berkeley Packet Filter规则,可以对系统调用进行过滤。Berkeley Packet Filter(BPF)是一种灵活的过滤机制,可以根据需要定义系统调用的访问规则。
通过定义适当的BPF规则,可以实现对系统调用的细粒度控制。可以选择允许或禁止特定的系统调用,限制对敏感资源的访问,或根据自定义的安全策略来选择合适的系统调用。这种可配置性使得seccomp能够适应各种不同的安全需求。
(1)
apt-get install libseccomp-dev
#include <seccomp.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
int main(int argc, char **argv)
{
/* initialize the libseccomp context */
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_KILL);
/* allow exiting */
printf("Adding rule : Allow exit_group\n");
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit_group), 0);
/* allow getting the current pid */
//printf("Adding rule : Allow getpid\n");
//seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(getpid), 0);
printf("Adding rule : Deny getpid\n");
seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EBADF), SCMP_SYS(getpid), 0);
/* allow changing data segment size, as required by glibc */
printf("Adding rule : Allow brk\n");
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(brk), 0);
/* allow writing up to 512 bytes to fd 1 */
printf("Adding rule : Allow write upto 512 bytes to FD 1\n");
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(write), 2,
SCMP_A0(SCMP_CMP_EQ, 1),
SCMP_A2(SCMP_CMP_LE, 512));
/* if writing to any other fd, return -EBADF */
printf("Adding rule : Deny write to any FD except 1 \n");
seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EBADF), SCMP_SYS(write), 1,
SCMP_A0(SCMP_CMP_NE, 1));
/* load and enforce the filters */
printf("Load rules and enforce \n");
seccomp_load(ctx);
seccomp_release(ctx);
//Get the getpid is denied, a weird number will be returned like
//this process is -9
printf("this process is %d\n", getpid());
return 0;
}
# gcc seccomp1.c -lseccomp
# ./a.out
Adding rule : Allow exit_group
Adding rule : Deny getpid
Adding rule : Allow brk
Adding rule : Allow write upto 512 bytes to FD 1
Adding rule : Deny write to any FD except 1
Load rules and enforce
this process is -9
(2)
新增了一个额外的seccomp模式,并使用与严格模式相同的prctl(2)调用进行启用。如果体系结构具有CONFIG_HAVE_ARCH_SECCOMP_FILTER,那么可以添加以下过滤器:
CONFIG_HAVE_ARCH_SECCOMP_FILTER=y
PR_SET_SECCOMP:
现在接受一个额外的参数,用于指定使用BPF程序的新过滤器。BPF程序将在反映系统调用编号、参数和其他元数据的struct seccomp_data上执行。然后,BPF程序必须返回可接受的值之一,以通知内核应采取的操作。
使用方法:
prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, prog);
'prog’参数是指向struct sock_fprog的指针,其中包含过滤器程序。如果程序无效,调用将返回-1并将errno设置为EINVAL。
如果允许fork/clone和execve通过@prog,任何子进程将受到与父进程相同的过滤器和系统调用ABI的限制。
在使用之前,任务必须调用prctl(PR_SET_NO_NEW_PRIVS, 1)或以其命名空间中的CAP_SYS_ADMIN特权运行。如果这些条件不成立,将返回-EACCES。此要求确保过滤器程序不能应用于比安装它们的任务拥有更高特权的子进程。
此外,如果附加的过滤器允许prctl(2),则可以叠加其他过滤器,这将增加评估时间,但允许在进程执行期间进一步减少攻击面。
以上调用成功时返回0,错误时返回非零值。
五、seccomp系统调用
NAME
seccomp - operate on Secure Computing state of the process
SYNOPSIS
#include <linux/seccomp.h> /* Definition of SECCOMP_* constants */
#include <linux/filter.h> /* Definition of struct sock_fprog */
#include <linux/audit.h> /* Definition of AUDIT_* constants */
#include <linux/signal.h> /* Definition of SIG* constants */
#include <sys/ptrace.h> /* Definition of PTRACE_* constants */
#include <sys/syscall.h> /* Definition of SYS_* constants */
#include <unistd.h>
int syscall(SYS_seccomp, unsigned int operation, unsigned int flags,
void *args);
Note: glibc provides no wrapper for seccomp(), necessitating the
use of syscall(2).
