文章目录
- 引言
- 一、模型加载
- 二、huggingface梯度更新使用
- 三、图像处理
- 四、模型推理
- 五、整体代码
- 总结
引言
本文介绍如何使用huggingface加载视觉模型openai/clip-vit-large-patch14-336,我之所以记录此方法源于现有大模型基本采用huggingface库来加载视觉模型和大语言模型,我也是在做LLava模型等模型。基于此,本节将介绍如何huggingface如何加载vit视觉模型。
一、模型加载
使用huggingface模型加载是非常简单,其代码如下:
from transformers import CLIPVisionModel, CLIPImageProcessor
if __name__ == '__main__':
vit_path='D:/clip-vit-large-patch14-336'
img_path='dogs.jpg'
image_processor = CLIPImageProcessor.from_pretrained(vit_path) # 加载图像预处理
vision_tower = CLIPVisionModel.from_pretrained(vit_path) # 加载图像模型
vision_tower.requires_grad_(False) # 模型冻结
for name, param in vision_tower.named_parameters():
print(name, param.requires_grad)
二、huggingface梯度更新使用
一般视觉模型需要冻结,使用lora训练,那么我们需要如何关闭视觉模型梯度。为此,我继续探讨梯度设置方法,其代码如下:
vision_tower.requires_grad_(False) # 模型冻结
for name, param in vision_tower.named_parameters():
print(name, param.requires_grad)
以上代码第一句话是视觉模型梯度冻结方法,下面2句是验证梯度是否冻结。如果设置’‘vision_tower.requires_grad_(False)’'表示冻结梯度,如果不设置表示需要梯度传播。我将不在介绍了,若你想详细了解,只要执行以上
代码便可知晓。
三、图像处理
在输入模型前,我们需要对图像进行预处理,然huggingface也很人性的自带了对应视觉模型的图像处理,我们只需使用PIL实现图像处理,其代码如下:
image = Image.open(img_path).convert('RGB') # PIL读取图像
def expand2square(pil_img, background_color):
width, height = pil_img.size # 获得图像宽高
if width == height: # 相等直接返回不用重搞
return pil_img
elif width > height: # w大构建w尺寸图
result = Image.new(pil_img.mode, (width, width), background_color)
result.paste(pil_img, (0, (width - height) // 2)) # w最大,以坐标x=0,y=(width - height) // 2位置粘贴原图
return result
else:
result = Image.new(pil_img.mode, (height, height), background_color)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image, tuple(int(x * 255) for x in image_processor.image_mean))
image = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
四、模型推理
最后就是模型推理,其代码如下:
image_forward_out = vision_tower(image.unsqueeze(0), output_hidden_states=True)
feature = image_forward_out['last_hidden_state']
print(feature.shape)
但是,我想说输出包含很多内容,其中hidden_states有25个列表,表示每个block输出结果,而hidden_states的最后一层与last_hidden_states值相同,结果分别如下图:
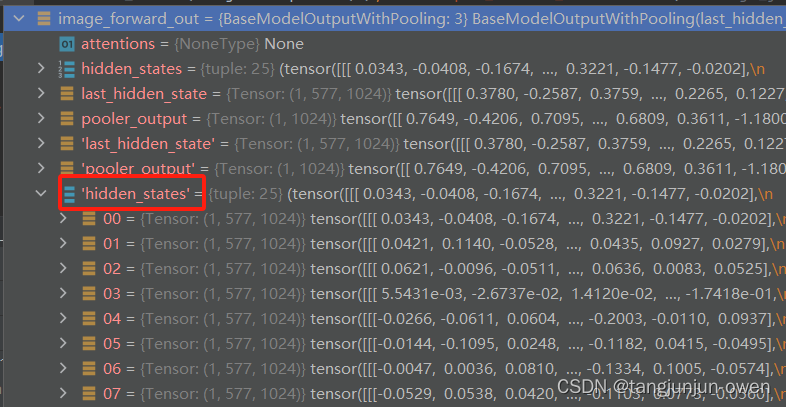
hidden_states与last_hidden_states对比如下:

五、整体代码
from transformers import CLIPVisionModel, CLIPImageProcessor
from PIL import Image
if __name__ == '__main__':
vit_path='E:/clip-vit-large-patch14-336'
img_path='dogs.jpg'
image_processor = CLIPImageProcessor.from_pretrained(vit_path) # 加载图像预处理
vision_tower = CLIPVisionModel.from_pretrained(vit_path) # 加载图像模型
vision_tower.requires_grad_(False) # 模型冻结
for name, param in vision_tower.named_parameters():
print(name, param.requires_grad)
image = Image.open(img_path).convert('RGB') # PIL读取图像
def expand2square(pil_img, background_color):
width, height = pil_img.size # 获得图像宽高
if width == height: # 相等直接返回不用重搞
return pil_img
elif width > height: # w大构建w尺寸图
result = Image.new(pil_img.mode, (width, width), background_color)
result.paste(pil_img, (0, (width - height) // 2)) # w最大,以坐标x=0,y=(width - height) // 2位置粘贴原图
return result
else:
result = Image.new(pil_img.mode, (height, height), background_color)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image, tuple(int(x * 255) for x in image_processor.image_mean))
image = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
image_forward_out = vision_tower(image.unsqueeze(0), output_hidden_states=True)
feature = image_forward_out['last_hidden_state']
print(feature.shape)
总结
本文是一个huggingface加载视觉模型的方法,另一个重点是梯度冻结。然而,我只代表VIT模型是如此使用,其它模型还未验证,不做任何说明。








![P2680 [NOIP2015 提高组] 运输计划 第一个测试点信息 || 被卡常,链式前向星应该解决的是vector的push_back频繁扩容的耗时](https://img-blog.csdnimg.cn/direct/b53d90bab61a4f5ebf84843963e971a2.png)