VM-UNet
- 期刊分析
- 摘要
- 贡献
- 方法
- 整体框架
- 1. Vision Mamba UNet (VM-UNet)
- 2. VSS block
- 3. Loss function
- 实验
- 1.对比实验
- 2.消融实验
- 可借鉴参考
- 代码使用
期刊分析
期刊名: Arxiv
论文主页: VM-UNet
代码: Code
摘要
在医学图像分割领域,基于 CNN 和基于 Transformer 的模型都得到了广泛的探索。然而,CNN 在远程建模能力方面表现出局限性,而 Transformer 则受到其二次计算复杂性的限制。 最近,
以 Mamba 为代表的状态空间模型 (SSM) 已成为一种有前途的方法。它们不仅擅长对远程交互进行建模,而且还保持线性计算复杂性。在本文中,利用状态空间模型,我们提出了一种用于医学图像分割的 Ushape 架构模型,名为 Vision Mamba UNet (VM-UNet)。具体来说,引入视觉状态空间(VSS)块作为基础块来捕获广泛的上下文信息,并构建不对称的编码器-解码器结构。我们在 ISIC17、ISIC18 和 Synapse 数据集上进行了全面的实验,结果表明 VM-UNet 在医学图像分割任务中表现出竞争力。据我们所知,这是第一个基于纯SSM模型构建的医学图像分割模型。我们的目标是建立一个基线,并为未来开发更高效、更有效的基于 SSM 的分割系统提供有价值的见解。我们的代码可在 https://github.com/JCruan519/VM-UNet 上获取。
贡献
- 提出了 VM-UNet,标志着首次探索纯粹基于 SSM 的模型在医学图像分割中的潜在应用。
- 在三个数据集上进行综合实验,结果表明VM-UNet表现出相当的竞争力。
- 我们为医学图像分割任务中基于纯SSM的模型建立了基线,提供了宝贵的见解,为开发更高效、更有效的基于SSM的分割方法铺平了道路。
方法
整体框架
整体依旧是传统UNet的结构,将原先的卷积模块换成了视觉状态空间模块(VSS block),将原先的上下采样换成了Patch Merging和Patch Expanding模块,因此跟着代码一个一个模块攻克即可!
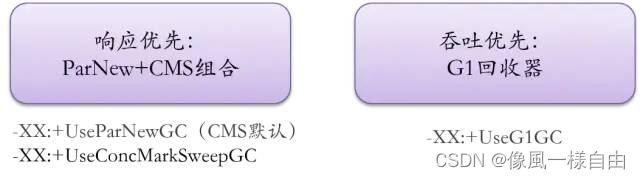
1. Vision Mamba UNet (VM-UNet)
1. Patch Embedding层首先将图像划分为4×4的非重叠patch,然后将图像通道数转化为C
2. 编码器由四个阶段组成,在前三个阶段的末尾应用补丁合并操作,以减少输入特征的高度和宽度,同时增加通道数。
