导语:上一节我们详细探索非监督学习的进阶应用,详情可见:
机器学习基础(四)非监督学习的进阶探索-CSDN博客文章浏览阅读613次,点赞15次,收藏13次。非监督学习像一位探险家,挖掘未标记数据的未知领域。它不依赖预先定义的类别或标签,而是试图揭示数据自身的结构和关系。这种学习方式在处理复杂数据集时尤其有价值,因为它能发现人类可能未曾预见的模式和联系。https://blog.csdn.net/qq_52213943/article/details/136188233?spm=1001.2014.3001.5502 这一节,我们将详细探索监督与非监督学习的结合使用。
目录
监督与非监督学习的结合
监督与非监督学习的结合:解决复杂问题的优势
数据利用率的提高
更好的泛化能力
复杂情况下的应用
创新的解决方案
半监督学习:最佳两界的结合
概述
应用场景
技术实现
强化学习:决策的艺术
应用场景
半监督学习实例:使用自训练模型进行文本分类
强化学习实例:使用Q学习解决简单迷宫问题
环境设置
Q表初始化并开始学习
监督与非监督学习的结合
将监督学习和非监督学习结合起来,就像将两种不同的艺术形式融合,创造出全新的作品。这种结合利用了两种学习方法的优点,能够处理更复杂的数据集,并提高模型的准确性和泛化能力。
监督与非监督学习的结合:解决复杂问题的优势
在探讨监督学习和非监督学习结合方法时,一个关键的优势是它们在处理复杂和多变数据集时的能力。这种结合方法像是在搭建一个多功能的工具箱,不仅提高了解决问题的灵活性,还增强了模型对新情况的适应能力。
数据利用率的提高
在传统的监督学习中,模型完全依赖于大量的标记数据。然而,在现实世界中,标记数据往往稀缺且昂贵。通过结合非监督学习,我们可以利用未标记数据,这在很多情况下更容易获得。这种方法使得模型能够从更多的数据中学习,从而提高了整体的数据利用率。
更好的泛化能力
结合监督学习和非监督学习的方法可以提高模型的泛化能力。非监督学习部分帮助模型理解数据的基本结构和分布,使其在面对新的、未见过的数据时表现更好。这种能力对于那些需要模型具有高度适应性的应用场景尤为重要。
复杂情况下的应用
在一些复杂的场景中,比如自然语言处理或图像识别,单纯的监督学习或非监督学习可能无法有效处理所有情况。结合这两种方法可以提取更丰富的特征,理解更复杂的模式,从而在这些复杂的任务中取得更好的表现。
创新的解决方案
这种结合方法为机器学习提供了新的视角和技术路线,使研究人员和实践者能够探索前所未有的解决方案。例如,半监督学习和强化学习已经在诸如自动驾驶、个性化医疗等领域展现了其巨大的潜力。
半监督学习:最佳两界的结合
概述
半监督学习就像是桥梁,连接了监督学习和非监督学习的两个岛屿。在这座桥上,不仅可以利用标记数据(监督学习的特点),还可以利用大量未标记的数据(非监督学习的特点)。这种方法能够让我们在数据标记有限的情况下,最大化学习效率和模型性能。
在很多实际应用中,获取大量标记数据既昂贵又耗时。半监督学习通过利用未标记的数据,可以显著提升模型的学习能力。例如,通过观察未标记数据的分布,模型可以更好地理解整体数据结构,从而在有限的标记数据上做出更准确的推断。
通常,半监督学习首先使用未标记数据训练一个基础模型,捕捉数据的基本特征和结构。然后,使用标记数据对模型进行微调,以提高其对特定任务的准确性。
应用场景
- 文本分类。在文本分类任务中,我们可能只有少量的文本被标记了类别(如正面或负面情感),但有大量未标记的文本可用。半监督学习可以帮助我们利用这些未标记文本来提升分类模型的性能。
- 图像识别。在图像识别领域,半监督学习可以用于提升模型对新图像的识别能力,特别是在标记样本有限的情况下。
技术实现
- 自训练模型,这是一种简单的半监督学习方法,其中首先使用少量标记数据训练一个模型,然后用该模型预测未标记数据的标签,并将最有信心的预测结果作为新的训练数据。
- 生成式模型,例如,使用生成对抗网络(GANs)或变分自编码器(VAEs)来学习数据的分布,然后利用这些知识来指导监督学习任务。
强化学习:决策的艺术
虽然强化学习通常被视为一个独立的学习范式,但它也可以看作是监督学习和非监督学习的一个扩展。在强化学习中,模型通过与环境的互动来学习最佳行为或策略。
强化学习是机器学习的一个分支,它模拟了生物学习过程中的试错机制。你可以将它想象成一个游戏,其中的“玩家”(即学习算法)需要通过探索来学习如何完成特定任务或达成目标。
