前言
这不是高支模项目需要嘛,他们用传统算法切那个横杆竖杆流程复杂耗时很长,所以想能不能用机器学习完成这些工作,所以我就来整这个工作了。
基于上文的数据集切分 ,现在来对切分好的数据来进行正式的训练。
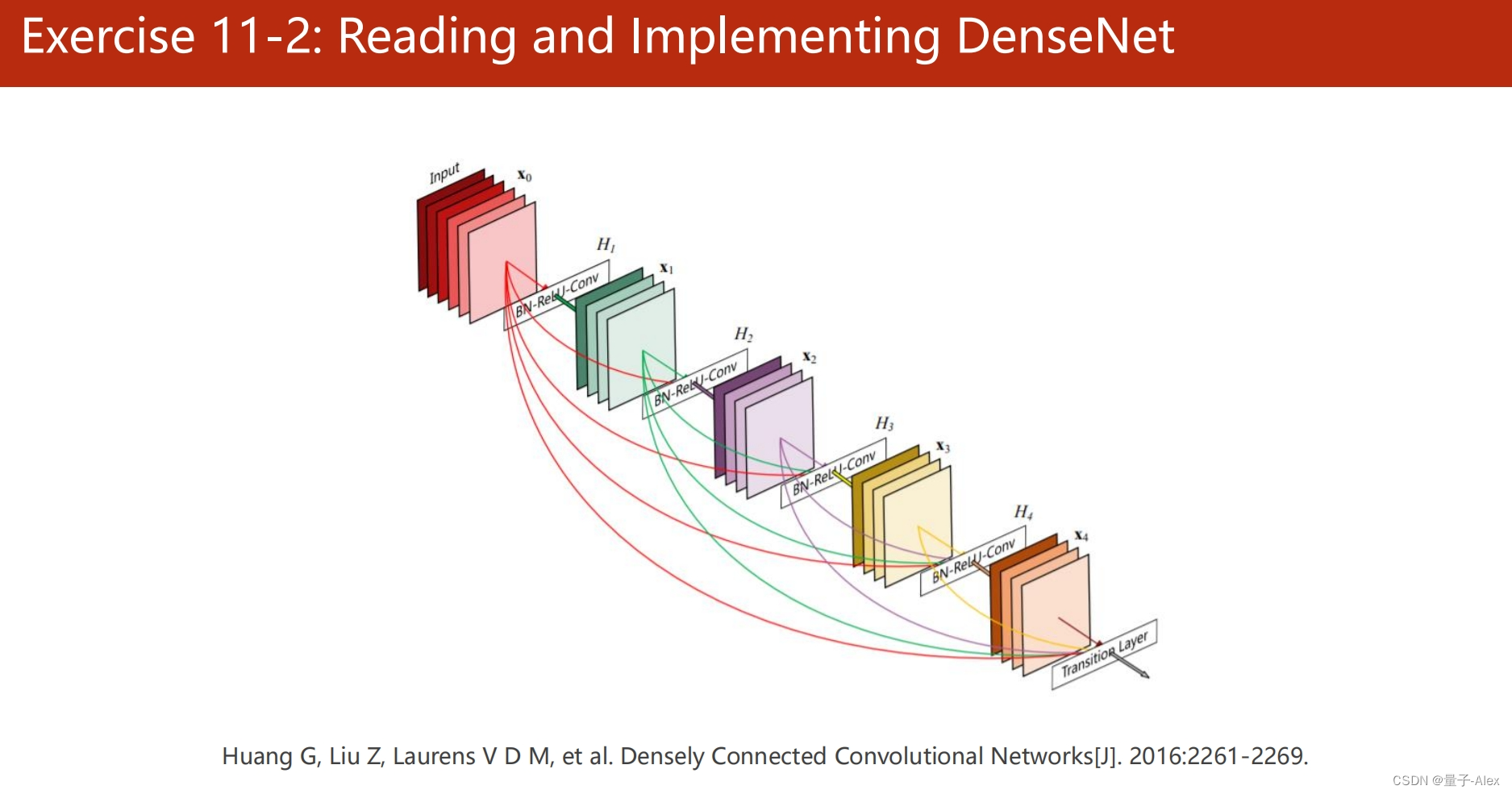
本系列文章所用的核心骨干网络代码主要来自点云处理:实现PointNet点云分割
原文的代码有点问题,这里做了一点修改,主要应用了paddlepaddle进行的pointNet进行分割任务。
流程
这里用的PointNet网络由于使用了全连接层,所以输入必须要抽稀出结果,故而流程如下:
- 读取原始点云和标签
- 随机对原始点云和标签进行采样
- 进行数据集划分
- 创建模型
- 进行训练
- 保存模型
- 对象评估
具体内容
1.依赖
import os
import tqdm
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", module="matplotlib")
from mpl_toolkits.mplot3d import Axes3D
# paddle相关库
import paddle
from paddle.io import Dataset
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm, Dropout, ReLU, Softmax, Sequential
2.点云的可视化
def visualize_data(point_cloud, label, title):
COLORS = ['b', 'y', 'r', 'g', 'pink']
label_map = ['none', 'Support']
df = pd.DataFrame(
data={
"x": point_cloud[:, 0],
"y": point_cloud[:, 1],
"z": point_cloud[:, 2],
"label": label,
}
)
fig = plt.figure(figsize=(15, 10))
ax = plt.axes(projection="3d")
ax.scatter(df["x"], df["y"], df["z"])
for i in range(label.min(), label.max()+1):
c_df = df[df['label'] == i]
ax.scatter(c_df["x"], c_df["y"], c_df["z"], label=label_map[i], alpha=0.5, c=COLORS[i])
ax.legend()
plt.title(title)
plt.show()
input()
3.点云抽稀和数据集
data_path = 'J:\\output\\Data'
label_path = 'J:\\output\\Label'
# 采样点
NUM_SAMPLE_POINTS = 1024
# 存储点云与label
point_clouds = []
point_clouds_labels = []
file_list = os.listdir(data_path)
for file_name in tqdm.tqdm(file_list):
# 获取label和data的地址
label_name = file_name.replace('.pts', '.seg')
point_cloud_file_path = os.path.join(data_path, file_name)
label_file_path = os.path.join(label_path, label_name)
# 读取label和data
point_cloud = np.loadtxt(point_cloud_file_path)
label = np.loadtxt(label_file_path).astype('int')
# 如果本身的点少于需要采样的点,则直接去除
if len(point_cloud) < NUM_SAMPLE_POINTS:
continue
# 采样
num_points = len(point_cloud)
# 确定随机采样的index
sampled_indices = random.sample(list(range(num_points)), NUM_SAMPLE_POINTS)
# 点云采样
sampled_point_cloud = np.array([point_cloud[i] for i in sampled_indices])
# label采样
sampled_label_cloud = np.array([label[i] for i in sampled_indices])
# 正则化
norm_point_cloud = sampled_point_cloud - np.mean(sampled_point_cloud, axis=0)
norm_point_cloud /= np.max(np.linalg.norm(norm_point_cloud, axis=1))
# 存储
point_clouds.append(norm_point_cloud)
point_clouds_labels.append(sampled_label_cloud)
class MyDataset(Dataset):
def __init__(self, data, label):
super(MyDataset, self).__init__()
self.data = data
self.label = label
def __getitem__(self, index):
data = self.data[index]
label = self.label[index]
data = np.reshape(data, (1, 1024, 3))
return data, label
def __len__(self):
return len(self.data)
4. 进行数据集的划分
# 数据集划分
VAL_SPLIT = 0.2
split_index = int(len(point_clouds) * (1 - VAL_SPLIT))
train_point_clouds = point_clouds[:split_index]
train_label_cloud = point_clouds_labels[:split_index]
print(train_label_cloud)
total_training_examples = len(train_point_clouds)