3. 类似地,解码器分为四个阶段。在最后三个阶段的开始,利用补丁扩展操作来减少特征通道的数量并增加高度和宽度。
4. 在解码器之后,采用最终投影层来恢复特征的大小以匹配分割目标。
5. 对于跳跃连接,采用简单的加法操作,没有花哨的东西,因此没有引入任何额外的参数。
疑问: 为什么在选择使用对称性的结构时,在最后一阶段解码器中只使用了1个VSS block呢?
2. VSS block
1. 源自 VMamaba 的 VSS 块是 VM-UNet 的核心模块,如图 1 (b) 所示。经过层归一化后,输入被分为两个分支。在第一个分支中,输入通过线性层,然后通过激活函数。在第二个分支中,输入通过线性层、深度可分离卷积和激活函数进行处理,然后输入 2D 选择性扫描 (SS2D) 模块以进行进一步的特征提取。随后,使用层归一化对特征进行归一化,然后使用第一个分支的输出执行按元素生成以合并两个路径。最后,使用线性层混合特征,并将此结果与残差连接相结合以形成 VSS 块的输出。本文默认采用SiLU[14]作为激活函数。
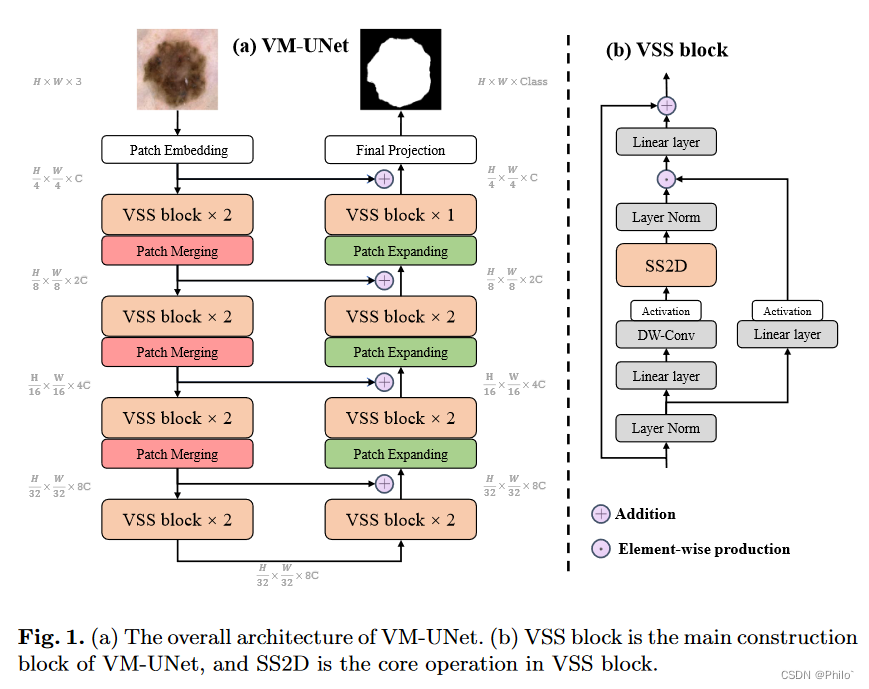
2. SS2D 由三个部分组成:扫描扩展操作(Scan Expanding)、S6 块和扫描合并操作(Scan Merging)这里不要和和Patch merging 和 Patch Expanding 弄混。如图2(a)所示,扫描扩展操作沿四个不同方向(左上到右下、右下到左上、右上到左下、左下到右上)展开输入图像)进入序列。然后,这些序列由 S6 块进行处理以进行特征提取,确保来自各个方向的信息得到彻底扫描,从而捕获不同的特征。随后,如图2(b)所示,扫描合并操作对来自四个方向的序列进行求和并合并,将输出图像恢复到与输入相同的大小。 S6 模块源自 Mamba [16],通过根据输入调整 SSM 的参数,在 S4 [17] 之上引入了一种选择机制。这使得模型能够区分并保留相关信息,同时过滤掉不相关的信息。 S6 块的伪代码如算法 1 所示。
3. SS2D中的核心S6

首先使用nn.linear()和x生成
Δ
\Delta
Δ,B,C;然后借助
Δ
\Delta
Δ,A,B生成
A
ˉ
\bar{A}
Aˉ,
B
ˉ
\bar{B}
Bˉ,最后借助公式计算出输出值y,具体解析见公式注释。
3. Loss function
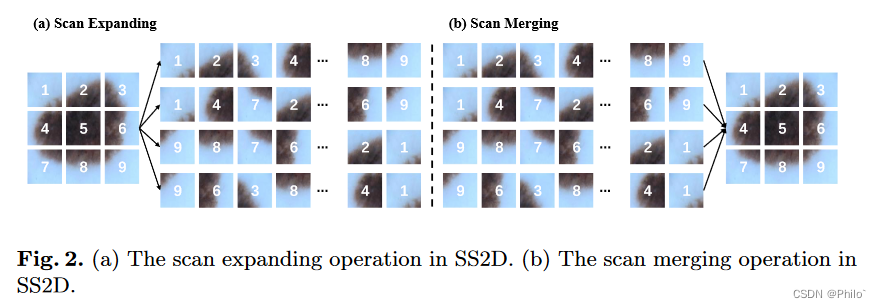
