TensorRT推理时,如何比对中间层的误差
- 有二种方案
- 第二种方案的实现
- 1.运行环境的搭建
- 2.实现代码(compare_trt_onnxrt.py)
- 3.运行
- 4.输出
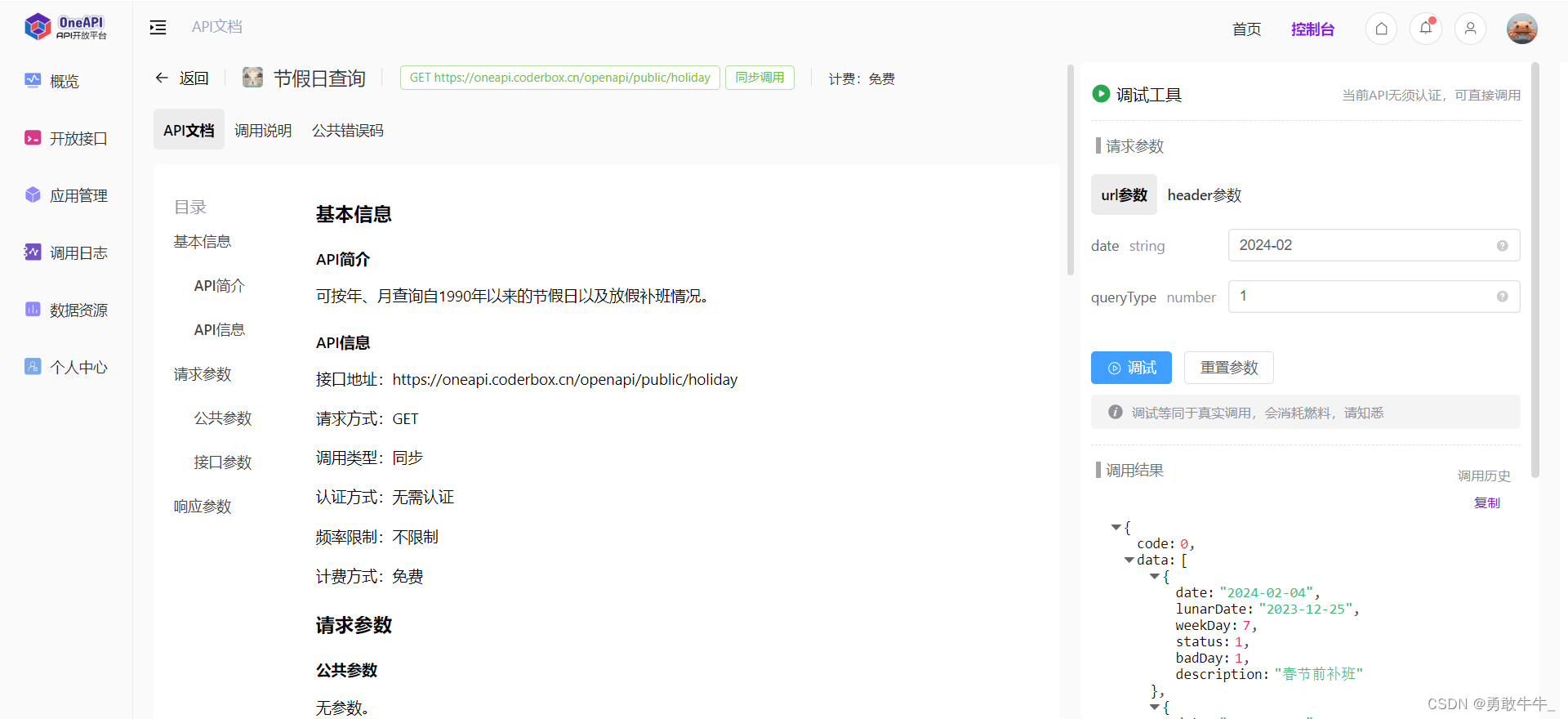
本文演示了TensorRT推理时,如何比对中间层的误差。
在做TensorRT推理加速时,可能会遇到精度问题,希望定位到是哪一个节点引起的误差,还是累计误差。
有二种方案
- 1.通过polygraphy run和–onnx-outputs和–trt-outputs参数,标记需要输出的节点。这种方法简单,但不灵活。
- 2.基于polygraphy api编程实现,该方法可以灵活设置希望标记为输出的节点
第二种方案的实现
1.运行环境的搭建
- 参考链接
2.实现代码(compare_trt_onnxrt.py)
from polygraphy.logger import G_LOGGER
import onnx
import torch
from torch.nn import functional as F
import tensorrt as trt
from polygraphy.comparator.data_loader import DataLoader
from polygraphy.backend.onnxrt import OnnxrtRunner, SessionFromOnnx
from polygraphy.backend.trt import EngineBytesFromNetwork, EngineFromBytes, NetworkFromOnnxPath, TrtRunner
from polygraphy.comparator import Comparator
from polygraphy.exception import PolygraphyException
from polygraphy.comparator.compare import CompareFunc
import pycuda.driver as cuda
import os
import pycuda.autoinit
import glob
from PIL import Image
import imageio as imageio
import numpy as np
import sys
import time
def get_img_data(img_lq):
'''图片预处理'''
img_t = torch.from_numpy(np.array(img_lq)).to('cpu').permute(2, 0, 1).unsqueeze(0)
img_t = (img_t/255.-0.5)/0.5
img_t = F.interpolate(img_t, (512, 512)).squeeze(0)
return img_t.numpy()
class MNISTEntropyCalibrator(trt.IInt8MinMaxCalibrator):
def __init__(self, cache_file):
trt.IInt8MinMaxCalibrator.__init__(self)
self.cache_file = cache_file
self.current_index = 0
self.batch_size=1
self.dataset = []
img_preprocess=get_img_data
for input_file in glob.glob("images/*"):
src_img = Image.open(input_file.strip())
src_img = img_preprocess(src_img)
src_img = np.expand_dims(src_img, 0)
src_tensor = torch.tensor(src_img).numpy()
self.dataset.append(src_tensor)
if len(self.dataset)==0:
self.dataset.append(torch.ones((1,3,512,512),dtype=torch.float32))
self.data=np.concatenate(self.dataset,axis=0)
self.total_samples=len(self.dataset)
self.device_input = cuda.mem_alloc(self.data[0].nbytes * self.batch_size)
def get_batch_size(self):
return self.batch_size
def get_batch(self, names):
if self.current_index + self.batch_size > self.total_samples:
return None
batch = self.data[self.current_index : self.current_index + self.batch_size].ravel()
cuda.memcpy_htod(self.device_input, batch)
self.current_index += self.batch_size
return [self.device_input]
def read_calibration_cache(self):
if os.path.exists(self.cache_file):
