文章目录
- 分类度量
- 混淆矩阵(Confusion Matrix):
- 二分类问题
- 二分类代码
- 多分类问题
- 多分类宏平均法:
- 多分类代码
- 多分类微平均法:
- 准确率(Accuracy):
- 精确率(Precision):
- 召回率(Recall):
- F1 分数(F1 Score):
- F-Score
- F1-Score
- F2-Score
- 其他F-Scores
- 为何使用F-Score?
- ROC 曲线(Receiver Operating Characteristic curve):
- 二分类ROC
- 多分类ROC
- 宏平均
- 微平均
- AUC(Area Under the ROC Curve):
- Cohen's Kappa:
- Matthews相关系数(Matthews Correlation Coefficient,MCC):
- 最优阈值
分类度量
以下是一些常见的分类任务中使用的度量:
混淆矩阵(Confusion Matrix):
// 计算混淆矩阵 -多分类
Eigen::MatrixXd calculateConfusionMatrix(const std::vector<Eigen::VectorXd>& predictions, const std::vector<Eigen::VectorXd>& targets)
{
size_t row = predictions.at(0).size()+1;
Eigen::MatrixXd confusionMat = Eigen::MatrixXd::Zero(row,row);
// 获取最大值所在的索引位置
int pIndex,tIndex;
for (size_t i = 0; i < predictions.size(); ++i)
{
predictions.at(i).maxCoeff(&pIndex);
targets.at(i).maxCoeff(&tIndex);
confusionMat(tIndex,pIndex)++;
}
//统计矩阵中数据放到最后一列和最后一行
for (size_t i = 0; i < row-1; ++i)
{
//累加行数据放到最后一列
confusionMat(i,row-1) = confusionMat.row(i).sum();
//累加列数据放到最后一行
confusionMat(row-1,i) = confusionMat.col(i).sum();
}
//最后一个数据
confusionMat(row-1,row-1) = confusionMat.col(row-1).sum();
return confusionMat;
}
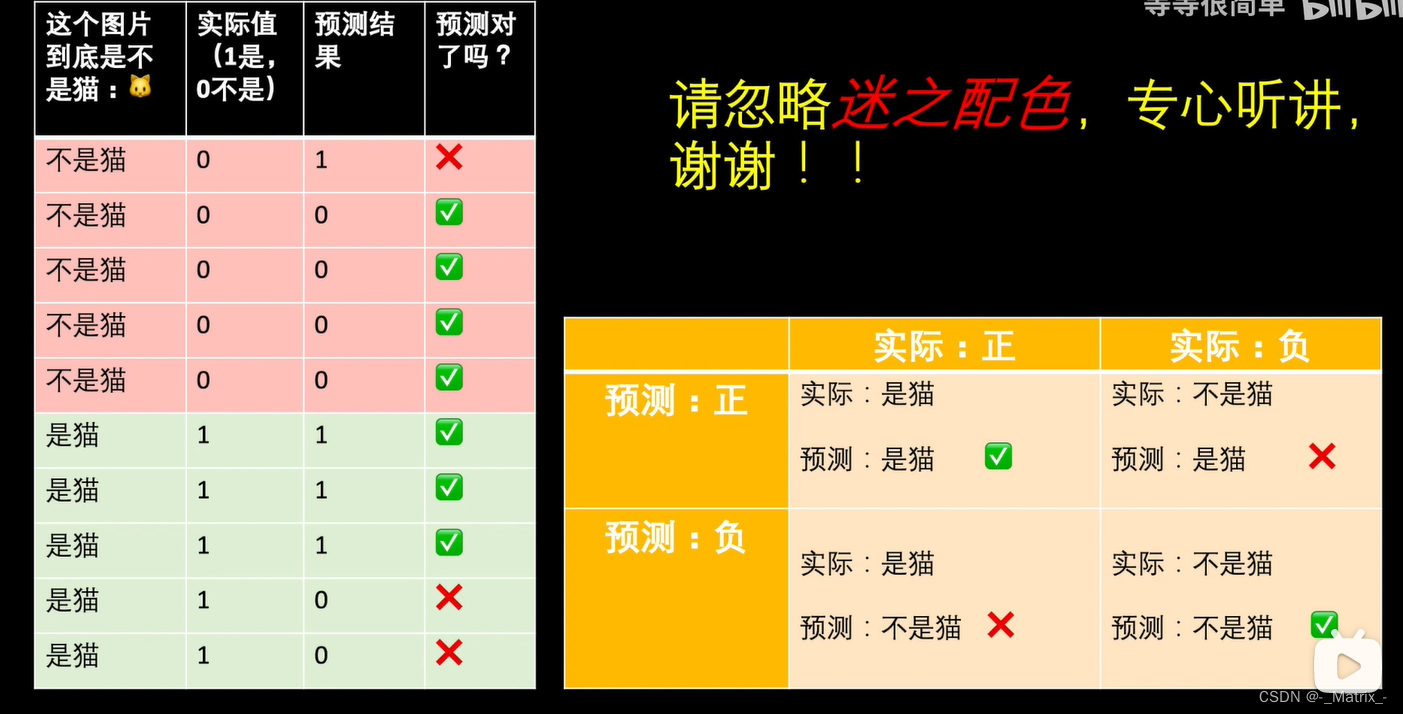
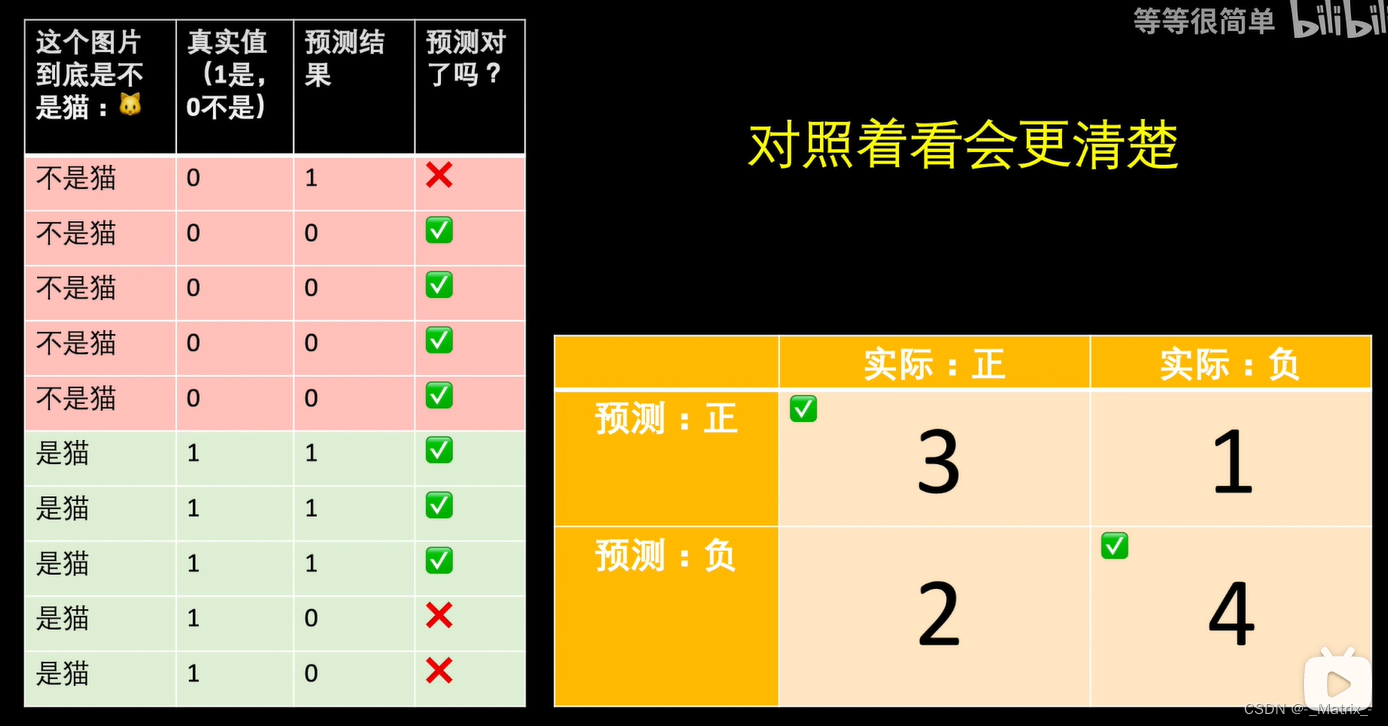
混淆矩阵是用于描述分类模型性能的表格,包括真正例、假正例、真负例和假负例的数量。
混淆矩阵(Confusion Matrix),也称为误差矩阵(Error Matrix),是用于衡量分类模型性能的一种矩阵形式的工具,特别适用于二分类问题。
二分类问题
混淆矩阵是一个2x2矩阵,其中每一行代表了真实的类别,每一列代表了模型的预测类别。它将预测结果与真实标签之间的四种不同情况进行了分类,包括真正类(True Positive,TP)、真负类(True Negative,TN)、假正类(False Positive,FP)和假负类(False Negative,FN)。
混淆矩阵(Confusion Matrix)中的四个元素用符号表示如下:
- TP(True Positive):正类别样本中,模型预测正确为正类别的样本数。
- TN(True Negative):负类别样本中,模型预测正确为负类别的样本数。
- FP(False Positive):负类别样本中,模型错误地预测为正类别的样本数。
- FN(False Negative):正类别样本中,模型错误地预测为负类别的样本数。
混淆矩阵的一般形式如下:
| | 预测为正类别 | 预测为负类别 |
|-------------|--------------|--------------|
| 真实为正类别 | TP | FN |
| 真实为负类别 | FP | TN |
通过混淆矩阵,我们可以计算出一系列分类模型的性能指标,如下所示:
-
精确率(Precision):用于衡量在所有被预测为正类别的样本中,有多少是真正的正类别。
公式: P r e c i s i o n = T P / ( T P + F P ) Precision = TP / (TP + FP) Precision=TP/(TP+FP) -
召回率(Recall):用于衡量在所有真实为正类别的样本中,有多少被正确预测为正类别。
公式: R e c a l l = T P / ( T P + F N ) Recall = TP / (TP + FN) Recall=TP/(TP+FN) -
F1分数(F1 Score):精确率和召回率的调和平均数,综合了两者的性能。
公式: F 1 S c o r e = 2 ∗ ( P r e c i s i o n ∗ R e c a l l ) / ( P r e c i s i o n + R e c a l l ) F1 Score = 2 * (Precision * Recall) / (Precision + Recall) F1Score=2∗(Precision∗Recall)/(Precision+Recall) -
准确率(Accuracy):用于衡量模型在所有样本中正确预测的比例。
公式: A c c u r a c y = ( T P + T N ) / ( T P + T N + F P + F N ) Accuracy = (TP + TN) / (TP + TN + FP + FN) Accuracy=(TP+TN)/(TP+TN+FP+FN)
这些指标可以帮助我们全面评估分类模型的性能,并更好地理解模型在不同类别下的预测表现。
二分类代码
以下是用C++编写的一个简单示例代码,用于计算混淆矩阵的四个元素(TP、TN、FP、FN)和计算精确率(Precision)、召回率(Recall)、F1分数(F1 Score)和准确率(Accuracy):
#include <iostream>
#include <vector>
// 计算混淆矩阵的四个元素(TP、TN、FP、FN)
void calculateConfusionMatrix(const std::vector<int>& predictions, const std::vector<int>& targets,
int& TP, int& TN, int& FP, int& FN) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return;
}
TP = TN = FP = FN = 0;
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == 1) {
if (targets[i] == 1) {
TP++;
} else {
FP++;
}
} else {
if (targets[i] == 0) {
TN++;
} else {
FN++;
}
}
}
}
// 计算精确率(Precision)
double calculatePrecision(int TP, int FP) {
if (TP + FP == 0) {
return 0.0;
}
return static_cast<double>(TP) / (TP + FP);
}
// 计算召回率(Recall)
double calculateRecall(int TP, int FN) {
if (TP + FN == 0) {
return 0.0;
}
return static_cast<double>(TP) / (TP + FN);
}
// 计算F1分数(F1 Score)
double calculateF1Score(double precision, double recall) {
