论文链接
搁置了许久的毕设,又要开始重新启航。
2022年的最后一段时间过得真是很崎岖,2023希望大家平安喜乐。
课设还未结束,但是毕设不能再拖,开工啦!
这又是一篇综述,有关推荐系统中的公平性,之前有两篇综述都更宏观,讲了机器学习领域的公平性,当然推荐系统也在其中,这次就读的细一点,从推荐系统方向来看,也许不久的将来我也会去做推荐系统与RL的交叉了。
写在前面:看这篇综述时,有参考这篇知乎内容。
摘要
关键内容是之前未有过系统的总结fairness in recommendation这一话题,很难让新的研究者了解到这一领域并展开研究。
本文先从机器学习领域的公平性谈起,有一个宏观的公平性研究概念,再介绍推荐系统中的公平性,重点关注当前公平性定义的分类、提高公平性的技术以及推荐系统中用于公平性研究的数据集。最后还探讨了公平性研究面临的挑战和机遇,以期促进公平推荐研究领域的发展。
引言
- 推荐系统的不公平现象:
① 工作推荐系统:种族/性别歧视
② 电子商务推荐系统:看popular
③ 新闻推荐系统:可能由于“回声室效应” - 本文的脉络:
① 简明介绍ML中的公平性研究,尤其是分类与排序任务中;
② 从四个角度介绍推荐系统的公平性研究:分类,方法,数据集与挑战 - However, most of the works on bias in recommendation focus on improving the recommendation accuracy or robustness in out-of-distribution scenario through debiasing methods instead of promoting fairness.
机器学习中的公平性研究
不公平的原因
caused by various forms of biases
- 数据偏差
统计偏差: 发生在数据收集和存储阶段,由于实验设计或者数据处理时,往往会使得最终的数据并不能代表原始数据的真实分布。
早已存在的偏差: 数据产生阶段存在偏见,即原始数据本身就反映了某种偏差。 - 算法偏差
举例:
①Presentation Bias表示偏差:
当展示的信息以一种具有偏差性质的方法展示时,就会出现表示偏差。
例如,排序偏差,越靠前的位置会得到更多的曝光,导致更多的用户点击,而靠后的则相反,虽然这些靠后的物品和靠前的物品在相关度上可能相差无几;流行度偏差(在推荐系统中),即相比那些不那么受欢迎但同样相关甚至更相关的item,互动更多的item反而会被更频繁地推荐,获得更多曝光。
②Evaluation Bias评估偏差 :
当在模型评估中使用不合适的benchmark时,通常会出现评估偏差。
数据偏差和算法偏差其实形成了一个反馈环:用户行为本身具有一定偏见,导致收集的是本身自带偏差的数据,被用来训练算法(数据收集和存储阶段),用户行为又会受到有偏算法的影响,又会引入新的数据偏差(数据产生阶段)。面对相互交织在一起的偏差,理清彼此之间如何相互影响,并针对性解决是非常重要的。
- 其他原因
例如,不同的公平要求相互冲突,即不能同时得到满足。
公平机器学习方法
- 预处理方法:针对训练数据进行去偏
方法:①改变某些数据点的标签;②映射原始数据到新的无偏空间中。
优点:转换后的数据可以用于训练任何下游(downstream)算法,而无需进行一定的假设。
缺点:无法确保准确度;无法消除测试集数据上的不公平。 - 在处理方法: through modifying the learning process
将公平性指标纳入到学习任务的目标函数中;
需平衡准确度与公平性;
主要的缺点是这种方法通常会导致一个非凸的优化问题,而不能保证最优性。 - 后处理方法: apply transformations to the model output
优点:把中间推荐模型视作黑盒,具有模型无关的灵活性;不需要修改模型和数据,实现相对较好的准确度和公平。
缺点:当测试阶段无法获得敏感信息(会引起偏见的那些特征,e.g.,性别、种族)时,那算法就不能应用。
公平性定义
no consensus on fairness definitions
