单周期处理器
简要描述单周期处理器的执行过程:
-
PC从指令存储器中读取指令
-
取指后译码得出相关的控制信号+读取regfile(寄存器堆)
-
运算器对regfile中取出的操作数进行计算,
将计算的结果写回通用寄存器堆或者得到访存指令的地址或者得到转移指令的跳转目标 -
load指令访问数据存储器后,将结果写回到通用寄存器,通用寄存器堆写入数据在计算结果和访存结果之间二选一。
【注】:新的指令地址可能是顺序的pc+4,也可以是转移指令计算出来的跳转目标
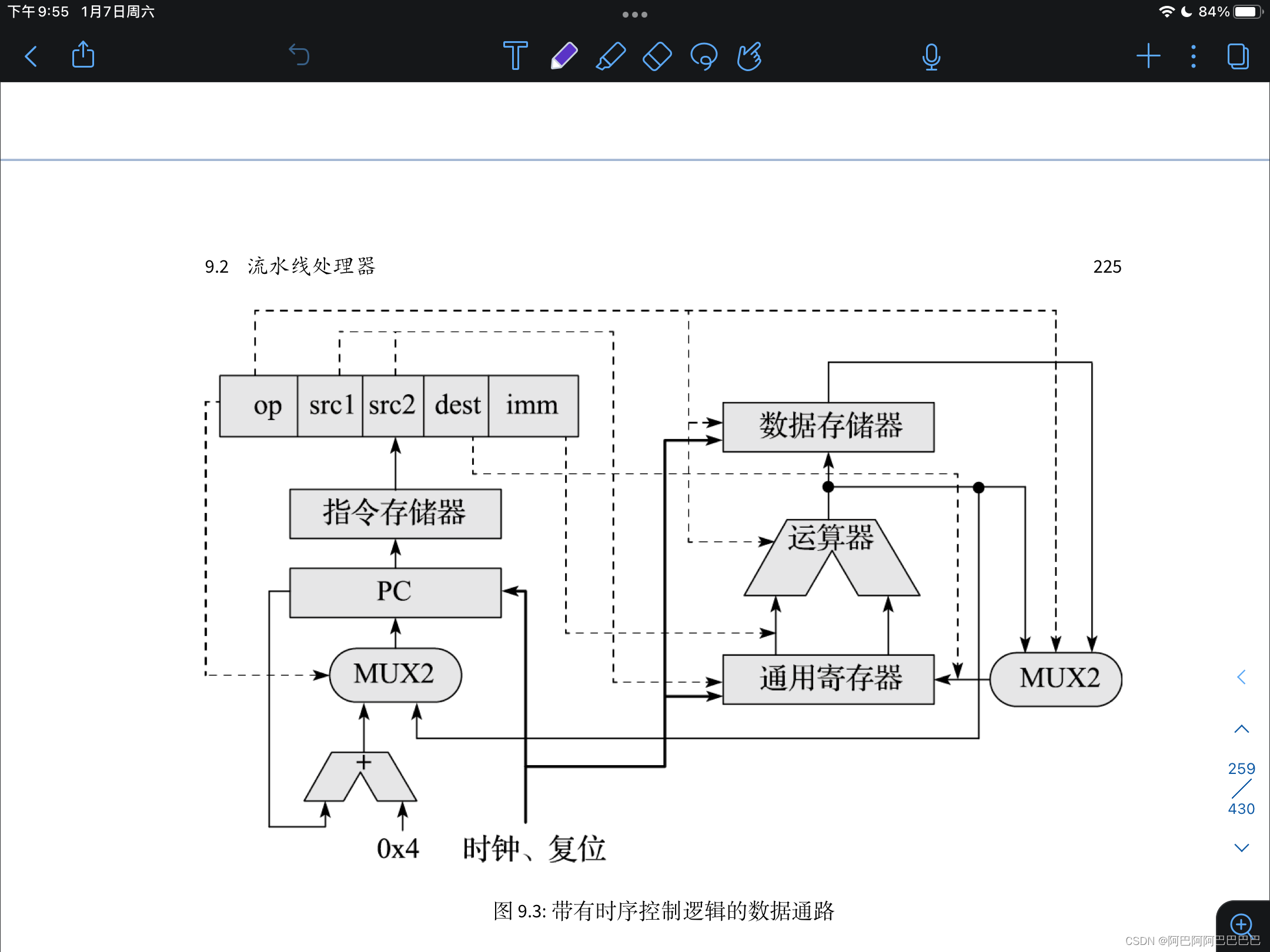
简单的CPU数据通路如下图:

改进一下,带时序控制逻辑的数据通路:
clk:更新PC触发器,写寄存器以及访存指令需要时钟
rst:确保处理器每次上电后都是从相同的位置取第一条指令
第一个时钟周期:取指、译码、执行、访存、生成结果(回写)
第二个时钟周期上升沿到来时:将上一个时钟周期的结果写入regfile中的寄存器堆,执行可能的数据存储写操作
第二个时钟周期内:执行第二条指令,步骤和第一个指令相似。
单周期处理器的每一条指令基本都在一拍内完成
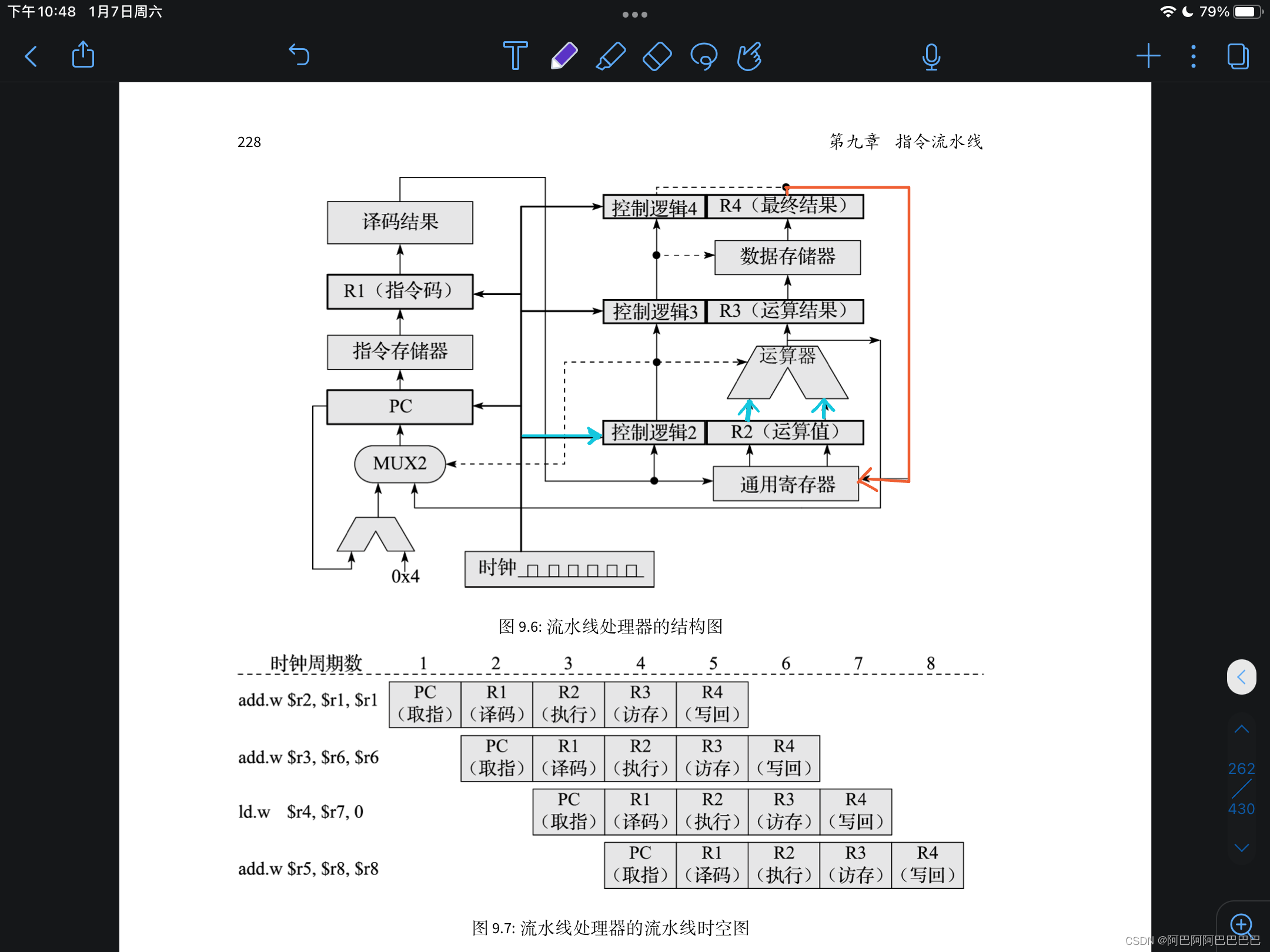
流水线处理器
很显然,单周期处理器中每个周期要完成很多的组合逻辑工作,如果将每个时钟周期的间隔拉长,处理器的主频无法提高,所以引入流水线。