1. VM-UNet的引入旨在验证纯基于SSM的模型在医学图像分割任务中的应用潜力。因此,我们专门利用最基本的二元交叉熵和骰子损失(BceDice 损失)以及交叉熵和骰子损失(CeDice 损失)分别作为二元和多类分割任务的损失函数,如方程 5 所示和 6.
2.
3.
实验
在本节中,我们在 VM-UNet 上针对皮肤病变和器官分割任务进行全面的实验。具体来说,我们评估了 VM-UNet 在 ISIC17、ISIC18 和 Synapse 数据集上的医学图像分割任务上的性能。 对于这两个数据集,我们提供了对多个指标的详细评估,包括并集平均交集 (mIoU)、Dice 相似系数 (DSC)、准确性 (Acc)、灵敏度 (Sen) 和特异性 (Spe)。
继之前的工作[28,9]之后,我们将 ISIC17 和 ISIC18 数据集中的图像大小调整为 256×256,将 Synapse 数据集中的图像大小调整为 224×224。为了防止过度拟合,采用了数据增强技术,包括随机翻转和随机旋转。 ISIC17和ISIC18数据集采用BceDice损失函数,Synapse数据集采用CeDice损失函数。
我们将批量大小设置为 32,并使用 AdamW [23] 优化器,初始学习率为 1e-3。 CosineAnnealingLR [22] 用作调度器,最多 50 次迭代,最小学习率为 1e-5。训练周期设置为 300。对于 VM-UNet,我们使用 VMamba-S [20] 的权重初始化编码器和解码器的权重,VMamba-S [20] 在 ImageNet-1k 上预训练。所有实验均在单个 NVIDIA RTX A6000 GPU 上进行。
1.对比实验
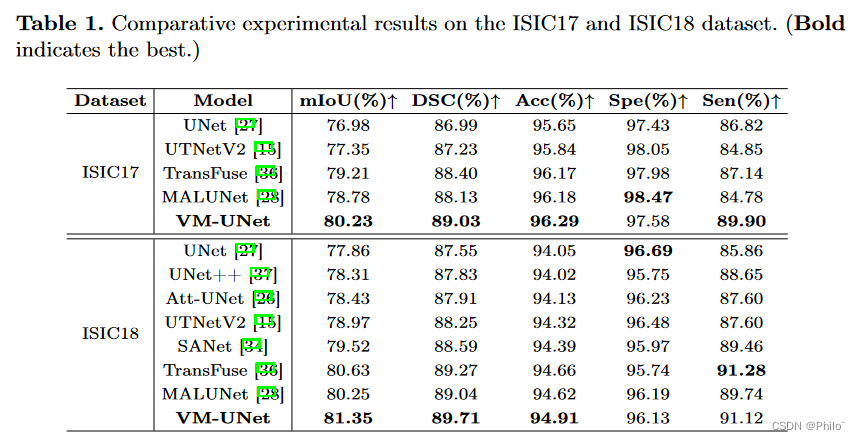
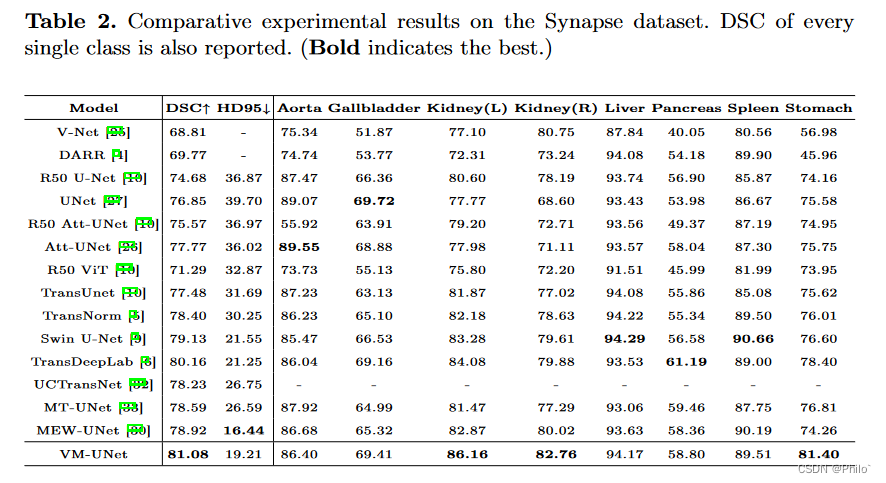
将 VM-UNet 与一些最先进的模型进行比较,实验结果如表 1 和表 2 所示。对于 ISIC17 和 ISIC18 数据集,我们的 VM-UNet 在 mIoU、DSC 和 Acc 方面优于其他模型指标。对于Synapse数据集,VM-UNet也取得了有竞争力的性能。例如,我们的模型在 DSC 和 HD95 指标上超过了 Swin-UNet(第一个纯基于 Transformer 的模型)1.95% 和 2.34mm。结果证明了基于SSM的模型在医学图像分割任务中的优越性。
找来了ISIC2018数据集上结果榜单如下:
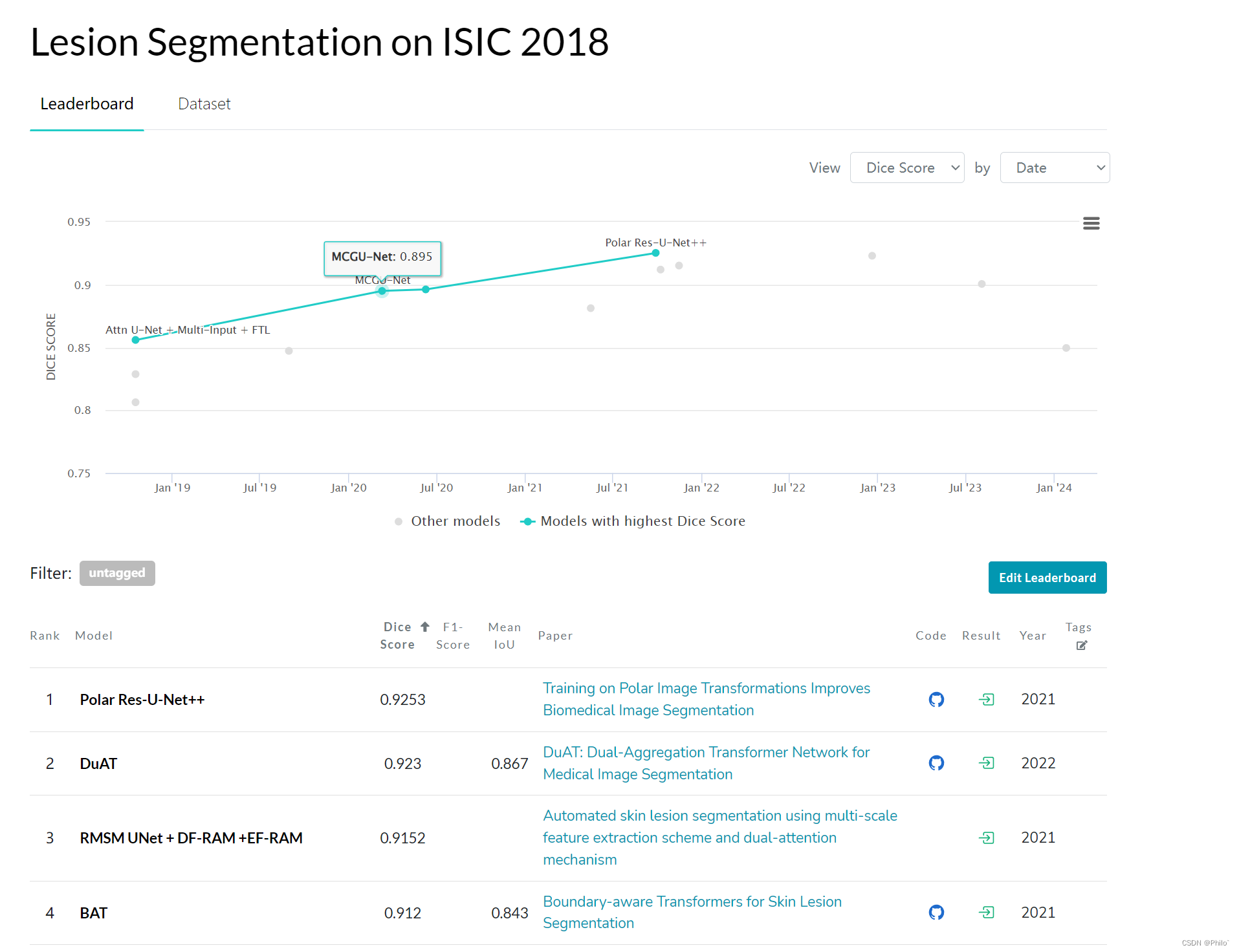
VM-UNet 距离SOTA还有一点距离!!