三类定义:Group Fairness; Individual Fairness; and Hybrid Fairness
- Group Fairness组公平
研究对象通常根据一定的分组方法被分为不同的组,最常见地,我们会根据某个敏感特征划分。组公平的基本思想是要保护组和优势组能够被平等对待。
例如:研究在招聘决策系统中的性别歧视问题,首先将候选人根据他们的性别分到不同的组,然后以组的工资或招聘率来衡量组公平。 - Individual Fairness个体公平
similar individuals should be treated similarly
相似度是通过对象的特征或者特征组进行定义的
注意:组公平和个体公平定义是截然不同的两个概念。讨论个体公平时,我们会把相似个体分到一个组里,然后要求这个组里的个体都应该被公平对待;而组公平是要在组这个层面上,令不同组能够被公平对待。个体公平可能不会保证组公平,可能同一组的人得到公平的对待,但有些组比其他组好得多即无法保证组公平。反之亦然,因此到底要定义组公平还是个体公平,需要谨慎选择。
- Hybrid Fairness混合公平
目的:multiple fairness definitions should be satisfied at the same time
例如,both user-side and item-side 等。
但,同公平定义可能是相互矛盾的。
分类任务中的公平性
推荐问题有时可以被建模为一个分类任务,例如,当我们试图预测用户是否会点击一个item时。
公平定义
- Group fairness组公平定义
绝大多数关于公平性分类任务的定义都是限制在组公平定义上。
组公平定义往往会涉及到分类算法预测的阳性率指标Pr( y ^ \widehat{y} y =1)和混淆矩阵相关指标(TPR,FPR,TNR,FNR),前者希望不同组的预测阳性率相同,后者希望能在更细粒度层面缩小不同组的差异。
① predicted positive rate-based metrics:
Statistical Parity(Demographic Parity or No Disparate Impact);
② confusion matrix-based metrics:
Equal Opportunity; Equalized Odds; Overall Accuracy Equality; Equalizing Disincentives; Treatment Equality;
这些具体定义有在我的这篇博客另一篇综述里介绍,本次博客主要详细记录推荐系统的公平性研究。 - Individual fairness个体公平定义
举例:
① Counterfactual Fairness 反事实公平
对任意个体,在反事实世界和真实世界中,预测结果应该一样:
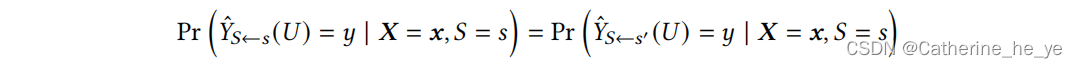 常用的实现反事实公平的技术有:因果推断中的干预intervention、直接移除敏感属性以及其后代相关属性、变分编码器variation autoencoders、对抗学习adversarial learning、数据预处理、因果正则化causal regularization、数据增强等。
常用的实现反事实公平的技术有:因果推断中的干预intervention、直接移除敏感属性以及其后代相关属性、变分编码器variation autoencoders、对抗学习adversarial learning、数据预处理、因果正则化causal regularization、数据增强等。
② Fairness Through Awareness
要求任意两个非敏感特征相近的个体应该得到相似的预测结果
个体之间的差异程度d(x1,x2)应该是预测结果差异值F( y 1 ^ \widehat{y_1} y1 , y 2 ^ \widehat{y_2} y2 )的上界:

促进分类任务中公平性的方法
- 预处理阶段:
① massaging:将敏感特征S=s的个体标签从"-“改为”+“,其余S!=s的集合里中随机选取相同数量的个体,把”+“改为”-"