DESCRIPTION
The seccomp() system call operates on the Secure Computing (seccomp) state of the calling process.
// kernel/seccomp.c
/* Common entry point for both prctl and syscall. */
static long do_seccomp(unsigned int op, unsigned int flags,
void __user *uargs)
{
switch (op) {
case SECCOMP_SET_MODE_STRICT:
if (flags != 0 || uargs != NULL)
return -EINVAL;
return seccomp_set_mode_strict();
case SECCOMP_SET_MODE_FILTER:
return seccomp_set_mode_filter(flags, uargs);
......
}
}
SYSCALL_DEFINE3(seccomp, unsigned int, op, unsigned int, flags,
void __user *, uargs)
{
return do_seccomp(op, flags, uargs);
}
seccomp()系统调用用于操作调用进程的安全计算(seccomp)状态。它支持以下操作值:
(1)
SECCOMP_SET_MODE_STRICT:将进程设置为严格的安全计算模式。在此模式下,调用线程只能调用一组有限的系统调用,包括read(2)、write(2)、_exit(2)(但不包括exit_group(2))和sigreturn(2)。其他系统调用将导致发送SIGKILL信号。严格的安全计算模式适用于可能需要执行不受信任的字节码(例如从管道或套接字读取)的数值计算应用程序。
需要注意的是,虽然调用线程不能再调用sigprocmask(2),但它可以使用sigreturn(2)来阻塞除了SIGKILL和SIGSTOP之外的所有信号。这意味着alarm(2)(例如)不足以限制进程的执行时间。为可靠地终止进程,必须使用SIGKILL。可以通过使用带有SIGEV_SIGNAL和sigev_signo设置为SIGKILL的timer_create(2),或者使用setrlimit(2)设置RLIMIT_CPU的硬限制来实现。
(2)
SECCOMP_SET_MODE_FILTER:将进程设置为通过指针传递的伯克利数据包过滤器(BPF)定义的系统调用模式。args参数是指向struct sock_fprog的指针,该结构可以设计用于过滤任意系统调用和系统调用参数的BPF程序。如果过滤器无效,seccomp()调用将失败,并返回EINVAL错误。
如果过滤器允许fork(2)或clone(2),则子进程将受到与父进程相同的系统调用过滤器的限制。如果允许execve(2),则在调用execve(2)后仍将保留现有的过滤器。
要使用SECCOMP_SET_MODE_FILTER操作,调用线程必须具有用户命名空间中的CAP_SYS_ADMIN特权,或者线程必须已经设置了no_new_privs位。如果no_new_privs位不是由该线程的祖先进程设置的,线程必须执行以下调用:
prctl(PR_SET_NO_NEW_PRIVS, 1);
否则,SECCOMP_SET_MODE_FILTER操作将失败,并返回EACCES错误。此要求确保非特权进程不能应用恶意过滤器,然后使用execve(2)调用调用特权程序,从而潜在地危害该程序的安全性。 (例如,这样的恶意过滤器可能会导致对setuid(2)的调用将调用者的用户ID设置为非零值,但实际上返回0而不进行系统调用。因此,程序可能会被欺骗,在可能影响它执行危险操作的情况下保留超级用户特权。)
如果附加的过滤器允许prctl(2)或seccomp(),则可以添加其他过滤器。这将增加评估时间,但允许在线程执行期间进一步减少攻击面。
此操作仅在内核配置了启用CONFIG_SECCOMP_FILTER时可用。
#include <linux/audit.h>
#include <linux/filter.h>
#include <linux/seccomp.h>
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/prctl.h>
#include <sys/syscall.h>
#include <unistd.h>
#define X32_SYSCALL_BIT 0x40000000
#define ARRAY_SIZE(arr) (sizeof(arr) / sizeof((arr)[0]))
static int
install_filter(int syscall_nr, unsigned int t_arch, int f_errno)