if (precision == 0.0 || recall == 0.0) {
return 0.0;
}
return 2 * (precision * recall) / (precision + recall);
}
// 计算准确率(Accuracy)
double calculateAccuracy(int TP, int TN, int FP, int FN) {
int totalSamples = TP + TN + FP + FN;
if (totalSamples == 0) {
return 0.0;
}
return static_cast<double>(TP + TN) / totalSamples;
}
int main() {
// 假设有10个样本的预测值和真实值
std::vector<int> predictions = {1, 0, 1, 1, 0, 1, 0, 0, 1, 1};
std::vector<int> targets = {1, 0, 0, 1, 0, 1, 1, 0, 1, 1};
int TP, TN, FP, FN;
// 计算混淆矩阵的四个元素
calculateConfusionMatrix(predictions, targets, TP, TN, FP, FN);
// 计算精确率(Precision)
double precision = calculatePrecision(TP, FP);
// 计算召回率(Recall)
double recall = calculateRecall(TP, FN);
// 计算F1分数(F1 Score)
double f1Score = calculateF1Score(precision, recall);
// 计算准确率(Accuracy)
double accuracy = calculateAccuracy(TP, TN, FP, FN);
std::cout << "混淆矩阵:" << std::endl;
std::cout << "| " << TP << " | " << FN << " |" << std::endl;
std::cout << "| " << FP << " | " << TN << " |" << std::endl;
std::cout << "精确率(Precision)为: " << precision << std::endl;
std::cout << "召回率(Recall)为: " << recall << std::endl;
std::cout << "F1分数(F1 Score)为: " << f1Score << std::endl;
std::cout << "准确率(Accuracy)为: " << accuracy << std::endl;
return 0;
}
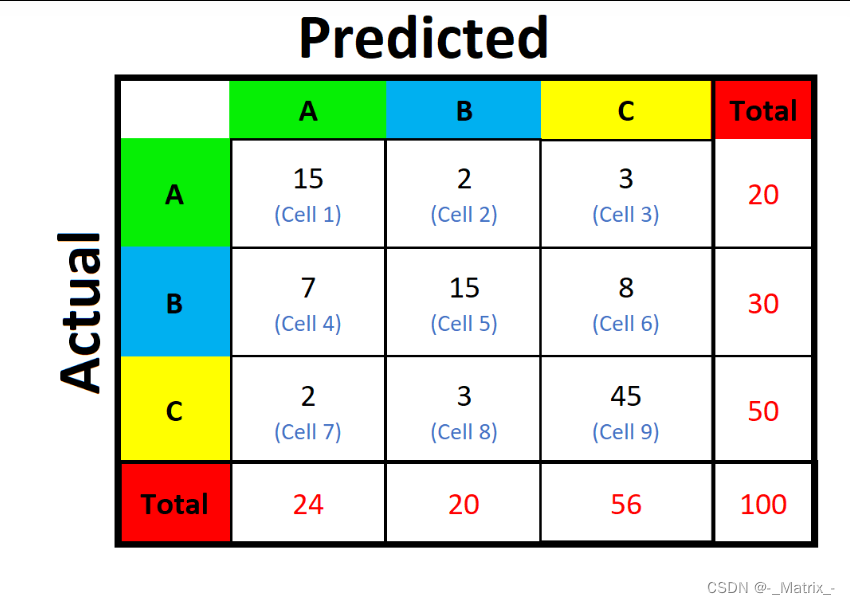
多分类问题
多分类宏平均法:
| | 预测为正类别 | 预测为负类别 |
|-------------|--------------|--------------|
| 真实为正类别 | TP | FN |
| 真实为负类别 | FP | TN |
| 预测为类别 1 | 预测为类别 2 | 预测为类别 3 | 预测为类别 4 |
----------------------------------------------------------------
真实为类别 1 | TP_1 | FP_1 | FP_1' | FP_1'' |
真实为类别 2 | FP_2 | TP_2 | FP_2' | FP_2'' |
真实为类别 3 | FP_3 | FP_3' | TP_3 | FP_3'' |
真实为类别 4 | FP_4 | FP_4' | FP_4'' | TP_4 |
- 宏平均精确率(Precision):
宏平均精确率是计算每个类别的精确率,并对它们取算术平均。它衡量了分类器在每个类别上的平均分类精确率。
Macro-Precision = 1 N ∑ i = 1 N TP i TP i + FP i \text{Macro-Precision} = \frac{1}{N} \sum_{i=1}^{N} \frac{\text{TP}_i}{\text{TP}_i + \text{FP}_i} Macro-Precision=N1∑i=1NTPi+FPiTPi
其中,N是类别的总数, TP i \text{TP}_i TPi是第i个类别的真正例数, FP i \text{FP}_i FPi是第i个类别的假正例数。
- 宏平均召回率(Macro-Recall):
宏平均召回率是计算每个类别的召回率,并对它们取算术平均。它衡量了分类器在每个类别上的平均分类召回率。
Macro-Recall = 1 N ∑ i = 1 N TP i TP i + FN i \text{Macro-Recall} = \frac{1}{N} \sum_{i=1}^{N} \frac{\text{TP}_i}{\text{TP}_i + \text{FN}_i} Macro-Recall=N1∑i=1NTPi+FNiTPi
其中, FN i \text{FN}_i FNi是第i个类别的假反例数。
- 宏平均F1分数(Macro-F1):
宏平均F1分数是计算每个类别的F1分数,并对它们取算术平均。F1分数是准确率和召回率的调和平均,用于综合衡量分类器在精确性和召回性能之间的平衡。
Macro-F1 = 1 N ∑ i = 1 N 2 × TP i 2 × TP i + FP i + FN i \text{Macro-F1} = \frac{1}{N} \sum_{i=1}^{N} \frac{2 \times \text{TP}_i}{2 \times \text{TP}_i + \text{FP}_i + \text{FN}_i} Macro-F1=N1∑i=1N2×TPi+FPi+FNi2×TPi
4.准确率(Accuracy):用于衡量模型在所有样本中正确预测的比例。
Accuracy
=
正确分类的样本数
总样本数
\text{Accuracy} = \frac{\text{正确分类的样本数}}{\text{总样本数}}
Accuracy=总样本数正确分类的样本数
//微平均 按照上述公式,所有结果 = tp / 总样本 ,也就是准确率
// 计算准确率(Accuracy)-多分类
double calculateAccuracy(const Eigen::MatrixXd& confusionMat)
{
size_t numClass = confusionMat.rows()-1;
size_t totalSamples = (size_t)confusionMat(numClass,numClass);
if (confusionMat(numClass,numClass) == 0)
{
return 0.0;
}
double accuracy = 0;
//累加所有正确类别个数
for (size_t i = 0; i < numClass; ++i)
{
accuracy += confusionMat(i,i);
}
return accuracy / totalSamples;
}
多分类代码
// 计算混淆矩阵 -多分类
Eigen::MatrixXd calculateConfusionMatrix(const std::vector<Eigen::VectorXd>& predictions, const std::vector<Eigen::VectorXd>& targets)
{
size_t row = predictions.at(0).size()+1;
Eigen::MatrixXd confusionMat = Eigen::MatrixXd::Zero(row,row);
// 获取最大值所在的索引位置
int pIndex,tIndex;
for (size_t i = 0; i < predictions.size(); ++i)
{
predictions.at(i).maxCoeff(&pIndex);
targets.at(i).maxCoeff(&tIndex);
confusionMat(tIndex,pIndex)++;