2.消融实验
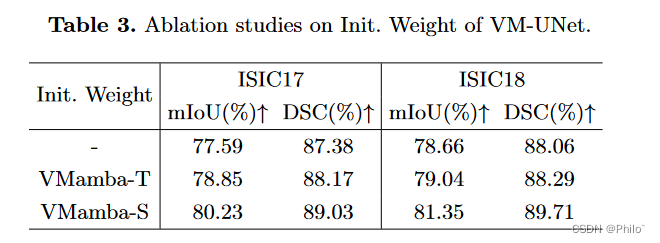
在本节中,我们使用 ISIC17 和 ISIC18 数据集对 VMUNet 的初始化进行消融实验。我们分别使用 VMamba-T 和 VMamba-S 的预训练权重初始化 VM-UNet1。实验结果如表 3 所示,表明更有效的预训练权重显着增强了 VM-UNet 的下游性能,表明 VM-UNet很大程度上受预训练权重的影响。
可以很明显看出,大一点的模型预训练权重就是厉害!
总体看下来:
- 作为mamba模型最重要的突破点,线性计算复杂度没有做实验证明,真的可惜!
- 作者选择在对称结构上使用不对称的VSS block数量,也是经过实验得到的(对称好肯定就用对称的了)。因此感觉将mamba模型放到分割任务中,只超过一些经典模型,对于SOTA模型还有一些距离,因此需要做好攻克的准备。
- 作者公开了代码,而且代码结构简单好用,太棒了!!
可借鉴参考
-
提供了一个baseline
-
提供了mamba模型的介绍流程
-
阅读U-Mamba 2024
Ma, J., Li, F., Wang, B.: U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024) -
阅读SegMamba 2024
Xing, Z., Ye, T., Yang, Y., Liu, G., Zhu, L.: Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. arXiv preprint arXiv:2401.13560 (2024)
代码使用
当前mamba_ssm包只发布了Linux版本,因此在Win系统下无法运行
- Linux下安装mamba_ssm
pip install mamba_ssm
- 复制代码使用
import time
import math
from functools import partial
from typing import Optional, Callable
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from einops import rearrange, repeat
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
try:
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn, selective_scan_ref
except:
pass
# an alternative for mamba_ssm (in which causal_conv1d is needed)
# try:
# from selective_scan import selective_scan_fn as selective_scan_fn_v1
# from selective_scan import selective_scan_ref as selective_scan_ref_v1
# except:
# pass
DropPath.__repr__ = lambda self: f"timm.DropPath({self.drop_prob})"
def flops_selective_scan_ref(B=1, L=256, D=768, N=16, with_D=True, with_Z=False, with_Group=True, with_complex=False):
"""
u: r(B D L)
delta: r(B D L)
A: r(D N)
B: r(B N L)
C: r(B N L)
D: r(D)
z: r(B D L)
delta_bias: r(D), fp32
ignores:
[.float(), +, .softplus, .shape, new_zeros, repeat, stack, to(dtype), silu]
"""
import numpy as np
# fvcore.nn.jit_handles
def get_flops_einsum(input_shapes, equation):
np_arrs = [np.zeros(s) for s in input_shapes]
optim = np.einsum_path(equation, *np_arrs, optimize="optimal")[1]
for line in optim.split("\n"):
if "optimized flop" in line.lower():
# divided by 2 because we count MAC (multiply-add counted as one flop)
flop = float(np.floor(float(line.split(":")[-1]) / 2))
return flop
assert not with_complex
flops = 0 # below code flops = 0
if False:
...