与传统的监督学习不同,强化学习不依赖于数据集中的标签,而是通过与环境的互动来学习。它就像是一个探险家,在每次尝试和失败中学习如何更好地做出决策。
试错过程:在强化学习中,算法(或智能体)通过尝试不同的行为并观察结果来学习。每当智能体做出选择,它会从环境中获得反馈(通常是奖励或惩罚),并据此调整其行为。
奖励系统:学习过程的核心在于奖励系统。智能体的目标是最大化其长期收到的奖励总和,这可能涉及到权衡短期利益和长期利益。
应用场景
自动驾驶汽车,在这个应用中,强化学习可以帮助汽车学习如何在复杂的道路环境中做出最佳的驾驶决策;游戏AI,从棋类游戏到视频游戏,强化学习被用来训练能够战胜人类玩家的高水平AI;个性化推荐,强化学习还可以用于个性化推荐系统,如在线购物或视频流平台,通过不断学习用户的偏好来提供更准确的推荐。
在强化学习应用于自动驾驶汽车的场景中,汽车被视为智能代理,在一个不断变化的环境中作出决策。这个环境包括其他车辆、行人、交通信号灯和道路的不同状况。
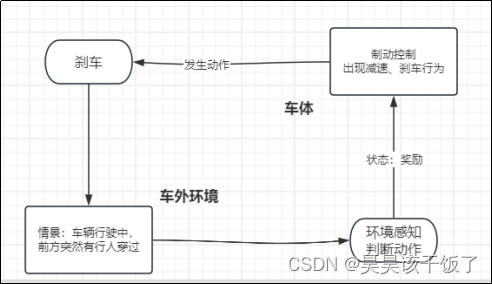
自动驾驶汽车(智能代理)通过观察环境状态,并基于这些观察做出减速动作,随后它会收到来自环境的反馈,图中是一个奖励信号,该信号表明其先前动作的效果。通过这种方式,汽车逐渐学习了哪些动作会导致正面的结果,从而改善其决策策略。强化学习算法通过与环境的交互学习,不断优化其决策策略,以实现如平滑驾驶、避免碰撞、遵守交通规则等目标。
半监督学习实例:使用自训练模型进行文本分类
假设有一些标记的文本数据和大量未标记的文本数据,开发者将使用这些数据来训练一个文本分类模型。具体来说,是使用自训练模型进行文本分类。本节的示例将展示如何结合少量的标记数据和大量的未标记数据来提升文本分类模型的性能,半监督学习文本分类的步骤如下。
- 数据准备:加载并分割已标记和未标记的数据。
- 模型训练:首先使用已标记数据训练基础分类器。
- 自训练:使用基础分类器对未标记数据进行预测,然后将预测结果中最自信的一部分加入训练集。
- 再训练:使用扩展的训练集重新训练分类器。
import pandas as pd
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.feature_extraction.text import CountVectorizer
# 加载数据(假设已经加载为Pandas DataFrame)
# labeled_data: 已标记数据; unlabeled_data: 未标记数据
# 'text'是文本特征,'label'是标签
# 向量化文本数据
vectorizer = CountVectorizer()
X_labeled = vectorizer.fit_transform(labeled_data['text'])
y_labeled = labeled_data['label']
X_unlabeled = vectorizer.transform(unlabeled_data['text'])
# 训练初始模型
model = SVC(probability=True)
model.fit(X_labeled, y_labeled)
# 预测未标记数据
proba = model.predict_proba(X_unlabeled)
# 选择最高置信度的数据
high_confidence_indices = [i for i, p in enumerate(proba.max(axis=1)) if p > 0.9]
new_training_samples = X_unlabeled[high_confidence_indices]
new_training_labels = model.predict(new_training_samples)
# 将新数据添加到训练集
X_train_extended = vstack([X_labeled, new_training_samples])
y_train_extended = np.concatenate([y_labeled, new_training_labels])
# 重新训练模型
model.fit(X_train_extended, y_train_extended)
# 评估模型性能(使用测试集,假设已经分割好)
X_test = vectorizer.transform(test_data['text'])
