其实细数AI的发展历程非常之久,而让AI的应用一下子出现在人们眼前的其实就是ChatGPT的出现,这意味着AIGC应用已经从概念为王变的非常实用了。伴随着ChatGPT的出现,大量的开源大模型也如雨后春笋一样出现。就现在而言,打造一个自己的AIGC应用已经非常简单了。
基础环境
我们需要配置一个环境
- python3.8+,不要太新
- CUDA+环境
- pytorch
- 支持C++17的编译器
首先我比较推荐你配置一个anaconda的环境,因为pytorch的其他安装方法真的很麻烦
- https://www.anaconda.com/distribution/#download-section
然后你需要安装CUDA的环境,正常来说只需要下载对应的CUDA版本即可
- CUDA Toolkit 12.3 Update 2 Downloads | NVIDIA Developer
然后就是安装pytorch的环境,这个环境比较麻烦,正常来说通过conda来安装是比较靠谱的办法,当然有些时候就是安不了。
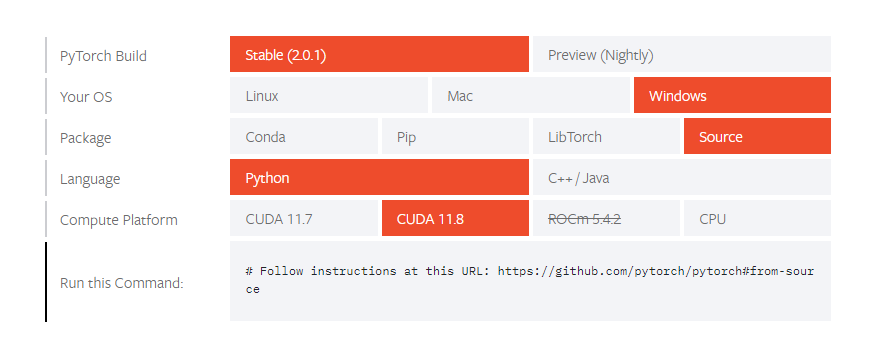
如果安装不成功,就只能用源码来编译了。
- GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
首先,clone一下源码
1 2 3 4 5 | git clone --recursive https://github.com/pytorch/pytorch cd pytorch # if you are updating an existing checkout git submodule sync git submodule update --init --recursive |
然后安装一下对应的各种依赖
1 2 3 4 5 6 7 8 | conda install cmake ninja # Run this command from the PyTorch directory after cloning the source code using the “Get the PyTorch Source“ section below pip install -r requirements.txt conda install mkl mkl-include # Add these packages if torch.distributed is needed. # Distributed package support on Windows is a prototype feature and is subject to changes. conda install -c conda-forge libuv=1.39 |
然后windows的源码编译有点儿复杂,具体要参考各种情况下的编译
- GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
在编译这个pytorch这个东西的时候我遇到过贼多问题,其中大部分问题我都搜不到解决方案,最终找到的最靠谱的方案是,不能用太低或者太高版本的python,会好解决很多,最终我选择了用3.10版本的python,解决了大部分的问题。
另外就是如果gpu不是很好或者显存不是很高,也可以使用cpu版本,大部分电脑的内存都会比较大,起码能跑起来。
如果是windows,那一定会用到huggingface,有个东西我建议一定要注意下。
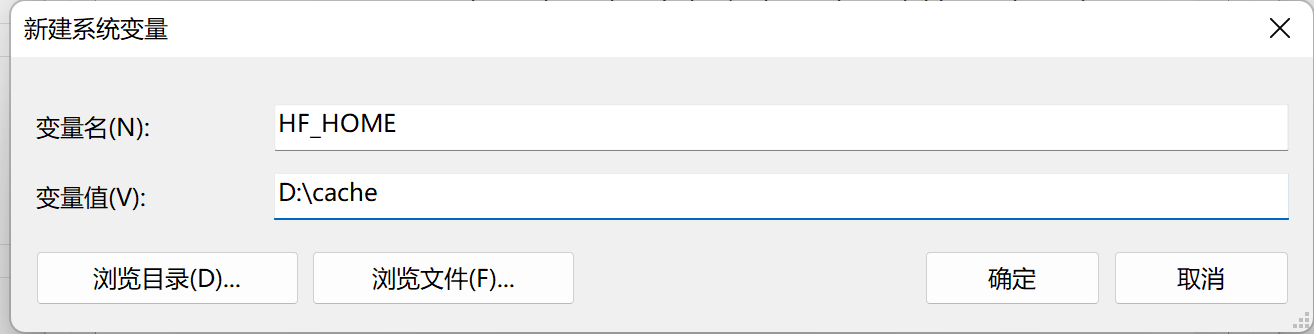
默认的huggingface和pytorch的缓存文件夹是在~/.cache/下,是在c盘下面,而一般LLM的模型文件都贼大,很容易把C盘塞满,这个注意要改下。
在环境变量里加入**HF_HOME和TORCH_HOME ,设**置为指定变量即可。
除此之外,有的项目也会提供docker化的部署方案,如果采用这种方案,就必须在宿主机安装NVIDIA Container Toolkit,并重启docker
1 2 3 | sudo apt-get install -y nvidia-container-toolkit-base sudo systemctl daemon-reload sudo systemctl restart docker |