val_point_clouds = point_clouds[split_index:]
val_label_cloud = point_clouds_labels[split_index:]
print("Num train point clouds:", len(train_point_clouds))
print("Num train point cloud labels:", len(train_label_cloud))
print("Num val point clouds:", len(val_point_clouds))
print("Num val point cloud labels:", len(val_label_cloud))
# 测试定义的数据集
train_dataset = MyDataset(train_point_clouds, train_label_cloud)
val_dataset = MyDataset(val_point_clouds, val_label_cloud)
print('=============custom dataset test=============')
for data, label in train_dataset:
print('data shape:{} \nlabel shape:{}'.format(data.shape, label.shape))
break
# Batch_size 大小
BATCH_SIZE = 64
# # 数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = paddle.io.DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
5. 创建PointNet网络
class PointNet(paddle.nn.Layer):
def __init__(self, name_scope='PointNet_', num_classes=4, num_point=1024):
super(PointNet, self).__init__()
self.num_point = num_point
self.input_transform_net = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.input_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 9,
weight_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.zeros((256, 9)))),
bias_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.reshape(paddle.eye(3), [-1])))
)
)
self.mlp_1 = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 64,(1, 1)),
BatchNorm(64),
ReLU(),
)
self.feature_transform_net = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.feature_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 64*64)
)
self.mlp_2 = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128,(1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024,(1, 1)),
BatchNorm(1024),
ReLU(),
)
self.seg_net = Sequential(
Conv2D(1088, 512, (1, 1)),
BatchNorm(512),
ReLU(),
Conv2D(512, 256, (1, 1)),
BatchNorm(256),
ReLU(),
Conv2D(256, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, num_classes, (1, 1)),
Softmax(axis=1)
)
def forward(self, inputs):
batchsize = inputs.shape[0]
t_net = self.input_transform_net(inputs)
t_net = paddle.squeeze(t_net)
t_net = self.input_fc(t_net)
t_net = paddle.reshape(t_net, [batchsize, 3, 3])
x = paddle.reshape(inputs, shape=(batchsize, 1024, 3))
x = paddle.matmul(x, t_net)
x = paddle.unsqueeze(x, axis=1)
x = self.mlp_1(x)
t_net = self.feature_transform_net(x)
t_net = paddle.squeeze(t_net)
t_net = self.feature_fc(t_net)
t_net = paddle.reshape(t_net, [batchsize, 64, 64])
x = paddle.reshape(x, shape=(batchsize, 64, 1024))
x = paddle.transpose(x, (0, 2, 1))
x = paddle.matmul(x, t_net)
x = paddle.transpose(x, (0, 2, 1))
x = paddle.unsqueeze(x, axis=-1)
point_feat = x
x = self.mlp_2(x)
x = paddle.max(x, axis=2)
global_feat_expand = paddle.tile(paddle.unsqueeze(x, axis=1), [1, self.num_point, 1, 1])
x = paddle.concat([point_feat, global_feat_expand], axis=1)
x = self.seg_net(x)
x = paddle.squeeze(x, axis=-1)
