文章目录
- 一.for循环删除列表元素
- 1.删除list元素方法
- 2.直接删除往往结果与期望不一致
- 3.循环删除元素的正确方法:
- 方法1:while循环+i减
- 方法2:使用copy
- 方法3:倒叙遍历
- 二.字符串处理库
- 三.字典—dict运用
- 四.csv操作
- 五.excel操作
- 1.读excel——xlrd
- 2.写excel——xlwt
- 3.使用 openpyxl 来处理
- 4.使用Pandas库来处理excel数据
一.for循环删除列表元素
1.删除list元素方法
-
pop方法:是删除第一个或者是指定删除元素的下标。返回被删除的值。
list.pop(i) -
remove方法:直接指定要删除的元素值,删除首个匹配的值。
list.remove(item)list2=[1,2,3,4,5,6,7,5] list2.remove(5) print(list2) -
结果:
[1, 2, 3, 4, 6, 7, 5]- del 元素方法
-
可以删除指定下标的元素,删除指定下标范围内的多个元素,删除整个对象
list2=[1,2,3,4,5,6,7,5] del list2[1] print(list2) #[1, 3, 4, 5, 6, 7, 5] list2=[1,2,3,4,5,6,7,5] del list2[2:4] #删除3,4 print(list2) #[1, 2, 5, 6, 7, 5] list2=[1,2,3,4,5,6,7,5] del list2 print(list2) #NameError: name 'list2' is not defined
2.直接删除往往结果与期望不一致
python 使用for循环删除列表元素,容易出现结果与期望不一致问题。
- 例如代码:要删除列表中的3或者4,但是最后结果是4未删除掉。
list = [1, 2, 3, 4, 5]
print(list)
for ele in list:
if ele == 3 or ele == 4:
list.remove(ele)
else:
print(ele)
print(list)
结果:
[1, 2, 3, 4, 5]
1
2
5
[1, 2, 4, 5]
- 因为删除3后,3之后的[4,5]前移,4占了3原来的位置。下次循环是取3之后的数,即现在4之后的数(因为4去3的位置顶替了),也就是继续去判断5了。
3.循环删除元素的正确方法:
方法1:while循环+i减
- 使用while循环时刻监测数组长度,控制数组索引i,当i 遇到删除元素时候就往回移动一个元素位置,即减1
list=[1,2, 3, 4, 5]
i=0
#不能使用for i in range(0,len(num_list))会导致最后index溢出
while i < len(list):
if list[i] == 3 or list[i]==4:
list.pop(i)
i-=1
else:
print("num_list[{}]={}".format(i,list[i]))
i+=1
print(list)
结果:
num_list[0]=1
num_list[1]=2
num_list[2]=5
[1, 2, 5]