}
//统计矩阵中数据放到最后一列和最后一行
for (size_t i = 0; i < row-1; ++i)
{
//累加行数据放到最后一列
confusionMat(i,row-1) = confusionMat.row(i).sum();
//累加列数据放到最后一行
confusionMat(row-1,i) = confusionMat.col(i).sum();
}
//最后一个数据
confusionMat(row-1,row-1) = confusionMat.col(row-1).sum();
return confusionMat;
}
// 宏平均精确率(Precision)-多分类
double calculatePrecision(const Eigen::MatrixXd& confusionMat)
{
size_t numClass = confusionMat.rows()-1;
Eigen::VectorXd classV(numClass);
for (size_t i = 0; i < numClass; ++i)
{
if(confusionMat(numClass,i) == 0)
{
classV(i) = 0;
}
else
{
classV(i) = confusionMat(i,i) / confusionMat(numClass,i);
}
}
//所有类累加后的平均值
return classV.sum() / numClass;
}
// 宏平均召回率(Recall)-多分类
double calculateRecall(const Eigen::MatrixXd& confusionMat)
{
size_t numClass = confusionMat.rows()-1;
Eigen::VectorXd classV(numClass);
for (size_t i = 0; i < numClass; ++i)
{
if(confusionMat(i,numClass) == 0)
{
classV(i) = 0;
}
else
{
classV(i) = confusionMat(i,i) / confusionMat(i,numClass);
}
}
//所有类累加后的平均值
return classV.sum() / numClass;
}
// 宏平均F1分数(F1 Score)-多分类
double calculateF1Score(const Eigen::MatrixXd& confusionMat)
{
size_t numClass = confusionMat.rows()-1;
Eigen::VectorXd classV(numClass);
for (size_t i = 0; i < numClass; ++i)
{
if(confusionMat(i,numClass) == 0 || confusionMat(numClass,i) == 0)
{
classV(i) = 0;
}
else
{
classV(i) = 2 * confusionMat(i,i) / (confusionMat(numClass,i) + confusionMat(i,numClass));
}
}
//所有类累加后的平均值
return classV.sum() / numClass;
}
// 计算准确率(Accuracy)-多分类
double calculateAccuracy(const Eigen::MatrixXd& confusionMat)
{
size_t numClass = confusionMat.rows()-1;
size_t totalSamples = (size_t)confusionMat(numClass,numClass);
if (confusionMat(numClass,numClass) == 0)
{
return 0.0;
}
double accuracy = 0;
//累加所有正确类别个数
for (size_t i = 0; i < numClass; ++i)
{
accuracy += confusionMat(i,i);
}
return accuracy / totalSamples;
}
多分类微平均法:
多分类微平均法是一种用于多类别分类任务性能评估的指标汇总方法,它将所有类别的预测结果汇总成一个二分类问题,并计算总体性能指标。与宏平均法不同,多分类微平均法将每个样本都视为同等重要,不考虑类别本身,因此适用于类别样本数量相对均衡的情况。
在多分类微平均法中,我们通常会关注以下性能指标:
-
总体精确率(Micro-Precision):
Micro-Precision = TP total TP total + FP total \text{Micro-Precision} = \frac{\text{TP}_{\text{total}}}{\text{TP}_{\text{total}} + \text{FP}_{\text{total}}} Micro-Precision=TPtotal+FPtotalTPtotal -
总体召回率(Micro-Recall):
Micro-Recall = TP total TP total + FN total \text{Micro-Recall} = \frac{\text{TP}_{\text{total}}}{\text{TP}_{\text{total}} + \text{FN}_{\text{total}}} Micro-Recall=TPtotal+FNtotalTPtotal -
总体F1分数(Micro-F1):
Micro-F1 = 2 × TP total 2 × TP total + FP total + FN total \text{Micro-F1} = \frac{2 \times \text{TP}_{\text{total}}}{2 \times \text{TP}_{\text{total}} + \text{FP}_{\text{total}} + \text{FN}_{\text{total}}} Micro-F1=2×TPtotal+FPtotal+FNtotal2×TPtotal
4.准确率(Accuracy):用于衡量模型在所有样本中正确预测的比例。
Accuracy
=
正确分类的样本数
总样本数
\text{Accuracy} = \frac{\text{正确分类的样本数}}{\text{总样本数}}
Accuracy=总样本数正确分类的样本数
准确率(Accuracy):
准确率是最常见的分类度量之一,它简单地表示模型预测正确的样本数量与总样本数量之间的比例。
准确率的取值范围在 0 到 1 之间,数值越接近 1 表示模型预测越准确,数值越接近 0 表示模型预测越不准确。
数学上,准确率的计算方法如下:
假设有 n 个样本,模型的预测结果分别为 y ^ 1 , y ^ 2 , . . . , y ^ n ŷ₁, ŷ₂, ..., ŷₙ y^1,y^2,...,y^n,对应的真实标签为 y 1 , y 2 , . . . , y n y₁, y₂, ..., yₙ y1,y2,...,yn。
准确率 = ( 正确分类的样本数量 ) / ( 总样本数量 ) = ( 正确分类的样本数量 ) / n = Σ ( y ^ i = = y i ) / n 准确率 = (正确分类的样本数量) / (总样本数量) = (正确分类的样本数量) / n = Σ (ŷᵢ == yᵢ) / n 准确率=(正确分类的样本数量)/(总样本数量)=(正确分类的样本数量)/n=Σ(y^i==yi)/n
其中, ( y ^ i = = y i ) (ŷᵢ == yᵢ) (y^i==yi) 表示第 i 个样本是否被正确分类,如果预测值 ŷᵢ 等于真实标签 yᵢ,则表示第 i 个样本被正确分类。
需要注意的是,准确率可能并不适用于所有情况。在某些不平衡的分类问题中,如果某个类别的样本数量较少,模型可能会倾向于预测样本属于数量较多的类别,从而导致准确率的误导。在这种情况下,可能需要结合其他评估指标来综合评估模型的性能。
下面是用C++编写的一个简单示例代码,用于计算分类模型的准确率(Accuracy):
#include <iostream>