② re-weighting:减少敏感特征与标签之间的依赖关系。将S=s集合中标签为"+“的实例赋更高的权重(与S=s且标签为”-“的集合相比),而将S!=s集合中标签为”+“的实例赋更低的权重(与S!=s且标签为”-"的集合相比) - 在处理阶段:
对目标函数施以公平性约束条件 - 后处理阶段:
常用方法有:调整分类阈值、特征重加权。
特征重加权:需要找到影响公平性因素的特征,直接丢弃或者减小其权重。
排序任务中的公平性
Recommendation algorithms can usually be considered as a type of ranking problem.
排序任务中的公平定义
- 排序任务可分为两类:
① Score-based Ranking:score直接用给定的函数计算得到
② Learning to Rank:通过模型预估得到score - 本节主要探讨Learning to Rank中的排序公平性问题
- 现有大多数公平排序方法都是用list-wise的定义,即衡量结果公平需要使用所有的结果列表。
- 基于概率的公平Probability-based Fairness:
protected candidates在排序结果中的出现比例要在给定的最大/最小范围内(只能从组公平角度考虑):
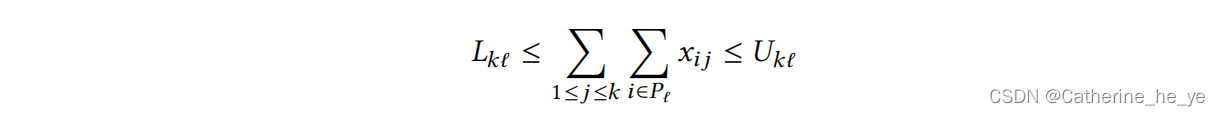
- 基于曝光/注意的公平Exposure/Attention-based Fairness:
既可以量化个体公平还可以量化组公平
曝光资源是极其有限的,因此,基于曝光的公平指标是与不同组的曝光度相关的,理想情况是各组的曝光值正比于其与搜索词的相关度。
基于曝光的组公平定义如下:
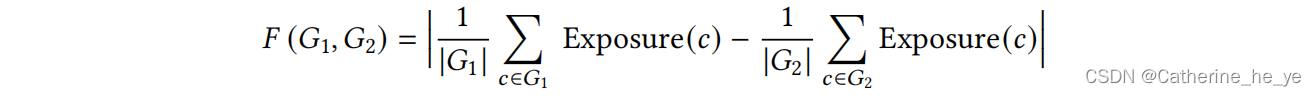
基于曝光的个体公平如下:
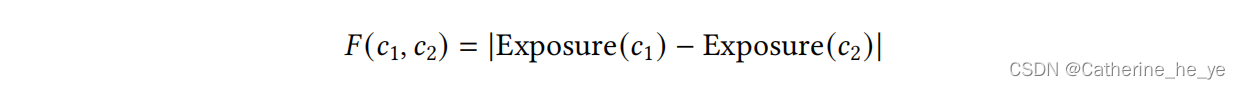
方法
-
预处理阶段:
常用方法为将用户记录映射到一个低秩表征空间中,
低秩表征可形式化为概率聚类问题,对于每个样本xi,xi被分配到某个簇的概率ui反应了该样本与簇之间的distance,因此各个样本的理想低秩表征即映射函数可以写为
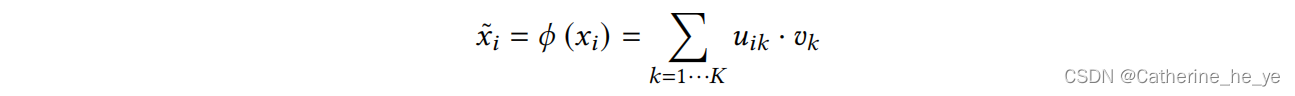 追求公平即给定两样本 xi 和 xj,用 xi* 和 xj* 表示只包含非敏感特征的表征,那么要让:
追求公平即给定两样本 xi 和 xj,用 xi* 和 xj* 表示只包含非敏感特征的表征,那么要让:
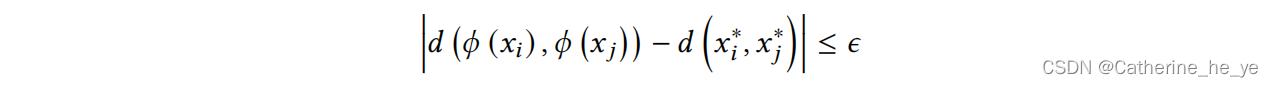 公平目标可定为损失函数的形式:
公平目标可定为损失函数的形式:
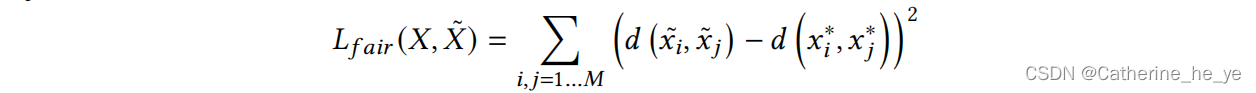
-
在处理阶段:
从零开始学习一个公平的排名模型,例如在目标函数中加入公平限制项 -
后处理阶段:
对排序结果进行重排序实现公平
给定单个查询q,排序算法用于得出排序结果r,r对q的效用值记作U(r|q),公平排序是要把公平约束作为优化目标之一,然后模型最大化效用和公平值。
一种方法是学习一个概率排序矩阵P,其中Pi,j表示第i个文档放在第j个位置的概率,这个矩阵需要满足行之和和列之和均为1,约束问题形式化如下:
 公平约束是要以最优化某个公平定义为目标,论文中是以最简单的统计均等为例,希望各组的曝光期望相等。文档di的曝光值定义如下
公平约束是要以最优化某个公平定义为目标,论文中是以最简单的统计均等为例,希望各组的曝光期望相等。文档di的曝光值定义如下
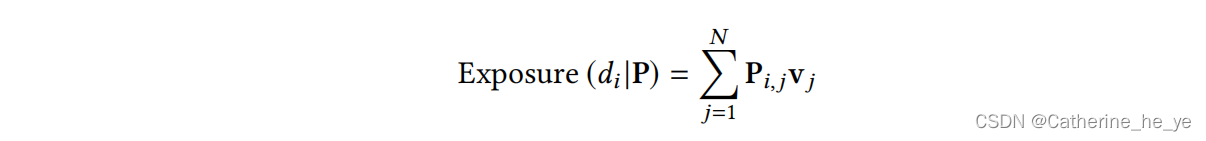
其中vj表示第j个位置的权重大小。自然我们可以得到第Gk组的曝光和
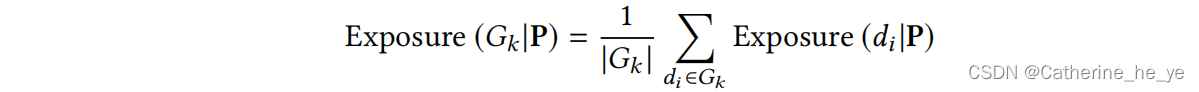
那么统计均等就是
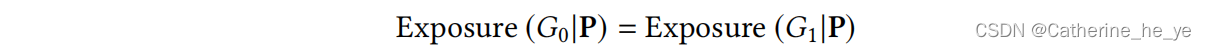
很多情况下,这种约束问题最终转化为了线性规划约束问题,需要依赖各种工具进行求解。