"""
dtype_in = u.dtype
u = u.float()
delta = delta.float()
if delta_bias is not None:
delta = delta + delta_bias[..., None].float()
if delta_softplus:
delta = F.softplus(delta)
batch, dim, dstate = u.shape[0], A.shape[0], A.shape[1]
is_variable_B = B.dim() >= 3
is_variable_C = C.dim() >= 3
if A.is_complex():
if is_variable_B:
B = torch.view_as_complex(rearrange(B.float(), "... (L two) -> ... L two", two=2))
if is_variable_C:
C = torch.view_as_complex(rearrange(C.float(), "... (L two) -> ... L two", two=2))
else:
B = B.float()
C = C.float()
x = A.new_zeros((batch, dim, dstate))
ys = []
"""
flops += get_flops_einsum([[B, D, L], [D, N]], "bdl,dn->bdln")
if with_Group:
flops += get_flops_einsum([[B, D, L], [B, N, L], [B, D, L]], "bdl,bnl,bdl->bdln")
else:
flops += get_flops_einsum([[B, D, L], [B, D, N, L], [B, D, L]], "bdl,bdnl,bdl->bdln")
if False:
...
"""
deltaA = torch.exp(torch.einsum('bdl,dn->bdln', delta, A))
if not is_variable_B:
deltaB_u = torch.einsum('bdl,dn,bdl->bdln', delta, B, u)
else:
if B.dim() == 3:
deltaB_u = torch.einsum('bdl,bnl,bdl->bdln', delta, B, u)
else:
B = repeat(B, "B G N L -> B (G H) N L", H=dim // B.shape[1])
deltaB_u = torch.einsum('bdl,bdnl,bdl->bdln', delta, B, u)
if is_variable_C and C.dim() == 4:
C = repeat(C, "B G N L -> B (G H) N L", H=dim // C.shape[1])
last_state = None
"""
in_for_flops = B * D * N
if with_Group:
in_for_flops += get_flops_einsum([[B, D, N], [B, D, N]], "bdn,bdn->bd")
else:
in_for_flops += get_flops_einsum([[B, D, N], [B, N]], "bdn,bn->bd")
flops += L * in_for_flops
if False:
...
"""
for i in range(u.shape[2]):
x = deltaA[:, :, i] * x + deltaB_u[:, :, i]
if not is_variable_C:
y = torch.einsum('bdn,dn->bd', x, C)
else:
if C.dim() == 3:
y = torch.einsum('bdn,bn->bd', x, C[:, :, i])
else:
y = torch.einsum('bdn,bdn->bd', x, C[:, :, :, i])
if i == u.shape[2] - 1:
last_state = x
if y.is_complex():
y = y.real * 2
ys.append(y)
y = torch.stack(ys, dim=2) # (batch dim L)
"""
if with_D:
flops += B * D * L
if with_Z:
flops += B * D * L
if False:
...
"""
out = y if D is None else y + u * rearrange(D, "d -> d 1")
if z is not None:
out = out * F.silu(z)
out = out.to(dtype=dtype_in)
"""
return flops
class PatchEmbed2D(nn.Module):
r""" Image to Patch Embedding
Args:
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None, **kwargs):
super().__init__()
if isinstance(patch_size, int):
patch_size = (patch_size, patch_size)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
x = self.proj(x).permute(0, 2, 3, 1)
if self.norm is not None:
x = self.norm(x)
return x
class PatchMerging2D(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
B, H, W, C = x.shape
SHAPE_FIX = [-1, -1]
if (W % 2 != 0) or (H % 2 != 0):
print(f"Warning, x.shape {x.shape} is not match even ===========", flush=True)
SHAPE_FIX[0] = H // 2
SHAPE_FIX[1] = W // 2
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
if SHAPE_FIX[0] > 0:
x0 = x0[:, :SHAPE_FIX[0], :SHAPE_FIX[1], :]
x1 = x1[:, :SHAPE_FIX[0], :SHAPE_FIX[1], :]
x2 = x2[:, :SHAPE_FIX[0], :SHAPE_FIX[1], :]
x3 = x3[:, :SHAPE_FIX[0], :SHAPE_FIX[1], :]
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, H//2, W//2, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
class PatchExpand2D(nn.Module):
def __init__(self, dim, dim_scale=2, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim*2
self.dim_scale = dim_scale
self.expand = nn.Linear(self.dim, dim_scale*self.dim, bias=False)
self.norm = norm_layer(self.dim // dim_scale)
def forward(self, x):
B, H, W, C = x.shape
x = self.expand(x)
x = rearrange(x, 'b h w (p1 p2 c)-> b (h p1) (w p2) c', p1=self.dim_scale, p2=self.dim_scale, c=C//self.dim_scale)
x= self.norm(x)
return x
class Final_PatchExpand2D(nn.Module):
def __init__(self, dim, dim_scale=4, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.dim_scale = dim_scale
self.expand = nn.Linear(self.dim, dim_scale*self.dim, bias=False)
self.norm = norm_layer(self.dim // dim_scale)
def forward(self, x):
B, H, W, C = x.shape
x = self.expand(x)
x = rearrange(x, 'b h w (p1 p2 c)-> b (h p1) (w p2) c', p1=self.dim_scale, p2=self.dim_scale, c=C//self.dim_scale)
x= self.norm(x)
return x
class SS2D(nn.Module):
def __init__(
self,
d_model,
d_state=16,
# d_state="auto", # 20240109
d_conv=3,
expand=2,
dt_rank="auto",
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
dropout=0.,
conv_bias=True,
bias=False,
device=None,
dtype=None,
**kwargs,
):
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
self.d_model = d_model
self.d_state = d_state
# self.d_state = math.ceil(self.d_model / 6) if d_state == "auto" else d_model # 20240109
self.d_conv = d_conv
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias, **factory_kwargs)
self.conv2d = nn.Conv2d(
in_channels=self.d_inner,
out_channels=self.d_inner,
groups=self.d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
self.act = nn.SiLU()
self.x_proj = (
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs),
)
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K=4, N, inner)
del self.x_proj
self.dt_projs = (
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),
)
self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K=4, inner, rank)
self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K=4, inner)
del self.dt_projs
self.A_logs = self.A_log_init(self.d_state, self.d_inner, copies=4, merge=True) # (K=4, D, N)