with open(self.cache_file, "rb") as f:
return f.read()
def write_calibration_cache(self, cache):
with open(self.cache_file, "wb") as f:
f.write(cache)
def main():
onnx_model_path="yolov5n.onnx"
onnx_model_output_path="yolov5n_tmp.onnx"
# 需要导出的节点类型(也可以修改为按name过滤)
filter_names=["Pow","Add","Sqrt","Div","Mul","LeakyRelu","Reduce","Conv","Gemm"]
# 标记onnx模型的输出节点
model = onnx.load(onnx_model_path)
for node in model.graph.node:
for name in filter_names:
if node.name.find(name)>=0:
for output in node.output[:1]:
model.graph.output.extend([onnx.ValueInfoProto(name=output)])
onnx.save(model,onnx_model_output_path)
parse_network_from_onnx = NetworkFromOnnxPath(onnx_model_path)
builder, network, parser=parse_network_from_onnx()
# TensorRT编译参数
config = builder.create_builder_config()
config.set_tactic_sources(1 << int(trt.TacticSource.CUBLAS))
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 2 << 30)
config.set_flag(trt.BuilderFlag.FP16)
if True: #是否为int8模式
calibration_cache = "calibration.cache"
if os.path.exists(calibration_cache):
os.remove(calibration_cache)
calib = MNISTEntropyCalibrator(cache_file=calibration_cache)
config.int8_calibrator = calib
config.set_flag(trt.BuilderFlag.INT8)
# 标记输出节点
for i in range(network.num_layers):
layer = network.get_layer(i)
if layer.type in [trt.LayerType.CONSTANT]:
continue
for name in filter_names:
if layer.name.find(name)>=0:
out_name=layer.get_output(0).name
if out_name!="skip.23":
layer.set_output_type(0, trt.DataType.FLOAT)
network.mark_output(layer.get_output(0))
break
build_engine = EngineBytesFromNetwork((builder, network, parser),config)
deserialize_engine = EngineFromBytes(build_engine)
build_onnxrt_session = SessionFromOnnx(onnx_model_output_path)
runners = [
TrtRunner(deserialize_engine),
OnnxrtRunner(build_onnxrt_session),
]
data_loader = DataLoader(val_range=(-1.0, 1.0))
results = Comparator.run(runners,data_loader)
success = True
#compare_func = CompareFunc.simple(check_shapes=True,show_heatmaps=False,rtol=1e-2,atol=1e-2)
# 忽略绝对误差,只关心相对误差
compare_func = CompareFunc.simple(check_shapes=True,show_heatmaps=False,rtol=1e-2,atol=1000)
success &= bool(Comparator.compare_accuracy(results,compare_func=compare_func))
if not success:
raise PolygraphyException('FAILED')
if __name__=="__main__":
main()
3.运行
# 安装pycuda
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
export CPATH=$CPATH:/usr/local/cuda/include
pip install pycuda==2023.1
# 执行
python compare_trt_onnxrt.py
4.输出