基础环境
hostnamectl set-hostname els01
hostnamectl set-hostname els02
hostnamectl set-hostname els03
hostnamectl set-hostname kba
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
systemctl stop firewalld & systemctl disable firewalld
# 安装jdk
cd /usr/local
tar -xvf jdk1.8.0_231.tar.gz
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
elasticsearch
安装
# 创建用户与组
groupadd -g 500 els
mkdir -p /opt/app/els
useradd -d /opt/app/els -u 2000 -g els els
echo "els#123" | passwd --stdin els
cp -r etc/skel/.bash* /opt/app/els
cd /opt/app
chown -R els:els /opt/app/els
chmod -R 755 /opt/app/els
su - els
tar -xvf elasticsearch-7.6.2-linux-x86_64.tar.gz -C /opt/app/els
chown -R els:els /opt/app/els
更改用户可创建的线程数
vi /etc/security/limits.d/20-nproc.conf
els soft nproc 4096
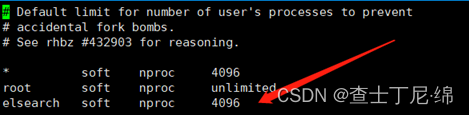 否则报错:max number of threads [1024] for user [elsearch] likely too low, increase to at least [4096]
否则报错:max number of threads [1024] for user [elsearch] likely too low, increase to at least [4096]
更改打开文件数与线程数
vi /etc/security/limits.conf
els soft nofile 65536
els hard nofile 131072
els soft nproc 4096
els hard nproc 4096
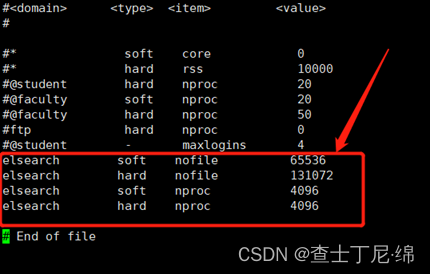
否则报错:node validation exception bootstrap checks failed
更改系统控制文件
Elasticsearch 默认使用 mmapfs 目录存储索引,而 Linux 默认对 mmap 计数限制可能太低,会导致内存异常。系统控制文件是管理系统中的各种资源控制的配置文件,ES 需要开辟一个 65536 字节以上空间的虚拟内存,但 Linux 又不允许任何用户直接开辟虚拟内存,所以通过如下方式修改:
vi /etc/sysctl.conf
vm.max_map_count=655360
sysctl -p
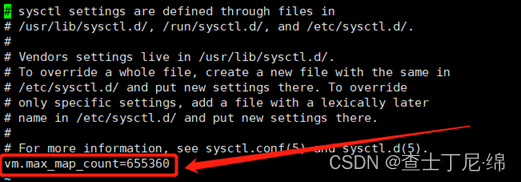
否则报错:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
环境变量
vi /opt/app/els/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_231
export ES_HOME=$HOME/elasticsearch-7.6.2
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$ES_HOME/lib
export PATH=$HOME/bin:$JAVA_HOME/bin:$ES_HOME/bin:$PATH
vi /opt/app/elsearch/.bashrc
ES_HOME=/opt/app/elsearch/elasticsearch-7.6.2
PATH=$PATH:$ES_HOME/bin