多周期处理器
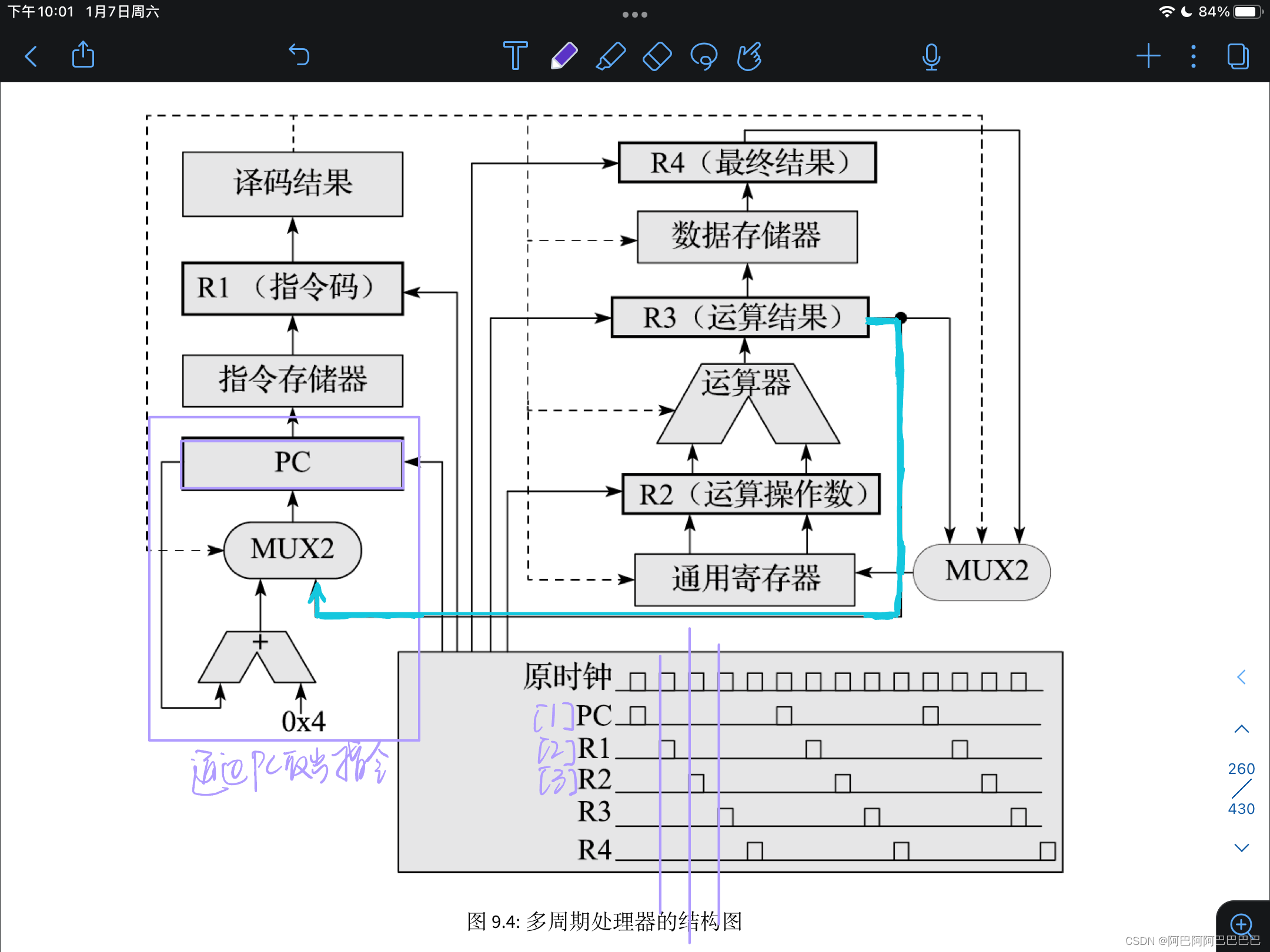
- 第一个时钟周期:通过PC取出指令,在第二个时钟上升沿
锁存到指令码触发器R1 - 第二个时钟周期:将R1译码并生成控制逻辑(译码出需要执行什么类型的操作),读取通用寄存器,读取的res在第三个时钟周期的上升沿锁存到触发器R2
- 第三个时钟周期:使用控制逻辑和R2进行运算
分频时钟:将原始的时钟通过分频的方式产生5个时钟,控制PC、R1-R5这5个触发器。(事实上就用了一个时钟周期,只是用分频时钟将它变成了5个,很划算)。