- 注意:while循环不可以换成for,for i in range(0,len(num_list))会导致最后索引i溢出
方法2:使用copy
- 切片是生成数组的copy方式之一
list = [1, 2, 3, 4, 5]
# num_list[:]是对num_list的拷贝
for item in list[:]:
if item == 3 or item==4:
list.remove(item)
else:
print(item)
print(list)
结果:
1
2
5
[1, 2, 5]
方法3:倒叙遍历
倒叙遍历,删除某个元素后,后面元素向前顶替位置,后面的元素是已经check过的,所以不会导致元素遗漏问题。
list = [1, 2, 3, 4, 5]
for i in range(len(list)-1, -1, -1):
if list[i] == 3 or list[i] == 4:
list.pop(i)
else:
print("num_list[{}]={}".format(i,list[i]))
print(list)
结果:
num_list[4]=5
num_list[1]=2
num_list[0]=1
[1, 2, 5]
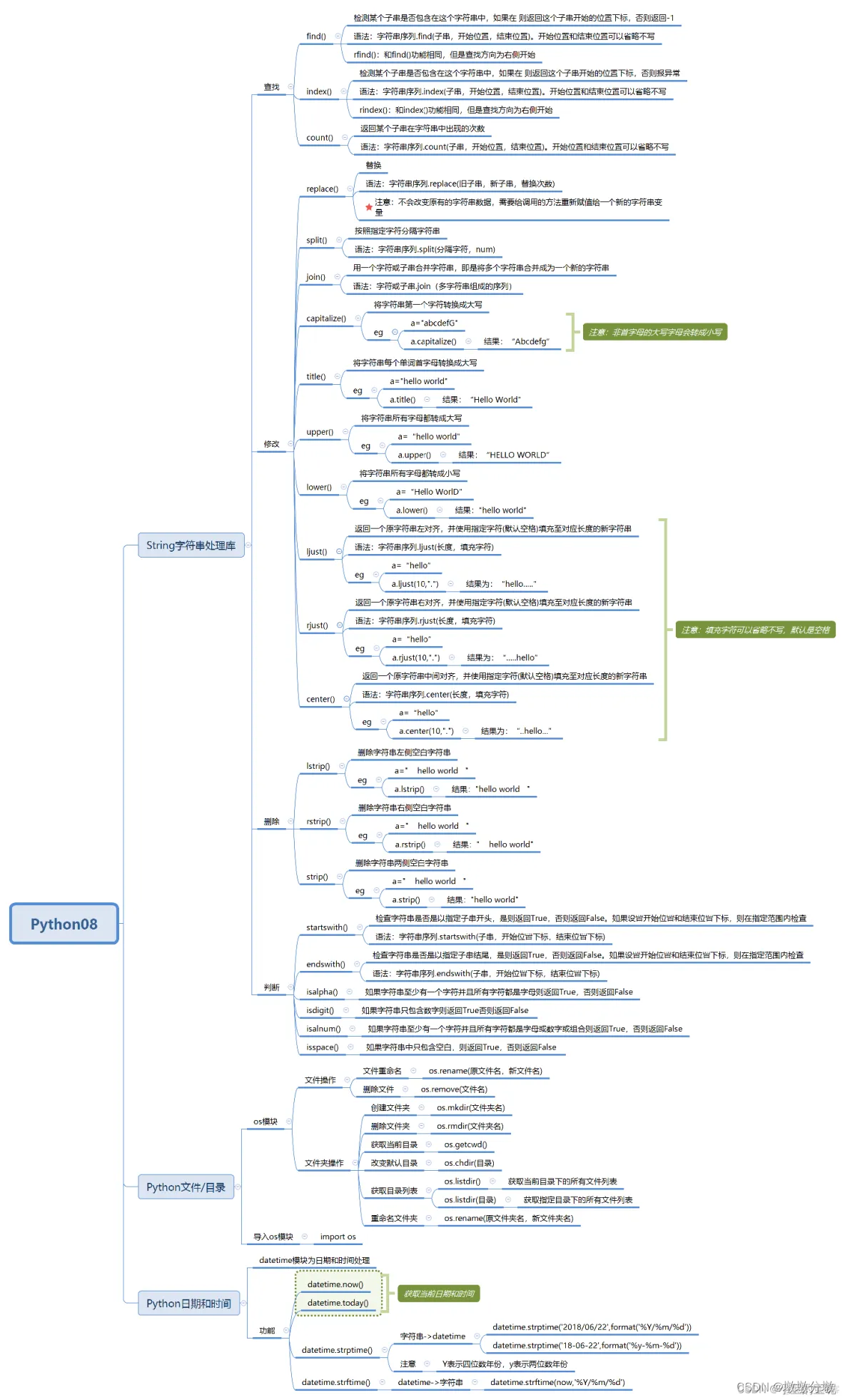
二.字符串处理库
三.字典—dict运用
-
setdefault() 函数 —有key获取值、没key设置 key:default
dict.setdefault(key, default=None)-
如果 key 在 字典中,返回对应的值。
-
如果 key 不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
-
-
get()函数—有key获取值、没key返回default:
dict.get(key, default=None)- 返回指定键的值,如果值不在字典中返回默认值 None。
而dict[key] 这种查询方法不要用,查询不到会报错
- 返回指定键的值,如果值不在字典中返回默认值 None。
四.csv操作
读取CSV文件,打开文件并创建一个csv.reader对象来读取文件的内容
import csv
with open(r'C:\Users\87772\Desktop\asr_text_20240223.csv', 'r') as file:
# 创建CSV读取器
reader = csv.reader(file)
# 遍历每一行
for row in reader:
print(row)
写入CSV文件,需要创建一个csv.writer对象,并将要写入的数据传递给它。
import csv
data = [
['Name', 'Age', 'Country'],
['John', 25, 'USA'],
['Alice', 30, 'Canada'],
['Bob', 35, 'UK']
]
#指定了参数newline='',以防止在写入文件时出现空行
with open(r'C:\Users\87772\Desktop\asr_text_20240223.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
五.excel操作
1.读excel——xlrd

