文章目录
- 📋 前言
- 🌰 举个例子
- 🎯 什么是 Redis(知识点补充)
- 🎯 Redis 中的多线程
- 🎯 I/O 多线程
- 🎯 Redis 中的多进程
- 📝 结论
- 🎯书籍推荐
- 🔥参与方式

📋 前言
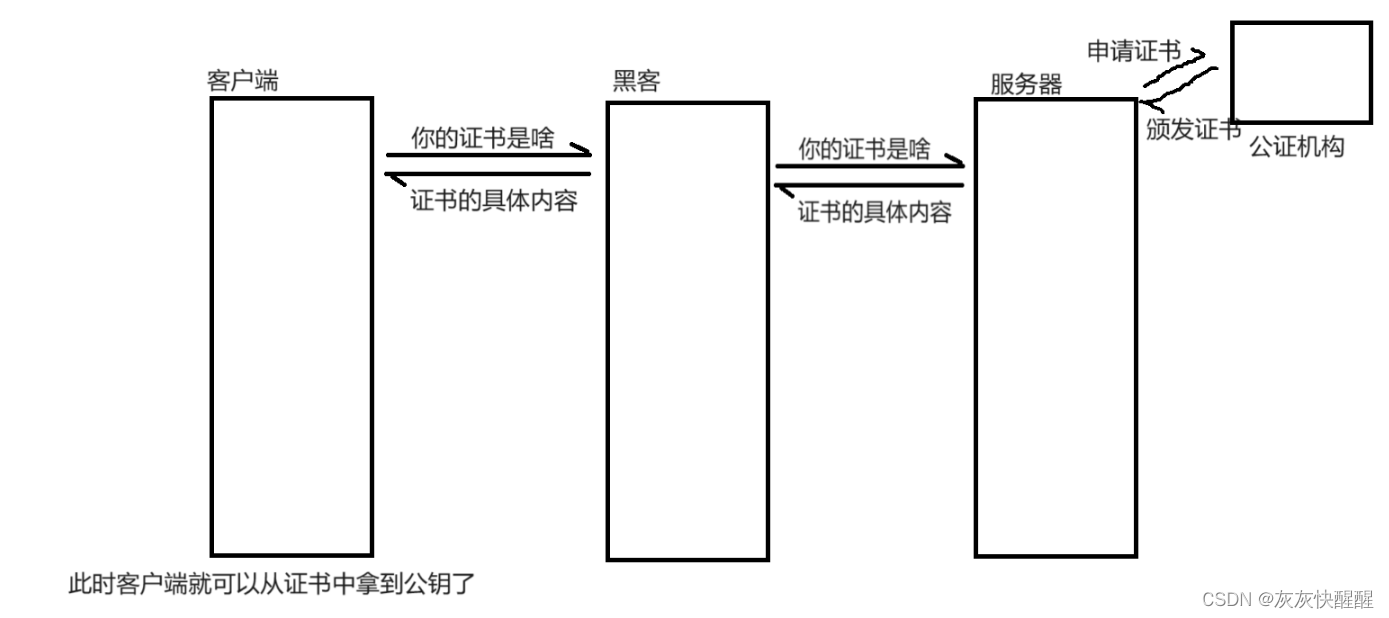
很多后端或运维程序员再面试中都遇到过这么一道面试题:Redis 是单线程还是多线程?这个问题既简单又复杂。说他简单是因为大多数人都知道 Redis 是单线程,说复杂是因为这个答案其实并不准确。
🌰 举个例子
难道 Redis 不是单线程?我们启动一个 Redis 实例,验证一下就知道了。Redis 安装部署方式如下所示:
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
接下来启动Redis实例,使用命令ps查看所有线程,如下所示:
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
竟然有 6 个线程!不是说 Redis 是单线程吗?怎么会有这么多线程呢?这 6 个线程的含义你可能不太了解,但是通过这个示例至少说明 Redis 并不是单线程。