进阶构成
LLM
LLM全称**Large Language Model,大语言模型,是以ChatGPT为代表的ai对话核心模块,相比我们无法控制、训练的ChatGPT,也逐渐在出现大量的开源大语言模型,尤其是以ChatGLM、LLaMA**为代表的轻量级语言模型相当好用。
虽然这些开源语言模型相比ChatGPT差距巨大,但深度垂直领域的ai应用也在逐渐被人们所认可。与其说我们想要在开源世界寻找ChatGPT的代替品,不如说这些开源大语言模型的出现,意味着我们有能力打造自己的GPT。
- ChatGLM-6B
- GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
- ChatGLM2-6B
- GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
目前中文领域效果最好,也是应用最多的开源底座模型。大部分的中文GPT二次开发几乎都是在这个模型的基础上做的开发,尤其是2代之后进一步拓展了基座模型的上下文长度。最厉害的是它允许商用。
- Moss
- GitHub - OpenLMLab/MOSS: An open-source tool-augmented conversational language model from Fudan University
MOSS是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
- ChatRWKV
- GitHub - BlinkDL/ChatRWKV: ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source.
一系列基于RWKV架构的Chat模型(包括英文和中文),发布了包括Raven,Novel-ChnEng,Novel-Ch与Novel-ChnEng-ChnPro等模型,可以直接闲聊及进行诗歌,小说等创作,包括7B和14B等规模的模型。
LLM的基座模型说实话有点儿多,尤其是在最开始的几个开源之后,后面各种LLM基座就像雨后春笋一样出现了,比较可惜的是目前的的开源模型距离ChatGPT的差距非常之大,大部分的模型只能达到GPT3的级别,距离GPT3.5都有几个量级的差距,更别提GPT4了。
- GitHub - HqWu-HITCS/Awesome-Chinese-LLM: 整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主,包括底座模型,垂直领域微调及应用,数据集与教程等。
- GitHub - chenking2020/FindTheChatGPTer: ChatGPT爆火,开启了通往AGI的关键一步,本项目旨在汇总那些ChatGPT的开源平替们,包括文本大模型、多模态大模型等,为大家提供一些便利
给大家看一个通过一些标准排名出来的LLM排行榜,这个说法比较多,一般就是看样本集的覆盖程度。
- GitHub - CLUEbenchmark/SuperCLUElyb: SuperCLUE琅琊榜:中文通用大模型匿名对战评价基准

Embedding
Embedding 模型也是GPT的很重要一环,在之前的文章里曾经提到过。由于GPT的只能依赖对话的模式受限于上下文的长度。
所以也就衍生出了不少的开源Embedding模型
- https://huggingface.co/GanymedeNil/text2vec-large-chinese
- https://huggingface.co/shibing624/text2vec-base-chinese

gradio
gradio是一个非常有名的机器学习用于数据演示的web框架。通过gradio可以快速的构建一个可以实时交互的web界面。有点儿像flask
- GitHub - gradio-app/gradio: Build and share delightful machine learning apps, all in Python. 🌟 Star to support our work!

首先要注意gradio最起码python在3.8版本以上.
