这篇文章是对 CUDA 的超级简单介绍,CUDA 是 NVIDIA 流行的并行计算平台和编程模型。我之前在2013年写过一篇文章《CUDA简单介绍》,多年来一直很受欢迎。但 CUDA 编程变得更加容易,GPU 也变得更快,所以是时候进行更新(甚至更简单)的介绍了。
这篇文章是对 CUDA 的超级简单介绍,CUDA 是 NVIDIA 流行的并行计算平台和编程模型。我之前在2013年写过一篇文章《CUDA简单介绍》,多年来一直很受欢迎。但 CUDA 编程变得更加容易,GPU 也变得更快,所以是时候进行更新(甚至更简单)的介绍了。
CUDA C++ 只是使用 CUDA 创建大规模并行应用程序的方法之一。它允许您使用强大的 C++ 编程语言来开发由 GPU 上运行的数千个并行线程加速的高性能算法。许多开发人员通过这种方式加速了计算和带宽需求大的应用程序,包括支持正在进行的人工智能革命(称为深度学习)的库和框架。
因此,您已经听说过 CUDA,并且有兴趣学习如何在自己的应用程序中使用它。如果您是 C 或 C++ 程序员,这篇博文应该会给您一个良好的开端。要继续进行操作,您需要一台具有支持 CUDA 的 GPU(Windows、Mac 或 Linux,以及任何 NVIDIA GPU 都可以)的计算机,或者具有 GPU 的云实例(AWS、Azure、IBM SoftLayer 和其他云服务)供应商有它们)。您还需要安装免费的 CUDA 工具包。您还可以使用在云中的 GPU 上运行的 Jupyter Notebook 进行操作。
让我们开始吧!!!

Starting Simple
我们将从一个简单的 C++ 程序开始,该程序将两个数组的元素相加,每个数组有 100 万个元素。
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
首先,编译并运行这个 C++ 程序。将上面的代码放入一个文件中并将其另存为 add.cpp,然后使用 C++ 编译器进行编译。我使用的是 Mac,所以我使用 clang++,但您可以在 Linux 上使用 g++,或者在 Windows 上使用 MSVC。
clang++ add.cpp -o add
然后运行它:
> ./add
Max error: 0.000000
(在 Windows 上,您可能需要将可执行文件命名为 add.exe 并使用 .\add 运行它。)
正如所料,它打印出求和没有错误,然后退出。现在我想让这个计算在 GPU 的多个核心上(并行)运行。事实上,迈出第一步非常容易。
首先,我只需要把我们的add函数变成GPU可以运行的函数,在CUDA中称为内核。为此,我所要做的就是向函数添加说明符 global ,它告诉 CUDA C++ 编译器这是一个在 GPU 上运行的函数,可以从 CPU 代码中调用。
// CUDA Kernel function to add the elements of two arrays on the GPU
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
这些 global 函数称为内核,在 GPU 上运行的代码通常称为设备代码,而在 CPU 上运行的代码称为主机代码。
Memory Allocation in CUDA
为了在 GPU 上计算,我需要分配 GPU 可访问的内存。 CUDA 中的统一内存通过提供可供系统中所有 GPU 和 CPU 访问的单一内存空间,使这一过程变得简单。要在统一内存中分配数据,请调用 cudaMallocManaged(),它返回一个可以从主机 (CPU) 代码或设备 (GPU) 代码访问的指针。要释放数据,只需将指针传递给 cudaFree()。
我只需要将上面代码中对 new 的调用替换为对 cudaMallocManaged() 的调用,并将对 delete [] 的调用替换为对 cudaFree 的调用。
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
...
// Free memory
cudaFree(x);
cudaFree(y);
最后,我需要启动 add() 内核,它会在 GPU 上调用它。 CUDA 内核启动是使用三尖括号语法 <<< >>> 指定的。我只需将它添加到参数列表之前的调用中即可。
add<<<1, 1>>>(N, x, y);
简单的!我很快就会详细介绍尖括号内的内容;现在您需要知道的是这一行启动一个 GPU 线程来运行 add()。
还有一件事:我需要 CPU 等待内核完成后再访问结果(因为 CUDA 内核启动不会阻塞调用 CPU 线程)。为此,我只需在对 CPU 进行最终错误检查之前调用 cudaDeviceSynchronize() 即可。
这是完整的代码:
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
CUDA 文件的文件扩展名为 .cu。因此,将此代码保存在名为 add.cu 的文件中,并使用 CUDA C++ 编译器 nvcc 进行编译。
> nvcc add.cu -o add_cuda
> ./add_cuda
Max error: 0.000000
这只是第一步,因为正如所写的,该内核仅对于单个线程是正确的,因为运行它的每个线程都会对整个数组执行添加操作。此外,由于多个并行线程都会读取和写入相同的位置,因此存在竞争条件。
注意:在 Windows 上,您需要确保在 Microsoft Visual Studio 项目的配置属性中将平台设置为 x64。
Profile it!
我认为了解内核运行时间的最简单方法是使用 nvprof(CUDA 工具包附带的命令行 GPU 分析器)运行它。只需在命令行中输入 nvprof ./add_cuda:

上面是 nvprof 的截断输出,显示了对 add 的单个调用。在 NVIDIA Tesla K80 加速器上大约需要半秒,在我用了 3 年的 Macbook Pro 上的 NVIDIA GeForce GT 740M 上大约需要同样的时间。
让我们通过并行性使其更快。
Picking up the Threads
现在您已经运行了一个带有一个线程来执行一些计算的内核,如何使其并行?关键在于 CUDA 的 <<<1, 1>>> 语法。这称为执行配置,它告诉 CUDA 运行时要使用多少个并行线程来在 GPU 上启动。这里有两个参数,但让我们从更改第二个参数开始:线程块中的线程数。 CUDA GPU 使用大小为 32 倍数的线程块运行内核,因此选择 256 个线程是合理的大小。
add<<<1, 256>>>(N, x, y);
如果我仅使用此更改运行代码,它将为每个线程执行一次计算,而不是将计算分散到并行线程中。为了正确地做到这一点,我需要修改内核。 CUDA C++ 提供了关键字,让内核可以获取正在运行的线程的索引。具体来说,threadIdx.x 包含当前线程在其块中的索引,blockDim.x 包含块中线程的数量。我将修改循环以使用并行线程跨过数组。
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
add 功能没有太大变化。事实上,将索引设置为 0 并将步长设置为 1 使其在语义上与第一个版本相同。
将文件保存为 add_block.cu 并再次在 nvprof 中编译并运行。在本文的其余部分中,我将仅显示输出中的相关行。

这是一个很大的加速(从 463 毫秒降至 2.7 毫秒),但并不奇怪,因为我从 1 个线程增加到 256 个线程。 K80 比我的小型 Macbook Pro GPU 更快(3.2 毫秒)。让我们继续努力以获得更好的性能。
Out of the Blocks
CUDA GPU 具有许多并行处理器,分为流式多处理器 (SM)。每个SM可以运行多个并发线程块。例如,基于 Pascal GPU 架构的 Tesla P100 GPU 有 56 个 SM,每个 SM 最多能够支持 2048 个活动线程。为了充分利用所有这些线程,我应该启动具有多个线程块的内核。
现在您可能已经猜到执行配置的第一个参数指定了线程块的数量。并行线程块一起构成了所谓的网格。由于我有 N 个元素要处理,每个块有 256 个线程,因此我只需要计算块数即可获得至少 N 个线程。我只是将 N 除以块大小(小心向上舍入,以防 N 不是 blockSize 的倍数)。