y_test = test_data['label']
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))强化学习实例:使用Q学习解决简单迷宫问题
在这个示例中,我们将展示如何使用Q学习(强化学习的一种方法。 Q学习就是要记录下学习过的策略,因而告诉智能体什么情况下采取什么行动会有最大的奖励值。)算法训练一个智能体在迷宫中找到出口。
环境设置
假设迷宫是一个网络,每个格点代表了智能体可能处于的状态。智能体可以采取动作,包括向上、向下、向左、向右四个方向的移动。在这个迷宫中,有一些状态被标记为出口,当智能体到达出口时,它将获得正奖励,这可以被视为成功完成任务的奖励(例如+1)。然而,迷宫中还存在一些障碍物或墙壁,如果智能体撞到墙壁,它将受到负奖励,这可以被视为一个惩罚(例如-1)。
在这个环境中,智能体的目标是学会采取适当的行动,以最大化累积奖励,从起始状态成功导航到出口状态,同时避免与墙壁碰撞。这个任务反映了强化学习中一个常见的情境,智能体必须在不断尝试和学习的过程中找到最佳策略,以达到预定的目标。
Q表初始化并开始学习
使用numpy创建一个Q表,每个状态-动作对应一个初始值(通常为0),智能体根据Q表以一定概率随机选择动作(探索),或选择具有最高Q值的动作(利用),执行动作后,环境提供下一个状态和奖励,根据公式更新Q表中的值:
Q(state,action) = Q(state,action) + α * (reward + γ * max(Q(next_state, all_actions)) - Q(state,action))
由公式可知,α是学习率,也是折扣因子。
import numpy as np
import random
# 定义迷宫的状态数和动作数
n_states = 4 # 例如迷宫有4个格子
n_actions = 4 # 上、下、左、右
# 初始化Q表
Q = np.zeros((n_states, n_actions))
# Q学习参数
alpha = 0.1 # 学习率
gamma = 0.6 # 折扣因子
epsilon = 0.1 # 探索率
# Q学习过程
for i in range(1000):
state = 0 # 假设起始状态为0
while state != n_states - 1: # 假设最后一个状态为出口
if random.uniform(0, 1) < epsilon:
action = random.randint(0, n_actions - 1) # 探索
else:
action = np.argmax(Q[state]) # 利用
# 假设getNextStateAndReward是一个函数,根据当前状态和动作返回下一个状态和奖励
next_state, reward = getNextStateAndReward(state, action)
# 更新Q值
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])
state = next_state
# 打印最终的Q表
print("Q-table:")
print(Q)在上述代码示例中,包括了一个简单的Q学习过程,用于在迷宫中学习一个Q表格。这个Q表格Q表格的每一行代表一个状态,每一列代表一个动作。智能体根据探索率(epsilon)选择探索或利用策略来采取动作,并使用Q学习的更新规则来更新Q值。这是一个基本的Q学习示例,用于解决迷宫问题。
下一节我们将进行TensorFlow与PyTorch工具的介绍讲解
机器学习基础(六)TensorFlow与PyTorch-CSDN博客对于追求稳定性和可扩展性的生产环境项目,TensorFlow可能更合适;而对于注重灵活性和快速迭代的研究项目,PyTorch可能更优。https://blog.csdn.net/qq_52213943/article/details/136215309?spm=1001.2014.3001.5502-----------------
以上,欢迎点赞收藏、评论区交流







![[算法沉淀记录] 排序算法 —— 冒泡排序](https://img-blog.csdnimg.cn/direct/9b01a18b50a44b08ad45fd9937b9e0fc.png)