x = paddle.transpose(x, (0, 2, 1))
return x
# 创建模型
model = PointNet()
model.train()
# 优化器定义
optim = paddle.optimizer.Adam(parameters=model.parameters(), weight_decay=0.001)
# 损失函数定义
loss_fn = paddle.nn.CrossEntropyLoss()
# 评价指标定义
m = paddle.metric.Accuracy()
6. 训练模型
# 训练轮数
epoch_num = 50
# 每多少个epoch保存
save_interval = 2
# 每多少个epoch验证
val_interval = 2
best_acc = 0
# 模型保存地址
output_dir = './output'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 训练过程
plot_acc = []
plot_loss = []
for epoch in range(epoch_num):
total_loss = 0
for batch_id, data in enumerate(train_loader()):
inputs = paddle.to_tensor(data[0], dtype='float32')
labels = paddle.to_tensor(data[1], dtype='int64')
print(data[1])
print(labels)
predicts = model(inputs)
# 计算损失和反向传播
loss = loss_fn(predicts, labels)
if loss.ndim == 0:
total_loss += loss.numpy() # 零维数组,直接取值
else:
total_loss += loss.numpy()[0] # 非零维数组,取第一个元素
loss.backward()
# 计算acc
predicts = paddle.reshape(predicts, (predicts.shape[0]*predicts.shape[1], -1))
labels = paddle.reshape(labels, (labels.shape[0]*labels.shape[1], 1))
correct = m.compute(predicts, labels)
m.update(correct)
# 优化器更新
optim.step()
optim.clear_grad()
avg_loss = total_loss/batch_id
plot_loss.append(avg_loss)
print("epoch: {}/{}, loss is: {}, acc is:{}".format(epoch, epoch_num, avg_loss, m.accumulate()))
m.reset()
# 保存
if epoch % save_interval == 0:
model_name = str(epoch)
paddle.save(model.state_dict(), './output/PointNet_{}.pdparams'.format(model_name))
paddle.save(optim.state_dict(), './output/PointNet_{}.pdopt'.format(model_name))
# 训练中途验证
if epoch % val_interval == 0:
model.eval()
for batch_id, data in enumerate(val_loader()):
inputs = paddle.to_tensor(data[0], dtype='float32')
labels = paddle.to_tensor(data[1], dtype='int64')
predicts = model(inputs)
predicts = paddle.reshape(predicts, (predicts.shape[0]*predicts.shape[1], -1))
labels = paddle.reshape(labels, (labels.shape[0]*labels.shape[1], 1))
correct = m.compute(predicts, labels)
m.update(correct)
val_acc = m.accumulate()
plot_acc.append(val_acc)
if val_acc > best_acc:
best_acc = val_acc
print("===================================val===========================================")
print('val best epoch in:{}, best acc:{}'.format(epoch, best_acc))
print("===================================train===========================================")
paddle.save(model.state_dict(), './output/best_model.pdparams')
paddle.save(optim.state_dict(), './output/best_model.pdopt')
m.reset()
model.train()
7.尝试对点云进行预测
ckpt_path = 'output/best_model.pdparams'
para_state_dict = paddle.load(ckpt_path)
# 加载网络和参数
model = PointNet()
model.set_state_dict(para_state_dict)
model.eval()
# 加载数据集
point_cloud = point_clouds[0]
show_point_cloud = point_cloud
point_cloud = paddle.to_tensor(np.reshape(point_cloud, (1, 1, 1024, 3)), dtype='float32')
label = point_clouds_labels[0]
# 前向推理
preds = model(point_cloud)
show_pred = paddle.argmax(preds, axis=-1).numpy() + 1