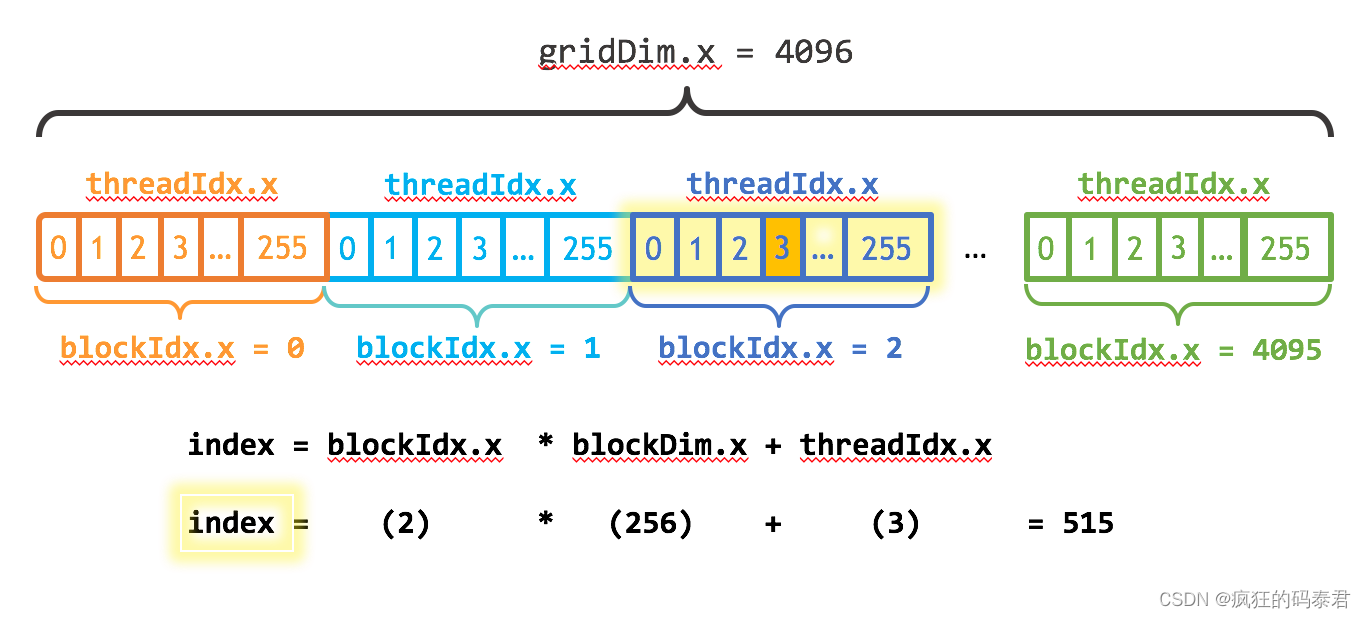
我还需要更新内核代码以考虑整个线程块网格。 CUDA提供了gridDim.x,它包含网格中块的数量,以及blockIdx.x,它包含当前线程块在网格中的索引。图 1 说明了使用 blockDim.x、gridDim.x 和 threadIdx.x 在 CUDA 中对数组(一维)进行索引的方法。这个想法是,每个线程通过计算到其块开头的偏移量(块索引乘以块大小:blockIdx.x * blockDim.x)并添加块内线程的索引(threadIdx.x)来获取其索引。代码 blockIdx.x * blockDim.x + threadIdx.x 是惯用的 CUDA。
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
更新后的内核还将步幅设置为网格中的线程总数 (blockDim.x * gridDim.x)。 CUDA 内核中的这种类型的循环通常称为网格跨度循环。
将文件另存为 add_grid.cu 并再次在 nvprof 中编译并运行。

在 K80 的所有 SM 上运行多个块,这又是 28 倍的加速!我们只使用 K80 上 2 个 GPU 之一,但每个 GPU 有 13 个 SM。请注意,我笔记本电脑中的 GeForce 有 2 个(较弱的)SM,运行内核需要 680us。
Summing Up
以下是 Tesla K80 和 GeForce GT 750M 上三个版本的 add() 内核的性能概要。
 正如您所看到的,我们可以在 GPU 上实现非常高的带宽。本文中的计算非常受带宽限制,但 GPU 也擅长计算密集型计算,例如密集矩阵线性代数、深度学习、图像和信号处理、物理模拟等。
正如您所看到的,我们可以在 GPU 上实现非常高的带宽。本文中的计算非常受带宽限制,但 GPU 也擅长计算密集型计算,例如密集矩阵线性代数、深度学习、图像和信号处理、物理模拟等。


![[已解决]npm淘宝镜像最新官方指引(2023.08.31)](https://img-blog.csdnimg.cn/direct/eb7d9c2019a9461ab759da8c3ddffe5f.png)