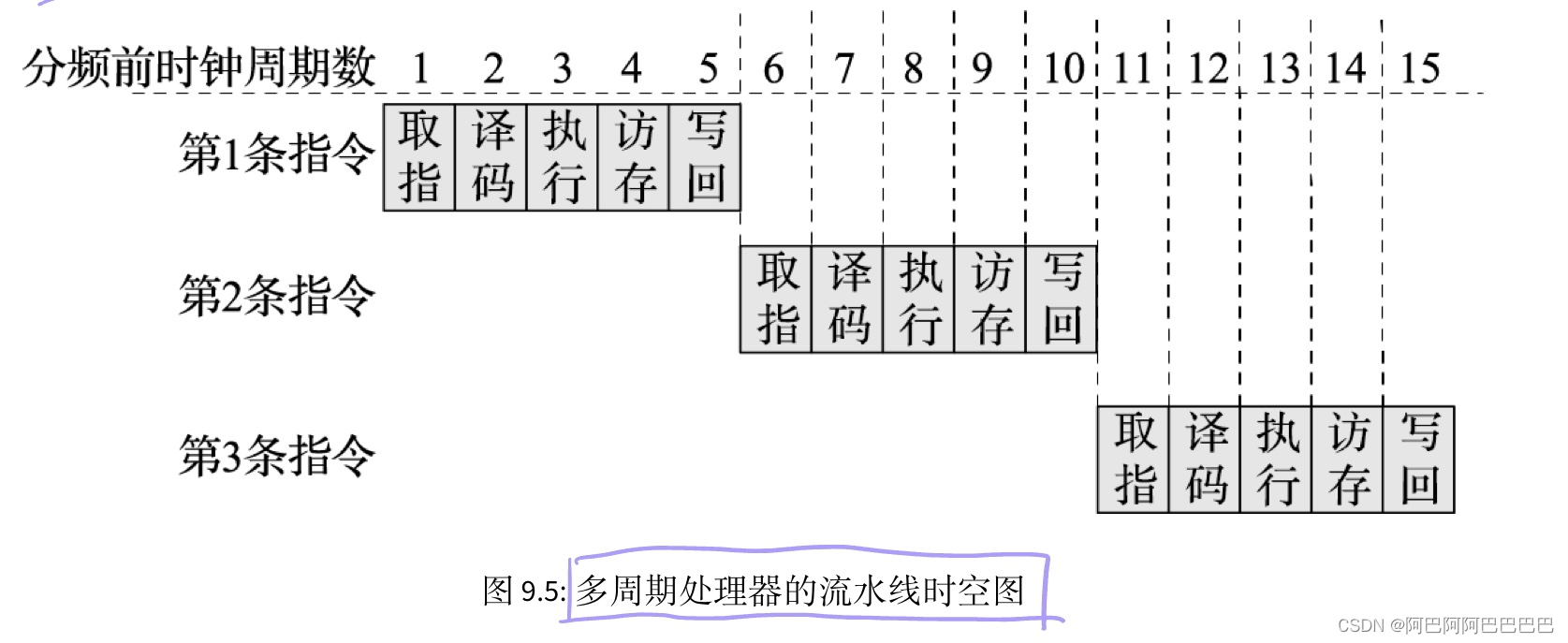
五级流水线的时空图:
流水线处理器
这样每条指令的执行时间并不降低,所以需要将同一时刻不同指令的不同执行阶段“重叠”起来,进一步提高处理器执行效率
指令相关和流水线冲突
指令相关
指令之间的相关分为3类:
- 数据相关:如果两条指令访问同一个寄存器或者内存单元,且这两条指令中至少有一条是写寄存器或者内存单元的指令,那么就一定存在数据相关。
add.w $r2,$r1,$r1
add.w $r3,$r2,$r2
以上就存在数据相关,因为1中r2寄存器的值还没计算出来,2中无法使用r2计算出正确的r3值。