visualize_data(show_point_cloud, show_pred[0], 'pred')
visualize_data(show_point_cloud, label, 'label')
全流程代码
import os
import tqdm
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", module="matplotlib")
from mpl_toolkits.mplot3d import Axes3D
# paddle相关库
import paddle
from paddle.io import Dataset
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm, Dropout, ReLU, Softmax, Sequential
# 可视化使用的颜色和对应label的名字
def visualize_data(point_cloud, label, title):
COLORS = ['b', 'y', 'r', 'g', 'pink']
label_map = ['none', 'Support']
df = pd.DataFrame(
data={
"x": point_cloud[:, 0],
"y": point_cloud[:, 1],
"z": point_cloud[:, 2],
"label": label,
}
)
fig = plt.figure(figsize=(15, 10))
ax = plt.axes(projection="3d")
ax.scatter(df["x"], df["y"], df["z"])
for i in range(label.min(), label.max()+1):
c_df = df[df['label'] == i]
ax.scatter(c_df["x"], c_df["y"], c_df["z"], label=label_map[i], alpha=0.5, c=COLORS[i])
ax.legend()
plt.title(title)
plt.show()
input()
data_path = 'J:\\output\\Data'
label_path = 'J:\\output\\Label'
# 采样点
NUM_SAMPLE_POINTS = 1024
# 存储点云与label
point_clouds = []
point_clouds_labels = []
file_list = os.listdir(data_path)
for file_name in tqdm.tqdm(file_list):
# 获取label和data的地址
label_name = file_name.replace('.pts', '.seg')
point_cloud_file_path = os.path.join(data_path, file_name)
label_file_path = os.path.join(label_path, label_name)
# 读取label和data
point_cloud = np.loadtxt(point_cloud_file_path)
label = np.loadtxt(label_file_path).astype('int')
# 如果本身的点少于需要采样的点,则直接去除
if len(point_cloud) < NUM_SAMPLE_POINTS:
continue
# 采样
num_points = len(point_cloud)
# 确定随机采样的index
sampled_indices = random.sample(list(range(num_points)), NUM_SAMPLE_POINTS)
# 点云采样
sampled_point_cloud = np.array([point_cloud[i] for i in sampled_indices])
# label采样
sampled_label_cloud = np.array([label[i] for i in sampled_indices])
# 正则化
norm_point_cloud = sampled_point_cloud - np.mean(sampled_point_cloud, axis=0)
norm_point_cloud /= np.max(np.linalg.norm(norm_point_cloud, axis=1))
# 存储
point_clouds.append(norm_point_cloud)
point_clouds_labels.append(sampled_label_cloud)
#visualize_data(point_clouds[0], point_clouds_labels[0], 'label')
class MyDataset(Dataset):
def __init__(self, data, label):
super(MyDataset, self).__init__()
self.data = data
self.label = label
def __getitem__(self, index):
data = self.data[index]
label = self.label[index]
data = np.reshape(data, (1, 1024, 3))
return data, label
def __len__(self):
return len(self.data)
# 数据集划分
VAL_SPLIT = 0.2
split_index = int(len(point_clouds) * (1 - VAL_SPLIT))
train_point_clouds = point_clouds[:split_index]
train_label_cloud = point_clouds_labels[:split_index]
print(train_label_cloud)
total_training_examples = len(train_point_clouds)
val_point_clouds = point_clouds[split_index:]
val_label_cloud = point_clouds_labels[split_index:]
print("Num train point clouds:", len(train_point_clouds))