{
unsigned int upper_nr_limit = 0xffffffff;
/* Assume that AUDIT_ARCH_X86_64 means the normal x86-64 ABI
(in the x32 ABI, all system calls have bit 30 set in the
'nr' field, meaning the numbers are >= X32_SYSCALL_BIT). */
if (t_arch == AUDIT_ARCH_X86_64)
upper_nr_limit = X32_SYSCALL_BIT - 1;
struct sock_filter filter[] = {
/* [0] Load architecture from 'seccomp_data' buffer into
accumulator. */
BPF_STMT(BPF_LD | BPF_W | BPF_ABS,
(offsetof(struct seccomp_data, arch))),
/* [1] Jump forward 5 instructions if architecture does not
match 't_arch'. */
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, t_arch, 0, 5),
/* [2] Load system call number from 'seccomp_data' buffer into
accumulator. */
BPF_STMT(BPF_LD | BPF_W | BPF_ABS,
(offsetof(struct seccomp_data, nr))),
/* [3] Check ABI - only needed for x86-64 in deny-list use
cases. Use BPF_JGT instead of checking against the bit
mask to avoid having to reload the syscall number. */
BPF_JUMP(BPF_JMP | BPF_JGT | BPF_K, upper_nr_limit, 3, 0),
/* [4] Jump forward 1 instruction if system call number
does not match 'syscall_nr'. */
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, syscall_nr, 0, 1),
/* [5] Matching architecture and system call: don't execute
the system call, and return 'f_errno' in 'errno'. */
BPF_STMT(BPF_RET | BPF_K,
SECCOMP_RET_ERRNO | (f_errno & SECCOMP_RET_DATA)),
/* [6] Destination of system call number mismatch: allow other
system calls. */
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
/* [7] Destination of architecture mismatch: kill process. */
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS),
};
struct sock_fprog prog = {
.len = ARRAY_SIZE(filter),
.filter = filter,
};
if (syscall(SYS_seccomp, SECCOMP_SET_MODE_FILTER, 0, &prog)) {
perror("seccomp");
return 1;
}
return 0;
}
int
main(int argc, char *argv[])
{
if (argc < 5) {
fprintf(stderr, "Usage: "
"%s <syscall_nr> <arch> <errno> <prog> [<args>]\n"
"Hint for <arch>: AUDIT_ARCH_I386: 0x%X\n"
" AUDIT_ARCH_X86_64: 0x%X\n"
"\n", argv[0], AUDIT_ARCH_I386, AUDIT_ARCH_X86_64);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl");