self.Ds = self.D_init(self.d_inner, copies=4, merge=True) # (K=4, D, N)
# self.selective_scan = selective_scan_fn
self.forward_core = self.forward_corev0
self.out_norm = nn.LayerNorm(self.d_inner)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias, **factory_kwargs)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4, **factory_kwargs):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank**-0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=1, device=None, merge=True):
# S4D real initialization
A = repeat(
torch.arange(1, d_state + 1, dtype=torch.float32, device=device),
"n -> d n",
d=d_inner,
).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 1:
A_log = repeat(A_log, "d n -> r d n", r=copies)
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 1:
D = repeat(D, "n1 -> r n1", r=copies)
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
def forward_corev0(self, x: torch.Tensor):
self.selective_scan = selective_scan_fn
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1) # (b, k, d, l)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
# x_dbl = x_dbl + self.x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
# dts = dts + self.dt_projs_bias.view(1, K, -1, 1)
xs = xs.float().view(B, -1, L) # (b, k * d, l)
dts = dts.contiguous().float().view(B, -1, L) # (b, k * d, l)
Bs = Bs.float().view(B, K, -1, L) # (b, k, d_state, l)
Cs = Cs.float().view(B, K, -1, L) # (b, k, d_state, l)
Ds = self.Ds.float().view(-1) # (k * d)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state) # (k * d, d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
out_y = self.selective_scan(
xs, dts,
As, Bs, Cs, Ds, z=None,
delta_bias=dt_projs_bias,
delta_softplus=True,
return_last_state=False,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
return out_y[:, 0], inv_y[:, 0], wh_y, invwh_y
# an alternative to forward_corev1
def forward_corev1(self, x: torch.Tensor):
self.selective_scan = selective_scan_fn
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1) # (b, k, d, l)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
# x_dbl = x_dbl + self.x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
# dts = dts + self.dt_projs_bias.view(1, K, -1, 1)
xs = xs.float().view(B, -1, L) # (b, k * d, l)
dts = dts.contiguous().float().view(B, -1, L) # (b, k * d, l)
Bs = Bs.float().view(B, K, -1, L) # (b, k, d_state, l)
Cs = Cs.float().view(B, K, -1, L) # (b, k, d_state, l)
Ds = self.Ds.float().view(-1) # (k * d)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state) # (k * d, d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
out_y = self.selective_scan(
xs, dts,
As, Bs, Cs, Ds,
delta_bias=dt_projs_bias,
delta_softplus=True,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
return out_y[:, 0], inv_y[:, 0], wh_y, invwh_y
def forward(self, x: torch.Tensor, **kwargs):
B, H, W, C = x.shape
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1) # (b, h, w, d)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.act(self.conv2d(x)) # (b, d, h, w)
y1, y2, y3, y4 = self.forward_core(x)
assert y1.dtype == torch.float32
y = y1 + y2 + y3 + y4
y = torch.transpose(y, dim0=1, dim1=2).contiguous().view(B, H, W, -1)
y = self.out_norm(y)
y = y * F.silu(z)
out = self.out_proj(y)
if self.dropout is not None:
out = self.dropout(out)
return out
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
attn_drop_rate: float = 0,
d_state: int = 16,
**kwargs,
):
super().__init__()
self.ln_1 = norm_layer(hidden_dim)
self.self_attention = SS2D(d_model=hidden_dim, dropout=attn_drop_rate, d_state=d_state, **kwargs)
self.drop_path = DropPath(drop_path)
def forward(self, input: torch.Tensor):
x = input + self.drop_path(self.self_attention(self.ln_1(input)))
return x
class VSSLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(
self,
dim,
depth,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
downsample=None,
use_checkpoint=False,
d_state=16,
**kwargs,
):
super().__init__()
self.dim = dim
self.use_checkpoint = use_checkpoint
self.blocks = nn.ModuleList([
VSSBlock(
hidden_dim=dim,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
attn_drop_rate=attn_drop,
d_state=d_state,
)
for i in range(depth)])
if True: # is this really applied? Yes, but been overriden later in VSSM!
def _init_weights(module: nn.Module):
for name, p in module.named_parameters():
if name in ["out_proj.weight"]:
p = p.clone().detach_() # fake init, just to keep the seed ....
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
self.apply(_init_weights)
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class VSSLayer_up(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(
self,
dim,
depth,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
upsample=None,
use_checkpoint=False,
d_state=16,
**kwargs,
):
super().__init__()
self.dim = dim
self.use_checkpoint = use_checkpoint
self.blocks = nn.ModuleList([
VSSBlock(
hidden_dim=dim,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
attn_drop_rate=attn_drop,
d_state=d_state,
)
for i in range(depth)])
if True: # is this really applied? Yes, but been overriden later in VSSM!
def _init_weights(module: nn.Module):
for name, p in module.named_parameters():
if name in ["out_proj.weight"]:
p = p.clone().detach_() # fake init, just to keep the seed ....
