文章目录
- 概述
- DMA与Cache一致性
- DMA映射类型
- 一致性DMA映射
- dma_alloc_coherent
- 流式DMA映射
- dma_map_single
- 数据同步操作
- dma_direct_sync_single_for_cpu
- dma_direct_sync_single_for_device
- 相关参考
概述
现代计算机系统中,CPU访问内存需要经过Cache,但外部设备通常不感知Cache的存在,因此CPU和外设在访问DMA内存时,必须谨慎处理内存数据的一致性问题。为了处理这种一致性问题,同时为了兼顾多种设备类型,Linux系统会采用不同的规则来映射DMA内存,开发者遵循这套规则对DMA内存进行操作。
DMA与Cache一致性
DMA内存中的数据会涉及到CPU和设备的共同访问,区别在于CPU通常经过Cache访问内存,但常规的设备通常不会感知Cache的存在。因此,CPU写入的数据可能因为还存在Cache中而未及时刷入内存,从而导致设备没有DMA到最新的数据;反过来,设备已经向设备DMA了新的数据,但CPU可能仍然在使用Cache中旧的数据。
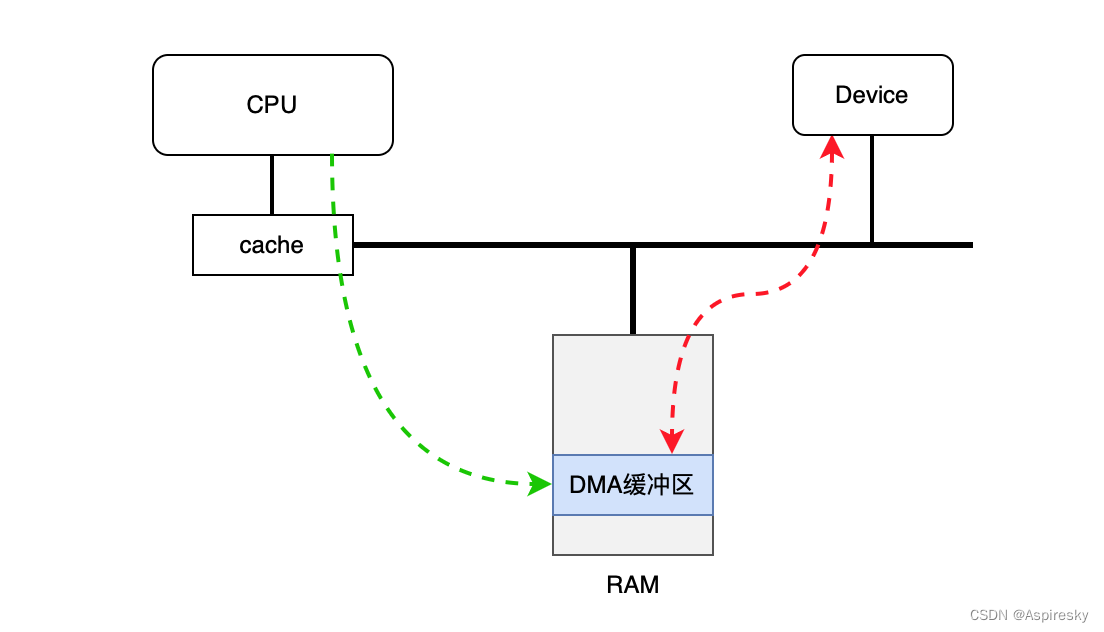
解决这种DMA与Cache间数据一致性的方法通常有两种,一种是设备硬件支持Cache一致性协议;另外一种就是软件通过同步操作来保证数据一致性。根据硬件是否支持Cache一致性,可以将设备分成两类:
- cache coherence设备:设备之间的读写不需要关心cache的一致性问题,硬件将确保数据一致,比如连接在ARM CCI端口上的设备就是cache coherence设备;
- non-coherence设备:需要额外的软件操作(flush/invalidate)等操作来确保数据一致;
DMA映射类型
Linux系统支持两种DMA映射类型:一致性DMA映射(Consistent DMA Mapping)和流式DMA映射(Streaming DMA Mapping)。二者的核心差异在于:
- 一致性DMA映射情况下,无论是CPU还是设备,在访问DMA内存时,全程都不使用Cache,从而避免数据一致性问题;
- 流式DMA映射则只在DMA传输数据时,通过软件操作来处理Cache的同步,以减轻关闭Cache对性能的影响。
一致性DMA映射
一致性DMA映射本质上是利用了硬件的支持,禁用了DMA内存缓存区的Cache功能。 CPU和DMA controller在发起对DMA缓冲区的并行访问的时候不需要考虑cache的影响,也就是说不需要软件进行Cache操作,CPU和DMA controller都可以看到对方对DMA缓冲区的更新。
dma_alloc_coherent
DMA一致性映射使用dma_alloc_coherent接口来分配DMA内存,实现流程如下:
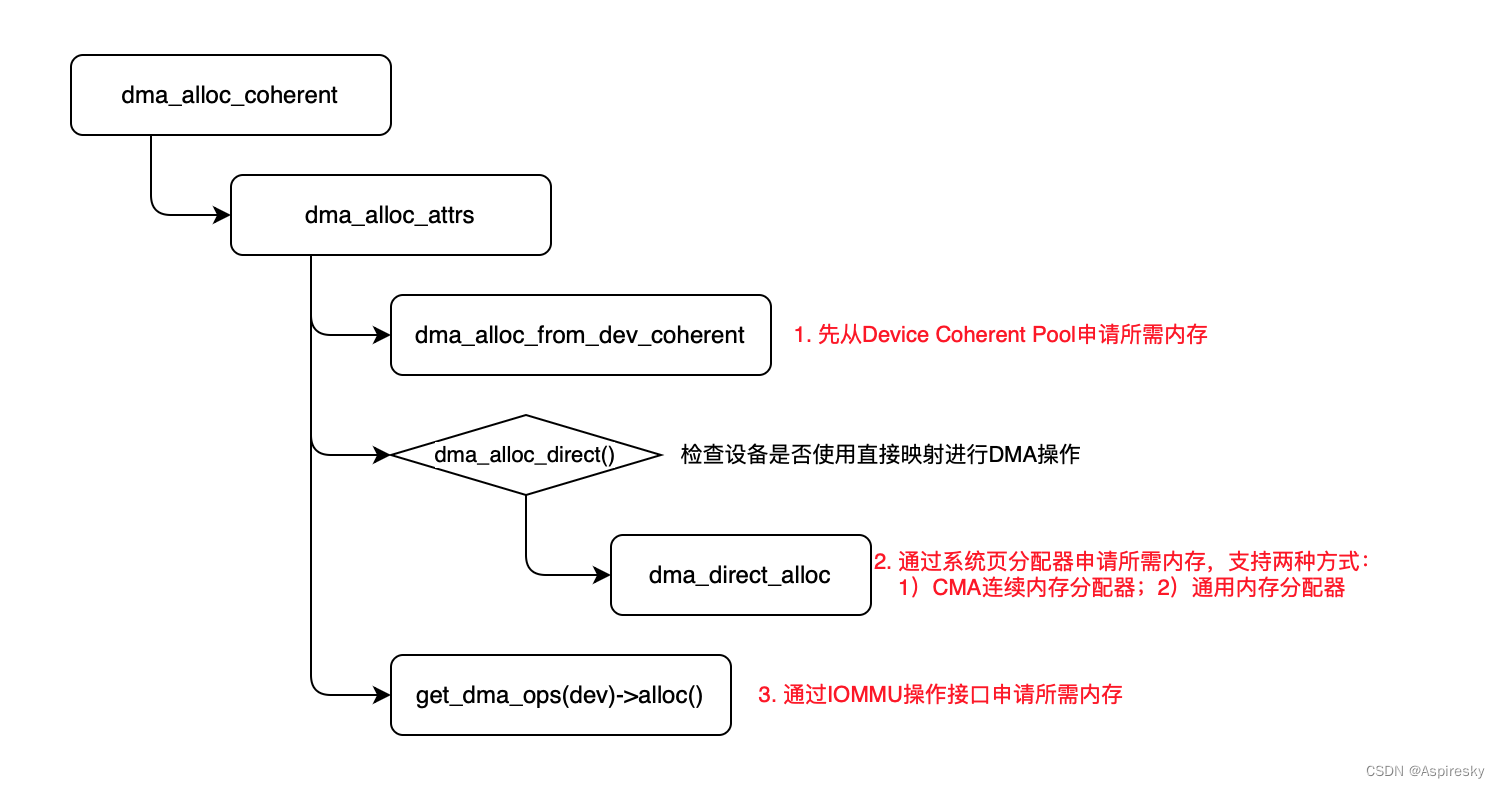