#include <vector>
// 计算准确率(Accuracy)
double calculateAccuracy(const std::vector<int>& predictions, const std::vector<int>& targets) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return -1.0;
}
int correctCount = 0;
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == targets[i]) {
correctCount++;
}
}
double accuracy = static_cast<double>(correctCount) / predictions.size();
return accuracy;
}
精确率(Precision):
精确率是指在所有被模型预测为正例的样本中,真正例的比例。它用于衡量模型预测为正例的准确性。
精确率的取值范围在 0 到 1 之间,数值越接近 1 表示模型在预测正类别时更准确,数值越接近 0 表示模型在预测正类别时不太准确。
数学上,精确率的计算方法如下:
假设有 n 个样本,模型的预测结果分别为 y ^ 1 , y ^ 2 , . . . , y ^ n ŷ₁, ŷ₂, ..., ŷₙ y^1,y^2,...,y^n,对应的真实标签为 y 1 , y 2 , . . . , y n y₁, y₂, ..., yₙ y1,y2,...,yn。
精确率 = ( 真正为正类别的样本数量 ) / ( 所有被预测为正类别的样本数量 ) = ( 真正为正类别的样本数量 ) / Σ ( y ^ i = = 1 ) 精确率 = (真正为正类别的样本数量) / (所有被预测为正类别的样本数量) = (真正为正类别的样本数量) / Σ (ŷᵢ == 1) 精确率=(真正为正类别的样本数量)/(所有被预测为正类别的样本数量)=(真正为正类别的样本数量)/Σ(y^i==1)
其中, ( y ^ i = = 1 ) (ŷᵢ == 1) (y^i==1) 表示第 i 个样本被模型预测为正类别。
精确率通常与召回率(Recall)一起使用,可以帮助我们全面评估分类模型的性能。高精确率意味着模型预测正类别时较少出现误判,而高召回率意味着模型对正类别的覆盖率较高。在实际应用中,需要根据具体任务和需求来选择精确率和召回率的权衡。
下面是用C++编写的一个简单示例代码,用于计算分类模型的精确率(Precision):
#include <iostream>
#include <vector>
// 计算精确率(Precision)
double calculatePrecision(const std::vector<int>& predictions, const std::vector<int>& targets) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return -1.0;
}
int truePositive = 0; // 真正为正类别的样本数量
int predictedPositive = 0; // 所有被预测为正类别的样本数量
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == 1) {
predictedPositive++;
if (targets[i] == 1) {
truePositive++;
}
}
}
double precision = static_cast<double>(truePositive) / predictedPositive;
return precision;
}
召回率(Recall):
召回率是指在所有真正正例中,模型正确预测为正例的比例。它用于衡量模型对正例的覆盖程度。
召回率的取值范围在 0 到 1 之间,数值越接近 1 表示模型对真实正类别的覆盖率较高,数值越接近 0 表示模型对真实正类别的覆盖率较低。
数学上,召回率的计算方法如下:
假设有 n 个样本,模型的预测结果分别为 y ^ 1 , y ^ 2 , . . . , y ^ n ŷ₁, ŷ₂, ..., ŷₙ y^1,y^2,...,y^n,对应的真实标签为 y 1 , y 2 , . . . , y n y₁, y₂, ..., yₙ y1,y2,...,yn。
召回率 = ( 真正为正类别的样本数量 ) / ( 所有真实为正类别的样本数量 ) = ( 真正为正类别的样本数量 ) / Σ ( y i = = 1 ) 召回率 = (真正为正类别的样本数量) / (所有真实为正类别的样本数量) = (真正为正类别的样本数量) / Σ (yᵢ == 1) 召回率=(真正为正类别的样本数量)/(所有真实为正类别的样本数量)=(真正为正类别的样本数量)/Σ(yi==1)
其中, ( y i = = 1 ) (yᵢ == 1) (yi==1) 表示第 i 个样本是真实为正类别的。
精确率(Precision)和召回率(Recall)通常一起使用,可以帮助我们全面评估分类模型的性能。高精确率意味着模型预测正类别时较少出现误判,而高召回率意味着模型对正类别的覆盖率较高。在实际应用中,需要根据具体任务和需求来选择精确率和召回率的权衡。
下面是用C++编写的一个简单示例代码,用于计算分类模型的召回率(Recall):
#include <iostream>
#include <vector>
// 计算召回率(Recall)
double calculateRecall(const std::vector<int>& predictions, const std::vector<int>& targets) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return -1.0;
}
int truePositive = 0; // 真正为正类别的样本数量
int actualPositive = 0; // 所有真实为正类别的样本数量
for (size_t i = 0; i < predictions.size(); ++i) {
if (targets[i] == 1) {
actualPositive++;
if (predictions[i] == 1) {
truePositive++;
}
}
}
double recall = static_cast<double>(truePositive) / actualPositive;
return recall;
}
F1 分数(F1 Score):
F1 分数是精确率和召回率的调和平均值,它综合了两者的性能。F1 分数更加平衡精确率和召回率的影响。
F1分数的取值范围在0到1之间,数值越接近1表示模型在预测时具有较高的准确性和召回率,数值越接近0表示模型的预测准确性和召回率较低。
F1分数的计算方法如下:
假设有 n 个样本,模型的预测结果分别为 y ^ 1 , y ^ 2 , . . . , y ^ n ŷ₁, ŷ₂, ..., ŷₙ y^1,y^2,...,y^n,对应的真实标签为 y 1 , y 2 , . . . , y n y₁, y₂, ..., yₙ y1,y2,...,yn。
精确率(Precision)的计算方法为:
P
r
e
c
i
s
i
o
n
=
(
真正为正类别的样本数量
)
/
(
所有被预测为正类别的样本数量
)
=
(
真正为正类别的样本数量
)
/
Σ
(
y
^
i
=
=
1
)
Precision = (真正为正类别的样本数量) / (所有被预测为正类别的样本数量) = (真正为正类别的样本数量) / Σ (ŷᵢ == 1)
Precision=(真正为正类别的样本数量)/(所有被预测为正类别的样本数量)=(真正为正类别的样本数量)/Σ(y^i==1)
召回率(Recall)的计算方法为:
R
e
c
a
l
l
=
(
真正为正类别的样本数量
)
/
(
所有真实为正类别的样本数量
)
=
(
真正为正类别的样本数量
)
/
Σ
(
y
i
=
=
1
)
Recall = (真正为正类别的样本数量) / (所有真实为正类别的样本数量) = (真正为正类别的样本数量) / Σ (yᵢ == 1)