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
self.apply(_init_weights)
if upsample is not None:
self.upsample = upsample(dim=dim, norm_layer=norm_layer)
else:
self.upsample = None
def forward(self, x):
if self.upsample is not None:
x = self.upsample(x)
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
return x
class VSSM(nn.Module):
def __init__(self, patch_size=4, in_chans=3, num_classes=1000, depths=[2, 2, 9, 2], depths_decoder=[2, 9, 2, 2],
dims=[96, 192, 384, 768], dims_decoder=[768, 384, 192, 96], d_state=16, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
if isinstance(dims, int):
dims = [int(dims * 2 ** i_layer) for i_layer in range(self.num_layers)]
self.embed_dim = dims[0]
self.num_features = dims[-1]
self.dims = dims
self.patch_embed = PatchEmbed2D(patch_size=patch_size, in_chans=in_chans, embed_dim=self.embed_dim,
norm_layer=norm_layer if patch_norm else None)
# WASTED absolute position embedding ======================
self.ape = False
# self.ape = False
# drop_rate = 0.0
if self.ape:
self.patches_resolution = self.patch_embed.patches_resolution
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, *self.patches_resolution, self.embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
dpr_decoder = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths_decoder))][::-1]
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = VSSLayer(
dim=dims[i_layer],
depth=depths[i_layer],
d_state=math.ceil(dims[0] / 6) if d_state is None else d_state, # 20240109
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging2D if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
)
self.layers.append(layer)
self.layers_up = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = VSSLayer_up(
dim=dims_decoder[i_layer],
depth=depths_decoder[i_layer],
d_state=math.ceil(dims[0] / 6) if d_state is None else d_state, # 20240109
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr_decoder[sum(depths_decoder[:i_layer]):sum(depths_decoder[:i_layer + 1])],
norm_layer=norm_layer,
upsample=PatchExpand2D if (i_layer != 0) else None,
use_checkpoint=use_checkpoint,
)
self.layers_up.append(layer)
self.final_up = Final_PatchExpand2D(dim=dims_decoder[-1], dim_scale=4, norm_layer=norm_layer)
self.final_conv = nn.Conv2d(dims_decoder[-1]//4, num_classes, 1)
# self.norm = norm_layer(self.num_features)
# self.avgpool = nn.AdaptiveAvgPool1d(1)
# self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m: nn.Module):
"""
out_proj.weight which is previously initilized in VSSBlock, would be cleared in nn.Linear
no fc.weight found in the any of the model parameters
no nn.Embedding found in the any of the model parameters
so the thing is, VSSBlock initialization is useless
Conv2D is not intialized !!!
"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
skip_list = []
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
skip_list.append(x)
x = layer(x)
return x, skip_list
def forward_features_up(self, x, skip_list):
for inx, layer_up in enumerate(self.layers_up):
if inx == 0:
x = layer_up(x)
else:
x = layer_up(x+skip_list[-inx])
return x
def forward_final(self, x):
x = self.final_up(x)
x = x.permute(0,3,1,2)
x = self.final_conv(x)
return x
def forward_backbone(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
return x
def forward(self, x):
x, skip_list = self.forward_features(x)
x = self.forward_features_up(x, skip_list)
x = self.forward_final(x)
return x
import torch
from torch import nn
class VMUNet(nn.Module):
def __init__(self,
input_channels=3,
num_classes=1,
depths=[2, 2, 9, 2],
depths_decoder=[2, 9, 2, 2],
drop_path_rate=0.2,
load_ckpt_path=None,
):
super().__init__()
self.load_ckpt_path = load_ckpt_path
self.num_classes = num_classes
self.vmunet = VSSM(in_chans=input_channels,
num_classes=num_classes,
depths=depths,
depths_decoder=depths_decoder,
drop_path_rate=drop_path_rate,
)
def forward(self, x):
if x.size()[1] == 1:
x = x.repeat(1,3,1,1)
logits = self.vmunet(x)
if self.num_classes == 1: return torch.sigmoid(logits)
else: return logits
def load_from(self):
if self.load_ckpt_path is not None:
model_dict = self.vmunet.state_dict()
modelCheckpoint = torch.load(self.load_ckpt_path)
pretrained_dict = modelCheckpoint['model']
# 过滤操作
new_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict.keys()}
model_dict.update(new_dict)
# 打印出来,更新了多少的参数
print('Total model_dict: {}, Total pretrained_dict: {}, update: {}'.format(len(model_dict), len(pretrained_dict), len(new_dict)))
self.vmunet.load_state_dict(model_dict)
not_loaded_keys = [k for k in pretrained_dict.keys() if k not in new_dict.keys()]
print('Not loaded keys:', not_loaded_keys)
print("encoder loaded finished!")
model_dict = self.vmunet.state_dict()
modelCheckpoint = torch.load(self.load_ckpt_path)
pretrained_odict = modelCheckpoint['model']
pretrained_dict = {}
for k, v in pretrained_odict.items():
if 'layers.0' in k:
new_k = k.replace('layers.0', 'layers_up.3')
pretrained_dict[new_k] = v
elif 'layers.1' in k:
new_k = k.replace('layers.1', 'layers_up.2')
pretrained_dict[new_k] = v
elif 'layers.2' in k:
new_k = k.replace('layers.2', 'layers_up.1')
pretrained_dict[new_k] = v
elif 'layers.3' in k:
new_k = k.replace('layers.3', 'layers_up.0')
pretrained_dict[new_k] = v
# 过滤操作
new_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict.keys()}
model_dict.update(new_dict)
# 打印出来,更新了多少的参数
print('Total model_dict: {}, Total pretrained_dict: {}, update: {}'.format(len(model_dict), len(pretrained_dict), len(new_dict)))
self.vmunet.load_state_dict(model_dict)
# 找到没有加载的键(keys)
not_loaded_keys = [k for k in pretrained_dict.keys() if k not in new_dict.keys()]
print('Not loaded keys:', not_loaded_keys)
print("decoder loaded finished!")