print("Num train point cloud labels:", len(train_label_cloud))
print("Num val point clouds:", len(val_point_clouds))
print("Num val point cloud labels:", len(val_label_cloud))
# 测试定义的数据集
train_dataset = MyDataset(train_point_clouds, train_label_cloud)
val_dataset = MyDataset(val_point_clouds, val_label_cloud)
print('=============custom dataset test=============')
for data, label in train_dataset:
print('data shape:{} \nlabel shape:{}'.format(data.shape, label.shape))
break
# Batch_size 大小
BATCH_SIZE = 64
# # 数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = paddle.io.DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
class PointNet(paddle.nn.Layer):
def __init__(self, name_scope='PointNet_', num_classes=4, num_point=1024):
super(PointNet, self).__init__()
self.num_point = num_point
self.input_transform_net = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.input_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 9,
weight_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.zeros((256, 9)))),
bias_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.reshape(paddle.eye(3), [-1])))
)
)
self.mlp_1 = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 64,(1, 1)),
BatchNorm(64),
ReLU(),
)
self.feature_transform_net = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.feature_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 64*64)
)
self.mlp_2 = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128,(1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024,(1, 1)),
BatchNorm(1024),
ReLU(),
)
self.seg_net = Sequential(
Conv2D(1088, 512, (1, 1)),
BatchNorm(512),
ReLU(),
Conv2D(512, 256, (1, 1)),
BatchNorm(256),
ReLU(),
Conv2D(256, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, num_classes, (1, 1)),
Softmax(axis=1)
)
def forward(self, inputs):
batchsize = inputs.shape[0]
t_net = self.input_transform_net(inputs)
t_net = paddle.squeeze(t_net)
t_net = self.input_fc(t_net)
t_net = paddle.reshape(t_net, [batchsize, 3, 3])
x = paddle.reshape(inputs, shape=(batchsize, 1024, 3))
x = paddle.matmul(x, t_net)
x = paddle.unsqueeze(x, axis=1)
x = self.mlp_1(x)
t_net = self.feature_transform_net(x)
t_net = paddle.squeeze(t_net)
t_net = self.feature_fc(t_net)
t_net = paddle.reshape(t_net, [batchsize, 64, 64])
x = paddle.reshape(x, shape=(batchsize, 64, 1024))
x = paddle.transpose(x, (0, 2, 1))
x = paddle.matmul(x, t_net)
x = paddle.transpose(x, (0, 2, 1))
x = paddle.unsqueeze(x, axis=-1)
point_feat = x
x = self.mlp_2(x)
x = paddle.max(x, axis=2)
global_feat_expand = paddle.tile(paddle.unsqueeze(x, axis=1), [1, self.num_point, 1, 1])
x = paddle.concat([point_feat, global_feat_expand], axis=1)
x = self.seg_net(x)
x = paddle.squeeze(x, axis=-1)
x = paddle.transpose(x, (0, 2, 1))
return x
# 创建模型
model = PointNet()
model.train()
# 优化器定义
optim = paddle.optimizer.Adam(parameters=model.parameters(), weight_decay=0.001)
# 损失函数定义
loss_fn = paddle.nn.CrossEntropyLoss()