Recall=(真正为正类别的样本数量)/(所有真实为正类别的样本数量)=(真正为正类别的样本数量)/Σ(yi==1)
F1分数的计算方法为:
F
1
S
c
o
r
e
=
2
∗
(
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
)
/
(
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
)
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
F1Score=2∗(Precision∗Recall)/(Precision+Recall)
F1分数是综合了精确率和召回率的评估指标,适用于处理类别不平衡的情况,因为它考虑了正类别和负类别的权衡。在某些情况下,我们更关注模型在正类别的预测准确性和召回率,此时F1分数是一个很有用的指标。
下面是用C++编写的一个简单示例代码,用于计算分类模型的F1分数(F1 Score):
#include <iostream>
#include <vector>
// 计算精确率(Precision)
double calculatePrecision(const std::vector<int>& predictions, const std::vector<int>& targets) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return -1.0;
}
int truePositive = 0; // 真正为正类别的样本数量
int predictedPositive = 0; // 所有被预测为正类别的样本数量
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == 1) {
predictedPositive++;
if (targets[i] == 1) {
truePositive++;
}
}
}
double precision = static_cast<double>(truePositive) / predictedPositive;
return precision;
}
// 计算召回率(Recall)
double calculateRecall(const std::vector<int>& predictions, const std::vector<int>& targets) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return -1.0;
}
int truePositive = 0; // 真正为正类别的样本数量
int actualPositive = 0; // 所有真实为正类别的样本数量
for (size_t i = 0; i < predictions.size(); ++i) {
if (targets[i] == 1) {
actualPositive++;
if (predictions[i] == 1) {
truePositive++;
}
}
}
double recall = static_cast<double>(truePositive) / actualPositive;
return recall;
}
// 计算F1分数(F1 Score)
double calculateF1Score(double precision, double recall) {
if (precision == 0.0 || recall == 0.0) {
return 0.0;
}
double f1Score = 2 * (precision * recall) / (precision + recall);
return f1Score;
}
F-Score
F-Score(也称为F-值)是一种用于评估分类模型准确性的度量。特别地,它是精确度(Precision)和召回率(Recall)的加权平均值。在深度学习和其他分类任务中,F-Score是一种常用的评估指标。
F-Score的一般公式如下:
F β = ( 1 + β 2 ) ⋅ Precision ⋅ Recall β 2 ⋅ Precision + Recall F_{\beta} = \frac{(1 + \beta^2) \cdot \text{Precision} \cdot \text{Recall}}{\beta^2 \cdot \text{Precision} + \text{Recall}} Fβ=β2⋅Precision+Recall(1+β2)⋅Precision⋅Recall
其中:
- Precision(精确度)是模型预测为正的样本中实际为正的样本的比例。
- Recall(召回率)是实际为正的样本中模型预测为正的样本的比例。
- β \beta β是一个权重因子,用于在精确度和召回率之间取平衡。特别地, β \beta β的值决定了你是更重视召回率还是精确度。
F1-Score
当 β = 1 \beta = 1 β=1时,精确度和召回率被赋予相同的权重,这就是F1-Score。F1-Score是最常用的F-Score,计算公式为:
F 1 = 2 ⋅ Precision ⋅ Recall Precision + Recall F1 = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} F1=Precision+Recall2⋅Precision⋅Recall
F2-Score
F2-Score给予召回率更高的权重,是一种特殊情况,其中 β = 2 \beta = 2 β=2。F2-Score适用于召回率比精确度更重要的场景。计算公式为:
F 2 = 5 ⋅ Precision ⋅ Recall 4 ⋅ Precision + Recall F2 = \frac{5 \cdot \text{Precision} \cdot \text{Recall}}{4 \cdot \text{Precision} + \text{Recall}} F2=4⋅Precision+Recall5⋅Precision⋅Recall
其他F-Scores
你可以通过调整 β \beta β的值来得到不同的F-Scores。具体来说,增加 β \beta β的值会增加召回率的权重,而减小 β \beta β的值会增加精确度的权重。
为何使用F-Score?
F-Score是一个有用的度量标准,特别是当数据集的类别分布不平衡时。在这些情况下,简单的准确度可能不是一个好的度量标准,因为它可能会被主导类别所掩盖。通过结合精确度和召回率,F-Score提供了一种平衡的方法来评估模型在各个类别上的性能。
ROC 曲线(Receiver Operating Characteristic curve):
二分类ROC
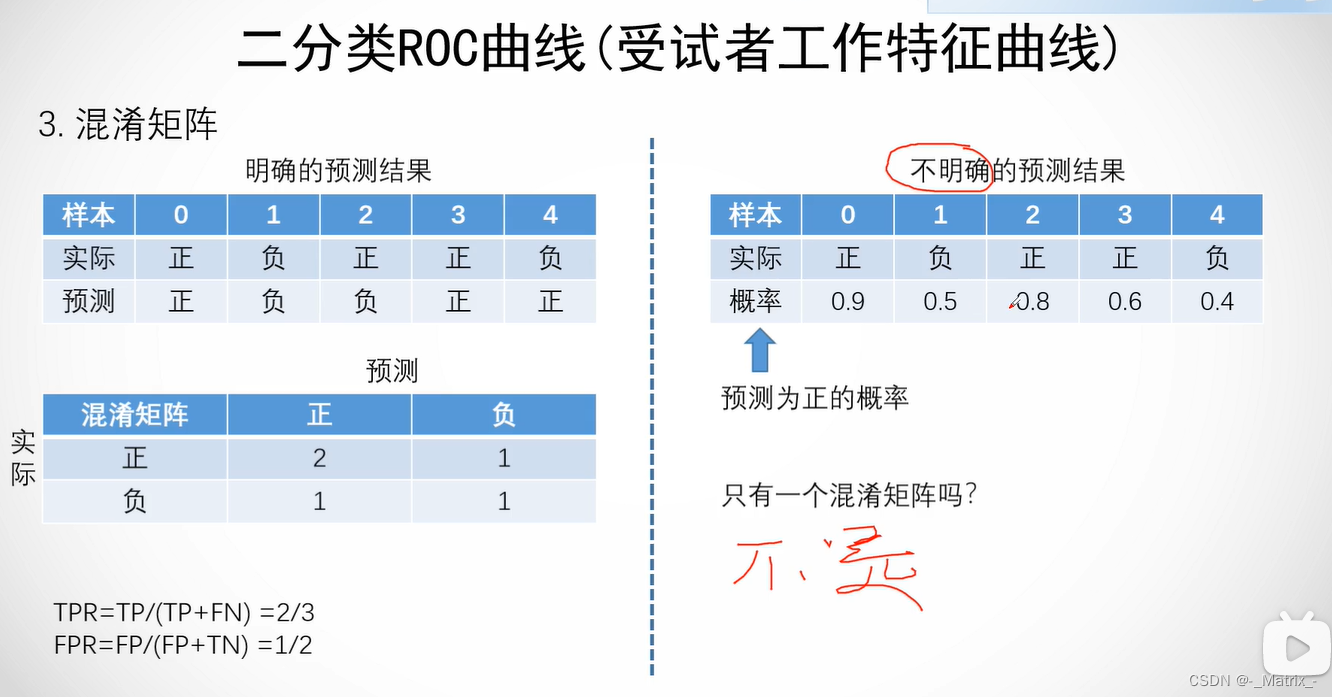
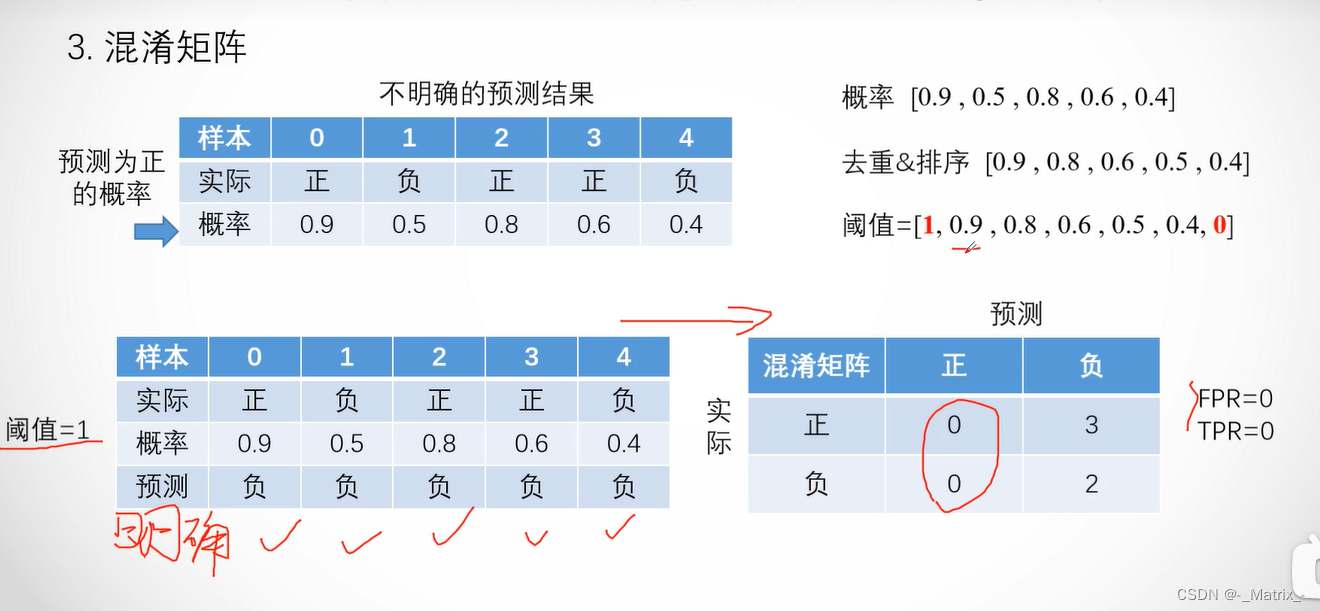
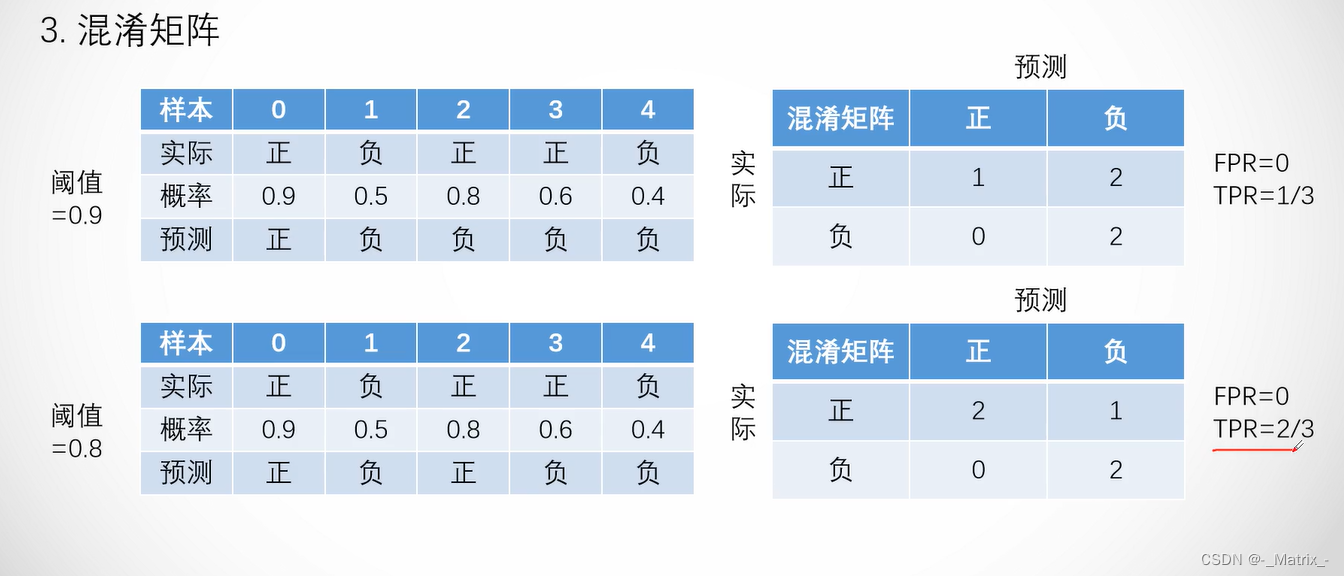
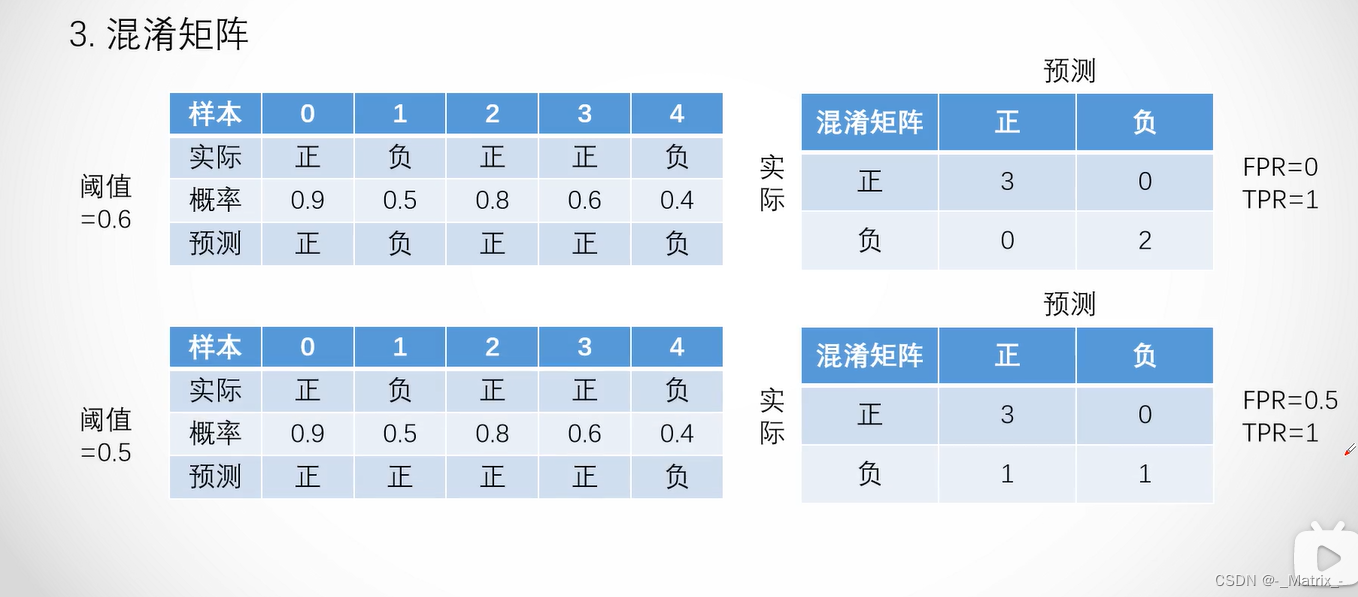
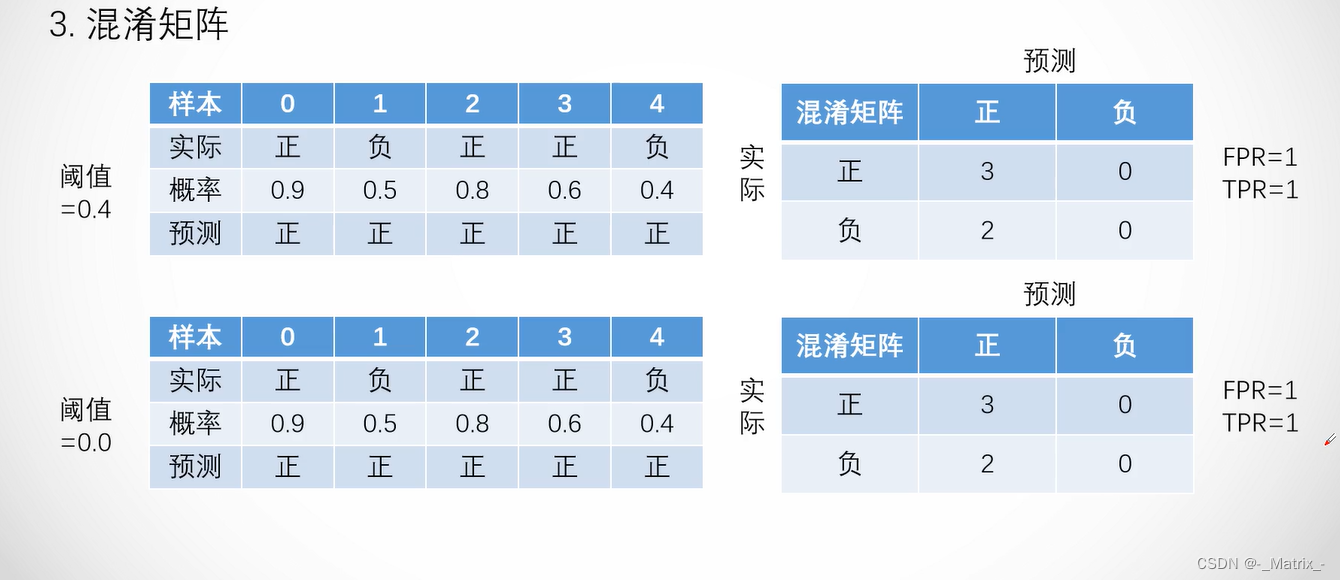
在ROC曲线中,横轴表示FPR,纵轴表示TPR。TPR是召回率(Recall)的另一个名称,它表示在所有真实为正类别的样本中,模型正确预测为正类别的样本所占的比例。FPR表示在所有真实为负类别的样本中,模型错误地预测为正类别的样本所占的比例。
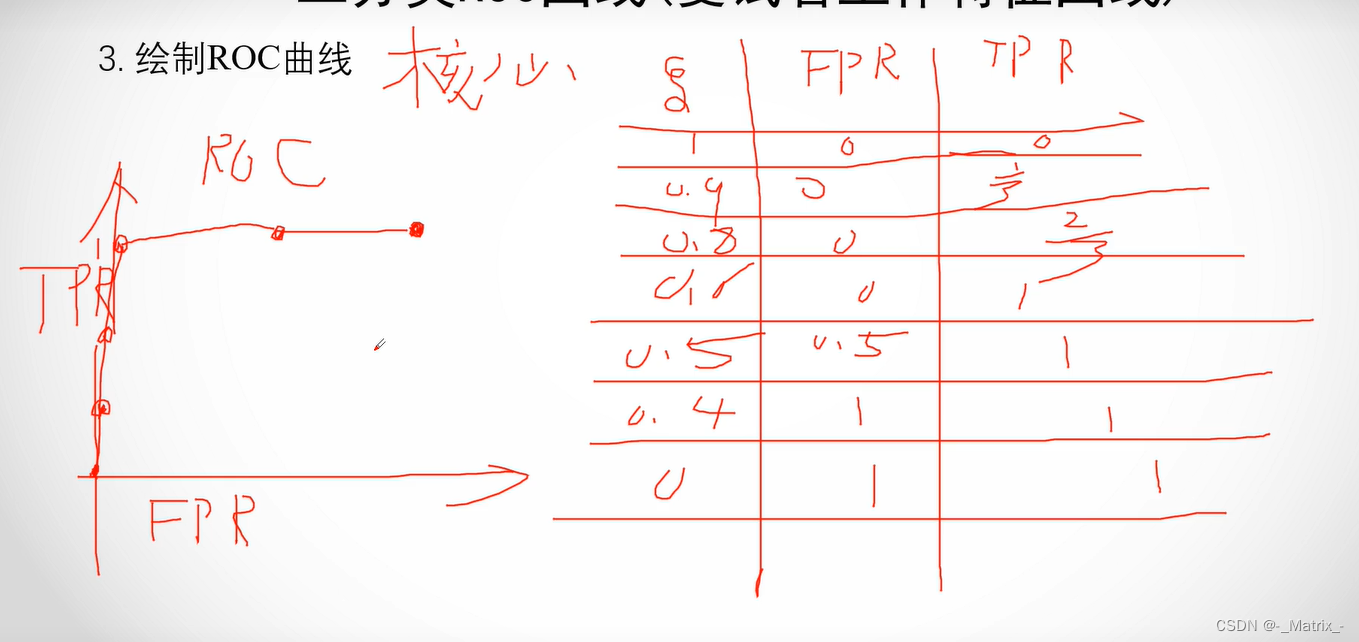
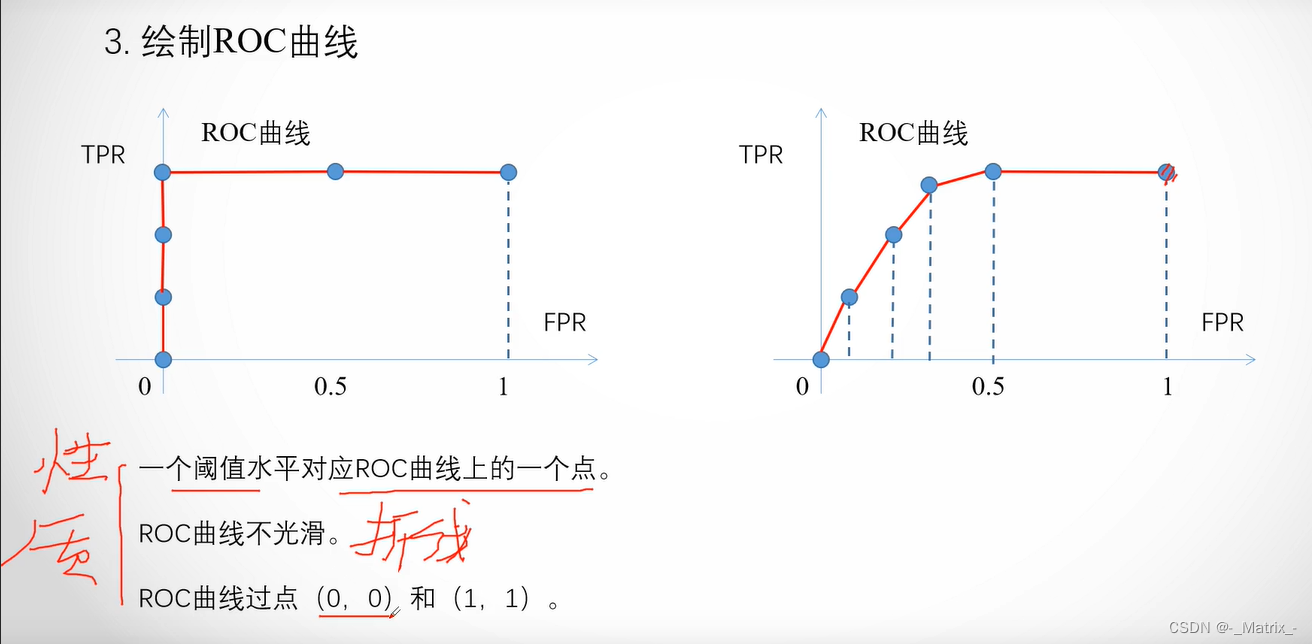
ROC曲线的绘制过程如下:
- 首先,根据模型预测的概率值对样本进行排序,从高到低排列。
- 选择一个阈值,将概率大于等于该阈值的样本预测为正类别,将概率小于该阈值的样本预测为负类别。
- 计算在当前阈值下的TPR和FPR。
- 不断地调整阈值,重复步骤3,直到所有样本都被预测为正类别或负类别。
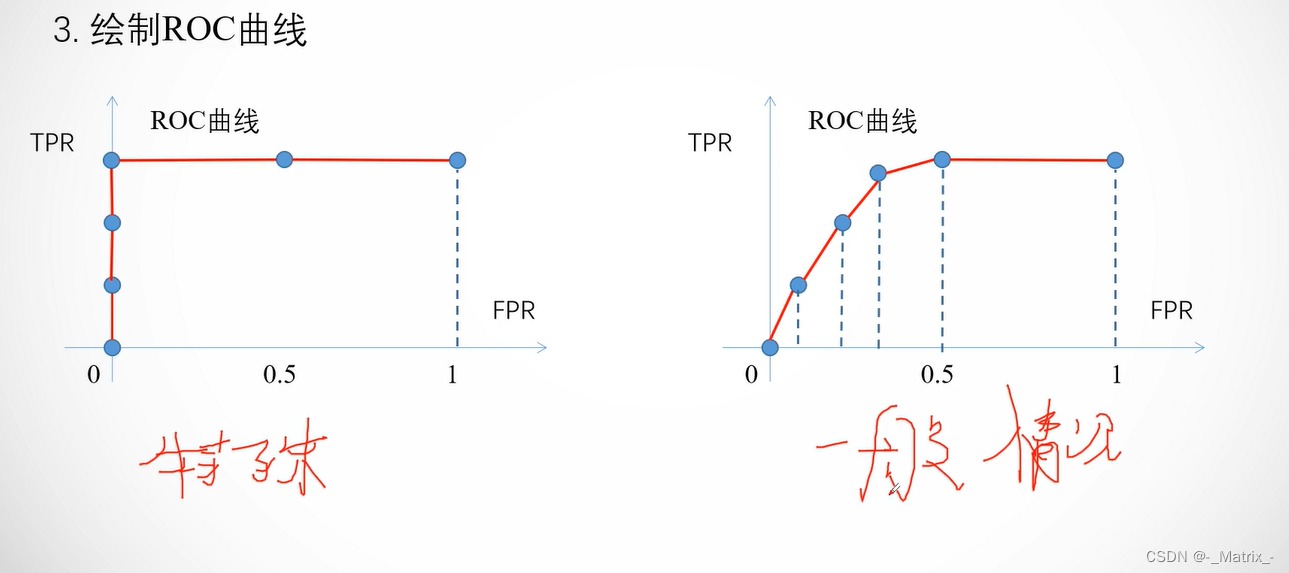