source ~/.bash_profile & source ~/.bashrc
su - els
mkdir -p /opt/app/elsearch/data /opt/app/elsearch/logs
vi elasticsearch-7.6.2/config/elasticsearch.yml
#集群名称
cluster.name: DR-ELK
#默认情况下,Elasticsearch 将使用随机生成的 UUID 的前七个字符作为节点 ID,该节点名称一经生成后,即使重启服务亦不会变更
node.name: els01
path.data: /opt/app/elsearch/data
path.logs: /opt/app/elsearch/logs
#默认情况下,此 elasticsearch 服务绑定到回环地址127.0.0.1。修改为节点ip在浏览器中访问不成功
network.host: 0.0.0.0
#集群中拥有被选举成 Master 节点资格的地址列表
discovery.seed_hosts: ["ip1:9400","ip2:9400","ip3:9400"]
#在一个新集群初始化时,符合 Master 节点资格的节点集
cluster.initial_master_nodes: ["ip1:9400","ip2:9400","ip3:9400"]
#为最多主节点个数
discovery.zen.minimum_master_nodes: 1
#为超时后生效节点数
gateway.recover_after_nodes: 1
#没有这两项配置7.6.2版本的kibana将无法调用ES
# 文本最后追加
http.cors.enabled: true
http.cors.allow-origin: "*"
注释掉判断是否存在 JAVA_HOME变量的流程分支,直接使用操作系统的JDK
cd /opt/app/elsearch/elasticsearch-7.6.2/bin/
cp elasticsearch-env elasticsearch-env.bak
vi /opt/app/elsearch/elasticsearch-7.6.2/bin/elasticsearch-env

su - els
cd /opt/app/elsearch/elasticsearch-7.6.2/bin
#以守护进程模式运行
./elasticsearch -d
#停止
ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}' | xargs kill -SIGTERM
#查看状态
cat /opt/app/elsearch/logs/集群名称.log
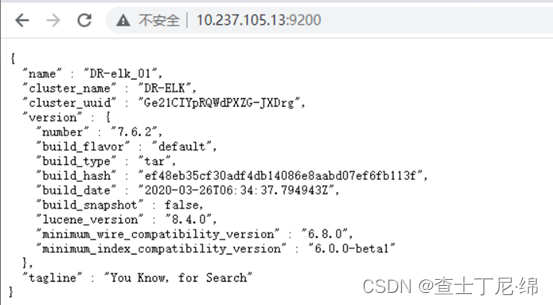
curl -X GET http://ip:9200
kibana
安装
groupadd -g 500 kbn
mkdir -p /opt/app/kbn
useradd -d /opt/app/kibana -u 2000 -g kba kba
/bin/echo "kba#123" | passwd --stdin kba
cp -r /etc/skel/.bash* /opt/app/kba
chown -R kbn:kbn /opt/app/kba
chmod -R 755 /opt/app/kba
su - kba
tar -xvf kibana-7.6.2-linux-x86_64.tar.gz -C /opt/app/kba
chown -R kba:kba /opt/app/kibana
环境变量
vi /opt/app/kba/.bashrc
# 注意jdk相关变量
export KIBANA_HOME=/opt/app/kibana/kibana-7.6.2-linux-x86_64
export PATH=$PATH:$KIBANA_HOME/bin
source ~/.bashrc
su - kba
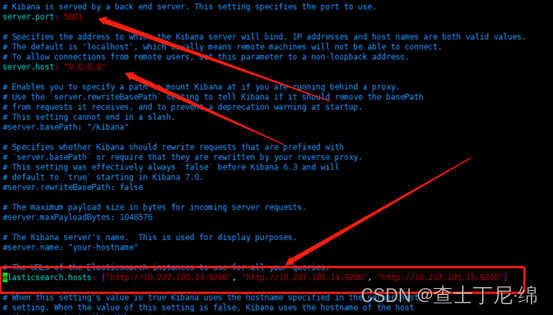
vi kibana-7.6.2-linux-x86_64/config/kibana.yml
# 端口
server.port: 5601
# 服务主机名
server.host: "0.0.0.0"