- 控制相关:如果两条指令中一条是转移指令且另一条指令是否被执行取决于该转移指令的执行结果。
- 结构相关:如果两条指令使用同一个硬件资源。
数据相关
分为三种:
- RAW(read after write)
- WAW(write after write)
- WAR(write after read)
主要分析RAW引起的流水线冲突以及其解决方法
add.w $r2,$r1,$r1
add.w $r3,$r2,$r2
ld.w $r4,$r3,0
add.w $r5,$r4,$r4
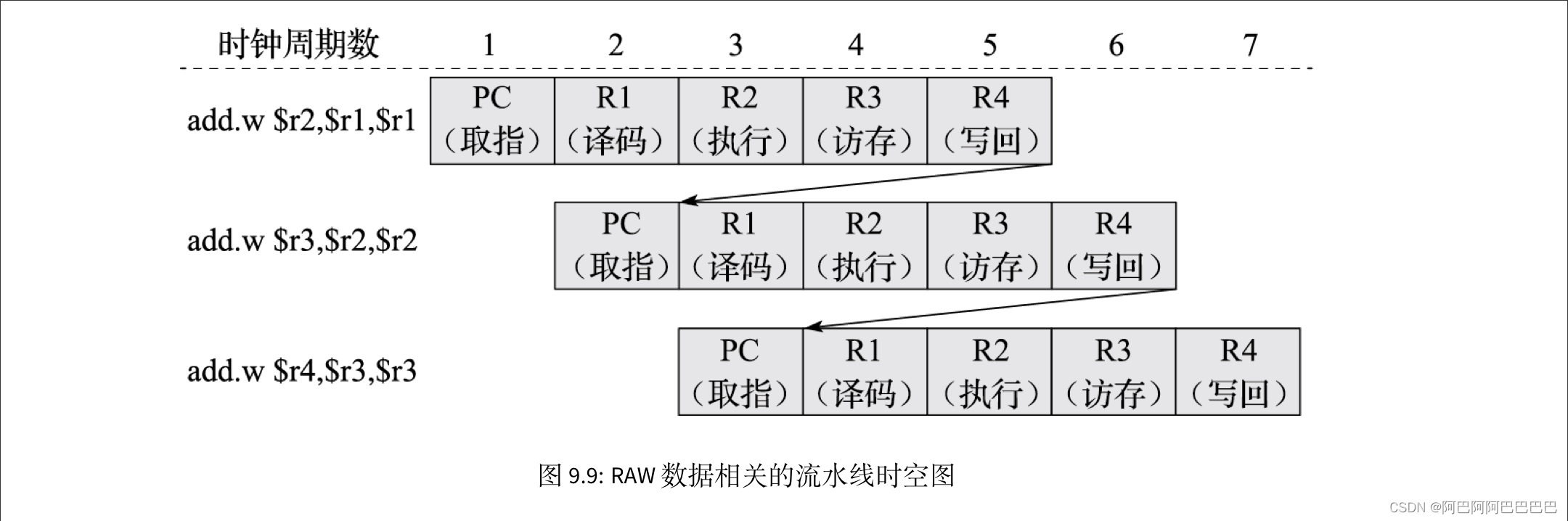 