- 将所有不同阈值下的TPR和FPR绘制成ROC曲线。
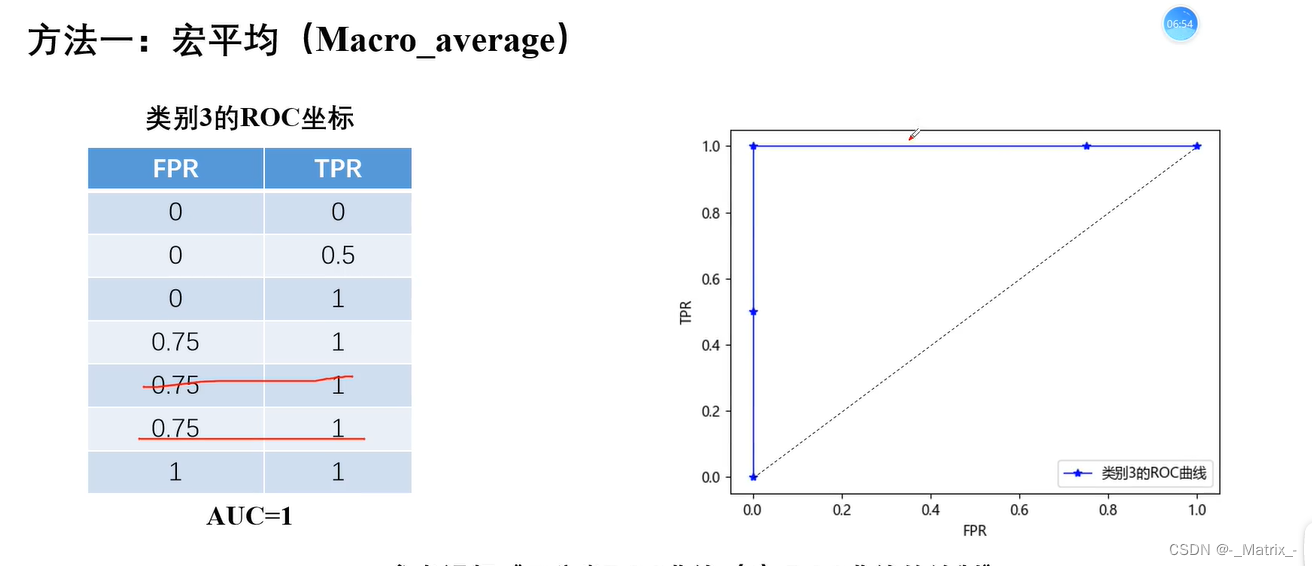
在ROC曲线中,理想的分类器的曲线将沿着左上角到右下角的对角线,这表示在所有阈值下,分类器的TPR和FPR均为1。而对角线以下的曲线则表示分类器的性能较差。
代码实现
// 计算TPR(True Positive Rate,召回率)
inline float calculateTPR(const int& TP, const int& FN)
{
float f = (float)TP / (TP + FN);
//保留小数点后5位
int p = 100000;
return static_cast<float>(static_cast<int>(f * p + 0.5) / (float)p);
}
// 计算FPR(False Positive Rate)
inline float calculateFPR(const int& FP, const int& TN)
{
float f = (float)FP / (FP + TN);
//保留小数点后5位
int p = 100000;
return static_cast<float>(static_cast<int>(f * p + 0.5) / (float)p);
}
//从小到大排序 并去重
std::vector<float> sortAndRemoveDuplicates(const std::vector<float>& input)
{
std::vector<float> sortedVector = input;
// 先排序
std::sort(sortedVector.begin(), sortedVector.end());
// 然后使用 std::unique 去重
sortedVector.erase(std::unique(sortedVector.begin(), sortedVector.end()), sortedVector.end());
return sortedVector;
}
// 绘制ROC曲线 - 二分类 返回一组坐标
virtual std::vector<std::pair<float,float> > calculateBinaryROC(const Eigen::VectorXf& predictions, const Eigen::VectorXf& targets)
{
//数据映射到vector
std::vector<float> preProb(predictions.data(), predictions.data() + predictions.size());
preProb.push_back(0.0);
preProb.push_back(1.0);
preProb = sortAndRemoveDuplicates(preProb);
std::vector<std::pair<float,float> > points;
// 遍历样本,计算TPR和FPR
for (int i = 0; i < preProb.size(); ++i)
{
int TP = 0;
int FP = 0;
int FN = 0;
int TN = 0;
for (int j = 0; j < predictions.rows(); ++j)
{
//划分概率样本 为正
if (predictions(j) - preProb.at(i) >= 0)
{
if ((int)targets(j) == 1)
{
TP++;
}
else
{
FP++;
}
}
else //为负
{
if ((int)targets(j) == 1)
{
FN++;
}
else
{
TN++;
}
}
}
std::pair<float,float> temp;
//TPR和FPR
temp.first = (calculateFPR(FP, TN));//FPR
temp.second = (calculateTPR(TP, FN));//TPR
points.push_back(temp);
}
points.push_back({0.0, 0.0});
points.push_back({1.0, 1.0});
//排序 -- 根据键值
std::sort(points.begin(), points.end(), [=](const auto& lhs, const auto& rhs)
{
// 首先比较键,如果键相等则比较值
if (lhs.first == rhs.first)
{
return lhs.second - rhs.second < 0.0;
}
return lhs.first - rhs.first < 0.0; // 从小到大 排序
});
// 去除相邻的重复元素
points.erase(std::unique(points.begin(), points.end(), [](const auto& a, const auto& b) {
return a.first == b.first && a.second == b.second;
}), points.end());
// //检测排序 是否 从小到大
// for(int i=1;i<points.size();++i)
// {
// CHECK(points.at(i-1).first <= points.at(i).first && points.at(i-1).second <= points.at(i).second);
// }
return points;
}
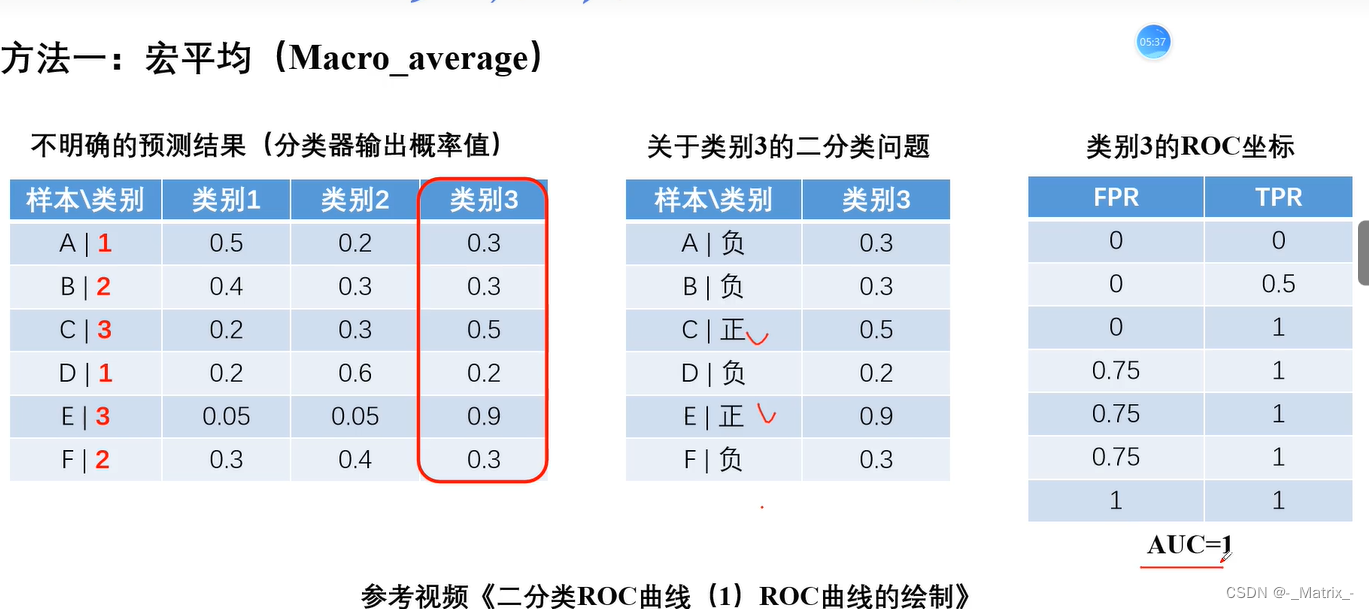
多分类ROC
宏平均多个分类->转多个二分类求平均值(多对多)
微平均多个分类->转一个二分类(多对一)
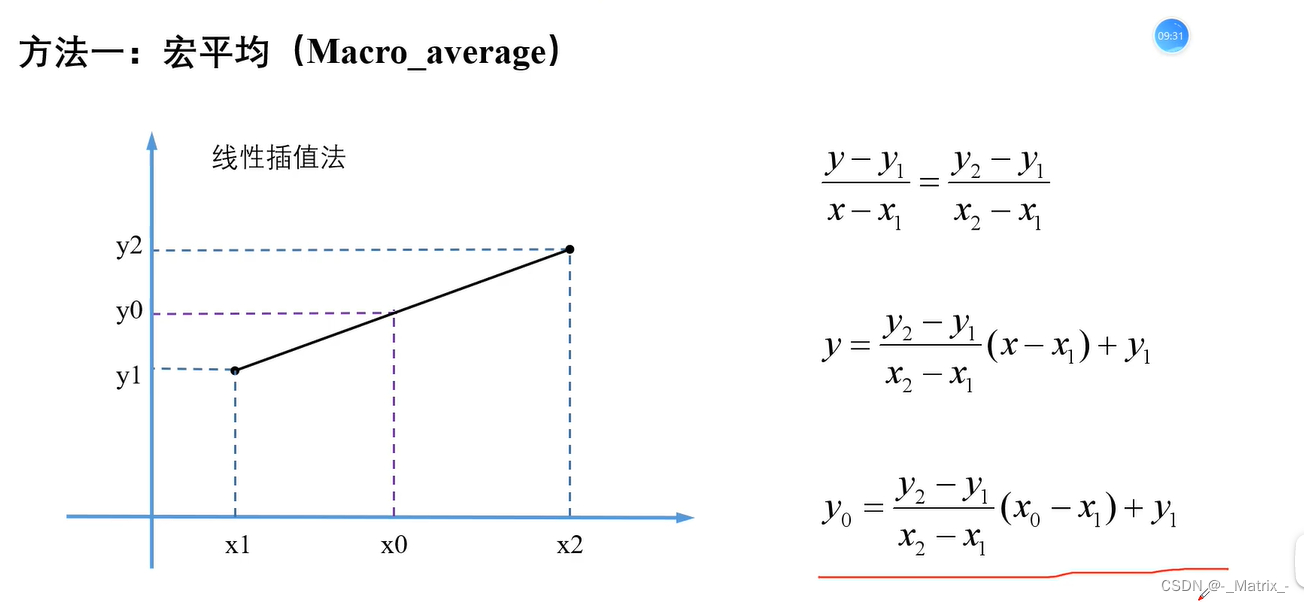
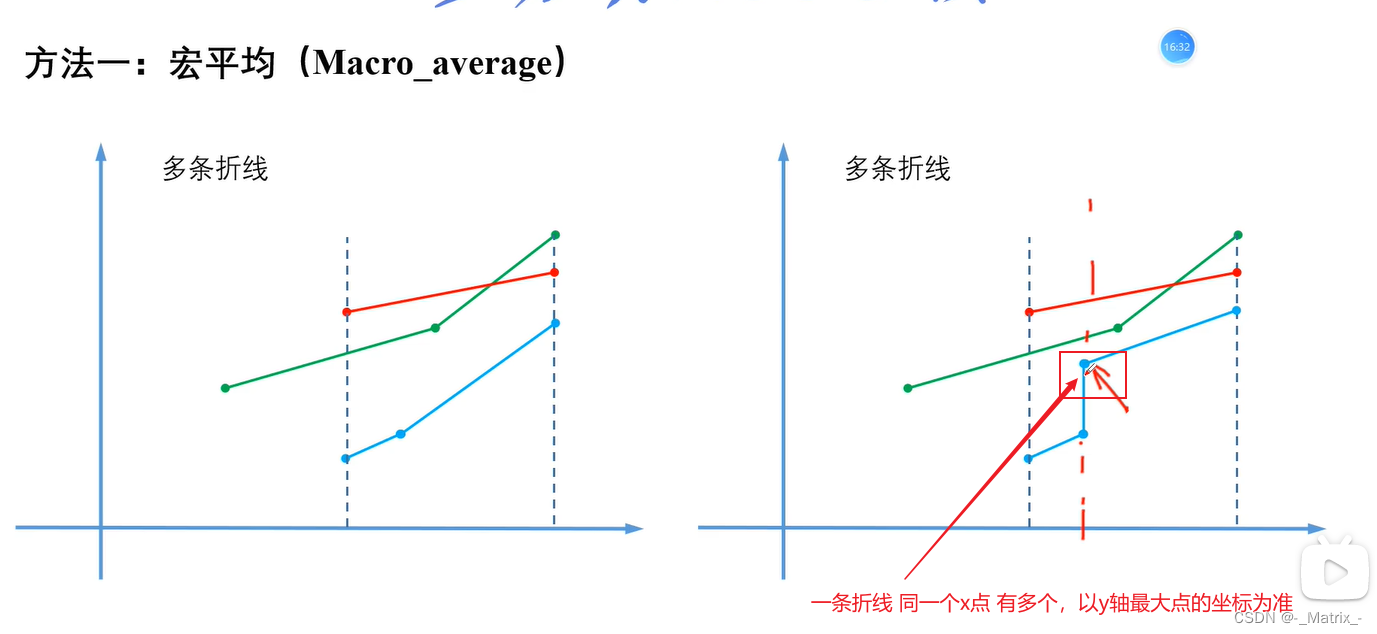
宏平均
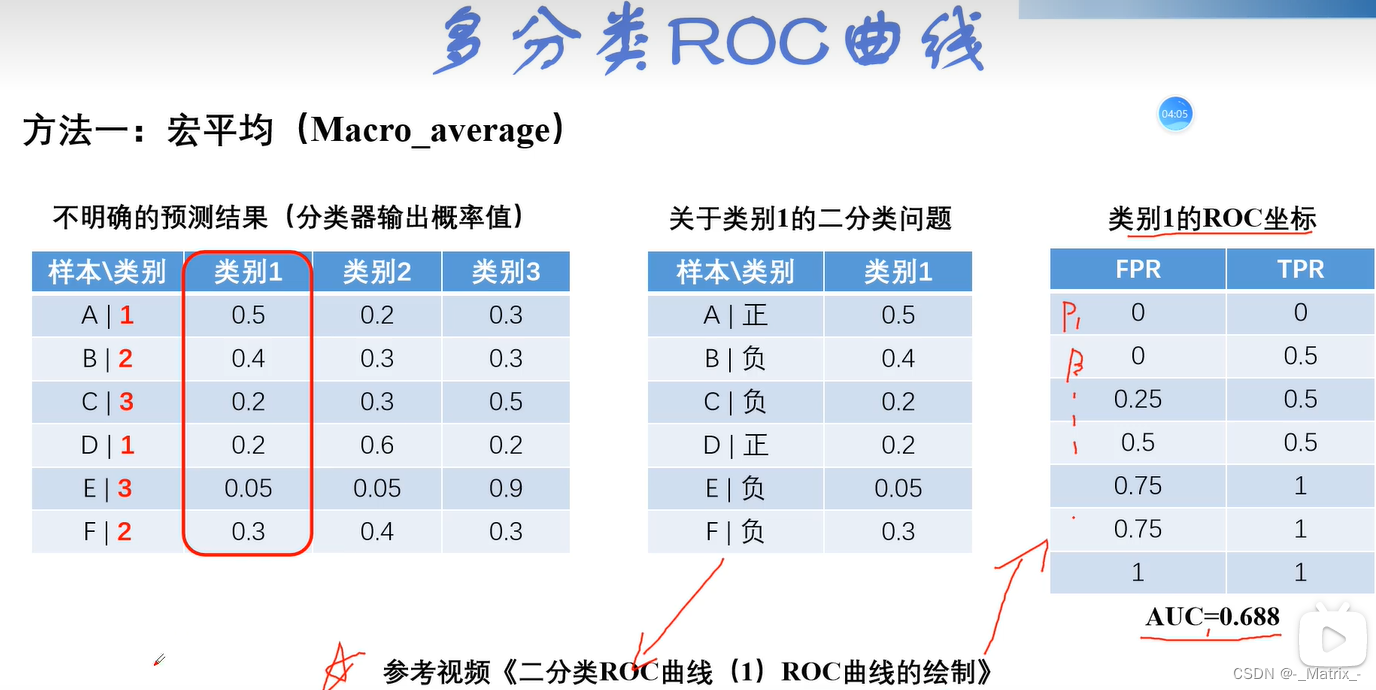
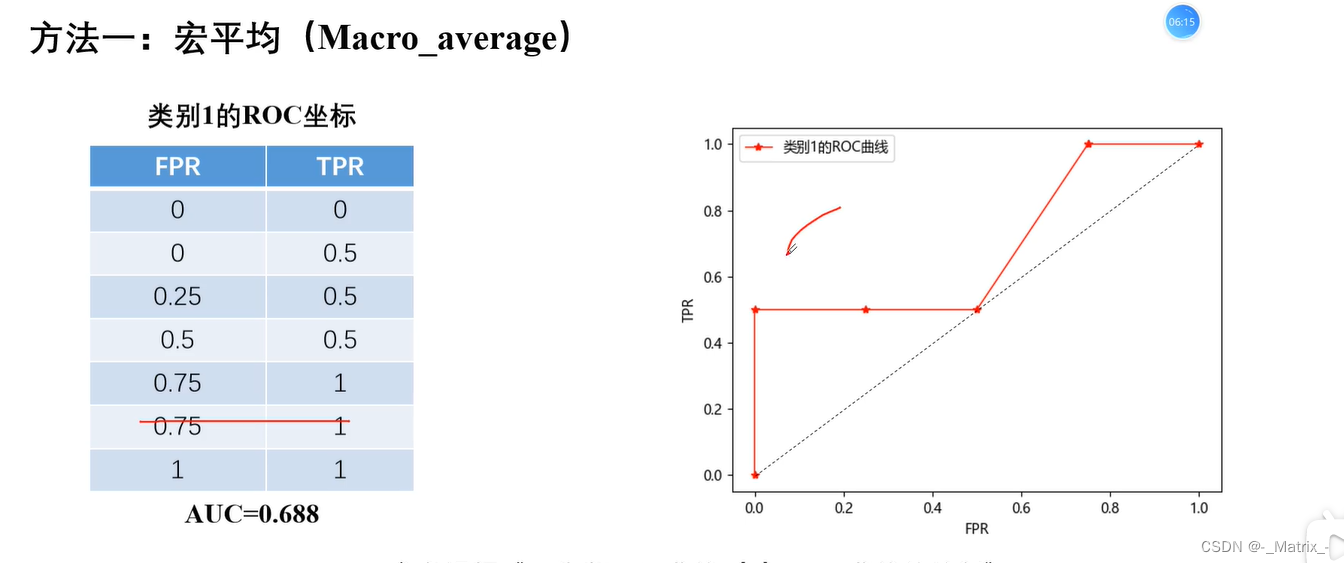
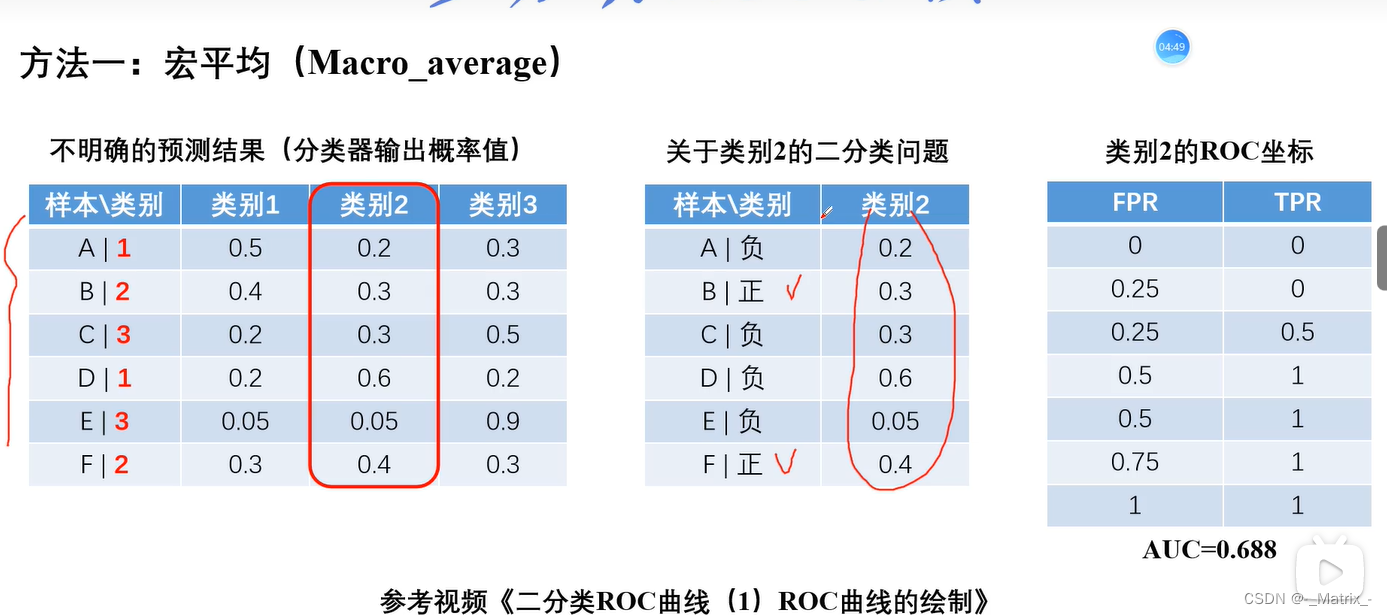
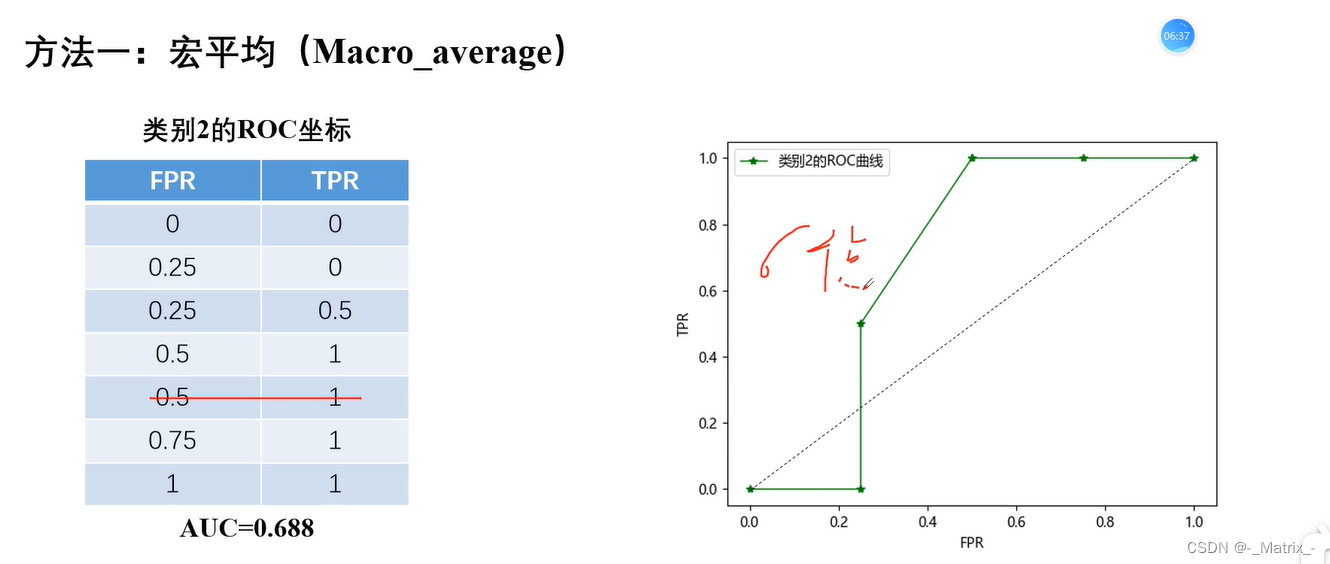
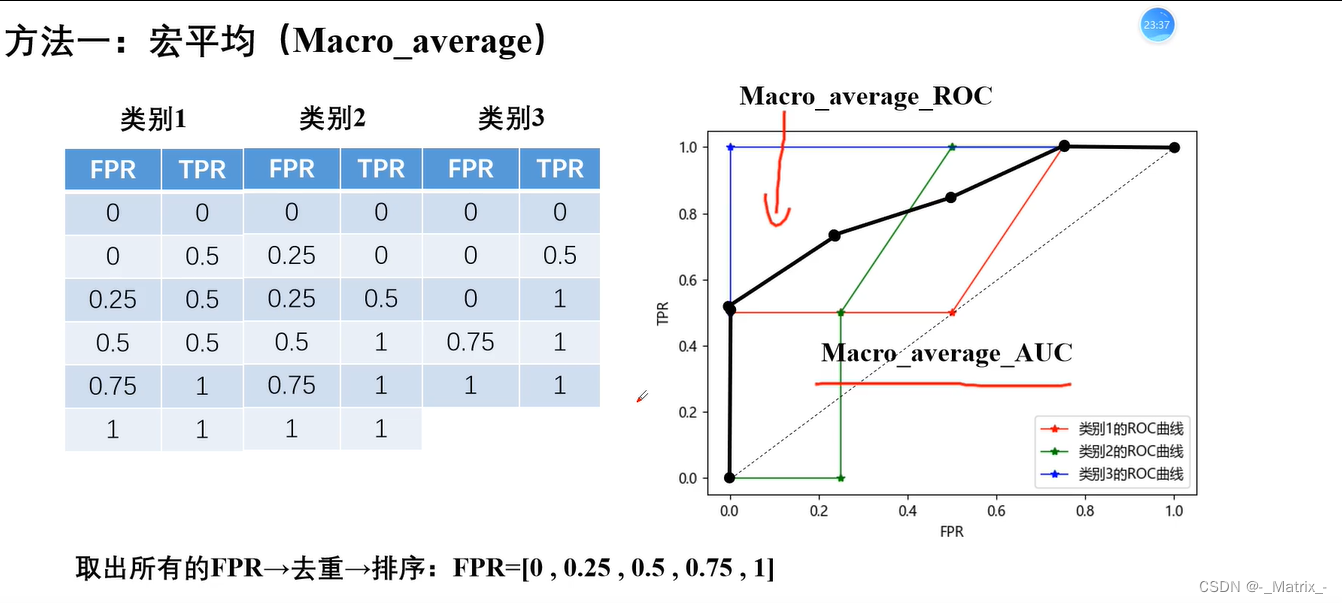
代码实现
// 宏平均绘制ROC曲线 - 多分类 返回一组坐标
virtual std::vector<std::pair<float,float> > calculateMacroROC(const Eigen::MatrixXf& predictions, const Eigen::MatrixXf& targets)
{
std::vector<std::vector<std::pair<float,float>>> MacroROC;
std::vector<float> allFPR;
//拆分成二分类绘制ROC曲线
for (int i = 0; i < predictions.cols(); ++i)
{
std::vector<std::pair<float,float>> binaryROC = calculateBinaryROC(predictions.col(i), targets.col(i));
MacroROC.push_back(binaryROC);
//找出所有FPR
for (int j = 0; j < binaryROC.size(); ++j)
{
allFPR.push_back(binaryROC.at(j).first);
}
}
allFPR = sortAndRemoveDuplicates(allFPR);
//求宏平均ROC
std::vector<std::pair<float,float>> points;
Eigen::VectorXi indexPos = Eigen::VectorXi::Ones(MacroROC.size());
for (int i = 0; i < allFPR.size(); ++i)
{
float argY = 0.0;