1 2 3 4 5 6 7 8 | import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
|

gradio支持非常多这类的常用场景,就比如文本、勾选框、输入条,甚至文件上传、图片上传,都有非常不错的原生支持。
FastChat
FastChat是一个在LLM基础上构筑的一体化平台,FastChat是基于LLaMA做的二次调参训练。
1 | pip3 install fschat |
正常使用需要用机器生成Vicuna模型,将LLaMa weights合并Vicuna weights。而这个过程需要大量的内存和CPU,官方给出的参考数据是
- Vicuna-7B:30 GB of CPU RAM
- Vicuna-13B:60 GB of CPU RAM
如果没有足够的内存用,可以尝试下面两个办法来操作一下:
1、在命令中加入–low-cpu-mem,这个命令可以把峰值内存降到16G以下
2、创建一个比较大的交换分区让操作系统用硬盘作为虚拟内存
1 2 3 4 5 6 7 8 9 | python3 -m fastchat.model.apply_delta \
--base-model-path /path/to/llama-7b \
--target-model-path /path/to/output/vicuna-7b \
--delta-path lmsys/vicuna-7b-delta-v1.1
python3 -m fastchat.model.apply_delta \
--base-model-path /path/to/llama-13b \
--target-model-path /path/to/output/vicuna-13b \
--delta-path lmsys/vicuna-13b-delta-v1.1
|
下载完模型文件之后,可以快捷的使用对应的模型
1 | python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0 |
相比其他的基座模型LLM,FastChat的平台化程度就比较高了。
首先提供了controller和model worker分别部署的方案,一对多的方案本身比较符合项目化的结构。