很显然,如果第二条指令要使用第一条指令写回到寄存器中的结果,就必须保证第二条指令读取寄存器的时候第一条指令的结果已经写回到寄存器中了,为了保证执行正确,最简单粗暴的解决方法就是:让第二条指令在译码阶段等待(阻塞)3拍,直到第一条指令将运算结果写入寄存器后才能读取寄存器。
很显然,如果第二条指令要使用第一条指令写回到寄存器中的结果,就必须保证第二条指令读取寄存器的时候第一条指令的结果已经写回到寄存器中了,为了保证执行正确,最简单粗暴的解决方法就是:让第二条指令在译码阶段等待(阻塞)3拍,直到第一条指令将运算结果写入寄存器后才能读取寄存器。
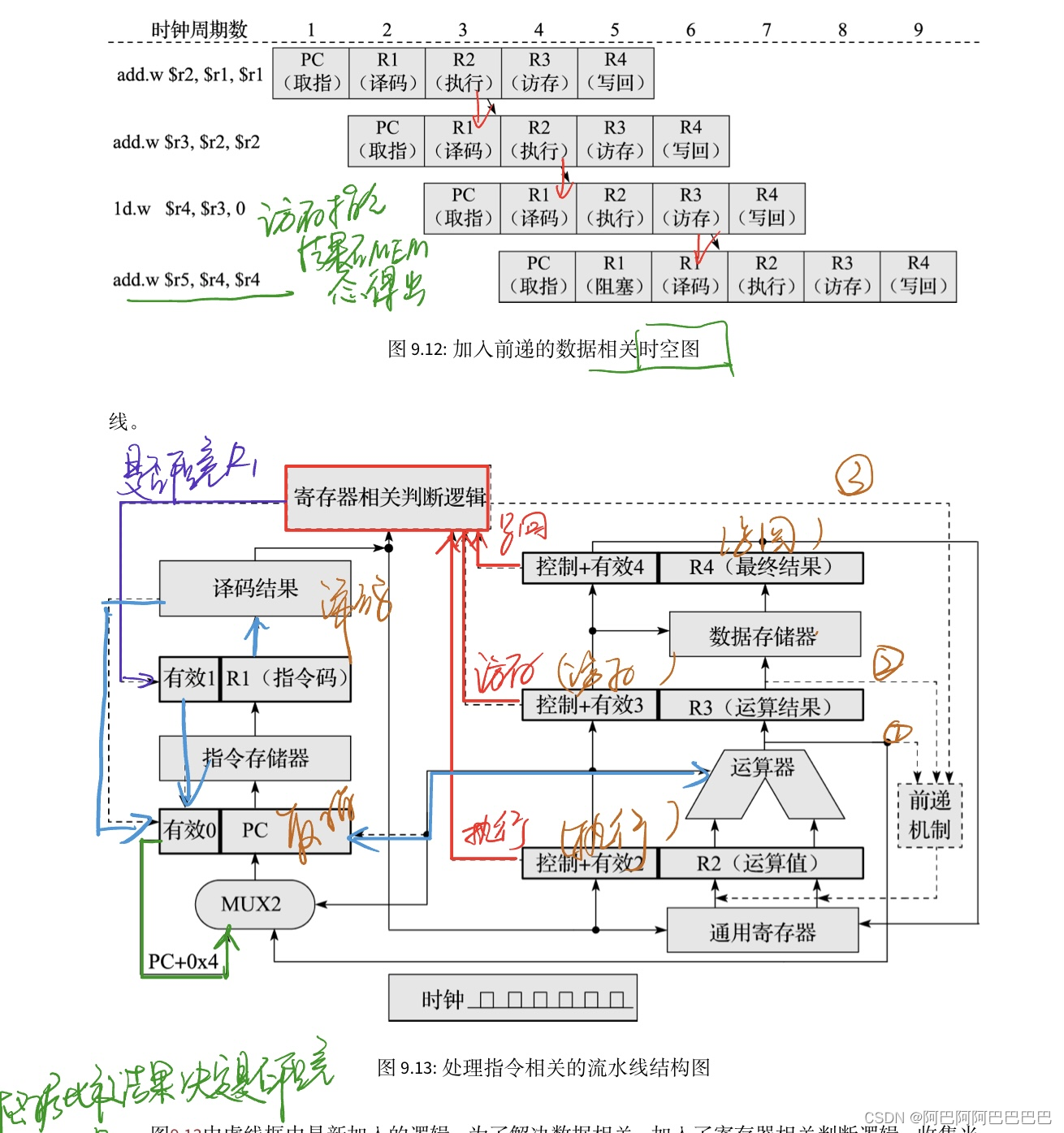