exit(EXIT_FAILURE);
}
if (install_filter(strtol(argv[1], NULL, 0),
strtoul(argv[2], NULL, 0),
strtol(argv[3], NULL, 0)))
exit(EXIT_FAILURE);
execv(argv[4], &argv[4]);
perror("execv");
exit(EXIT_FAILURE);
}
# ./a.out
Usage: ./a.out <syscall_nr> <arch> <errno> <prog> [<args>]
Hint for <arch>: AUDIT_ARCH_I386: 0x40000003
AUDIT_ARCH_X86_64: 0xC000003E
# ./a.out 59 0xC000003E 99 /bin/whoami
execv: Cannot assign requested address
# ./a.out 1 0xC000003E 99 /bin/whoami
# ./a.out 295 0xC000003E 99 /bin/whoami
root
六、Linux Capabilities and Seccomp
6.1 Linux Capabilities
Linux capabilities是一项功能,它将以root用户身份运行的进程的权限分解为更小的权限组。这样,具有root特权的进程可以被限制只获取执行其操作所需的最小权限。
在传统的UNIX系统中,root用户拥有完全的系统权限,这可能会导致潜在的安全风险。为了减少对系统的潜在威胁,Linux引入了capabilities功能。
通过使用capabilities,root用户可以被划分为多个小组权限,每个权限组只包含一组特定的权限。这使得可以将root特权限制为只获取执行特定操作所需的最小权限集合。
例如,常见的capabilities包括:
CAP_NET_ADMIN:允许进行网络管理操作,如配置网络接口、设置防火墙规则等。
CAP_SYS_ADMIN:允许进行系统管理操作,如挂载文件系统、更改主机名等。
CAP_DAC_OVERRIDE:允许绕过文件权限检查,访问任何文件。
CAP_SETUID:允许更改进程的有效用户ID(UID)。
通过将这些capabilities分配给进程,即使以root特权运行,进程也只能执行与其所需操作相关的特定权限,而不是完整的root权限。
这种细粒度的权限控制有助于减少潜在的安全漏洞和提高系统的安全性。它使管理员能够更好地控制进程的权限,并将特权最小化,从而降低了攻击者滥用root权限造成的风险。
详细请参考:Linux 安全 - Capabilities机制
6.2 Linux Seccomp
安全计算模式(seccomp)是一种内核功能,允许您对容器内的系统调用进行过滤。受限和允许的调用的组合以配置文件的形式存在,您可以将不同的配置文件传递给不同的容器。seccomp提供比Capabilities更精细的控制,使攻击者只能从容器中使用有限数量的系统调用。
seccomp通过定义配置文件来工作,配置文件指定了允许或拒绝进程进行的系统调用。这些配置文件可以根据不同容器的具体要求进行自定义。通过为不同的容器应用不同的配置文件,可以根据其特定需求实施不同级别的系统调用过滤。
seccomp的配置文件可以根据系统调用的调用号、参数或其他属性来允许或拒绝特定的系统调用。这种细粒度的控制使管理员能够准确地定义容器内进程的系统调用行为。
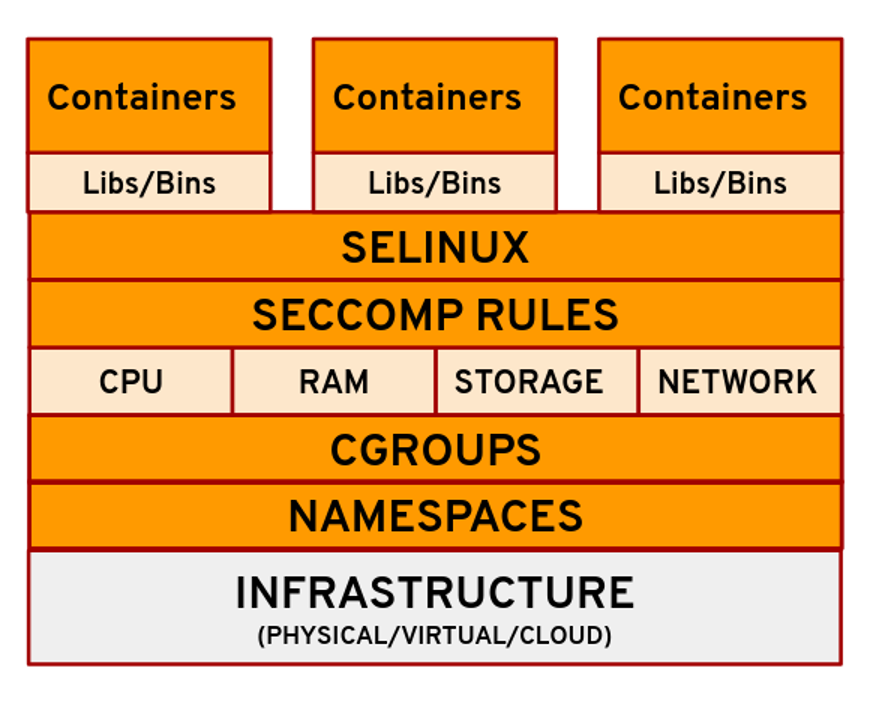
与Capabilities相比,seccomp在更低的层级上通过过滤实际的系统调用来进行操作。即使运行在容器中的进程具有root特权或提升的能力,通过seccomp可以将其限制为一组有限的允许的系统调用,有效地减小了潜在的攻击面。
通过将seccomp与其他安全机制(如Capabilities、namespace isolation和mandatory access control)结合使用,可以构建更健壮和安全的容器环境,减小安全漏洞的影响,并限制潜在攻击者的能力。
如下图所示:
参考资料
linux 安全模块 – seccomp 详解
https://www.man7.org/linux/man-pages/man2/seccomp.2.html
https://www.kernel.org/doc/html/latest/userspace-api/seccomp_filter.html
https://book.hacktricks.xyz/linux-hardening/privilege-escalation/docker-security/seccomp
https://opensource.com/article/21/8/container-linux-technology