dma_alloc_cohrent通过几种不同的方式分配DMA内存:
- 优先从Device Cohorent Pool申请内存,这是设备专用的DMA内存池;
- 若设备使用直接映射,通过dma_direct_alloc分配内存;
- 若设备使用IOMMU,通过IOMMU提供的操作接口分配内存。
流式DMA映射
流式DMA映射是一次性的,一般是需要进行DMA传输的时候才进行mapping,一旦DMA传输完成,就立刻ummap,或者使用dma_sync_*接口进行同步,并且硬件可以为顺序化访问进行优化。流式DMA映射是怎么保证数据一致性的呢,它的方式更加复杂,让我们从数据的两个方向来分析:
- DMA_TO_DEVICE:CPU将数据写入cache,然后同步cache与RAM(映射区域),同步操作完成后设备再从RAM(映射区域)获取数据;
- DMA_FROM_DEVICE:CPU标记RAM(映射区域)对应的cache line为无效状态,以避免设备将数据写入RAM(映射区域)后,CPU从cache中获得"脏数据"。
流式DMA映射根据数据方向对cache进行"flush/invalid",既保证了数据一致性,也避免了完全关闭cache带来的性能影响。

dma_map_single
DMA流式映射使用dma_map_single或dma_map_sg接口映射DMA内存,其中dma_map_sg支持Scantter/Gathter的处理,这里以dma_map_single接口说明DMA内存的申请流程:
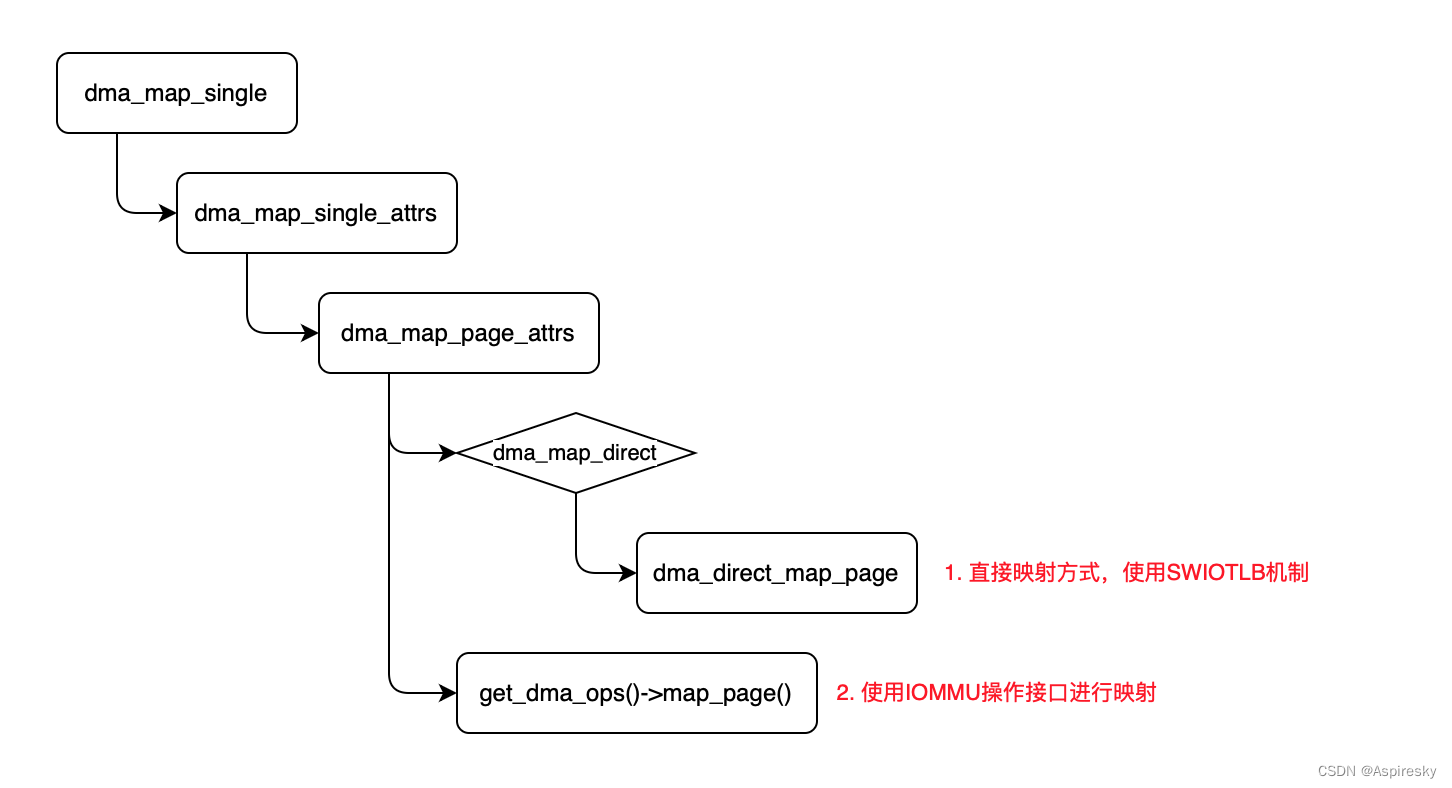
dma_map_single支持两种方式映射DMA内存:
- 直接映射方式,底层使用SWIOTLB机制实现;
- 设备支持IOMMU,通过IOMMU提供的操作接口映射内存。
数据同步操作
DMA流式映射提供了两个接口:dma_direct_sync_single_for_cpu和dma_direct_sync_single_for_device,用于完成DMA内存数据的同步。
dma_direct_sync_single_for_cpu
如果你需要多次访问同一个流式映射DMA缓冲区,并且在DMA传输之间读写DMA缓冲区上的数据,这时候你需要使用dma_sync_single_for_cpu进行DMA缓冲区的sync操作,以便CPU和设备可以看到最新的、正确的数据。

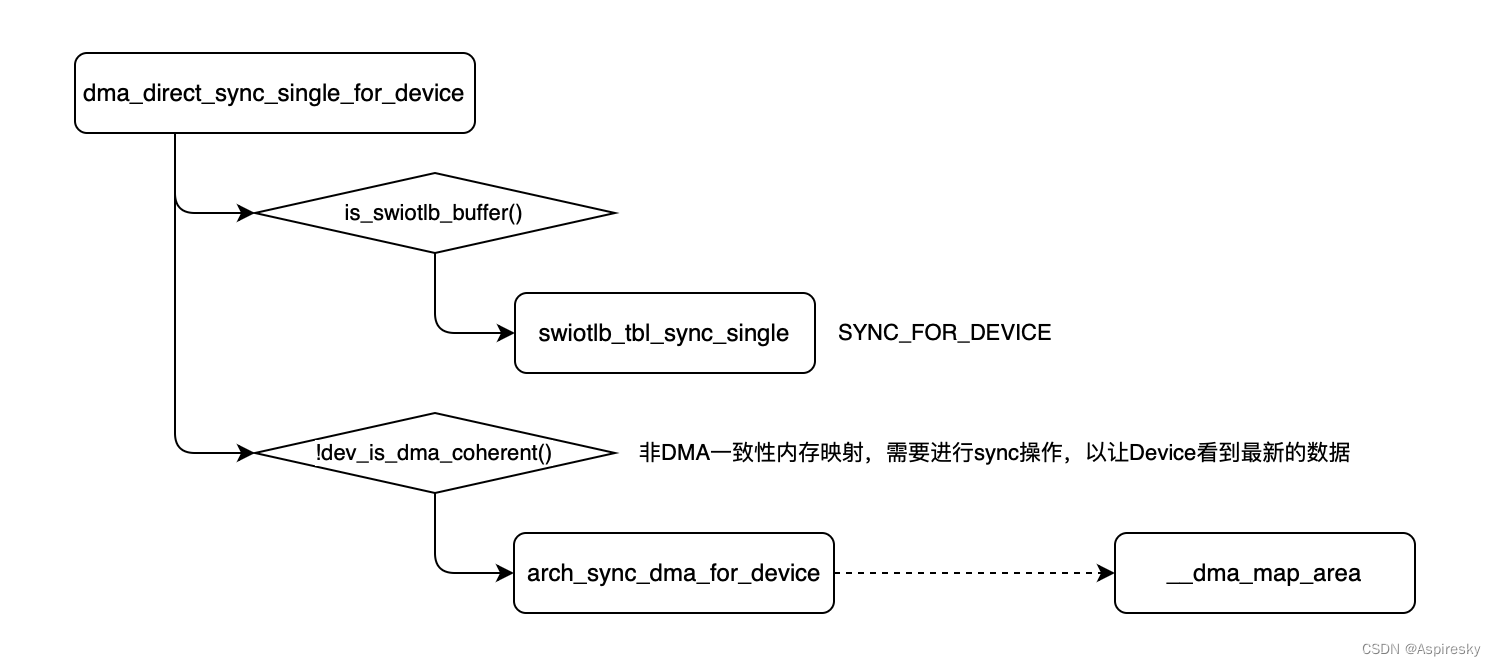
dma_direct_sync_single_for_device
如果CPU操作了DMA缓冲区的数据,然后你又想让硬件设备访问DMA缓冲区,这时候,在真正让硬件设备去访问DMA缓冲区之前,你需要调用dma_direct_sync_single_for_device接口以便让硬件设备可以看到cpu更新后的数据。
相关参考
- Dynamic DMA mapping guide
- 扒开DMA映射的内裤
- 看完秒懂:Linux DMA mapping机制分析