🎯 什么是 Redis(知识点补充)
基于很多前端开发的博友不一定了解 Redis,这里做一个简单介绍和了解。
Redis 是一种开源的内存数据库(In-Memory Database),也被称为数据结构服务器,它支持多种数据结构,如字符串(Strings)、哈希表(Hashes)、列表(Lists)、集合(Sets)和有序集合(Sorted Sets)等。Redis 的出色之处在于其高性能、简单且灵活的键值对存储方式,以及丰富的功能和数据结构支持。以下是 Redis 的一些主要特点和用途:
- 高性能:Redis 将数据存储在内存中,并通过异步写入磁盘或定期写入磁盘来保证数据持久化,因此具有非常快的读写速度。
- 数据结构丰富:除了支持基本的键值对存储外,Redis还支持多种数据结构,如字符串、哈希表、列表、集合和有序集合,使其适用于各种不同的应用场景。
- 持久化支持:Redis支持RDB持久化和AOF持久化两种方式,可以根据需求选择合适的持久化方式来保证数据的安全性。
- 发布与订阅:Redis支持发布与订阅功能,可以实现消息的广播和订阅模式,非常适合构建实时消息系统。
- 缓存:Redis常被用作缓存数据库,可以帮助加速访问速度,降低后端服务器的压力。
- 计数器:由于Redis的原子操作支持,可以方便地实现计数器功能,如网站点击量统计等。
- 分布式锁:Redis的分布式锁功能可以帮助解决分布式系统中的并发控制问题。
🎯 Redis 中的多线程
回到主题,接下来我们逐个介绍上述 6 个线程的作用:
-
redis-server:主线程,用于接收并处理客户端请求。
-
jemalloc_bg_thd:jemalloc 是新一代的内存分配器,Redis 底层使用他管理内存。
-
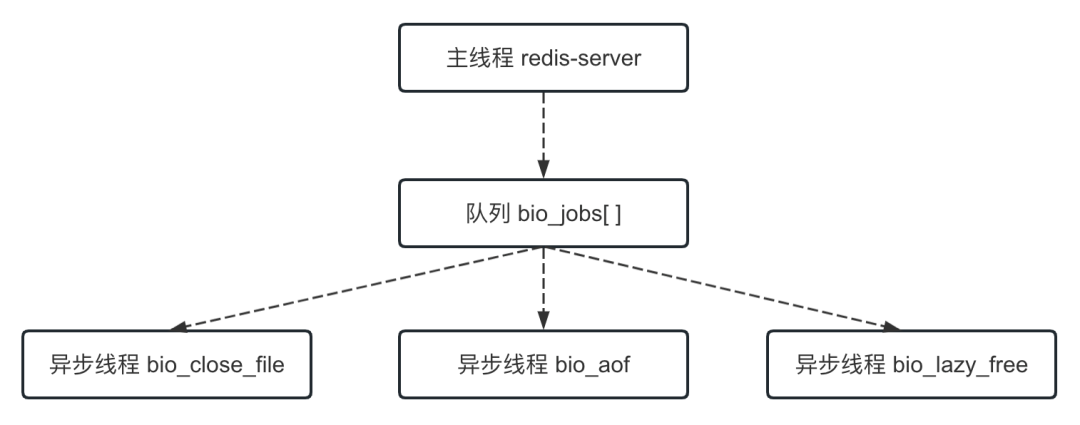
bio_xxx:以 bio 前缀开始的都是异步线程,用于异步执行一些耗时任务。其中,线程 bio_close_file 用于异步删除文件,线程 bio_aof 用于异步将 AOF 文件刷到磁盘,线程 bio_lazy_free 用于异步删除数据(懒删除)。
需要说明的是,主线程是通过队列将任务分发给异步线程的,并且这一操作是需要加锁的。主线程与异步线程的关系如下图所示:
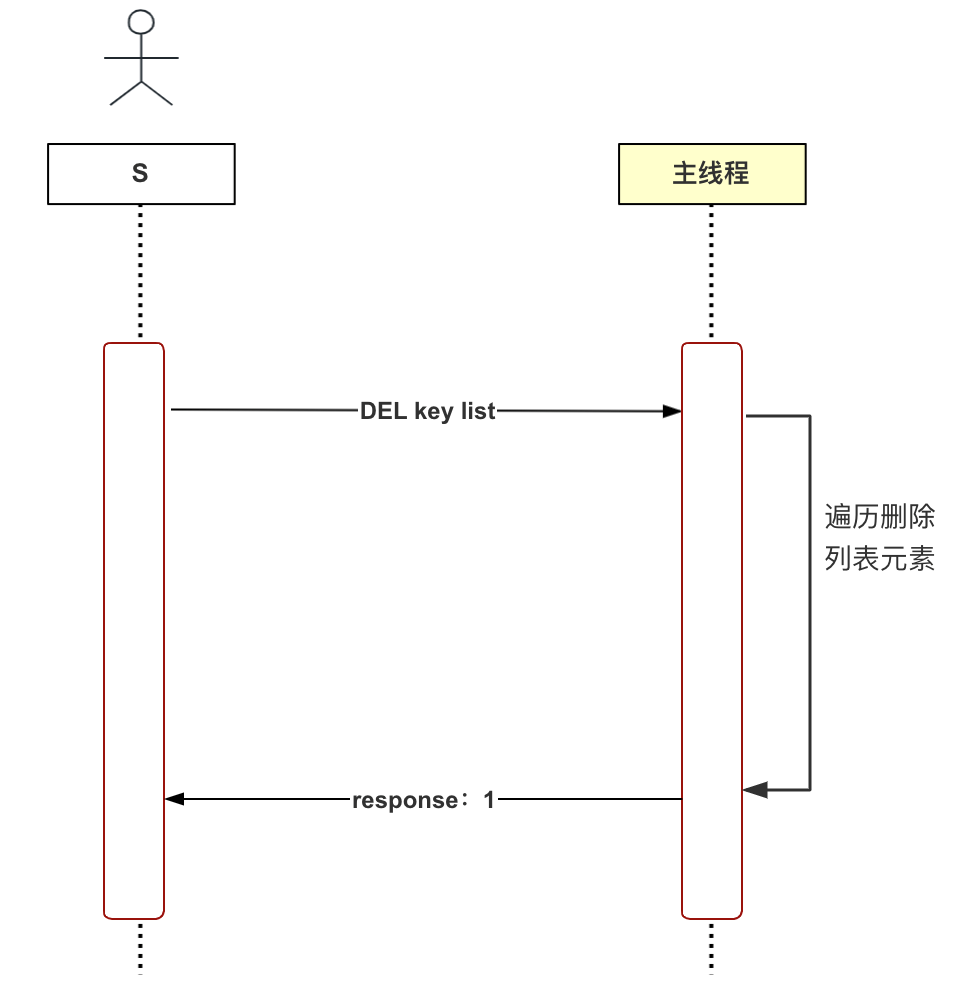