for (int j = 0; j < MacroROC.size(); ++j)
{
std::vector<std::pair<float,float>> binaryROC = MacroROC.at(j);
for (int k = indexPos(j); k < binaryROC.size(); ++k)
{
indexPos(j) = k;
//求线性插值 (y2-y1) / (x2 - x1) * (x-x1) + y1 = y x=allFPR.at(i)
if (binaryROC.at(k).first > allFPR.at(i))
{
//找到最后一个的等于值,取x相同的y最大值
if(binaryROC.at(k-1).first == allFPR.at(i))
{
argY += binaryROC.at(k-1).second;
}
else
{
argY += (binaryROC.at(k).second - binaryROC.at(k - 1).second) / (binaryROC.at(k).first - binaryROC.at(k - 1).first) *
(allFPR.at(i) - binaryROC.at(k - 1).first) + binaryROC.at(k - 1).second;
}
break;
}
}
}
std::pair<float,float> temp;
temp.first = (allFPR.at(i));
temp.second = (argY / MacroROC.size());
points.push_back(temp);
}
return points;
}
微平均
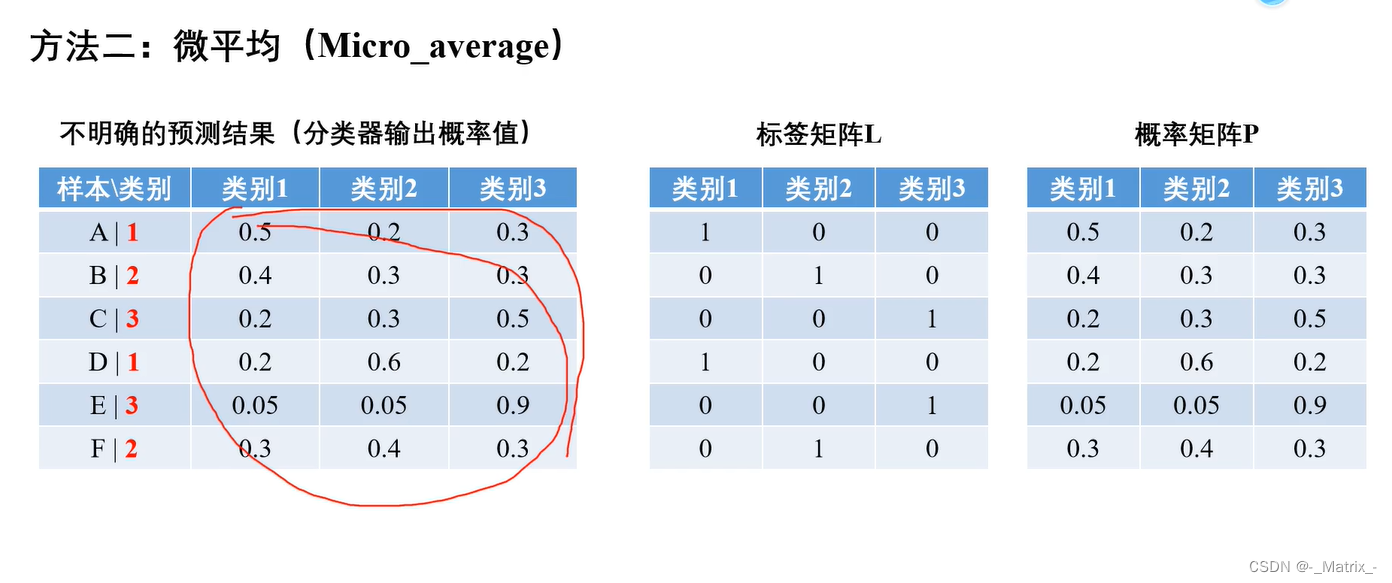


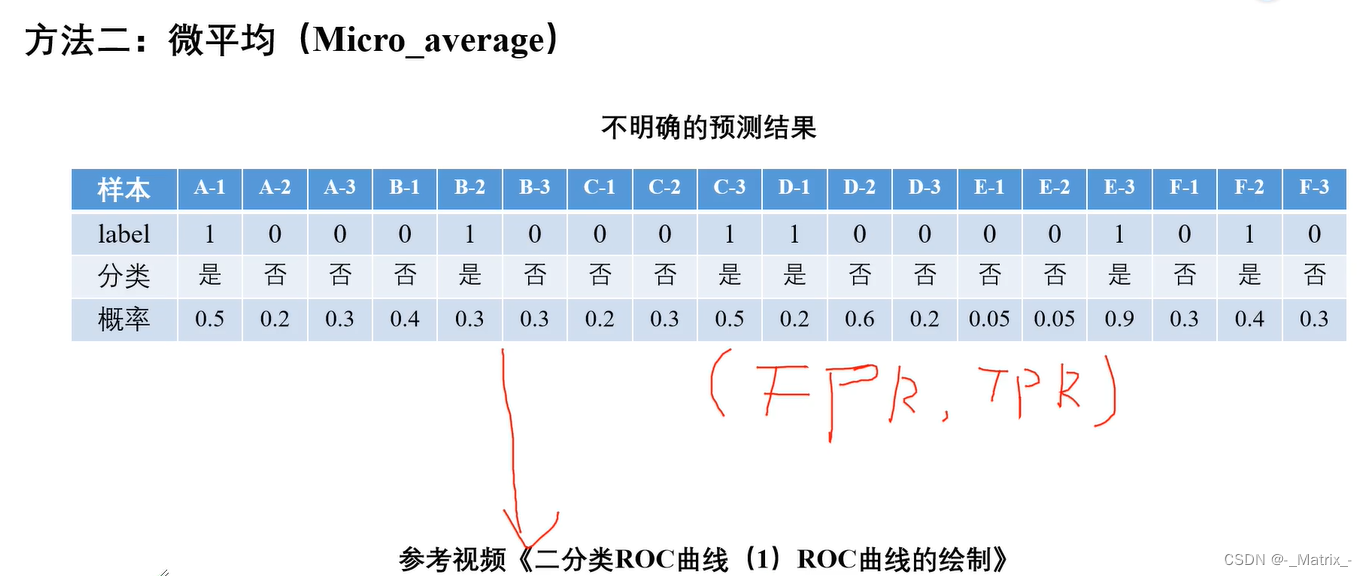
代码实现
// 微平均绘制ROC曲线 - 多分类 返回一组坐标
std::vector<std::pair<float,float>> calculateMicroROC(const Eigen::MatrixXf& predictions,
const Eigen::MatrixXf& targets)
{
//改变维度 - 以行为准则,改变为一维的向量
Eigen::VectorXf pred = predictions.reshaped<Eigen::RowMajor>().transpose();
Eigen::VectorXf targ = targets.reshaped<Eigen::RowMajor>().transpose();
return calculateBinaryROC(pred, targ);
}
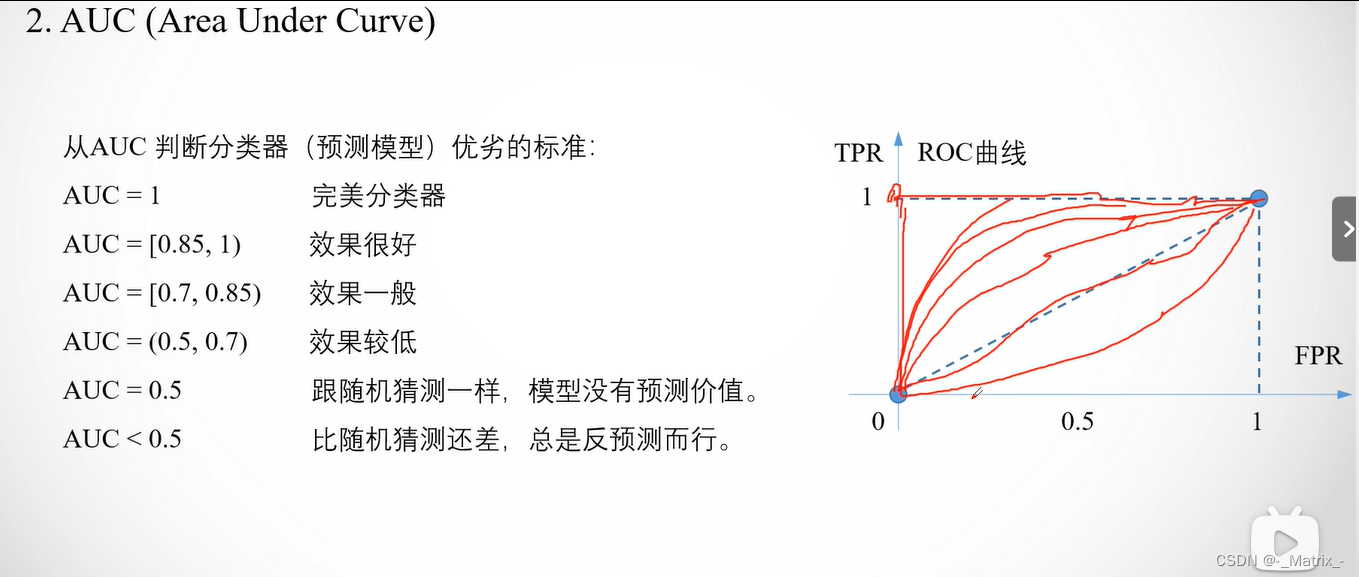
AUC(Area Under the ROC Curve):
AUC 是 ROC 曲线下的面积,用来衡量模型在不同阈值下分类性能的综合表现。
AUC(Area Under the ROC Curve)是用于衡量分类模型性能的重要指标之一,它表示ROC曲线下的面积,即ROC曲线与坐标轴之间的面积。
在ROC曲线中,横轴表示FPR(False Positive Rate),纵轴表示TPR(True Positive Rate,召回率)。
AUC表示ROC曲线下的面积,其取值范围在0.5到1之间。对于完美的分类器,AUC为1,表示模型在所有阈值下都能完美地将正类别和负类别样本分开。而AUC为0.5表示模型的分类性能等同于随机预测,即ROC曲线为对角线。
AUC值的含义如下:
- AUC = 1:完美分类器,模型的分类性能非常好。
- AUC > 0.5:优于随机预测,模型具有良好的分类性能。
- AUC = 0.5:等于随机预测,模型的分类性能不好,相当于乱猜。
- AUC < 0.5:差于随机预测,模型的分类性能更差,相当于反向分类。
AUC是一个非常重要的指标,特别适用于处理类别不平衡的情况。它可以帮助我们全面评估分类模型的性能,同时不受分类阈值的影响。在实际应用中,通常更高的AUC值表示模型的分类性能更好。

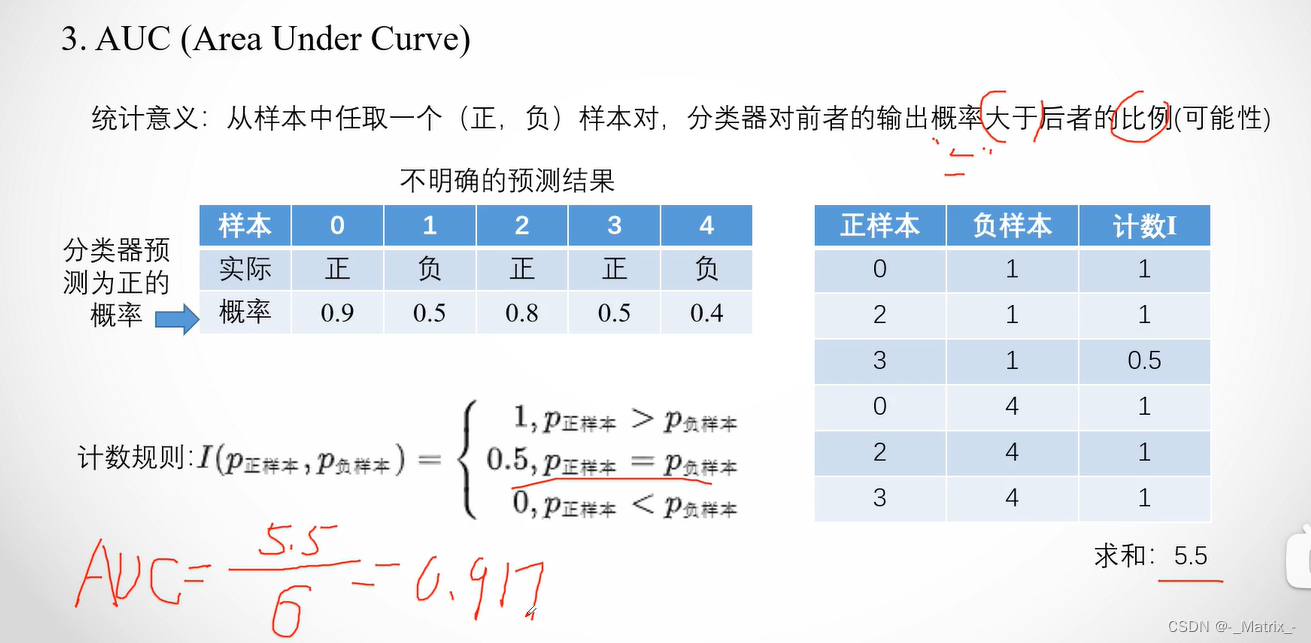


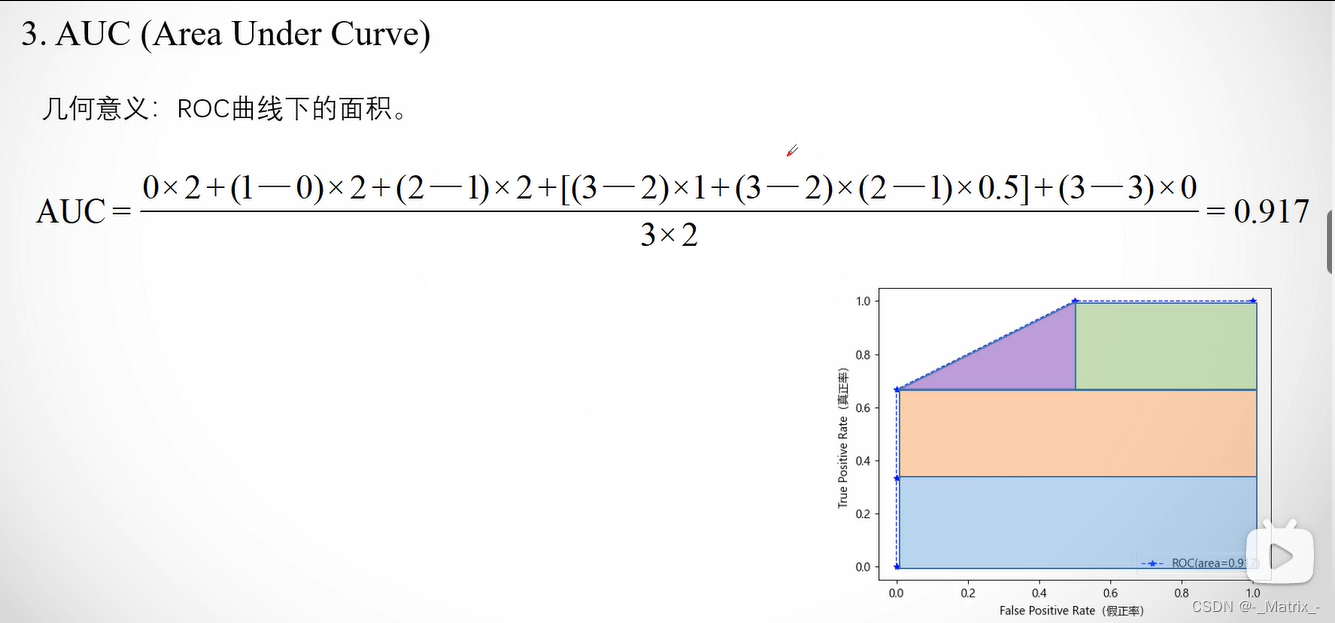
// 根据ROC曲线计算AUC - 返回面积
float calculatemAUC(const std::vector<std::pair<float,float>>& points)
{
//梯形面积累加 数据中必须从x=0开始,到1结束,否则缺少面积
float auc = 0.0;
for (int i = 1; i < points.size(); ++i)
{
float x1 = points[i - 1].first;
float x2 = points[i].first;
float y1 = points[i - 1].second;
float y2 = points[i].second;
float value = ((x2 - x1) * (y1 + y2) / 2.0);
auc += value;
}
return auc;
}
Cohen’s Kappa:
Cohen’s Kappa 是用于衡量分类器与随机分类器之间一致性的指标。它考虑了分类器的准确率与随机分类之间的差异。
Cohen’s Kappa(科恩的Kappa)是一种用于衡量分类模型在多类别分类问题中的一致性的统计量。它考虑了模型的预测结果与真实标签之间的一致性,同时考虑了由于随机预测导致的准确性。
Cohen’s Kappa的取值范围在-1到1之间,具体解释如下:
- Kappa = 1:表示模型的预测与真实标签完全一致,没有误差。
- Kappa > 0:表示模型的预测优于随机预测,具有一定的分类一致性。
- Kappa = 0:表示模型的预测与随机预测一致性相同,即模型的预测没有优于随机预测。
- Kappa < 0:表示模型的预测差于随机预测,可能存在较大的误差。
计算Cohen’s Kappa的公式如下:
Kappa = (Po - Pe) / (1 - Pe)
其中,Po是观测到的分类一致性,Pe是随机分类的预期一致性。
在计算Cohen’s Kappa时,首先需要计算混淆矩阵的四个元素(TP、TN、FP、FN),然后计算分类准确率(Overall Accuracy)和每个类别的预测准确率(Per Class Accuracy),最终计算Cohen’s Kappa。
Cohen’s Kappa是一个重要的评估指标,特别适用于多类别分类问题,它考虑了模型的分类一致性和随机预测之间的差异,使得其评估更加全面。
以下是用C++编写的一个简单示例代码,用于计算Cohen’s Kappa(科恩的Kappa):
#include <iostream>
#include <vector>
// 计算混淆矩阵的四个元素(TP、TN、FP、FN)
void calculateConfusionMatrix(const std::vector<int>& predictions, const std::vector<int>& targets,
int& TP, int& TN, int& FP, int& FN) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return;
}
TP = TN = FP = FN = 0;
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == 1) {
if (targets[i] == 1) {
TP++;
} else {
FP++;
}
} else {
if (targets[i] == 0) {
TN++;
} else {
FN++;
}
}
}
}
// 计算Cohen's Kappa
double calculateCohensKappa(int TP, int TN, int FP, int FN) {
int totalSamples = TP + TN + FP + FN;
if (totalSamples == 0) {
std::cerr << "样本数量不能为0" << std::endl;