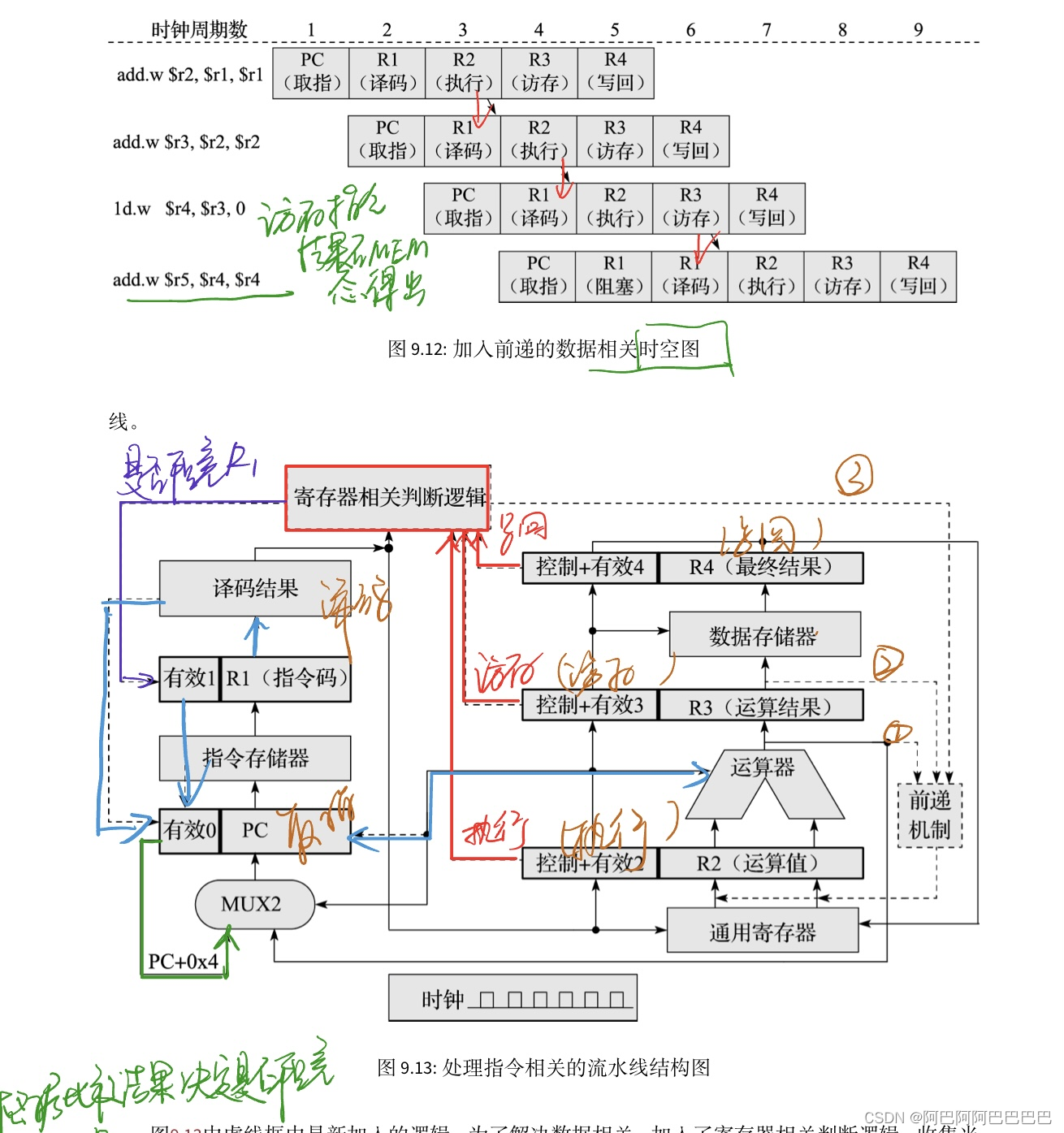
阻塞在具体电路中的实现就是:将被阻塞流水级所在的寄存器保持原值不变,同时向被阻塞的流水级的下一级输入指令无效信号,用Bubble填充。
流水线前递技术
使用阻塞的流水线的执行效率是很低的,所以出现了流水线前递技术。
“何必非要等这个值沿着流水线一级一级传送下去写入寄存器后再从寄存器读出来呢?直接把这个值取过来不也是可行的吗?
在流水线中读取指令源操作数的地方通过多路选择器直接把前面的指令的运算结果作为后面的指令输入
控制相关引发的冲突和解决方法

 懒得打字了
懒得打字了
结构相关引起的冲突以及解决方法