心得的体会
刚过了年刚开工,闲暇之余调研了分布式SQL流处理数据库–RisingWave,本人是Flink(包括FlinkSQL和Flink DataStream API)的资深用户,但接触到RisingWave令我眼前一亮,并且拿我们生产上的监控告警场景在RisingWave上做了验证,以下是自己的心得体会:
RisingWave架构简单,运维成本底,基于云原生(可以分别基于计算和存储动态伸缩),同时在开发上屏蔽了Flink等实时处理框架底层需要处理的一些技术细节(状态存储,数据一致性,分布式集群扩展等)。提供了与PostgreSQL兼容的标准SQL接口,用户可以像使用 PostgreSQL 一样处理数据流。并且RisingWave不单单可以处理流式数据,还提供了数据其他流式处理框架(如:Flink、storm)所不具备的数据存储能力,基本可以完全取代FlinkSQL。相对于其他OLAP系统(如:apache doris,starrocks),RisingWave采用同步实时,可以保证实时的新鲜度;强一致性,而不是最终一致性。用户需要做的仅仅是通过开发SQL就可以处理流数据,当然首先需要具备流式数据处理思维(相对于离线)。
RisingWave当然也有自身的不足,相对于Flink可以通过DataStream API自定义灵活的处理流式数据,RisingWave只能解决一些特定的流式场景,无法做太多定制开发;相对于Apache Doris等OLAP实时分析性数据库,RisingWave不适合做分析型随机查询。另外RisingWave是个新事物,正在发展阶段,周边生态和相关文档还不健全,作为尝鲜者可能会踩很多坑。然而令人欣慰的是RisingWave的社区回复还是很及时的,RisingWave官方投入了很多精力在做RisingWave的布道和答疑。
至于争论比较厉害的RisingWav VS FLink的性能和吞吐量上孰优孰劣,针对不同应用场景可能有不同表现,因此没有亲自调研就没有发言权。但我认为在不同的场景下他们应该有各自的优势。无论如何RisingWave部署简单,上手容易,试错成本低是一个不争的事实。RisingWave可以应用在一些数据看版,监控,实时指标等场景。
利用动态和时间过滤器实现监控告警
FlinkSQL解决不了定时触发的问题,FlinkSQL的流处理逻辑只是按event触发,不能按时间条件触发,也就是没有触发器机制。FlinkSQL窗口的定时触发,归根结底也是基于event触发,event驱动的机制。因此需要触发器的场景就需要用到Flink DataStream API的KeyedProcessFunction等算子。但RisingWave利用Dynamic filters 和 Temporal filters 可以间接实现类似场景的触发器机制。
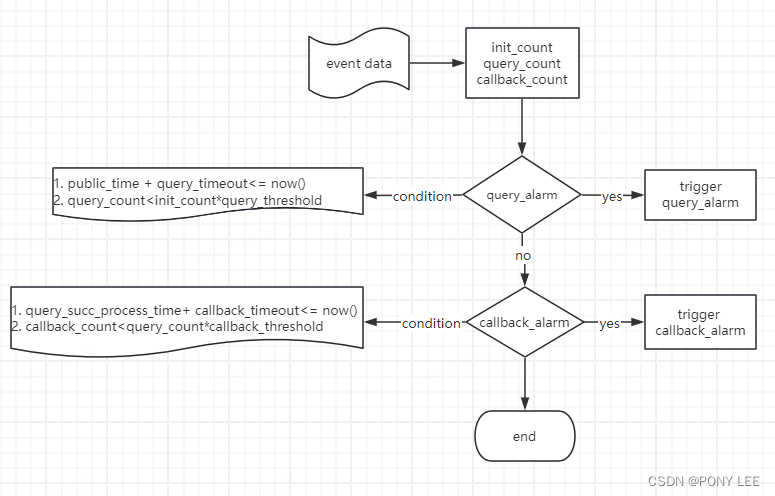
场景描述
现有如下群消息实时指标监控场景:
数据有初始化(init)、查询(query)、回调(callback:succ+fail)三种先后顺序状态。
数据是按预设时间批次分组的,例如:2024-01-01 08:00:00、2024-01-01 08:30:00,实时统计每一个批次内三种不同状态的数据count。
监控指标一:在某一个批次延迟指定的时间(query_timeout)之内(例如:2024-01-01 08:00:00延迟1小时触发时间为系统时间2024-01-01 09:00:00),该批次的query状态数据count没有达到init状态的数量count阀值(即query_count<init_count*query_threshold)就触发告警。
同时结束该批次数据统计,下发该批次数据的指标包括:批次时间、init_count、query_count等
监控指标二:如果指标一告警没有被触发,该批次在满足query状态数据count达到init状态数量count的阀值(即query_count>=init_countquery_threshold)以后,在指定的延迟时间内(callback_timeout),该批次的callback状态数据count没有达到query状态的数量count阀值(即callback_count<query_countcallback_threshold)就触发告警。
同时结束该批次数据统计,下发该批次数据的指标包括:批次时间、init_count、query_count、callback_count等
群消息实时指标监控流程图如下:
实例demo
RisingWave部署可以参考:RisingWave分布式SQL流处理数据库调研
假设:
query_threshold=1, callback_count=1
query_timeout= ‘5 minute’, callback_timeout= ‘1 minute’
0->init,1->query,2->callback
RisingWave SQL:
DROP TABLE t_msg;
CREATE TABLE t_msg(
msg_id int
,status smallint
,public_time timestamp
,process_time timestamp as proctime()
) APPEND ONLY;
set timezone = 'PRC';--PRC(People’s Republic of China)
show timezone;
select * from t_msg;
--统计不同状态的count
DROP MATERIALIZED VIEW mv_t_msg_groupby;
CREATE MATERIALIZED VIEW mv_t_msg_groupby AS
SELECT
public_time
,sum(case when status = 0 then 1 else 0 end) AS init_count
,sum(case when status = 1 then 1 else 0 end) AS query_count
,sum(case when status = 2 then 1 else 0 end) AS callback_count
,max(process_time) as process_time
FROM t_msg
group by public_time;
select * from mv_t_msg_groupby;
--sink_query_alarm
DROP SINK sink_query_alarm;
CREATE SINK sink_query_alarm AS
SELECT
public_time
,init_count
,query_count
,process_time
FROM mv_t_msg_groupby
where public_time + INTERVAL '5 minute' <= now() --query_timeout=1 minute, public_time相当于当前时间延迟1分钟触发,【Delay table changes】
and init_count*1 > query_count --query_threshold=1
WITH (
connector='kafka',
properties.bootstrap.server='192.168.1.100:8092',
topic='t_sink_query_alarm'
)
FORMAT PLAIN ENCODE JSON(
force_append_only='true'
);
--由于RisingWave不支持在【MATERIALIZED VIEW】和【SINK】等【可伸缩流】中指定处理时间字段,因此需要借助外部存储kafka周转
--RisngWave官方给的解释:support a proctime on an append only stream might be easier but on retractable stream could take extra cost. We must think it carefully to introduce such a feature.