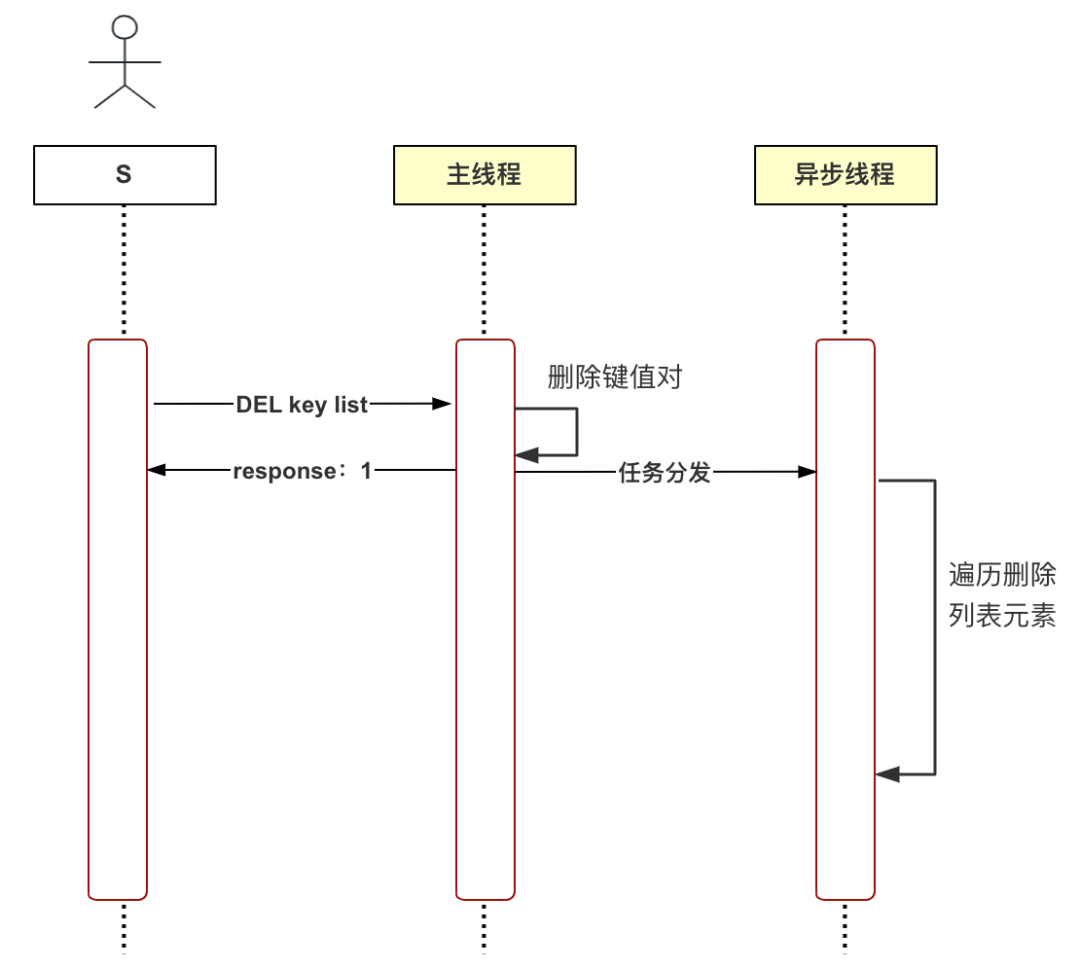
这里我们以懒删除为例,讲解为什么要使用异步线程。Redis 是一款内存数据库,支持多种数据类型,包括字符串、列表、哈希表、集合等。思考一下,删除(DEL)列表类型数据的流程是怎样的呢?第一步从数据库字典中删除该键值对,第二步遍历并删除列表中的所有元素(释放内存)。想想如果列表中的元素数目非常多呢?这一步将非常耗时。这种删除方式称为同步删除,流程如下图所示:
针对上述问题,Redis 提出了懒删除(异步删除),主线程在收到删除命令(UNLINK)时,首先从数据库字典中删除该键值对,随后再将删除任务分发给异步线程 bio_lazy_free,由异步线程执行第二步耗时逻辑。这时候的流程如下图所示:
🎯 I/O 多线程
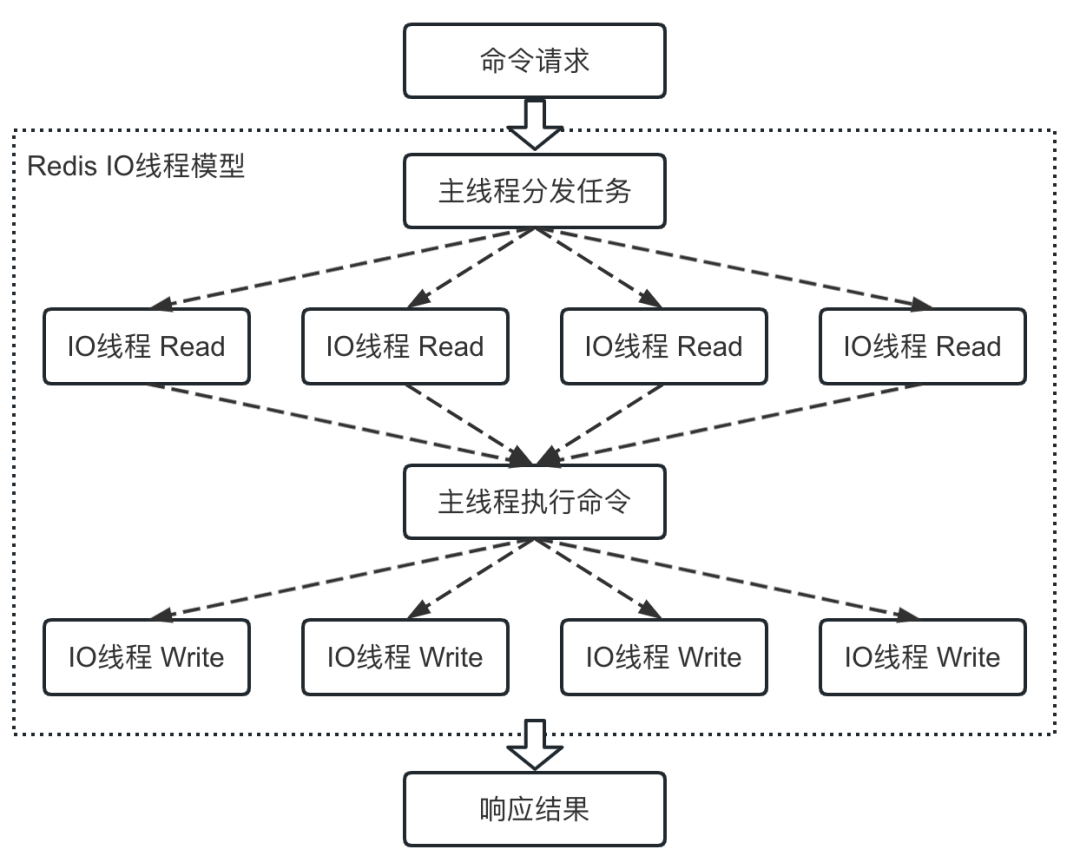
难道 Redis 是多线程?那为什么我们老说 Redis 是单线程呢?这是因为读取客户端命令请求,执行命令以及向客户端返回结果都是在主线程完成的。不然的话,多线程同时操作内存数据库,并发问题如何解决?如果每次操作之前都加锁,那和单线程又有什么区别呢?
