在colab上运行,所以如何在colab上安装fmm,可见FMM 笔记:在colab上执行FMM-CSDN博客
fmm见:论文笔记:Fast map matching, an algorithm integrating hidden Markov model with precomputation_ubodt(upper bounded origin destination table)-CSDN博客
0 导入库
from fmm import Network,NetworkGraph,FastMapMatch,FastMapMatchConfig,UBODT1 加载数据(边的shp文件) 【与st-matching部分一致】
import geopandas as gpd
shp_path = "../data/edges.shp"
gdf = gpd.read_file(shp_path)
gdf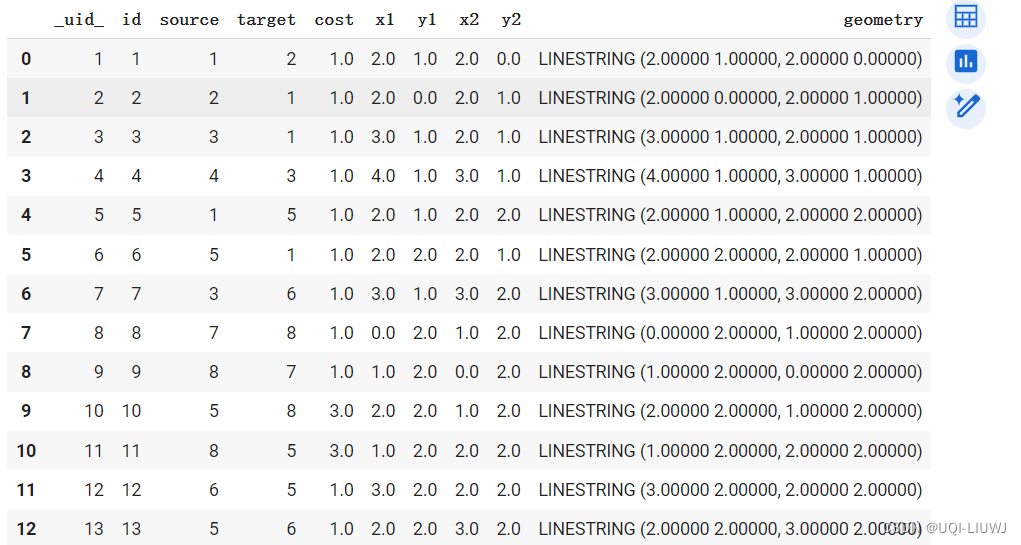
2 提取路网信息 【与st-matching部分一致】
network = Network("../data/edges.shp")
#通过Network类加载路网数据(edges.shp)
print("Nodes {} edges {}".format(network.get_node_count(),network.get_edge_count()))
#Nodes 17 edges 30
graph = NetworkGraph(network)
#使用NetworkGraph类基于这个网络创建一个图形(Graph)对象3 创建UBODT 【FMM独有】(如有ubodt文件,这一步略去)
FMM独特部分,上界起点-终点表(UBODT),详细内容,见论文笔记:Fast map matching, an algorithm integrating hidden Markov model with precomputation_ubodt(upper bounded origin destination table)-CSDN博客
from fmm import UBODTGenAlgorithm
ubodt_gen = UBODTGenAlgorithm(network,graph)
#创建UBODT生成算法的实例
status = ubodt_gen.generate_ubodt("../data/ubodt.txt",
4,
binary=False,
use_omp=True)
'''
生成UBODT文件,分别设置了
--输出文件路径
--delta (float or int): 搜索半径的阈值,用于限制生成UBODT时考虑的最短路径的最大长度
--binary (bool, optional): 指示输出文件格式是否为二进制。默认为False,表示输出为文本格式。
--use_omp (bool, optional): 指示是否使用OpenMP来并行化UBODT的生成过程。默认为True,允许使用多个CPU核心并行计算,以加速UBODT的生成。
print(status)
'''
Status: success
Time takes 0.004 seconds
'''ubodt文件内容如下:
pd.read_csv("../data/ubodt.txt",delimiter=';') 
4 读取ubodt文件
ubodt = UBODT.read_ubodt_csv("../data/ubodt.txt")
ubodt
#<fmm.UBODT; proxy of <Swig Object of type 'std::shared_ptr< FMM::MM::UBODT > *' at 0x7f9f5fe0fea0> >5 创建FMM模型
传入参数相比于st-matching,多一个ubodt
model = FastMapMatch(network,graph,ubodt)5.1 定义st-matching模型的配置
k = 4
#candidate 数量
gps_error = 0.5
#gps定位误差
radius = 0.4
#搜索半径
fmm_config = FastMapMatchConfig(k,radius,gps_error)6 单条数据的地图匹配
6.0 输入数据
输入数据是wkt格式的数据
地理笔记:WKT,WKB,GeoJSON-CSDN博客
wkt ='LINESTRING(0.200812146892656 2.14088983050848,1.44262005649717 2.14879943502825,3.06408898305084 2.16066384180791,3.06408898305084 2.7103813559322,3.70872175141242 2.97930790960452,4.11606638418078 2.62337570621469)'6.1 进行地图匹配
result = model.match_wkt(wkt,fmm_config)