1 2 3 | python3 -m fastchat.serve.controller python3 -m fastchat.serve.model_worker --model-path /path/to/model/weights |
而且同样利用gradio构建了相应的web界面
1 | python3 -m fastchat.serve.gradio_web_server |
除此之外FastChat还提供了和openai完全兼容的api接口和restfulapi.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import openai
openai.api_key = "EMPTY" # Not support yet
openai.api_base = "http://localhost:8000/v1"
model = "vicuna-7b-v1.3"
prompt = "Once upon a time"
# create a completion
completion = openai.Completion.create(model=model, prompt=prompt, max_tokens=64)
# print the completion
print(prompt + completion.choices[0].text)
# create a chat completion
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)
|
甚至可以直接以api的方式接入到其他的平台中,完成度很高。
知识库文件
知识库文件是langchain类方案中比较重要的一环,所有的问题会先进入知识库中搜索结果然后再作为上下文,知识库文件的数据量会直接影响到这类应用的结果有效度。而现在比较常见的相似度检测用的都是faiss,构建向量数据库用于数据比对。
- GitHub - facebookresearch/faiss: A library for efficient similarity search and clustering of dense vectors.
| 知识库数据 | FAISS向量 |
|---|---|
| 中文维基百科截止4月份数据,45万 | 链接:百度网盘 请输入提取码 提取码:l3pn |