当然这一流程在 Redis6.0 版本也发生了改变,Redis官方指出,Redis 是基于内存的键值对数据库,执行命令的过程是非常快的,读取客户端命令请求和向客户端返回结果(即网络I/O)通常会成为Redis的性能瓶颈。
因此,在 Redis 6.0 版本,作者加入了多线程 I/O 的能力,即可以开启多个 I/O 线程,并行读取客户端命令请求,并行向客户端返回结果。I/O 多线程能力使得 Redis 性能提升至少一倍。
为了开启多线程 I/O 能力,需要先修改配置文件 redis.conf:
io-threads-do-reads yes
io-threads 4
这两个配置含义如下:
-
io-threads-do-reads:是否开启多线程I/O能力,默认为"no";
-
io-threads:I/O 线程数目,默认为1,即只使用主线程执行网络 I/O,线程数最大为128;该配置应该根据 CPU 核数设置,作者建议,4 核 CPU 设置 2~3 个 I/O 线程,8 核 CPU 设置 6 个 I/O 线程。
开启多线程 I/O 能力之后,重新启动 Redis 实例,查看所有线程,结果如下:
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
由于我们设置了 io-threads 等于 4,所以会创建4个线程用于执行 I/O 操作(包括主线程),上述结果符合预期。
当然,只有 I/O 阶段才使用了多线程,处理命令请求还是单线程,毕竟多线程操作内存数据存在并发问题。
最后,开启了 I/O 多线程之后,命令的执行流程如下图所示:
🎯 Redis 中的多进程
Redis 还有多进程?是的。在某些场景下,Redis 也会创建多个子进程来执行一些任务。以持久化为例,Redis 支持两种类型的持久化:
- AOF(Append Only File):可以看作是命令的日志文件,Redis会将每一个写命令都追加到AOF文件。
- RDB(Redis Database):以快照的方式存储 Redis 内存中的数据。命令 SAVE 用于手动触发 RDB 持久化。想想如果 Redis 中的数据量非常大,持久化操作必然耗时比较长,而 Redis 是单线程处理命令请求,那么当命令 SAVE 的执行时间过长时,必然会影响其他命令的执行。
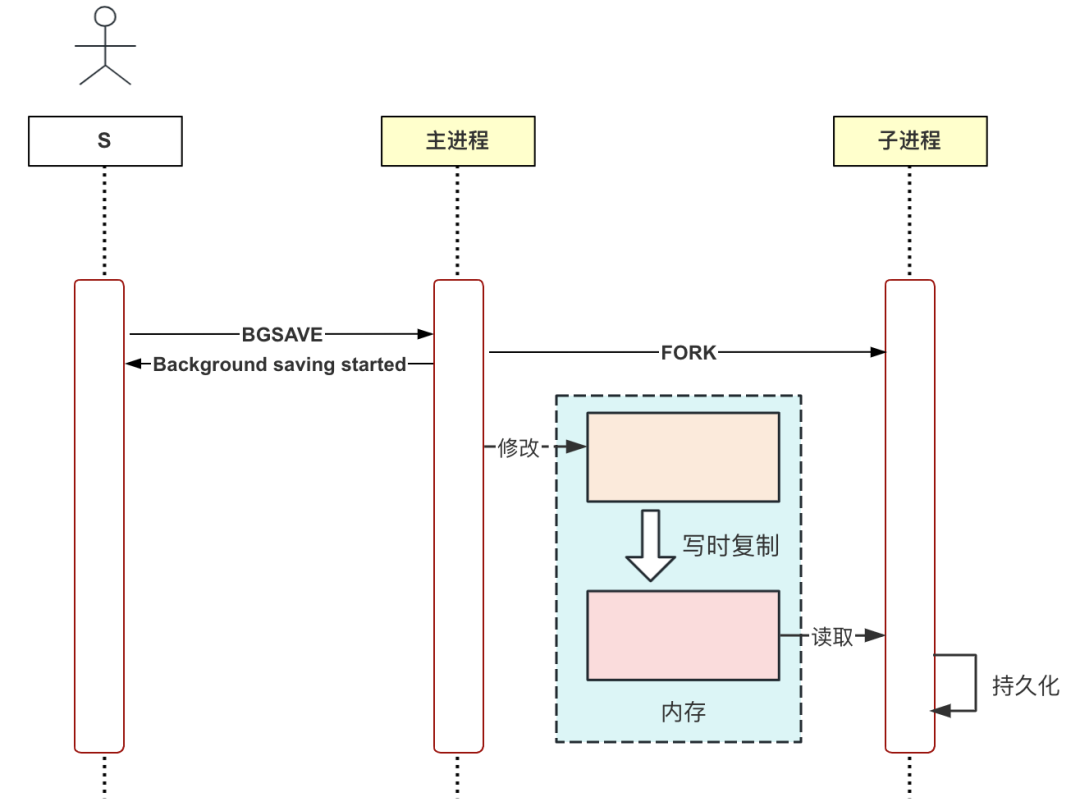
命令 SAVE 有可能会阻塞其他请求,为此,Redis 又引入了命令 BGSAVE,该命令会创建一个子进程来执行持久化操作,这样就不会影响主进程执行其他请求了。
我们可以手动执行命令 BGSAVE 验证。首先,使用 GDB 跟踪 Redis 进程,添加断点,让子进程阻塞在持久化逻辑。如下所示:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
设置好断点之后,使用 Redis 客户端发送命令 BGSAVE,结果如下:
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
可以看到,GDB 目前跟踪的是子进程,进程 ID 是 452541。也可以通过 Linux 命令 ps 查看所有进程,结果如下:
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
可以看到子进程的名称是 redis-rdb-bgsave ,也就是该进程将所有数据的快照持久化在 RDB 文件。
最后再思考两个问题。
问题1:为什么采用子进程而不是子线程呢?
因为 RDB 是将数据快照持久化存储,如果采用子线程,主线程与子线程将会共享内存数据,主线程在持久化的同时还会修改内存数据,这有可能导致数据不一致。而主进程与子进程的内存数据是完全隔离的,不存在此问题。
问题2:假设 Redis 内存中存储了 10 GB的数据,在创建子进程执行持久化操作之后,此时子进程也需要 10 GB的内存吗?复制 10 GB的内存数据,也会比较耗时吧?另外如果系统只有 15 GB的内存,还能执行 BGSAVE 命令吗?
这里有一个概念叫写时复制(copy on write),在使用系统调用 fork 创建子进程之后,主进程与子进程的内存数据暂时还是共享的,但是当主进程需要修改内存数据时,系统会自动将该内存块复制一份,以此实现内存数据的隔离。
命令 BGSAVE 的执行流程如下图所示:
📝 结论
Redis 的进程模型/线程模型还是比较复杂的,这里也只是简单介绍了部分场景下的多线程以及多进程,其他场景下的多线程、多进程还有待读者自己研究。
🎯书籍推荐
Redis 是一款非常受欢迎的开源内存数据存储系统,具有高性能、可扩展、灵活等优点,在互联网和大数据领域得到了广泛应用。为了帮助读者更好地理解和应用 Redis,需要一本既有理论又有实践、通俗易懂的 Redis 书籍。于是,本书诞生了。
本书将介绍 Redis 的基础知识,包括 Redis 的数据结构、数据存储方式、命令和使用场景等,同时深入探讨 Redis 的高级应用,如 Redis 集群、持久化、性能优化等。
本书将通过丰富的案例帮助读者更好地理解和掌握 Redis,使读者能够快速上手并在实际项目中应用 Redis。

🔥参与方式
《高效使用Redis:一书学透数据存储与高可用集群》免费包邮送出 3 本!
抽奖方式:评论区随机抽取 3 位小伙伴免费送出!
参与方式:关注博主、点赞、收藏、评论区评论 (随机有效留言即可)(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间:2024-2-28 22:00:00
当当网购买链接*:https://product.dangdang.com/29667600.html

![[更新]ARCGIS之土地耕地占补平衡、进出平衡系统报备坐标txt格式批量导出工具(定制开发版)](https://img-blog.csdnimg.cn/direct/456dc85e991d42f685c026ca693dde49.png)