rint("Matched path: ", list(result.cpath))
print("Matched edge for each point: ", list(result.opath))
print("Matched edge index ",list(result.indices))
print("Matched geometry: ",result.mgeom.export_wkt())
print("Matched point ", result.pgeom.export_wkt())
'''
Matched path: [8, 11, 13, 18, 20, 24]
Matched edge for each point: [8, 11, 18, 18, 20, 24]
Matched edge index [0, 1, 3, 3, 4, 5]
Matched geometry: LINESTRING(0.20081215 2,1 2,2 2,3 2,3 3,4 3,4 2.6233757)
Matched point LINESTRING(0.20081215 2,1.4426201 2,3 2.1606638,3 2.7103814,3.7087218 3,4 2.6233757)
'''cpath,opath这些的内容见:FMM 笔记:st-matching(colab上执行)【官方案例解读】-CSDN博客
6.2 输出每个点的匹配结果
candidates = []
for c in result.candidates:
candidates.append((c.edge_id,c.source,c.target,c.error,c.length,c.offset,c.spdist,c.ep,c.tp))
import pandas as pd
df = pd.DataFrame(candidates,
columns=["eid","source","target","error","length","offset","spdist","ep","tp"])
df.head()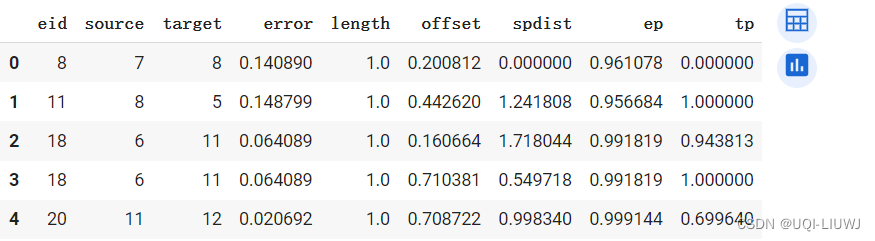
DataFrame的列含义如下:
eid:边的ID。source:边的起点节点ID。target:边的终点节点ID。error:候选点的误差值。length:边的长度。offset:GPS点在边上的偏移量。spdist:GPS点到边的最短距离。ep和tp:分别表示匹配点在边上的起始和终止位置,作为归一化的比例值。
7 将一个文件中的轨迹分别进行匹配,并输出到另一个文件中
from fmm import GPSConfig,ResultConfig7.1 输入文件设置【和st-matching 一致】
输入文件长这样:
gpd.read_file("../data/trips.csv")
# Define input data configuration
input_config = GPSConfig()
input_config.file = "../data/trips.csv"
input_config.id = "id"
print(input_config.to_string())
'''
[40]
0 秒
print(input_config.to_string())
gps file : ../data/trips.csv
id column : id
geom column : geom
timestamp column : timestamp
x column : x
y column : y
GPS point : false
'''7.2 输出文件信息【和st-matching一样】
result_config = ResultConfig()
result_config.file = "../data/mr.txt"
result_config.output_config.write_opath = True
#结果文件将包含匹配的路径信息(每个单独点匹配到的边的信息)
print(result_config.to_string())
'''
Result file : ../data/mr.txt
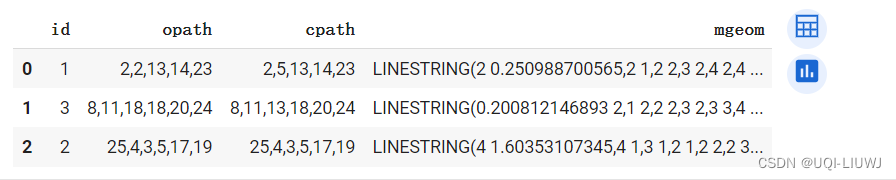
Output fields: opath cpath mgeom
'''7.3 路网匹配
status = model.match_gps_file(input_config, result_config, fmm_config)
print(status)
'''
Status: success
Time takes 0.003 seconds
Total points 17 matched 17
Map match speed 5666.67 points/s
'''7.4 查看匹配结果
import pandas as pd
pd.read_csv("../data/mr.txt",delimiter=';')