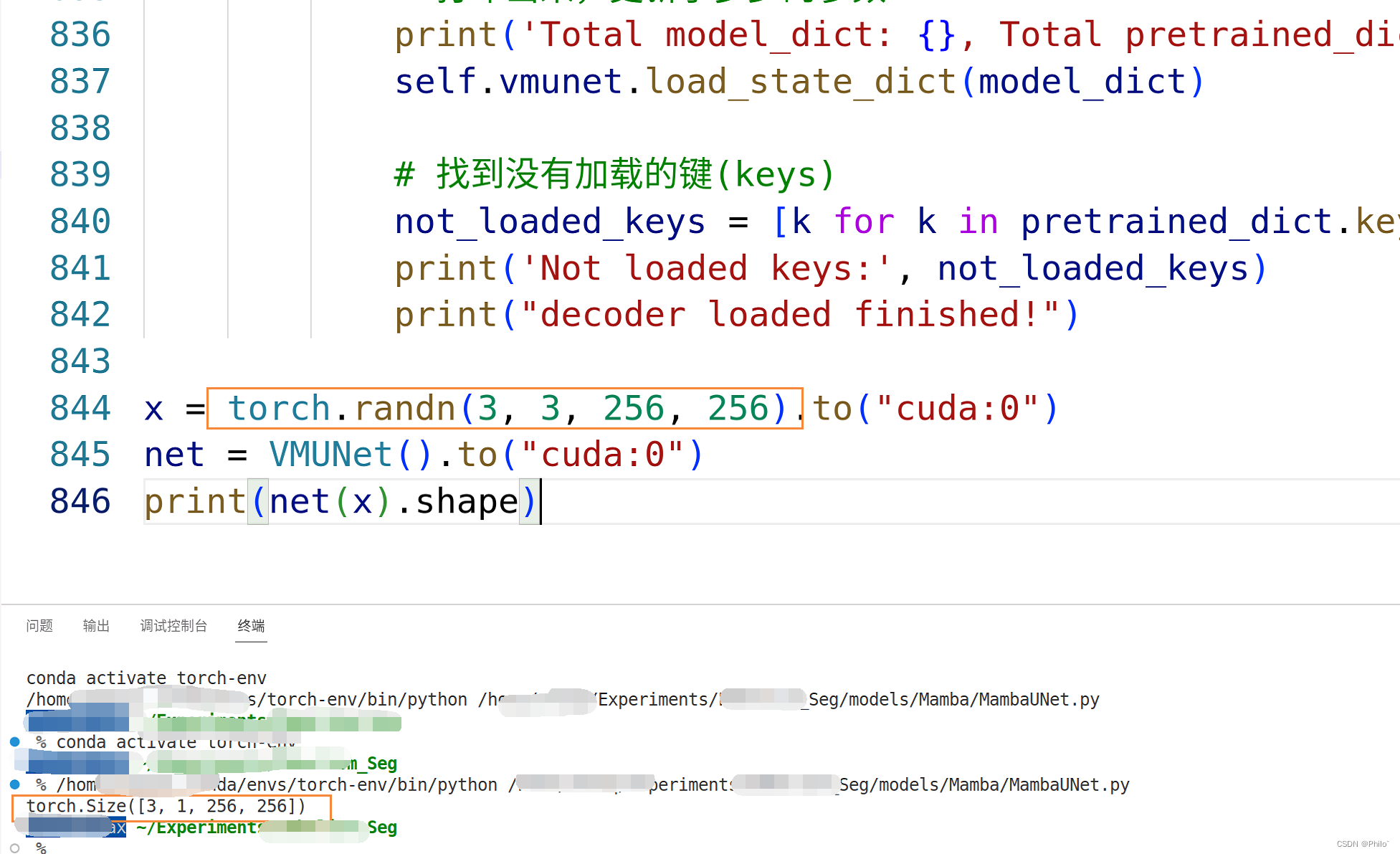
x = torch.randn(3, 3, 256, 256).to("cuda:0")
net = VMUNet().to("cuda:0")
print(net(x).shape)
直接复制使用,相较于原始代码,因为没安装成功selective_scan包,扫描代码发现其中只用到了一处,将其改成了mamba_scan中的函数了,实测效果不错,在自己最近做的任务中,分数可以排进前五!!





![P2680 [NOIP2015 提高组] 运输计划 第一个测试点信息 || 被卡常,链式前向星应该解决的是vector的push_back频繁扩容的耗时](https://img-blog.csdnimg.cn/direct/b53d90bab61a4f5ebf84843963e971a2.png)