| 截止去年九月的130w条中文维基百科处理结果和对应faiss向量文件 | 链接:百度网盘 请输入提取码 提取码:exij |
| 💹 大规模金融研报知识图谱 | 链接:百度网盘 请输入提取码 提取码:ujjv |
相应的现在很多应用还内置了用于测试知识库的接口,比如langchain-ChatGLM
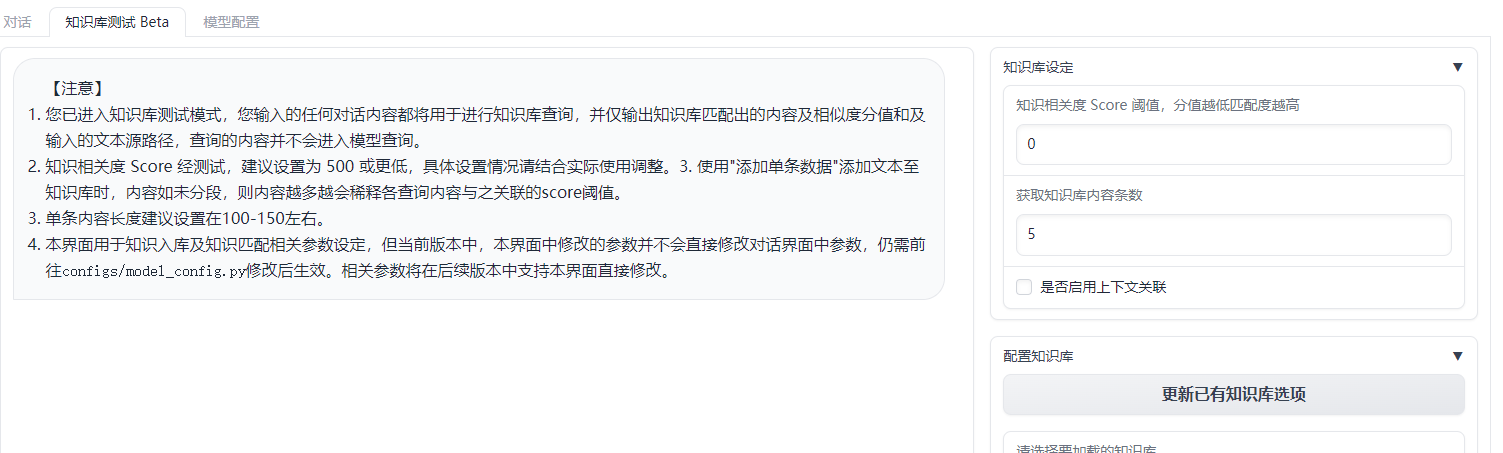
通过微调知识相关度的阈值,可以让回答消息更有效。你甚至可以直接在平台新建知识库并录入数据。
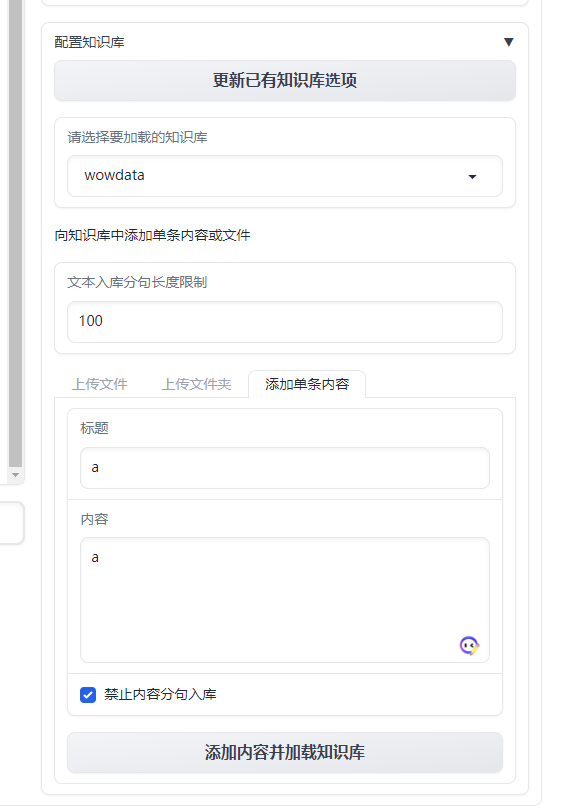
langchain
langchain是现在成熟度比较高的一套Aigc应用,现在比较主流的一种知识库检索方案,用的是曾经的文章中提到过的基于上下文的训练方案,用户输出会先进入数据库检索,然后找出最匹配问题的部分结果然后和问题一起加入到prompt的上下文中,最终由LLM生成最终的回答。
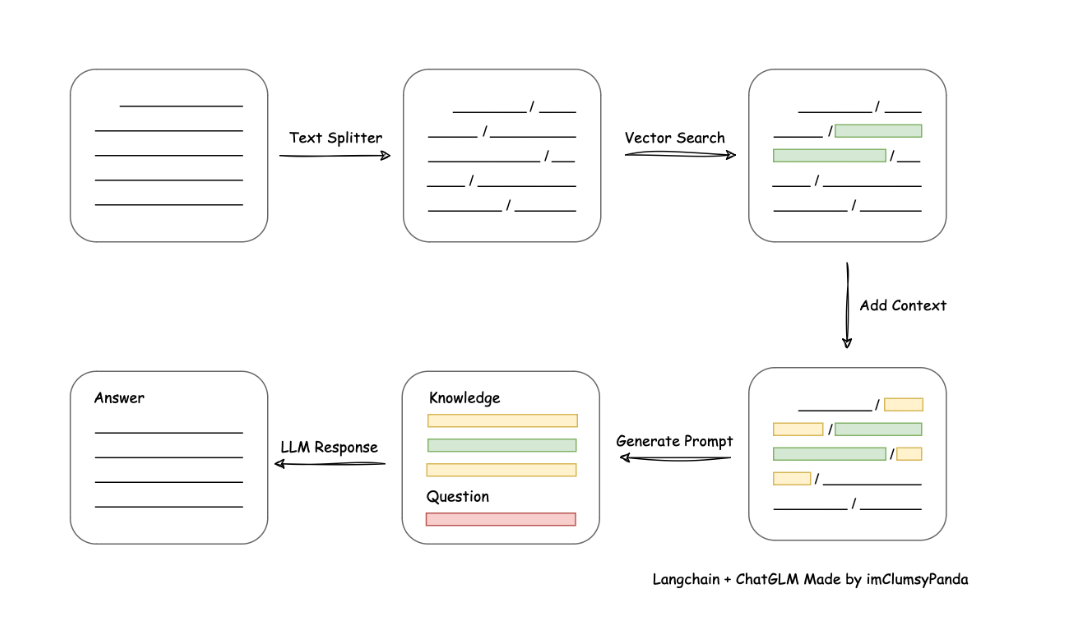
这个方案是目前最经典的知识库型训练方案,最有效的解决了大模型本身训练的难度和反馈结果的有效度难以兼容的问题。
- GitHub - langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications
建立在langchain的思想上,其实衍生了非常多比较有意思的项目,一方面引用了包括ChatGLM-6B等各种开源的大模型,也用了开源的embedding方案来处理文本。
- GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型

- https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main
另一方面呢也做了比较成熟的vue前端+知识库,可以快速的拼凑出可用的chat ai。
- GitHub - chatchat-space/Langchain-Chatchat: Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM 等语言模型的本地知识库问答 | Langchain-Chatchat (formerly langchain-ChatGLM), local knowledge based LLM (like ChatGLM) QA app with langchain