# 评价指标定义
m = paddle.metric.Accuracy()
# 训练轮数
epoch_num = 50
# 每多少个epoch保存
save_interval = 2
# 每多少个epoch验证
val_interval = 2
best_acc = 0
# 模型保存地址
output_dir = './output'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 训练过程
plot_acc = []
plot_loss = []
for epoch in range(epoch_num):
total_loss = 0
for batch_id, data in enumerate(train_loader()):
inputs = paddle.to_tensor(data[0], dtype='float32')
labels = paddle.to_tensor(data[1], dtype='int64')
print(data[1])
print(labels)
predicts = model(inputs)
# 计算损失和反向传播
loss = loss_fn(predicts, labels)
if loss.ndim == 0:
total_loss += loss.numpy() # 零维数组,直接取值
else:
total_loss += loss.numpy()[0] # 非零维数组,取第一个元素
loss.backward()
# 计算acc
predicts = paddle.reshape(predicts, (predicts.shape[0]*predicts.shape[1], -1))
labels = paddle.reshape(labels, (labels.shape[0]*labels.shape[1], 1))
correct = m.compute(predicts, labels)
m.update(correct)
# 优化器更新
optim.step()
optim.clear_grad()
avg_loss = total_loss/batch_id
plot_loss.append(avg_loss)
print("epoch: {}/{}, loss is: {}, acc is:{}".format(epoch, epoch_num, avg_loss, m.accumulate()))
m.reset()
# 保存
if epoch % save_interval == 0:
model_name = str(epoch)
paddle.save(model.state_dict(), './output/PointNet_{}.pdparams'.format(model_name))
paddle.save(optim.state_dict(), './output/PointNet_{}.pdopt'.format(model_name))
# 训练中途验证
if epoch % val_interval == 0:
model.eval()
for batch_id, data in enumerate(val_loader()):
inputs = paddle.to_tensor(data[0], dtype='float32')
labels = paddle.to_tensor(data[1], dtype='int64')
predicts = model(inputs)
predicts = paddle.reshape(predicts, (predicts.shape[0]*predicts.shape[1], -1))
labels = paddle.reshape(labels, (labels.shape[0]*labels.shape[1], 1))
correct = m.compute(predicts, labels)
m.update(correct)
val_acc = m.accumulate()
plot_acc.append(val_acc)
if val_acc > best_acc:
best_acc = val_acc
print("===================================val===========================================")
print('val best epoch in:{}, best acc:{}'.format(epoch, best_acc))
print("===================================train===========================================")
paddle.save(model.state_dict(), './output/best_model.pdparams')
paddle.save(optim.state_dict(), './output/best_model.pdopt')
m.reset()
model.train()
ckpt_path = 'output/best_model.pdparams'
para_state_dict = paddle.load(ckpt_path)
# 加载网络和参数
model = PointNet()
model.set_state_dict(para_state_dict)
model.eval()
# 加载数据集
point_cloud = point_clouds[0]
show_point_cloud = point_cloud
point_cloud = paddle.to_tensor(np.reshape(point_cloud, (1, 1, 1024, 3)), dtype='float32')
label = point_clouds_labels[0]
# 前向推理
preds = model(point_cloud)
show_pred = paddle.argmax(preds, axis=-1).numpy() + 1
visualize_data(show_point_cloud, show_pred[0], 'pred')
visualize_data(show_point_cloud, label, 'label')
看了下结果,对点云的数据进行了一个测试
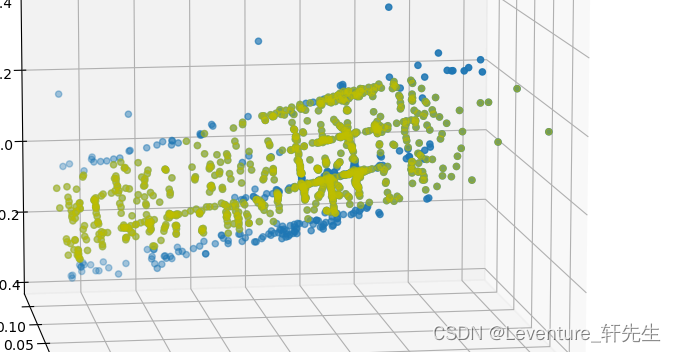
目标检测的是横杆,训练集的数据较少,所以结果比较一般,后续可以添加更多数据,应该能得到更好的结果。