return 0.0;
}
double Po = static_cast<double>(TP + TN) / totalSamples;
double Pe = static_cast<double>((TP + FN) * (TP + FP) + (FN + TN) * (FP + TN)) / (totalSamples * totalSamples);
if (Pe == 1) {
std::cerr << "Pe的值为1,Cohen's Kappa不能计算" << std::endl;
return 0.0;
}
double kappa = (Po - Pe) / (1 - Pe);
return kappa;
}
int main() {
// 假设有10个样本的预测值和真实值
std::vector<int> predictions = {1, 0, 1, 1, 0, 1, 0, 0, 1, 1};
std::vector<int> targets = {1, 0, 0, 1, 0, 1, 1, 0, 1, 1};
int TP, TN, FP, FN;
// 计算混淆矩阵的四个元素
calculateConfusionMatrix(predictions, targets, TP, TN, FP, FN);
// 计算Cohen's Kappa
double kappa = calculateCohensKappa(TP, TN, FP, FN);
std::cout << "混淆矩阵:" << std::endl;
std::cout << "| " << TP << " | " << FN << " |" << std::endl;
std::cout << "| " << FP << " | " << TN << " |" << std::endl;
std::cout << "Cohen's Kappa: " << kappa << std::endl;
return 0;
}
Matthews相关系数(Matthews Correlation Coefficient,MCC):
MCC 是另一种衡量分类器性能的指标,它综合考虑了真正例、真负例、假正例和假负例的数量。
Matthews相关系数(Matthews Correlation Coefficient,MCC),也称为Matthews相关性指数,是一种用于衡量二分类模型性能的指标。它综合考虑了混淆矩阵的四个元素(TP、TN、FP、FN),并可以评估模型在类别不平衡情况下的性能。
Matthews相关系数的取值范围在-1到1之间,具体解释如下:
- MCC = 1:完美预测,模型的预测与真实标签完全一致。
- MCC > 0:优于随机预测,模型的预测优于随机预测。
- MCC = 0:与随机预测一致,模型的预测没有优于随机预测。
- MCC < 0:差于随机预测,模型的预测差于随机预测。
Matthews相关系数的计算公式如下:
MCC = (TP * TN - FP * FN) / sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN))
其中,TP、TN、FP、FN分别为混淆矩阵的四个元素。
Matthews相关系数是一种对称性的指标,对类别不平衡问题不敏感。它可以帮助我们全面评估二分类模型的性能,并在样本不均衡的情况下提供更稳健的评估。通常来说,MCC值越接近1,表示模型的性能越好。
以下是用C++编写的一个简单示例代码,用于计算Matthews相关系数(MCC):
#include <iostream>
#include <vector>
#include <cmath>
// 计算混淆矩阵的四个元素(TP、TN、FP、FN)
void calculateConfusionMatrix(const std::vector<int>& predictions, const std::vector<int>& targets,
int& TP, int& TN, int& FP, int& FN) {
if (predictions.size() != targets.size() || predictions.empty()) {
std::cerr << "预测值和真实值的数量应该相等且不为空" << std::endl;
return;
}
TP = TN = FP = FN = 0;
for (size_t i = 0; i < predictions.size(); ++i) {
if (predictions[i] == 1) {
if (targets[i] == 1) {
TP++;
} else {
FP++;
}
} else {
if (targets[i] == 0) {
TN++;
} else {
FN++;
}
}
}
}
// 计算Matthews相关系数(MCC)
double calculateMatthewsCorrelationCoefficient(int TP, int TN, int FP, int FN) {
double denominator = sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN));
if (denominator == 0) {
std::cerr << "分母不能为0" << std::endl;
return 0.0;
}
double mcc = (TP * TN - FP * FN) / denominator;
return mcc;
}
int main() {
// 假设有10个样本的预测值和真实值
std::vector<int> predictions = {1, 0, 1, 1, 0, 1, 0, 0, 1, 1};
std::vector<int> targets = {1, 0, 0, 1, 0, 1, 1, 0, 1, 1};
int TP, TN, FP, FN;
// 计算混淆矩阵的四个元素
calculateConfusionMatrix(predictions, targets, TP, TN, FP, FN);
// 计算Matthews相关系数(MCC)
double mcc = calculateMatthewsCorrelationCoefficient(TP, TN, FP, FN);
std::cout << "混淆矩阵:" << std::endl;
std::cout << "| " << TP << " | " << FN << " |" << std::endl;
std::cout << "| " << FP << " | " << TN << " |" << std::endl;
std::cout << "Matthews相关系数(MCC): " << mcc << std::endl;
return 0;
}
在此示例中,我们定义了几个函数来计算混淆矩阵的四个元素(TP、TN、FP、FN)和Matthews相关系数(MCC)。首先,我们计算混淆矩阵的四个元素,然后根据这些元素计算Matthews相关系数。最后,输出混淆矩阵和Matthews相关系数的值作为二分类模型性能的评估指标。
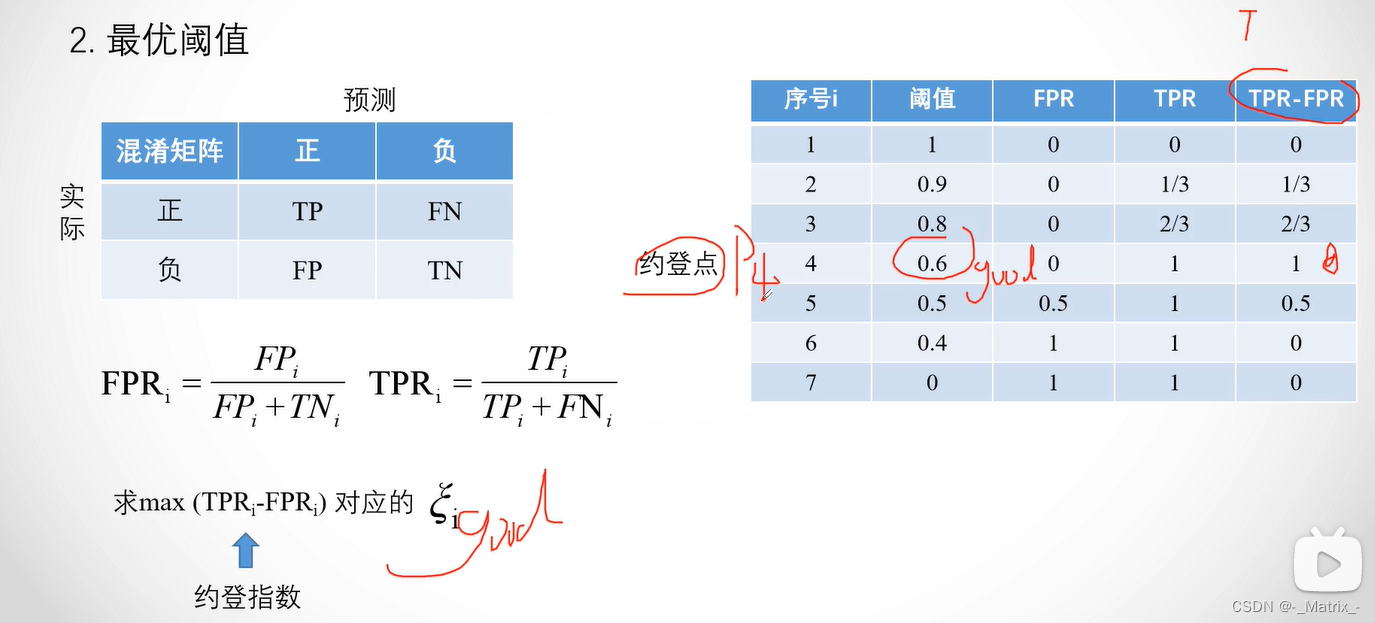
最优阈值
-
F1-Score:F1-Score是精确率(Precision)和召回率(Recall)的调和平均值,取得最大值时对应的阈值可以被认为是最优阈值。F1-Score适用于同时考虑准确率和召回率的情况。
-
ROC曲线:在ROC曲线上,最优阈值通常对应于曲线上最靠近左上角(0, 1)的点。这个点同时具有较高的真阳性率和较低的假阳性率。
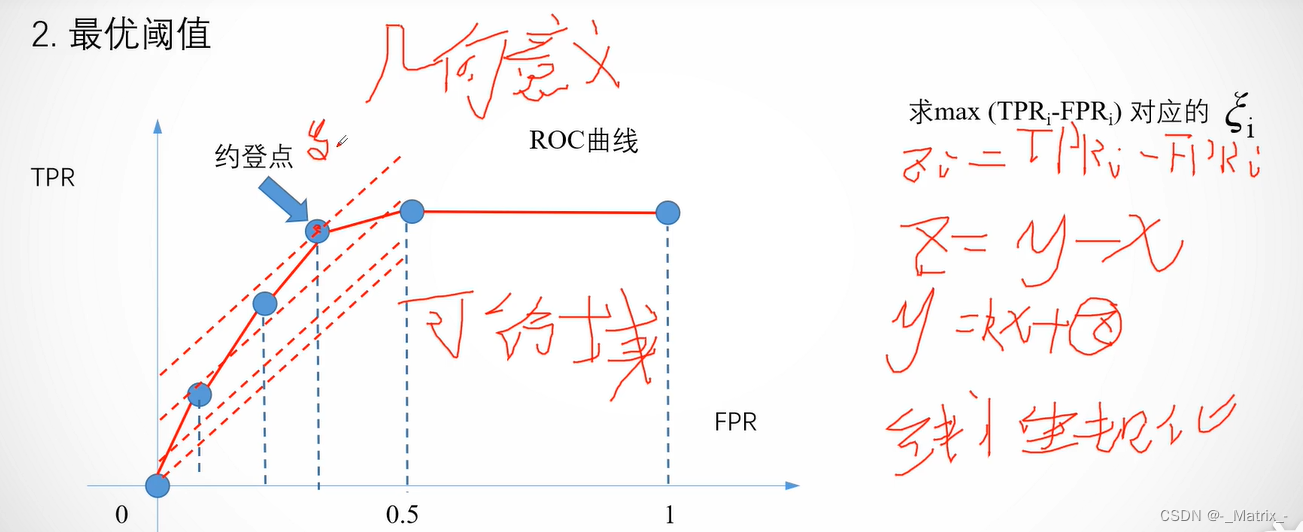
约登指数(Youden’s J statistic),所有样本中 T P R − F P R TPR-FPR TPR−FPR 的值最大的数叫约登点,当前序号阈值也是最优阈值。







![[计网底层小探索]:实现并部署多线程并发Tcp服务器框架(基于生产者消费者模型的线程池结构)](https://img-blog.csdnimg.cn/direct/c033820068dd452f96c57916b5fce352.jpeg#pic_center)