# 指定ES服务,可以指定多个
elasticsearch.hosts: ["http://ip1:9200","http://ip2:9200","http://ip3:9200"]
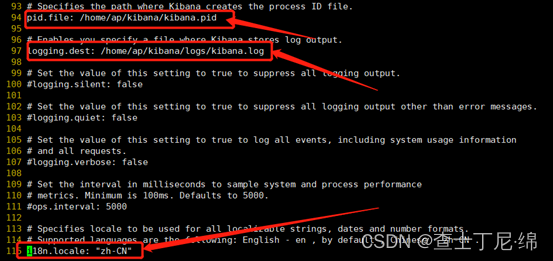
# 进程文件
pid.file: /opt/app/kibana/kibana.pid
# 日志路径
logging.dest: /opt/app/kibana/logs/kibana.log
# 汉化
i18n.locale: "zh-CN"
mkdir -p /opt/app/kibana/logs/
su - kba
cd /opt/app/kibana/kibana-7.6.2-linux-x86_64/bin
#后台运行
./kibana &
#停止
ps -ef | grep kibana | grep -v grep | awk '{print $2}' | xargs kill -SIGTERM
#查看
cat /opt/app/kibana/logs/kibana.logs
#浏览器访问http://ip:5601/
es核心概念
节点分类
节点是一个独立的服务器实例或进程,用于存储数据并参与集群的索引和搜索功能。每个节点都有自己的名称、角色和职责。
master node:负责管理集群的整体状态和执行一些关键的集群级别的操作。主节点负责将分片存储到数据节点、维护集群的状态信息、决定哪些节点是集群的一部分等。本身不负责存储实际的数据。
data node:数据节点负责存储实际的数据。管理索引的分片,并处理与数据相关的操作,如搜索、索引和删除。数据节点存储索引的一部分,并通过将数据分布在多个节点上来实现水平扩展。
coordinating node:协调节点是可选的节点类型,主要用于处理搜索请求的协调工作。不存储实际的数据,而是负责接收来自客户端的搜索请求,并将这些请求转发给数据节点。协调节点有助于分散搜索请求的负载,特别是在大规模集群中。
ingest node:预处理节点,负责数据的预处理,如数据的转换和附加处理。这允许在将数据索引到es之前对数据进行修改或过滤。该节点通常用于日志处理和数据管道中。
machine learning node:用于执行与机器学习相关的任务,如异常检测或趋势分析。
remote-eligible node:远程合格节点,拥有远程集群客户端角色,可以充当远程客户端。默认情况下,集群内任意节点都可以作为跨集群的客户端连接到远程集群。
transform节点:用于执行数据转换操作,例如从一个索引中提取数据并将其转换为另一个索引,以便在数据仓库和分析方面进行使用。
index
索引是一个逻辑存储,类似关系型数据库中的表,用来存储管理相关数据,数据以JSON格式存储在索引的基本单元-文档Document。
shard
一条索引的数据往往会被分为多个分片进行存储,每个分片是一个独立的存储单元,底层为一个Lucene索引,可以在集群中的不同节点上分布,以提供高可用性和负载均衡。
分片的目的
允许索引水平分割和分布存储,实现数据和负载的分布。
分片的数量
在索引创建后不能被更改。通常,每个主分片的大小应该适中,以便在集群中的各个节点上均匀分布负载,也有利于数据的快速查询。
主分片
每个索引都可以被分为一个或多个主分片。主分片存储索引的一部分数据,并负责处理搜索和查询操作。主分片的数量设置在索引创建时便被定义,无法进行动态修改。
Replica
副本是指索引的一个复制,每个索引可以被配置为具有零个或多个副本。副本可以提高集群的可用性和容错性,以及提高搜索性能。
每个索引被划分为一个或多个主分片。主分片负责存储索引的一部分数据,以及处理搜索和写入请求。为了提高可用性和容错性,每个主分片可以有零个或多个副本。
每个索引的副本数量是可以配置的。在创建索引时,可以指定副本的数量。副本数量的选择取决于对可用性和性能的需求。
maping
映射是索引中文档的规范,定义了结构和字段属性,描述了文档中的每个字段的数据类型、分词器、是否索引等信息。类似于关系型数据库中的Schema。
示例

index的名称为example_index
title是一个文本字段,使用标准分词器
author是一个关键字字段,通常用于精确匹配
publish_date是一个日期字段,用于存储日期信息
views是一个整数字段,用于存储整数值
tags是一个关键字字段,用于存储标签信息