- GitHub - yanqiangmiffy/Chinese-LangChain: 中文langchain项目|小必应,Q.Talk,强聊,QiangTalk
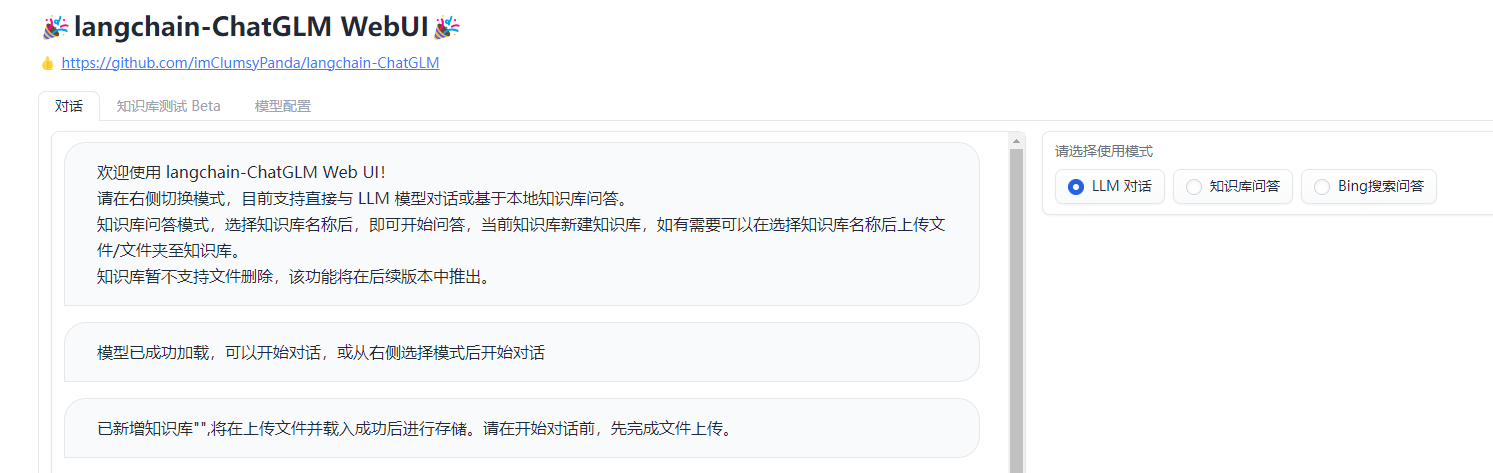
langchain-ChatGLM
langchain-ChatGLM是诸多langchain方案中中文支持实现的比较好的一个,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的**top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM**生成回答。
整个项目中的每个部分都可以一定程度的自由组合,Embedding 默认选用的是 GanymedeNil/text2vec-large-chinese,LLM 默认选用的是 ChatGLM-6B。或者也可以通过fastchat来接入。
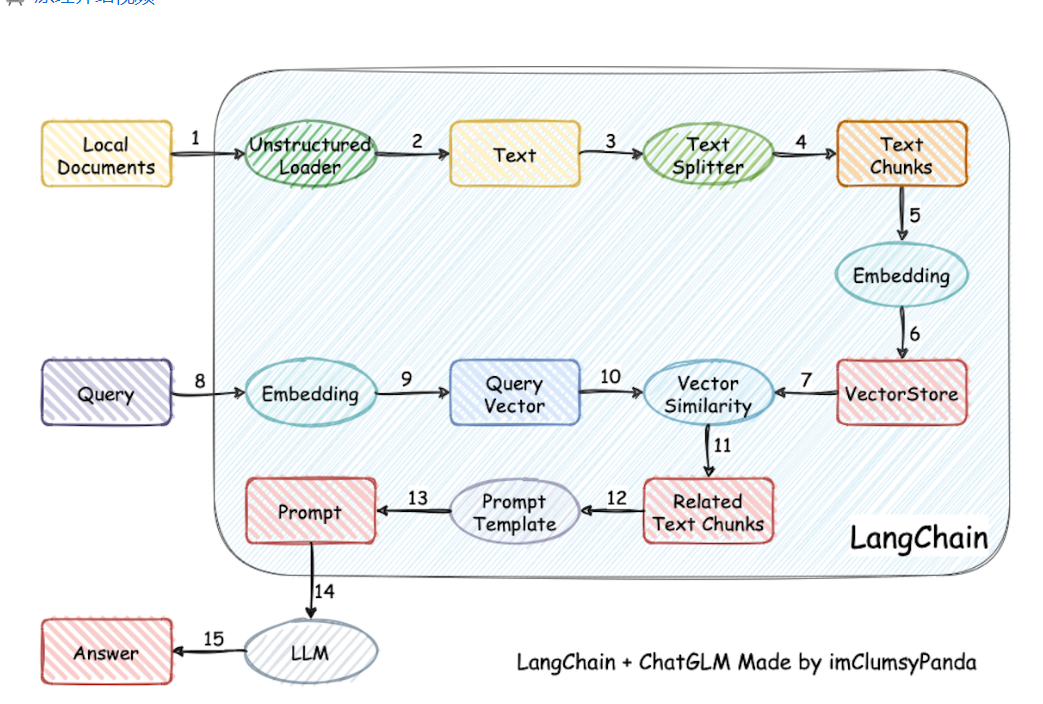
配置完成并安装好环境之后,就可以运行,首次运行会下载对应的大模型。

当然,这个模型实在是太大了,命令行下载的时候非常容易出问题,所以可以参考ChatGLM-6B的方案,自己下载模型然后再加载。
- GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
比较靠谱的就是先下模型实现,然后再单独下载模型并覆盖所有的文件
1 | GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b |
- 清华大学云盘
然后需要修改对应的配置文件中模型的位置,在configs/model_config.py

默认的知识库文件路径是
1 | knowledge_base\samples |
如果想用自用的本地知识文件,放在对应目录的knowledge_base即可。现在的知识库文件会遍历目录下的文件,所以指定目录即可。
1 | python cli_demo.py |

1 | python3.10 .\webui.py |