--sink_query_succ
DROP SINK sink_query_succ;
CREATE SINK sink_query_succ AS
SELECT
public_time
,init_count
,query_count
,callback_count
,process_time as query_succ_process_time
FROM mv_t_msg_groupby
where public_time + INTERVAL '5 minute' >= now() --query_timeout=1 minute, 在指定的时间内,【Delete and clean expired data】
and init_count*1 <= query_count --query_threshold=1,query_count达到了指定值
WITH (
connector='kafka',
properties.bootstrap.server='192.168.1.100:8092',
topic='t_sink_query_succ'
)
FORMAT PLAIN ENCODE JSON(
force_append_only='true'
);
--source连接器
DROP SOURCE source_query_succ;
CREATE SOURCE IF NOT EXISTS source_query_succ (
init_count int
,query_count int
,callback_count int
,public_time timestamp
,query_succ_process_time timestamp
)
WITH (
connector='kafka',
topic='t_sink_query_succ',
properties.bootstrap.server='192.168.1.100:8092',
scan.startup.mode='earliest', -- earliest ,latest,default:earliest
) FORMAT PLAIN ENCODE JSON;
select * from source_query_succ;
--sink_callback_alarm,用到动态过滤器和时间过滤器
DROP SINK sink_callback_alarm;
CREATE SINK sink_callback_alarm AS
WITH tmp AS (
select public_time, min(query_succ_process_time) as query_succ_process_time -- 动态过滤器
FROM source_query_succ
group by public_time
)
SELECT
b.public_time
,b.init_count
,b.query_count
,b.callback_count
,b.process_time
,a.query_succ_process_time
FROM tmp a
JOIN mv_t_msg_groupby b ON a.public_time=b.public_time
where a.query_succ_process_time + INTERVAL '1 minute' <= now() --query_timeout=1 minute, public_time相当于当前时间延迟1分钟触发,【Delay table changes】
and b.query_count*1 > b.callback_count --callback_threshold=1
WITH (
connector='kafka',
properties.bootstrap.server='192.168.1.100:8092',
topic='t_sink_callback_alarm'
)
FORMAT PLAIN ENCODE JSON(
force_append_only='true'
);
-- 模拟数据
--init
INSERT INTO t_msg values(1,0,'2024-02-23 15:55:00'::TIMESTAMP); --比当前系统时间早
INSERT INTO t_msg values(2,0,'2024-02-23 15:55:00'::TIMESTAMP);
INSERT INTO t_msg values(3,0,'2024-02-23 15:55:00'::TIMESTAMP);
--query
INSERT INTO t_msg values(1,1,'2024-02-23 15:55:00'::TIMESTAMP);
INSERT INTO t_msg values(2,1,'2024-02-23 15:55:00'::TIMESTAMP);
INSERT INTO t_msg values(3,1,'2024-02-23 15:55:00'::TIMESTAMP);
--callback
INSERT INTO t_msg values(1,2,'2024-02-23 15:55:00'::TIMESTAMP);
INSERT INTO t_msg values(2,2,'2024-02-23 15:55:00'::TIMESTAMP);
INSERT INTO t_msg values(3,2,'2024-02-23 15:55:00'::TIMESTAMP);
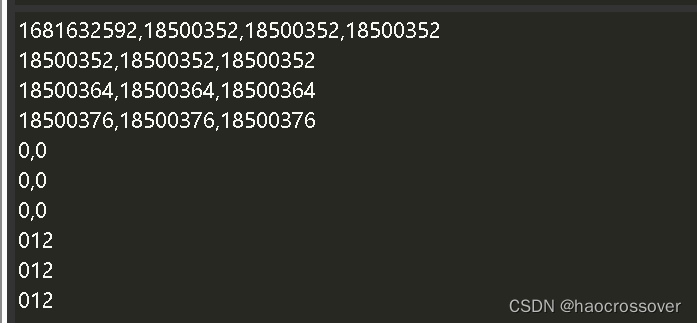
查看监控结果:
docker run -it --rm edenhill/kcat:1.7.1 kcat -b 192.168.1.100:8092 -t t_sink_query_alarm -C
docker run -it --rm edenhill/kcat:1.7.1 kcat -b 192.168.1.100:8092 -t t_sink_callback_alarm -C