示例1:Python读取Excel文件特定数据

示例2:Python读取Excel文件所有数据

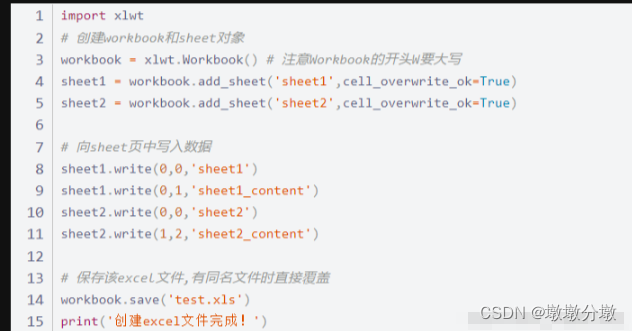
2.写excel——xlwt
xlwt模块只能写xls文件,不能写xlsx文件(写xlsx程序不会报错,但最后文件无法直接打开,会报错)。

示例:新建excel文件并写入数据
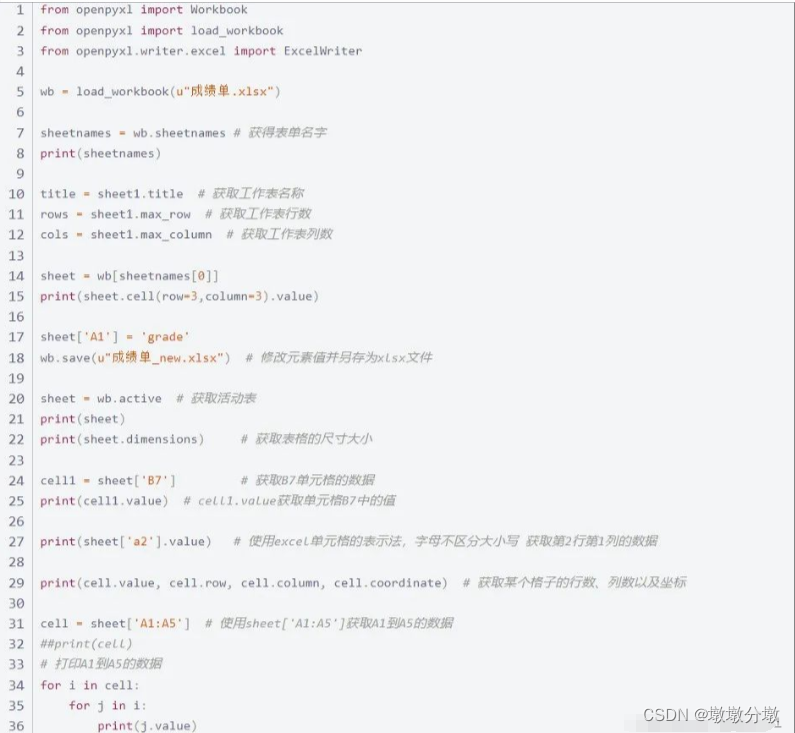
3.使用 openpyxl 来处理
openpyxl模块可实现对excel文件的读、写和修改,只能处理xlsx文件,不能处理xls文件。


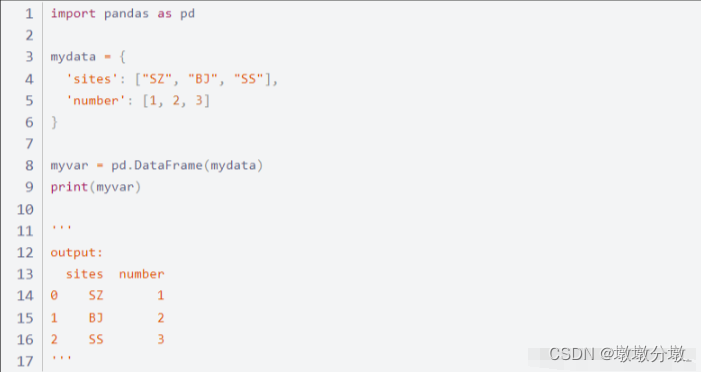
4.使用Pandas库来处理excel数据
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
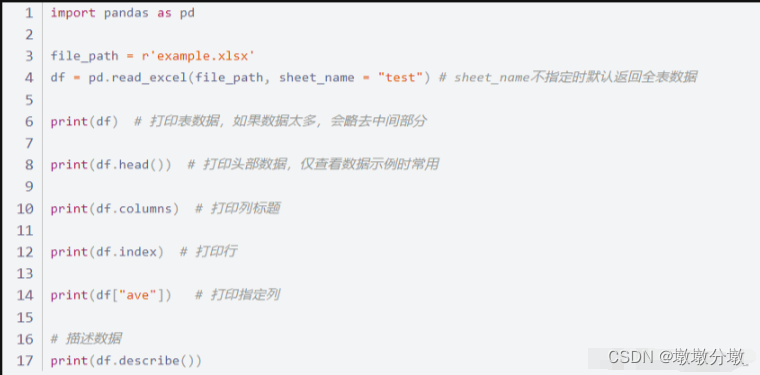
写excel

修改excel–以修改原Excel文件中gender列数据为例,把girl修改为female,boy修改为male:

示例1:读取excel数据

示例2:操作Excel中的行列





![[云原生] 二进制安装K8S(上)搭建单机matser、etcd集群和node节点](https://img-blog.csdnimg.cn/direct/b8c13775a13e466ebcb9dac39503e983.png)

![[HarekazeCTF2019]encode_and_encode 不会编程的崽](https://img-blog.csdnimg.cn/direct/799c8b05e4964382b4f95d1f70a1b93b.png)